レコメンドシステム——協調フィルタリング(Collaborative Filtering)
シリーズの目次
レコメンドシステムのシリーズをここにまとめています。
レコメンドシステムとは?
レコメンドシステムの主な課題は何ですか?
情報技術とインターネットの発展により、私たちは情報過多の時代に入っています。この時代において、情報の消費者と生産者は大きな課題に直面しています。
- 情報消費者:大量の情報の中から、いかに自分の興味のある情報を見つけ出すか
- 情報生産者:いかにして自分の作った情報を差別化し、より多くのユーザーの注目を集めるか
レコメンドシステムが解決する課題は、「情報過多」の中で、ユーザーが興味のある情報を効率的に入手できるようにすることです。
情報消費者が価値ある情報を発見するのを助けると同時に、情報生産者のコンテンツを適切なユーザーに届けることができます。
レコメンドシステムの論理構成
レコメンドシステムが扱うのは本質的に「人」と「情報」の関係です。「人」と「情報」をもとに、興味のある「情報」を見つける方法を構築します。この問題において重要な3つのポイントを以下のように抽象化しました。
-
コンテンツ情報(Item)
「情報」の具体的な意味は、場面によって多岐にわたります。例えば、商品のレコメンドでは「商品情報」、動画のレコメンドでは「動画情報」、ニュースのレコメンドでは「ニュース情報」を、便宜上「アイテム情報」と呼びます。 -
ユーザー情報(User)
レコメンドシステムは、「人」の視点から、「人」の興味関心をより正確に推測するために、「人」に関する情報を幅広く活用します。過去の行動、人口統計学的属性、関係ネットワークなどを総称して「ユーザー情報」と呼びます。 -
コンテキスト(Context)
具体的なレコメンドの場面におけるユーザーの最終的な選択は、「コンテキスト情報」と呼ばれる時間、場所、ユーザーの状態などの環境情報に影響されます。
これら3つの要素をもとにレコメンドシステムの論理構造を定義しました。
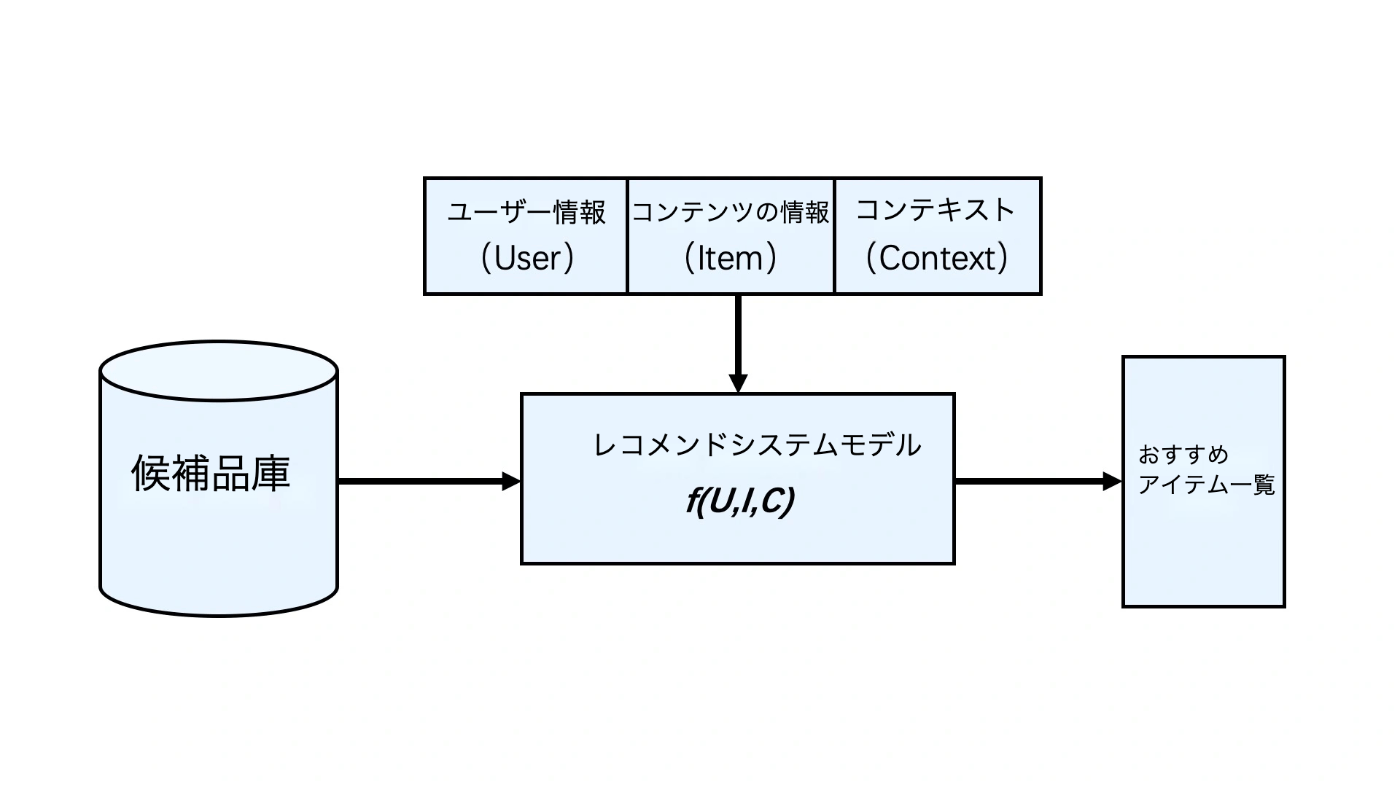
つまり、レコメンドシステムの本質は、どのようなユーザーが、どのような場面で、どのようなアイテムに興味を持つかを表す「関数」を定義することです。この定義の方法を一般的に「レコメンドアルゴリズム」と呼びます。
協調フィルタリング
協調フィルタリング(Collaborative Filtering)とは、過去の好みや趣味が似ているユーザーの選択に基づいて、アイテムを推薦する手法です。ユーザーの履歴行動データ(評価、購入、ダウンロードなど)を分析して好みの傾向を発見し、一般的にはアイテムの特徴(アイテム自体の属性)やユーザーの属性(年齢、性別など)は使用しません。現在広く使われている協調フィルタリングアルゴリズムは、近傍を用いた以下の2つの手法が主流です:
- ユーザーベース協調フィルタリング(UserCF):ユーザーと趣味が似ている他のユーザーが好むアイテムを推薦します。
- アイテムベース協調フィルタリング(ItemCF):ユーザーが過去に好んだアイテムと類似したアイテムを推薦します。
ユーザーベース協調フィルタリング(UserCF)
UserCFは1993年に考案された古典的なアルゴリズムですが、その考え方はシンプルです。あるユーザーAにパーソナライズされたレコメンドを提供する際、自分と似た趣味を持つ他のユーザーを見つけ出し、そのユーザーが好むアイテムの中からユーザーAがまだ知らないものを推薦します。
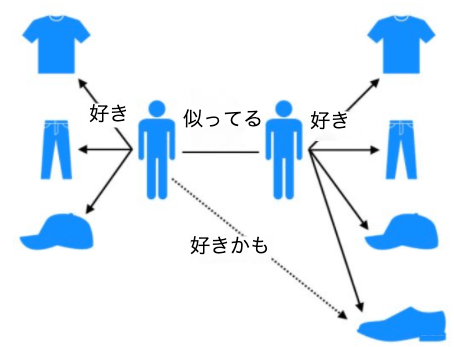
ユーザーベース協調フィルタリングは主に2つのステップで構成されます:
- 対象ユーザーと興味が似通ったユーザー群を特定する(ユーザー間の類似度を計算)
- 特定したユーザー群が好むアイテムの中から、対象ユーザーがまだ知らないものを選んで推薦する
アイテムベース協調フィルタリング(ItemCF)
アイテムベース協調フィルタリング(ItemCF)の基本的な考え方は、全ユーザーの過去の行動データからアイテム同士の類似性を事前に計算し、ユーザーが好むアイテムと類似性の高いアイテムを推薦するというものです。例えば、アイテムAとCが類似しており、多くのユーザーがAを好むならCも好む傾向にあるとき、ユーザーaがAを好んでいればCを推薦する、という具合です。
ItemCFは、アイテムの属性を使用せず、主にユーザーの行動履歴を分析して類似度を算出します。アイテムAとアイテムCの類似度が高いのは、AとCを同時に好むユーザーが多いためだと考えます。
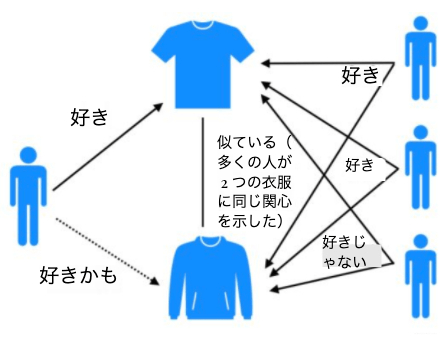
アイテムベース協調フィルタリングは、主に2つのステップで構成されます:
- アイテム間の類似度を計算する
- アイテムの類似度とユーザーの行動履歴から推薦リストを生成する(そのアイテムを購入したユーザーが他によく購入しているアイテムを抽出)
代表的な類似度計算手法
類似度とは、2つの要素間の類似性を数値化したものです。一般的に、要素間の距離を計算し、距離が小さいほど類似度は高く、距離が大きいほど類似度は低くなります。以下に、よく使用される類似度計算手法を紹介します。
-
ユークリッド距離(Euclidean Distance)
最も直感的な距離指標で、平面幾何学や立体幾何学でよく使用される距離計算方法です。 -
コサイン類似度(Cosine Similarity)
2つの属性ベクトルAとBが与えられたとき、そのコサイン類似度θは以下のように内積とベクトル長さによって定義されます。
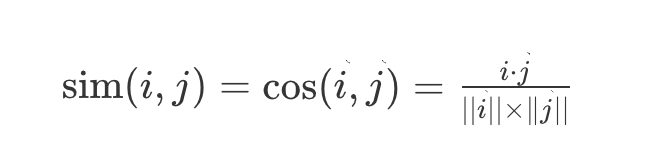
コサイン類似度は、次元数に関わらず「完全に一致する場合は1、直交する場合は0、正反対の場合は-1」という性質を持ちます。一方、ユークリッド距離は次元数の影響を受けて値の範囲が一定せず、解釈が難しくなります。ただし、ベクトルの長さを正規化するとピアソン相関係数と等価になり、この場合、ユークリッド距離とコサイン類似度は単調な関係になります。
- ピアソン相関係数(Pearson Correlation)
共分散を2つの変数の標準偏差で割った値です。ピアソン相関係数はコサイン類似度を発展させ、ユーザーごとの評価の偏りをユーザー平均で補正することで、より正確な類似度を算出できます。計算式は以下の通りです:
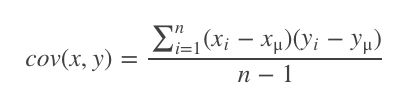
一般的に、データの正規化により指標間の次元の影響を除去する必要があるため、協調フィルタリングの多くの場面では、ユークリッド距離かコサイン類似度を使用します。ユークリッド距離は数値の絶対的な差異を、コサイン距離は方向の相対的な差異を表現するのに適しています。具体的な問題に応じて適切な指標を選択する必要があります。例えば:
-
2つのドラマに対するユーザーの視聴行動を分析する場合、ユーザーAの視聴ベクトルが(0,1)、ユーザーBが(1,0)のとき、コサイン距離は大きく、ユークリッド距離は小さくなります。この場合、異なるドラマに対する2人のユーザーの好みの相対的な差異に注目するため、コサイン距離が適しています。
-
ログイン回数と平均視聴時間を特徴とするアクティブ度を分析する場合、コサイン距離では(1,10)と(10,100)の2人のユーザーの距離が近いと判断されますが、実際には大きな差があります。この場合、絶対的な数値の差異に注目するため、ユークリッド距離が適しています。
協調フィルタリングアルゴリズムの比較
| UserCF | ItemCF | |
|---|---|---|
| 性能 | ユーザー数が少ない場合に適しています。ユーザー数が多い場合、ユーザー類似度行列の計算コストが高くなります | アイテム数がユーザー数より明らかに少ない場合に適していますが、アイテムが多い場合は類似度行列が大きくなります |
| 適用領域 | ユーザーの興味の多様性が低い分野に適しており、高い実用性を示します | ロングテールのアイテムが豊富で、ユーザーの個性が強く表れる分野に適しています |
| リアルタイム性 | ユーザーの新しい行動が必ずしもレコメンド結果に即座に反映されるとは限りません | ユーザーの新しい行動が必ずレコメンド結果に反映されます |
| コールドスタート | 新規ユーザーが少数のアイテムに対して行動を起こしても、すぐにパーソナライズされたレコメンドを提供することは困難です。ユーザー類似度テーブルは一定期間ごとにオフラインで計算されるためです | 新規アイテムは、ある程度のユーザー行動が蓄積された後でないと、類似の興味を持つユーザーへの推薦が難しく、オフラインでの類似度リストの更新が必要です |
| 推薦理由 | ユーザーに納得感のある説明を提供することが難しいです | ユーザーの過去の行動履歴に基づいて推薦理由を説明でき、ユーザーの理解を得やすいです |
実装例

Aliceのアイテム5に対する評価値を予測する場合...
アイテムベース協調フィルタリング(ItemCF)の実装
ステップ1:アイテム5と他のアイテムの類似度を計算します。ここではピアソン相関係数を使用します(正規化なし)。
類似度行列はnumpyを使用して簡単に計算できます。
import numpy as np
import pandas as pd
# items[i] アイテムi+1, その中でi=0,1,2,3,4
items = np.array([
[3, 4, 3, 1],
[1, 3, 3, 5],
[2, 4, 1, 5],
[3, 3, 5, 2],
[3, 5, 4, 1]]
)
cols = ['item' + str(idx) for idx in range(1, 6)]
pd.DataFrame(data=np.corrcoef(items), columns=cols, index=cols)
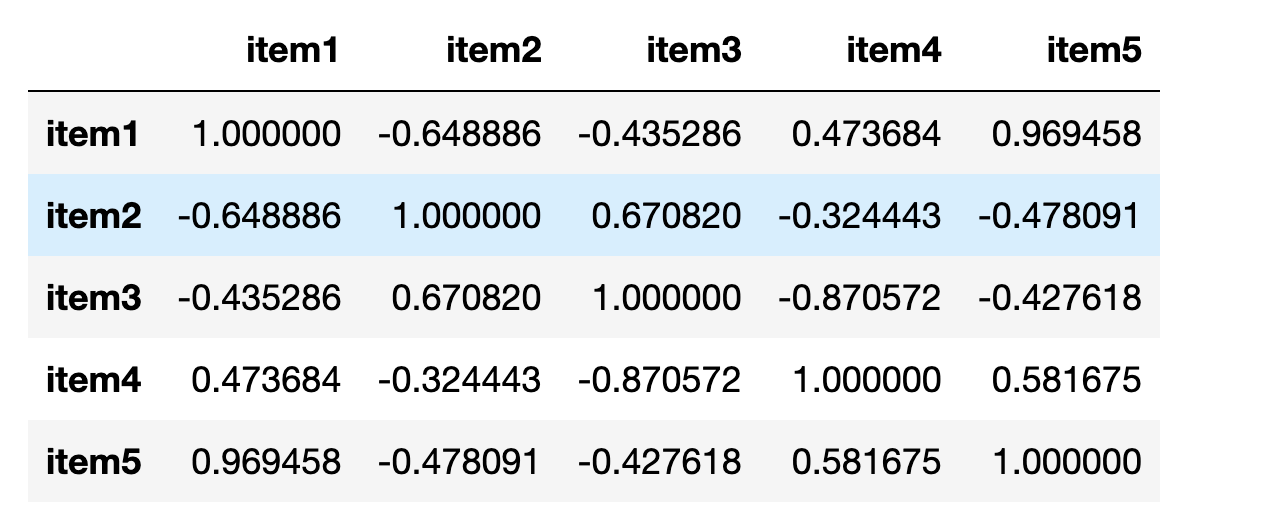
ステップ2:アイテム5に最も類似度の高いn個のアイテムを選択します。今回はアイテム数が少ないため、n=2とします。
ステップ1で計算した類似度行列から、アイテム5はアイテム1および4と高い類似度を示していることがわかりました。
ステップ3:Aliceの最も類似度の高いn個のアイテムの評価値から、アイテム5の評価値を予測します。
一般的には、アイテム類似度と類似アイテムの評価値の加重平均を用いて、ユーザーの評価値を予測します。
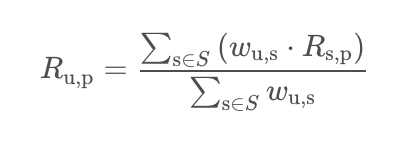
しかし、評価値の付け方には個人差があり、高い評価値を付ける傾向のユーザーもいれば、低い評価値を付ける傾向のユーザーもいます。このようなユーザーごとの評価傾向の違いが明確な場合は、以下の式のように、アイテムの評価値とユーザーの平均評価値との差分を加重平均して補正します。
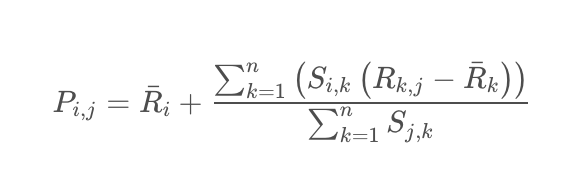
アイテム5とアイテム1,4の類似度はそれぞれ0.97と0.58、アイテム1,4の平均は16/5=3.2と17/5=3.4、アイテム5の平均は13/4=3.25となります。結果は以下のように計算されます:

ユーザーベース協調フィルタリング(UserCF)の実装
ステップ1:ユーザー5と他のユーザーのピアソン相関係数を計算します。
import numpy as np
import pandas as pd
# items[i] アイテムi+1,その中でi=0,1,2,3,4
users = np.array([
[3, 1, 2, 3,],
[4, 3, 4, 3,],
[3, 3, 1, 5,],
[1, 5, 5, 2,],
[5, 3, 4, 4]]
)
cols = ['user' + str(idx) for idx in range(1, 6)]
pd.DataFrame(data=np.corrcoef(users), columns=cols, index=cols)
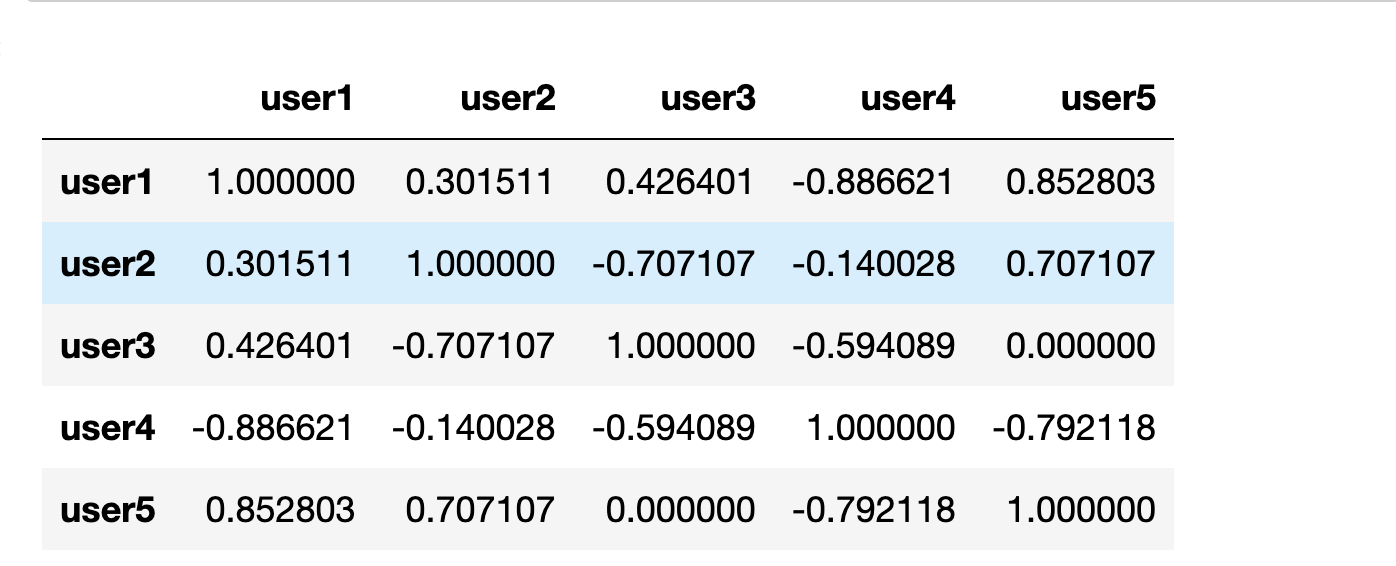
ステップ2:ユーザー5に最も類似度の高いn人のユーザーを選択します。ここでもn=2とします。
最も類似度の高い2人はユーザー1と2です。
ステップ3:類似ユーザーの評価値からアイテム5の評価値を予測します。
ユーザー5とユーザー1,2の類似度はそれぞれ0.85と0.71、ユーザー1,2の平均は12/5=2.4と19/5=3.8、ユーザー5の平均は16/4=4となります。
結果は以下のように計算されます:
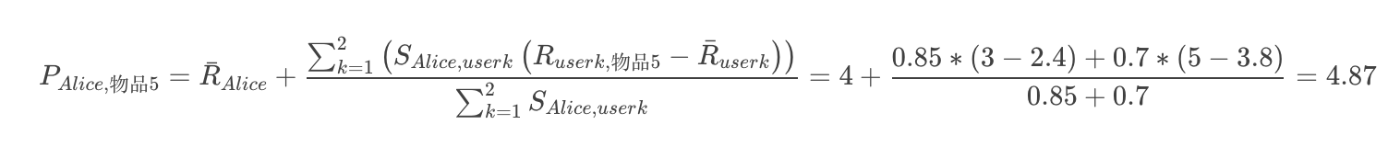
まとめ
本記事で解説した協調フィルタリングアルゴリズムは、比較的古い手法ですが、その考え方と原理には今でも学ぶべき点が多くあります。このアルゴリズムの特筆すべき点は、アイテム自体やユーザー自身の属性情報を必要とせず、ユーザーとアイテムの相互作用情報のみでレコメンドタスクを実現できることです。モデルの汎用性が高く、推薦理由の説明が容易で、対象領域の専門知識をあまり必要とせず、実装が比較的簡単でありながら、十分な効果が得られます。これらの特徴が、このモデルが初期に広く普及した理由です。
また、この古典的なレコメンドアルゴリズムは、後続の従来型モデルや深層学習モデルの発展に大きな影響を与えています。
データサイエンス君のAI教材シリーズ(未経験OK)
教材のターゲット層:
- 初心者: Pythonとデータ分析の基本を学びたい人
- 中級者: より高度な分析手法や機械学習を習得したい人
- レコメンド(推薦)エンジニア: レコメンデーションエンジンを作り、キャリアアップを目指したい人
AI領域に携わりたい方はぜひ!
datasciencekunのAI教材シリーズ
LINE公式アカウント
データサイエンス君のLINE公式アカウント友達募集中!
今登録すれば、下記の内容をプレゼントします!
- 特典資料:AI教材の一部を無料でお送りします!
- 専門家との相談:メッセージでデータサイエンス領域の不明点が相談できます!
一人で学ぶより、仲間と一緒に成長しませんか?
今すぐ友達登録して、データサイエンスの旅を始めましょう!
LINE公式アカウント:https://line.me/R/ti/p/@datasciencekun?from=page&accountId=datasciencekun

Discussion