特徴量エンジニアリングの完全ガイド
この記事は中国語の記事から洗い出したものです。
レコメンド領域の特徴量エンジニアリング
一、なぜ特徴量エンジニアリングが重要
特徴量エンジニアリングが重要な理由

機械学習の分野では、「Garbage In, Garbage Out(ゴミを入れればゴミが出てくる)」は業界の共通認識となっている。特徴量エンジニアリングは機械学習パイプラインの上流に位置し、その処理結果の良し悪しが後続のモデルの性能に影響を与える。
なので、特徴量エンジニアリングが重要になる理由は:
- データと特徴は効果の上限を決めている。モデルとアルゴリズムはただ上限に近づくための手段に過ぎない
- 特徴量エンジニアリングは専門家の経験を反映したもの
- 良い特徴量エンジニアリングは明らかにモデルの効果を向上できる
特徴量エンジニアリングに関する三つの勘違い
1、深層学習時代は特徴量エンジニアリングの必要がない

リレーショナルデータにおける特徴量生成と変換操作は、主に以下の2つの種類がある:
- 行に基づく特徴変換(row-based):新しい特徴は同じサンプルの他の特徴から変換されて得られるもので、例えば数値型特徴のスケーリング変換などがあります。
- 列に基づく特徴変換(column-based):すべてのサンプルデータに対して統計や集約を行うことで得られるもので、最大値、最小値、平均値などがあります。
深層学習にはある程度row-based特徴を学習できるけど、column-basedを学習することができない。深層モデルは一度に小さなバッチのサンプルしか受け入れられず、グローバルな統計集約情報をモデル化できない。そしてこの情報は通常とても重要なものだ。そのため、深層学習モデルであっても、特徴量エンジニアリングを慎重に行う必要がある。
2、AutoFE(automated feature engineering )などのツールがあるから、手動で特徴量エンジニアリングの必要がない
AutoFEの研究は始まったばかりで、使いやすくはない。
それに、専門家の経験を代替することができない。
3、技術的な要素が欠けている(上級者的じゃなく、初心者っぽい)
逆に特徴量エンジニアリングが上手な人は上級者的。
二、良い特徴量エンジニアリングとは
- 高品質な特徴
- 識別性がある
- 互いに独立している
- 解釈可能性が高い
- スケーラビリティ:
- 高次元のカーディナリティに対応
- 大規模データに対応
- 効率性:
- 高い同時実行性に対応
- 柔軟性:
- 様々なモデルタスクに適用可能
- ロバスト性:
- データ分布の変化に適応できる
三、よく使われる特徴量変換
数値系特徴
1、特徴量のスケーリング
特徴スケーリングは、値の範囲が大きい特徴を小さい範囲に縮小することだ。特徴スケーリングを行わないと、大きい値を持つ特徴が勾配更新の方向を支配してしまい、誤差超平面上で勾配が振動を繰り返すことになり、モデルの学習効率が低下する。
さらに、KNNやK-meansなどの距離に基づくアルゴリズムも、特徴スケーリングの有無に大きく影響を受ける。特徴スケーリングを行わないと、値の範囲が大きい特徴が距離関数の計算を支配し、他の特徴が効果を失ってしまう。

一般的な特徴量スケーリング手法は下記のようになる:

いくつかの課題を通して、具体的に理解を深めよう。
課題1:短編動画の人気度をどのように定量化するか?
参考答案:Log-basedをした上でZ-score正規化をする
解釈:log変換をせずに直接Z-score処理をすると、大部分の特徴値が非常に狭い領域に圧縮されてしまう。
課題2:商品は「高い」か「安い」かの程度がどのように定量化されるか?
参考答案:データ全体で計算することじゃなく、同じカテゴリに限定してZ-scoreにする
解釈:商品が「高い」か「安い」かの程度を測るときは、商品のカテゴリを考慮する必要がある。ここでおすすめの方法は、Zスコア標準化を使うこと。ただし、Zスコアの平均値と標準偏差の計算は、同じカテゴリの商品に限定しなければならず、データ全体で計算してはいけない。
課題3:ユーザーがニュースのテーマに対する好ましさをどのように定量化するか(閲覧回数)
参考答案:ユーザーごとにグループ分けして、グループ内でMin-max正規化をする。
解釈:ユーザーごとにアクティブ度が違う。アクティブなユーザーは複数のジャンルをたくさん読むかもしれないけど、あまりアクティブじゃないユーザーは特定のいくつかのジャンルをそこそこ読むくらいかもしれない。だから、分けて対応する必要がある。
2、異常値の処理(Robust scaling)
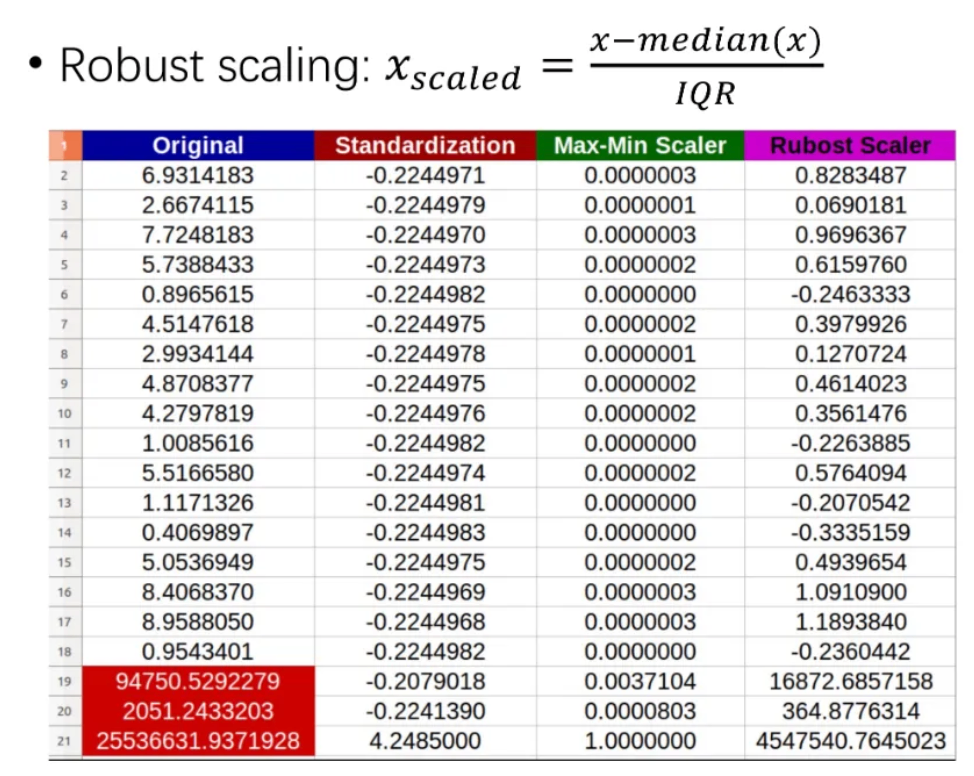
ここで、median(x)はxの中央値を意味する。IQRは四分位範囲(四分差)で、サンプルの75%分位点の値から25%分位点の値を引いたもの。
最良の処理方法は、まず異常値を事前に特定し、その後削除または置換処理を行うこと。
3、ビンニング(Binning)
ビンニングとは:連続的な特徴を離散化して、ある方法で特徴値をいくつかの箱(bin)に割り当てることだ。
なぜビンニングする?
- 非線形変換を導入して、モデルの性能を向上させる。元の値と目的値の間に線形関係がないことがあるから、そのままモデルで予測しても良い結果が出ない。
- モデルの説明性を強化する。分箱すると区間ごとの関数が得られるから、モデルの説明性が高まる。
- 異常値に影響されにくく、過学習を防ぐ。異常値も最終的にはどこかの箱に入るから、他の箱の正常な特徴値に影響を与えない。分箱はある程度、過学習の防止にもなる。
- 一番重要なのは、分箱した後に各箱ごとに統計を取ったり、特徴の組み合わせをしたりできること。例えば、年齢ごとに分箱した後、年齢層ごとにCTRを統計することができる。
ビンニングは教師なしの方法と教師ありの方法の二種類がある。
- 教師あり:教師なし方法には、固定幅ビンニング、分位数ビンニング、対数変換および切り捨てなど。よく使われる
- 教師なし:決定木など。あまり使われない
二つの課題を通して、具体的に理解を深めよう。
課題1:ユーザーの購買力や購買意欲をどのように定量化するか?
参考答案:まずは商品のカテゴリーごとで商品の高さを定量化する。そして、ユーザーごとで商品の高さによって購買力を定量化する。最後に、ユーザーの好みが違うので、商品のカテゴリーごとで購買力を定量化することもできる。
解釈:同じユーザーでも、異なる種類の商品に対する購買力は違う。例えば、あるユーザーは電子製品に高い金額を払うことをいとわないが、他の種類の商品に対する購買力は普通だったりする。だから、各カテゴリーごとに購買力を計算する必要がある。
課題2:緯度と経度をどのようにビンニングするか?
参考答案:よく使われる方法の一つがGeoHashで、簡単に言うと地図を二次元の格子に分け、異なる格子には一意のハッシュコードが割り当てられ、それが異なる地域を表す。
解釈:緯度と経度は一つの全体で、これを複数の独立した変数に分けて個別にビンニングすることはできない。これらの変数は一つの全体として考える必要がある。
良いビンニングとは?
bad idea:グローバルビンニング
good idea:ユーザーごとでビンニング

aliceのBeautyとBobのSportは実際に同じだ。この二つのカテゴリはお互いの優先選択肢であり、グローバルなビニングではこの類似性を反映できない。
そのため、特徴量エンジニアリングでは、ユーザーの統計的特徴を先にユーザーごとにグループ化してからビンニングを行うべきで、グローバルにビンニングをするのはお勧めしない。また、ビンニング後に保存すべきなのは箱番号であり、具体的な範囲の値ではない。
カテゴリー特徴
1、交差組み合わせ
識別性があまり良くない時、交差組み合わせを試してみよう。

上の図のように、特徴f1とf2がそれぞれ単独で存在していると、区別性があまり良くない。しかし、これらを組み合わせて1つの特徴にすると、良い予測ができるようになる。右側の散布図のように、青色と黄色はそれぞれ正のサンプルx1とx2を表していて、元々は線形で分けられないが、特徴の組み合わせx3=x1x2を導入すると、sign(x3)を使って予測できるようになる。
2、ビンニング(Binning)
カテゴリ型の特徴量も時にはビン分けが必要だ。特に高基数の特徴量がある場合、ビン分けを行わないと、高基数の特徴量が低基数の特徴量に対して支配的になりやすく、ノイズを引き入れ、モデルが過学習しやすくなる。
カテゴリ型特徴量のビン分け方法には通常、以下の3つがある。
- ビジネスの理解に基づく方法。例えば、userIDをビン分けする際に職業別に分けたり、年齢層別に分けたりする方法。
- 特徴量の頻度に基づき、低頻度の長尾部分を統合する方法(バックオフ)。
- 決定木モデルに基づく方法。
3、統計エンコーディング
統計エンコーディングは、カテゴリ自体やターゲット変数に関連する統計量を見つけて、それをカテゴリ特徴の代わりとして使う手法だ。これによって、カテゴリ特徴をコンパクトで密度の高い実数型の特徴ベクトルに変換できる。
- Count Encoding は、特定のカテゴリ特徴が出現する頻度を数える方法だ。通常、そのままではモデルに入力できないため、特徴変換が必要になる。推奨される特徴変換の方法としては、Gauss Rank や Binning などがある。
- Target Encoding は、特定のカテゴリ特徴のターゲット変換率を計算する方法だ。例えば、ターゲットがクリックならクリック率を、ターゲットが購入なら購入率を計算する。ただし、ターゲット変換率を計算するときは信頼度を考慮しなければならない。例えば、10回の閲覧で5回クリックがあった場合と、1000回の閲覧で500回クリックがあった場合では信頼度が異なる。そのため、クリック回数が少ない場合は、全体のクリック率を使ってスムーズに調整する必要がある。
- Odds Ratio は、ユーザーが特定のカテゴリの商品をどれくらい好んでいるかを、他のカテゴリと比較して測るための指標だ。例えば、上の図の例では、Alice の Bag カテゴリへの好みの度合いは、他のカテゴリに対する好みの 0.7906 倍になっている。
- Weight of Evidence(WOE) は、特定のカテゴリ特徴の異なるグループ(ビン)ごとの値とターゲットとの関連性を測る指標だ。値が正なら正の相関があり、値が負なら負の相関があることを意味する。
時系列特徴
時系列特徴には、過去1日、3日、7日、30日の総行動数や行動転換率の統計が含まれる。それに加えて、現在の値と過去の値の差を比較することもできる。
例えば、ECサイトのシナリオでは、商品の価格が以前と比べて上がったのか下がったのかが、ユーザーの購買意欲の重要な特徴になり得る。さらに、行動シーケンス特徴もあり、これはモデルとの連携が必要になる。
四、レコメンド領域の特徴量エンジニアリング
レコメンド領域の特徴
レコメンドシステムはリレーショナルデータにおけるデータマイニングの問題で、主な課題は高カーディナリティの特徴、大量のデータサンプル、オンライン推論のリアルタイム性の要求などがある。これらの課題に対応するために、業界で最も一般的な方法は統計的特徴を大量に使用することだ。
ユーザーや商品の特定の特徴について、異なる行動タイプ、異なる時間周期、異なるラベルごとに正負サンプルの数を集計して統計特徴を得る。これらの統計量は、特徴変換を経て、特徴スケーリング、ビニング、統計エンコーディングなどを行った後、最終的な特徴ベクトルの一部として使われる。Gauss Rank を使って特徴のスケーリングをするのがおすすめだ。Gauss Rank は特徴の分布の変化に対してある程度のロバスト性を持っているからだ。
具体的な手法

推薦するエンティティ(ユーザー、アイテム、コンテキストなど)をビンニングしてから、正例と負例のサンプル数を数える。これをbin countingと呼ぶ。
上の図のような感じだ。ユーザーやアイテムの分箱統計特徴を手に入れた後、それらを組み合わせて新しい統計量を作ることもできる。これをcross countingと呼ぶ。
最終的に、これらの統計量はすべて特徴に変換される。
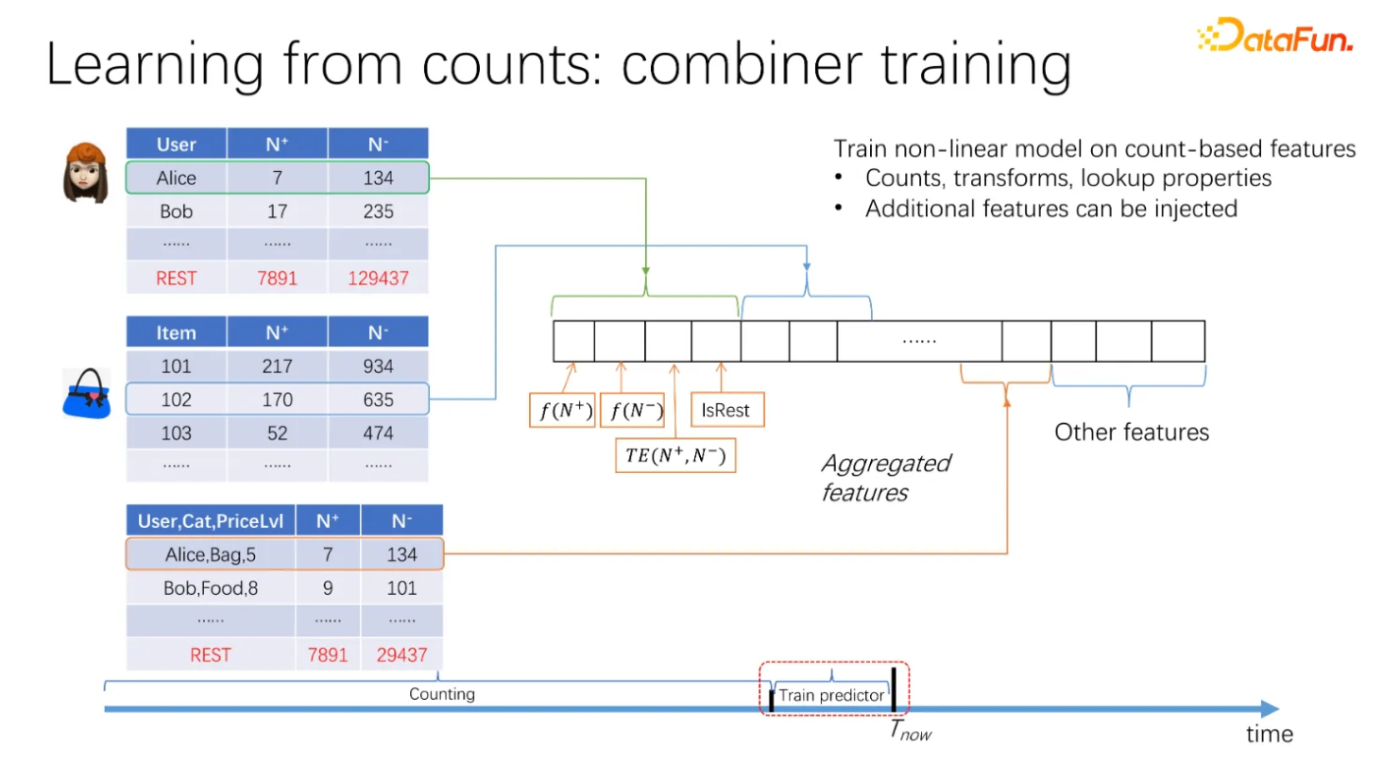
特徴のリーケージを防ぐために、すべての統計量の計算時間はサンプルイベントのビジネス時間より前に設定する必要がある。上の時間軸の図のように、Train predictorの段階では、その前のCountingの部分でしか統計カウントを行えない。最終的に、各粒度の統計量の特徴を変換した値を結合して、一つの特徴ベクトルにする。
まとめ
じゃあ、どうやってすべての特徴を考慮して、重複も漏れもなくするのか?以下のような構造化された方法で特徴を列挙できる。
-
エンティティを列挙する
レコメンドのシナリオでは、主なエンティティはユーザー、商品、コンテキスト。広告のシナリオでは、ユーザー、広告、検索ワード、広告プラットフォームが主なエンティティになる。
-
エンティティをビニングする
ユーザーや商品の自然属性に基づいてビニング(グループ分け)を行う。例えば、ユーザーは各ユーザープロフィールごとにビニングできるし、商品はカテゴリーや価格などを基準にビニングできる。こうして単一の特徴を得たら、過去の行動データを使って統計処理やエンコードを行う。
-
特徴交差を行う
エンティティのビニングを基に、特徴同士を掛け合わせて、2次、3次、さらに高次の特徴を作り出す。
最後にまとめると、検索プロモーションのシナリオにおける一般的な特徴エンジニアリングのパターンは、「Bin&Counting」という言葉でまとめられる。つまり、まずビニングを行い、その後カウントを行い、途中で「cross counting」を組み合わせる。
データサイエンス君のAI教材シリーズ(未経験OK)
教材のターゲット層:
- 初心者: Pythonとデータ分析の基本を学びたい人
- 中級者: より高度な分析手法や機械学習を習得したい人
- レコメンド(推薦)エンジニア: レコメンデーションエンジンを作り、キャリアアップを目指したい人
AI領域に携わりたい方はぜひ!
datasciencekunのAI教材シリーズ
LINE公式アカウント
データサイエンス君のLINE公式アカウント友達募集中!
今登録すれば、下記の内容をプレゼントします!
- 特典資料:AI教材の一部を無料でお送りします!
- 専門家との相談:メッセージでデータサイエンス領域の不明点が相談できます!
一人で学ぶより、仲間と一緒に成長しませんか?
今すぐ友達登録して、データサイエンスの旅を始めましょう!
LINE公式アカウント:https://line.me/R/ti/p/@datasciencekun?from=page&accountId=datasciencekun

Discussion