はじめに
Snowflake主催の最大のカンファレンスであるSUMMIT 2024に参加してきました。今年はサンフランシスコで6月3日から6月6日にかけて開催され、AIに関する発表が全面に押し出された印象的なイベントでした。
私は普段、データエンジニアとしてSnowflakeを使ったデータ基盤構築・運用に携わっています。本記事では、SUMMITで発表された新機能や改善点の中から、特にデータエンジニアの視点で注目した点をピックアップしてご紹介します。
ちなみに、私がどういうドメインの問題を扱っているかについては、「データ基盤Visionの進化の軌跡-事業の成長と共に歩んだ道のり」で詳しく書いてるので、背景を知りたい方はこちらを御覧ください。
なお、全体的な印象や、AI関連の機能に対する感想は、別途「Snowflake SUMMIT 2024が示唆する、AI時代のデータエンジニアリングの在り方」という記事も書いていますので、そちらもぜひご覧ください。
1. 開発体験向上
Snowflake Copilot:AI駆動のSQLアシスタント
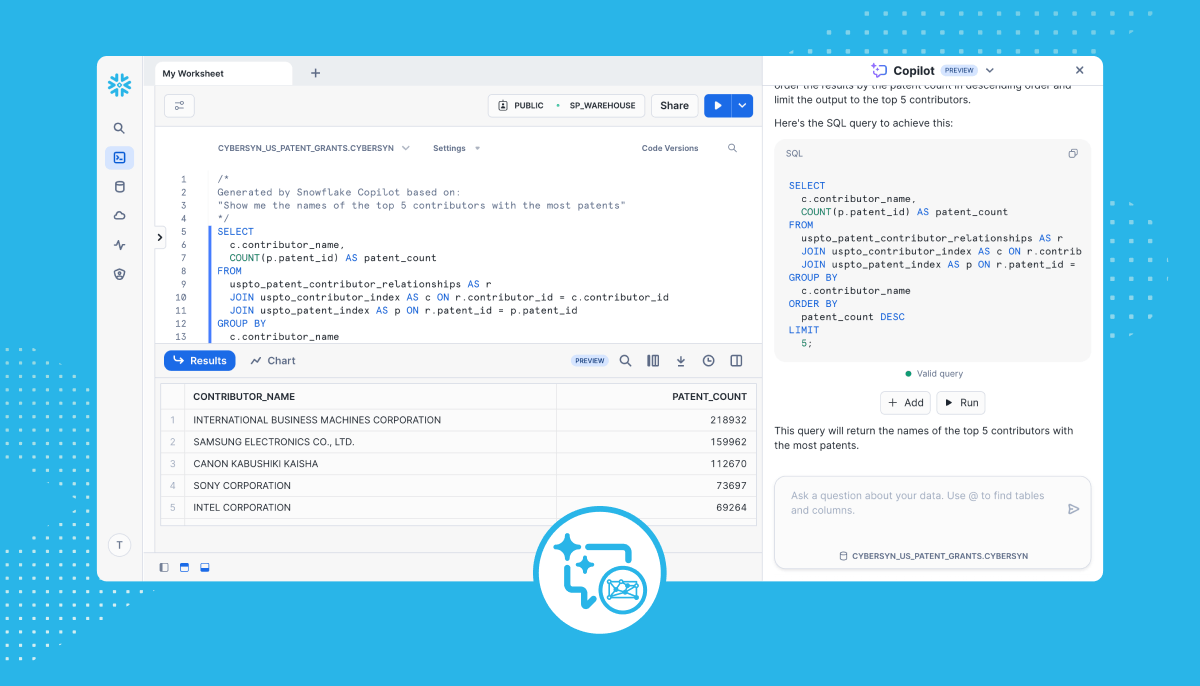
図: Snowflake Copilot のユーザーインターフェース [出典: Snowflake公式ブログ]
Snowflake Copilotは、AIを活用したSQLアシスタントです。主な機能は以下の通りです:
- 自然言語によるデータ分析クエリのSQL変換
- データの性質に関する質問応答
- 既存SQLクエリの最適化提案
技術的には、MistralのAIモデルとSnowflake独自のSQL生成モデルを組み合わせて実装されています。
この機能により、SQL熟練者の生産性向上が期待できます。ただし、以下の点に注意が必要です:
- 現時点では日本語未対応
- 生成されるSQLの品質や正確性の検証が必要
- 過度の依存によるSQL基礎スキル低下のリスク
日本語対応については、ユーザーからのフィードバックが重要です。積極的な利用と改善要望を通じて、日本語サポートの実現を促進したいところですね。
Snowsight Dark mode:目に優しく
図: ダークモードの実際の画面
SnowflakeのWebUIであるSnowsightがとうとうダークモードがリリースされました。
個人的に、眩しい画面が苦手だったので、地味に嬉しいリリースでした。
Snowflake Notebooks:統合分析環境の実現
公式記事: Snowpark ML、Snowflake Notebooks、Snowflake特徴量ストアを使用してMLを簡単に構築、展開
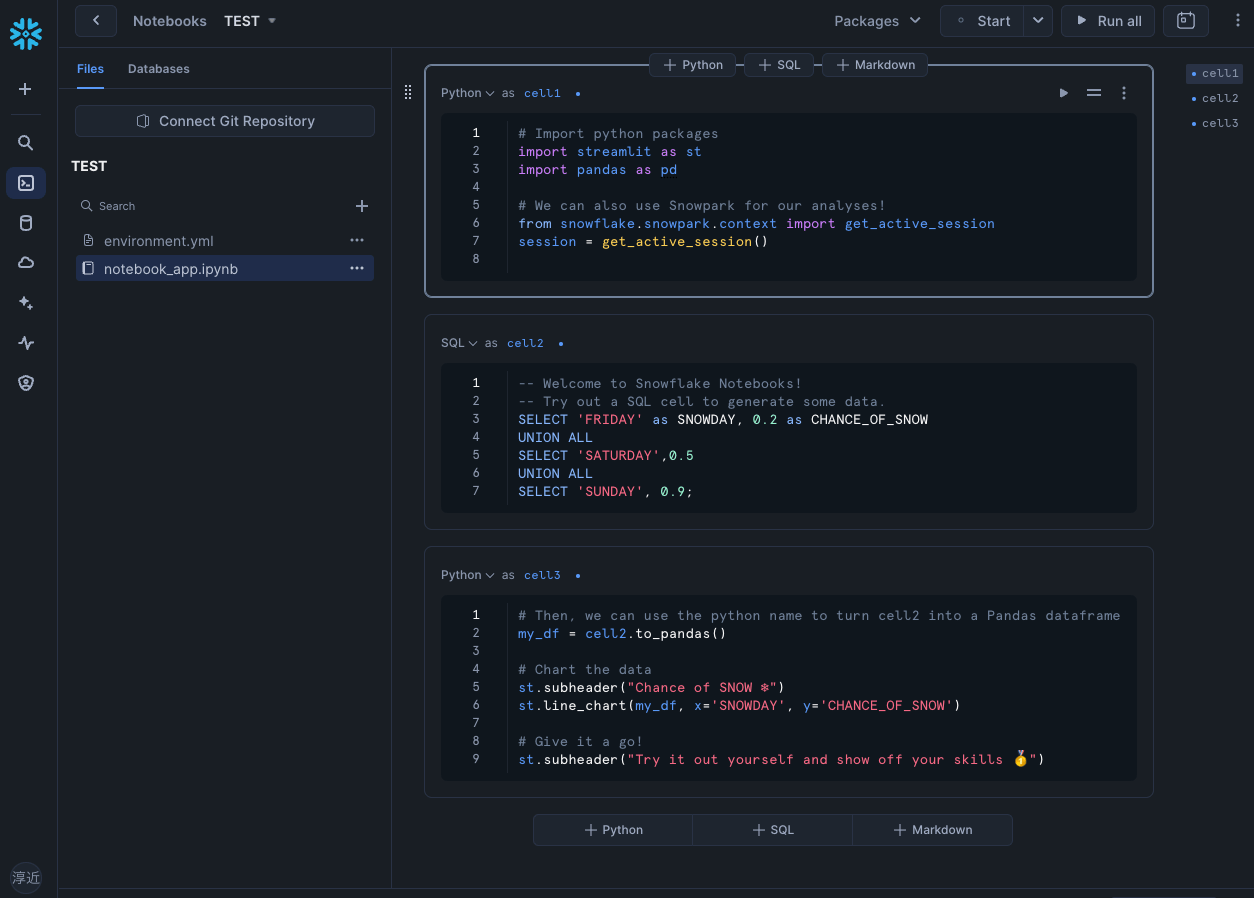
図: Notebookの実際の画面
Snowflake NotebooksはSnowflakeの新しい開発インターフェースで、SQLとPythonを使った分析環境を提供します。
Snowflakeを運用していると、「Notebookほしい」 ってN回くらい聞いた問い合わせなので、これがビルドインされるのはシンプルに嬉しかったです。
これによりデータがある場所で、特に追加の開発環境構築なしで、すぐに分析する環境が提供できるようになったので、Snowflakeで対応できるワークロードがシンプルに増えました。
地味にすごいのが、cell間をSQLとPythonが行き来できることです。
データの抽出はサクッとSQLで書いて、そこからpandasでコネコネするのはPythonといった感じの体験が実現されています。
SELECT 'FRIDAY' as SNOWDAY, 0.2 as CHANCE_OF_SNOW
UNION ALL
SELECT 'SATURDAY',0.5
UNION ALL
SELECT 'SUNDAY', 0.9;
my_df = cell2.to_pandas() # SQLの結果を取得
st.subheader("Chance of SNOW ❄️")
st.line_chart(my_df, x='SNOWDAY', y='CHANCE_OF_SNOW')
st.subheader("Try it out yourself and show off your skills 🥇")
また、スケジューリング実行も可能で、これでさくっと機械学習のバッチ学習とか組めてしまいますね。
図: スケジューリングの設定例
Database Change Management:データベース構造のコード化
Simplified End-to-End Development for Production-Ready Data Pipelines, Applications, and ML Models

図: Database Change Management (以下DCMとする) のイメージ図 [出典: Snowflake公式ブログ]
DCMは詳細情報が限られているものの、注目に値する新機能で、データベース構造の変更管理を効率化することを目的としています。
Snowflakeオブジェクトの変更を宣言的に管理し、GitリポジトリやSnowflakeのステージから直接変更を管理できるようにします。つまり、オブジェクトをコードとして管理できるようになります。
例えば、DDLスクリプトをソース管理に保存すると、Snowflakeが自動的に必要な変更(作成、変更、実行)を適用します。これにより、サードパーティツールやオブジェクトの状態管理のための複雑な仕組みが不要になる可能性があります。
DCMが登場することで、Hybrid tableの運用は劇的に便利になりそうだなと感じています。 従来の行指向データベースでDDLの運用をする場合、Flywayなどのマイグレーションツールが使用されますが、これらはツールの性質上、現在を示すものではありません。なぜならあくまで移行スクリプトを並べてるだけだからです。
一方のDCMは、あるべき状態を宣言的に記述でき、現在のDDL状態がコードで明確に示されるため、運用面で大きな利点となりそうです。
恐らく他にも便利になる場面が考えられそうですが、詳細を座して待ちましょう。
※Terraform x Snowflakeとの棲み分けは色んな現場で議論になりそうですが、詳細がまだわからないので、ここでは割愛します。
2. セキュリティの強化
Trust Center:業界標準ベストプラクティスを自動チェック
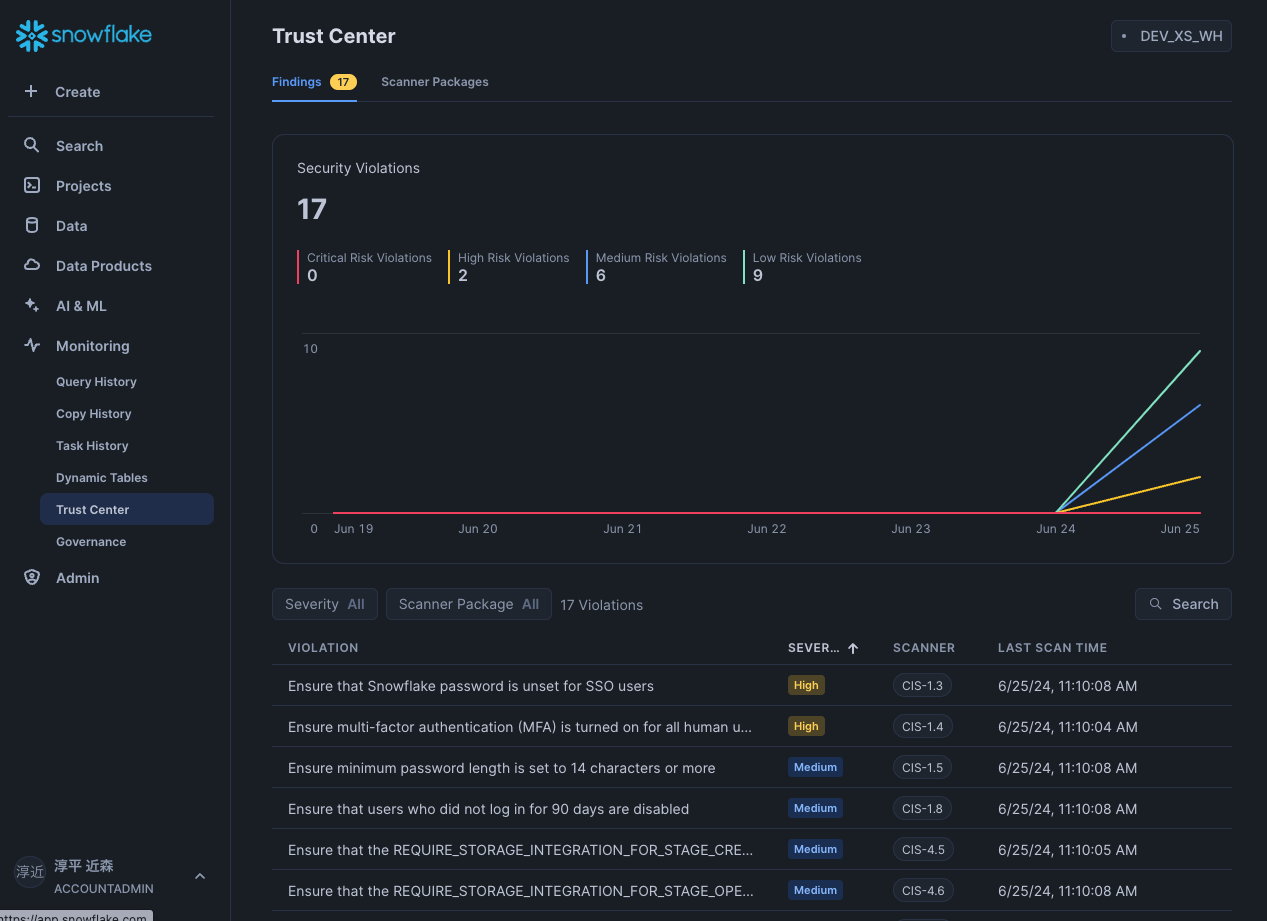
図:Trust Centerの画面
Trust Centerは、Snowflakeが提供する包括的なセキュリティ管理ツールです。
このツールは、アカウントのセキュリティリスクを継続的に評価・監視する機能を提供します。
具体的には、CIS(Center for Internet Security)ベンチマークに基づいてアカウントの設定が業界標準のベストプラクティスに沿っているかを確認してくれます。
ちなみに、CIS Benchmark は公開されているので、どういう項目がチェックされるのかは資料を見れば確認できます。個人的にはとりあえず動かしてみるのがおすすめです。
Trust Centerはまさに、「欲しかったやつ!!!!!!!!」って感じですよね。
私も既に試しましたが、これを入れることで機械的に不適切な設定を検知、または未然に防げるので、これからSnowflakeを導入する人は最初から入れるのをおすすめします。
3. オブザーバビリティの向上
Snowflake Trail:オブザーバビリティ強化の動き
公式記事: Snowflakeにおける可観測性:Snowflake Trailによる新時代
Snowflake Trailは、メトリクス、ログ、分散トレースなど、多様なテレメトリシグナルを提供します。
さらに、業界標準のOpenTelemetry仕様に準拠しているため、Datadog、などの外部ツールとの統合も容易です。これにより、ユーザーは既存のワークフローに統合することが可能になります。
現状、Snowparkをたくさん使っているようなユースケースに特化した内容で、これまでより圧倒的に監視がしやすくなるのではないでしょうか。
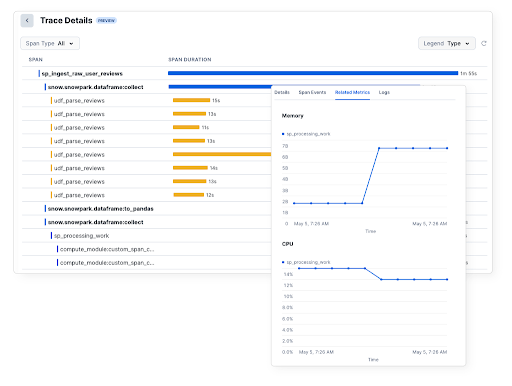
図: Snowparkにおける分散型トレースの可視化例 [出典: Snowflake公式ブログ]
これは私の妄想ですが、様々なメトリクスが、Snowflake Trailを通じて、サードパーティのツールと連携できるような世界観になってくるのでは?と思っていたりするので、めちゃくちゃ期待しています。
4. AI機能の強化
Snowflake Cortex:エンタープライズAIの進化
Snowflake Cortexが大幅にパワーアップされました。ちょっと前はそんなに色々できる認識ではなかったのですが、今回のSUMMITで、その全貌が明らかになりました。
- Cortex Analyst: 自然言語でデータにアクセスできる機能。
- Cortex Search: ベクトル検索機能。
- Cortexファインチューニング: LLMを特定のタスクに合わせてカスタマイズする機能。
- Cortex Guard: AIモデルの出力における有害コンテンツをフィルタリングする安全機能。
- etc...
AI周りの強化は相当盛りだくさんなので、ここをキャッチアップしてるだけで一苦労です。
今回はその中でも注目度の高いRAGについて、少しだけ触れます。
RAGフレームワーク
Easy and Secure LLM Inference and Retrieval Augmented Generation (RAG) Using Snowflake Cortex
Snowflake Cortexは出来ることがかなり多岐に渡るのですが、例えば、RAG(以下Retrieval Augmented Generation)の実装がSnowflake上だけで完結できます。
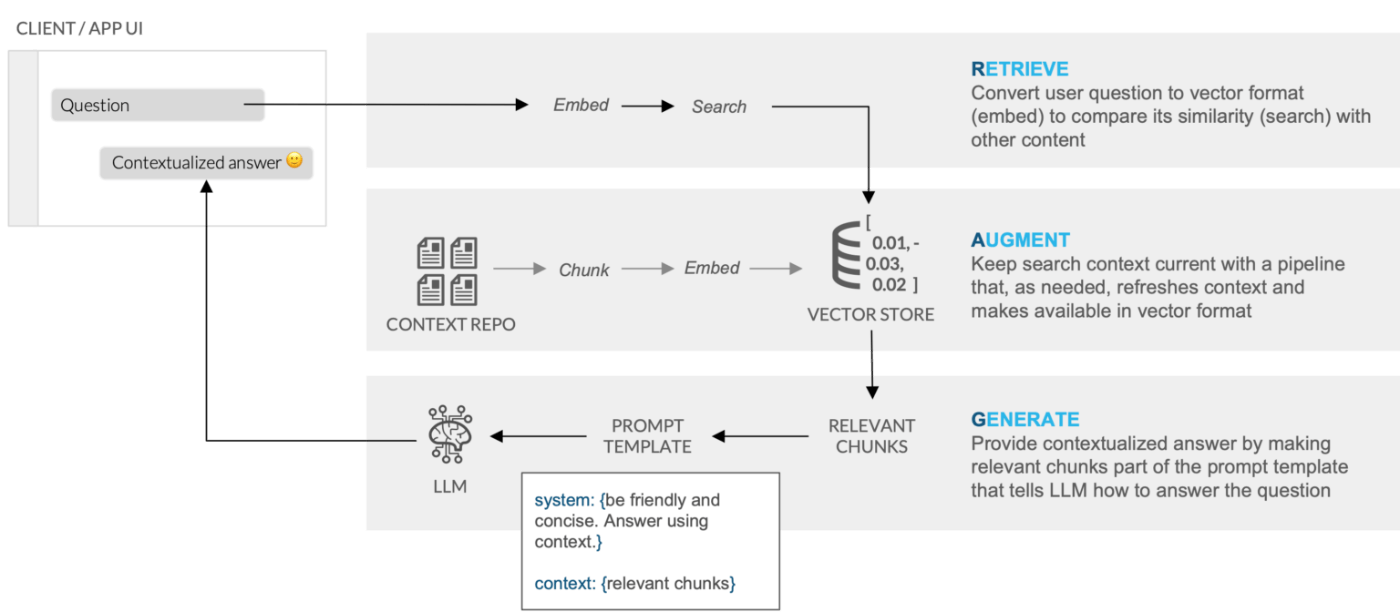
図: RAGのプロセスフロー [出典: Snowflake公式ブログ]
RAGを知らない人向けに簡単に説明すると、例えば社内のドキュメントを学習させた上で、社内特有の知識を踏まえて、回答できるようなものです。
詳細な挙動は次の通りです。
- 検索(Retrieve)
- ユーザーの質問をベクトル形式に変換(Embed)。
- 変換された質問ベクトルを使って類似度検索(Search)を実行。
- 補完(Augment)
- コンテキストリポジトリ(Context Repo)内のドキュメントを小さな塊(Chunk)に分割。
- 各塊をベクトル化し、ベクトルストア(Vector Store/Data)に格納。
- 検索結果に基づいて関連する塊(Relevant Chunks)を取得。
- 生成(Generate):補完された情報をもとに、LLMが文脈に即した回答を生成します。
- 関連する塊をプロンプトテンプレートに組み込む。
- テンプレートとユーザーの質問をLLMに入力。
- LLMがコンテキストを考慮した回答を生成。
RAGを構築するのは、見ての通り、結構いろいろなものが必要です。それがSnowflake Cortexの機能拡充により、SnowflakeだけでRAGが構築可能になりました。
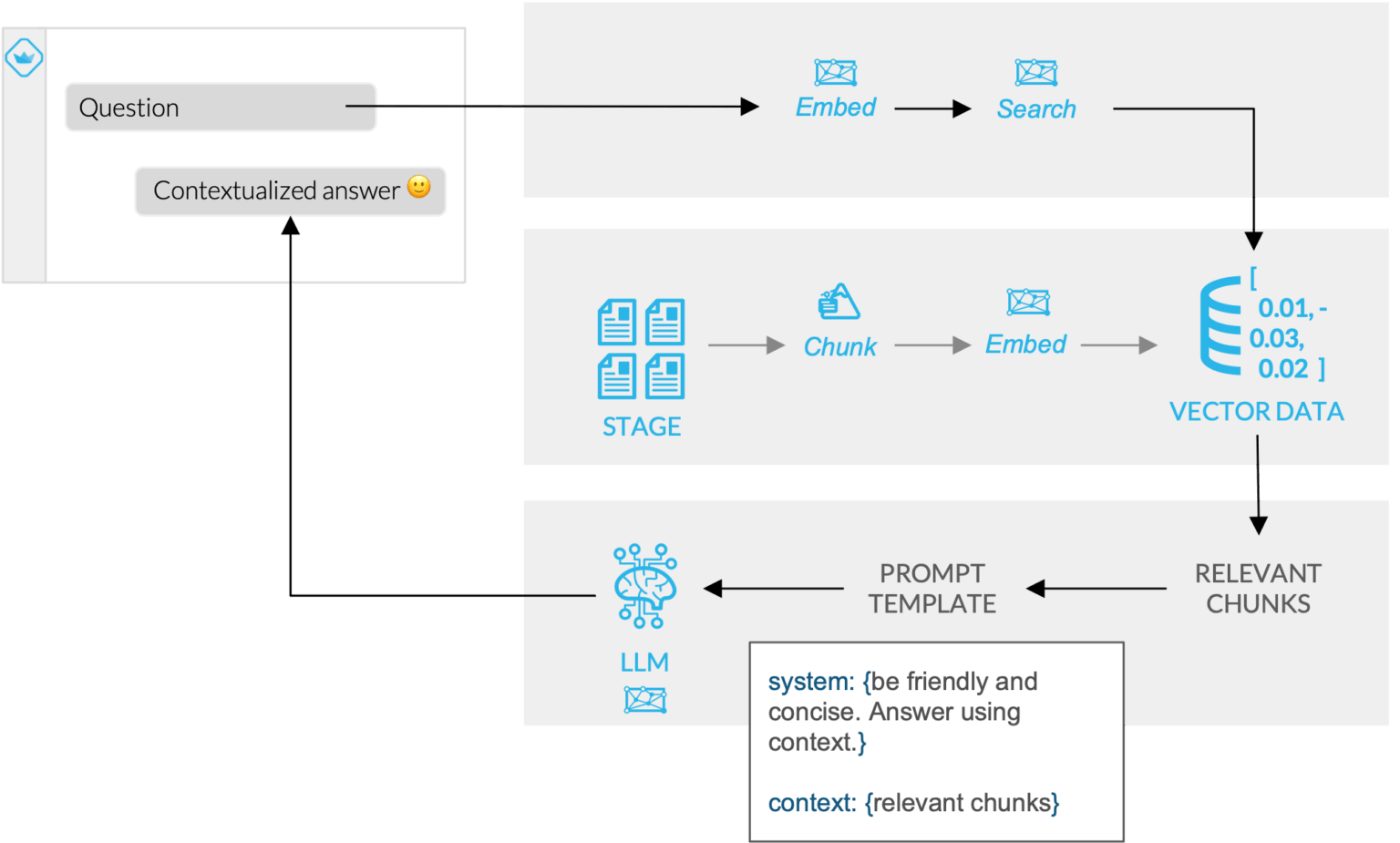
図: Snowflake CortexにおけるRAG実装 [出典: Snowflake公式ブログ]
上記の図の通り、全てのパーツがSnowflake上の機能で実現が可能になったのことで、データを外に持ち出さずにRAGが構築可能になりました。
ちなみに標準で用意された方法で、日本語データをチャンク化することは可能ですが、精度に課題がありそうなので、使い方は工夫する必要がありそうです
5. パフォーマンスの改善
Snowflake Performance Indexの27%向上
公式記事: Snowflakeパフォーマンス指数によると、パフォーマンスが27%向上
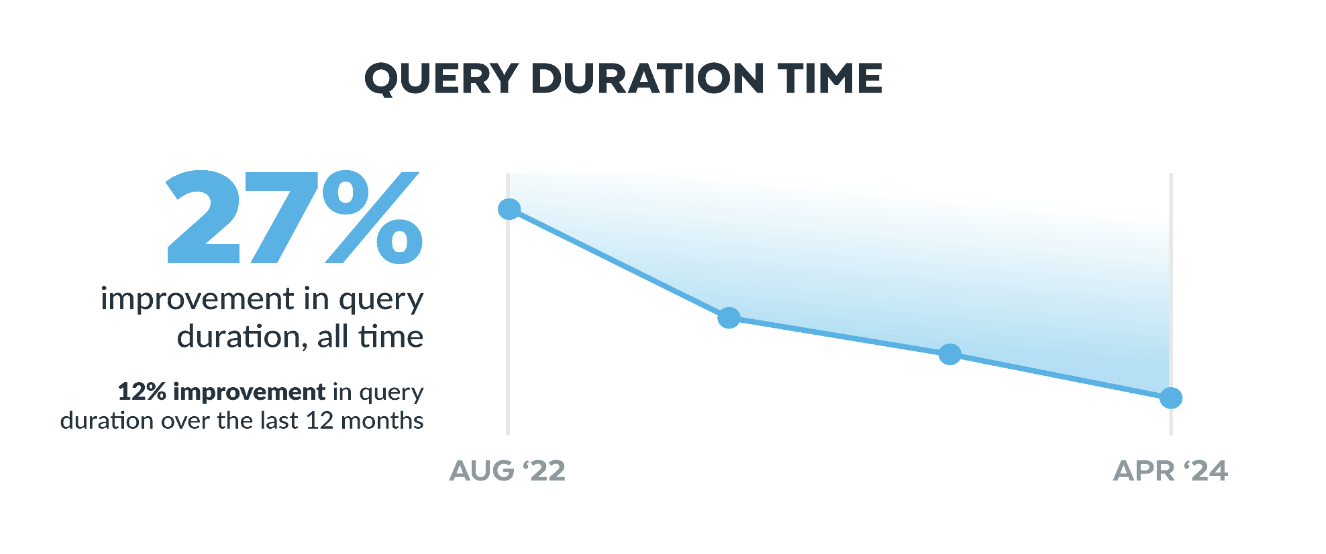
図: Snowflake Performance Indexの年次改善推移 [出典: Snowflake公式ブログ]
Snowflakeは年々パフォーマンスが改善されています。今年もなんと27%も改善されます。これはSnowflakeの課金モデル的に、利用者の支払うコストも下がっていることを意味します。
具体的に行われたチューニング項目としては、データの取り込み速度の向上、クエリ実行の最適化、マテリアライズドビューの維持コスト削減など、その他、幅広い面で改善が行われている様です。
個人的には、この改善の動きを単なるコスト削減の機会としてだけでなく、より高度なデータ活用を推進するチャンスとして捉えて、もっとデータ活用を推進したいところです。 そうすることで、真に双方がWin-Winの関係になれるはず・・・!
まとめ
Snowflake SUMMIT 2024では、多くの機能が発表されました。もちろん、この記事では触れていないものも含めると非常に盛りだくさんでした。
これらの機能は、データエンジニアの日々の業務を大きく変える可能性を秘めています。特に、AIとの融合やセキュリティ強化は、今後のデータ基盤構築において重要な要素となるでしょう。
一方で、AIの活用には質の高いデータが不可欠です。データエンジニアとして、これらの新機能を効果的に活用しつつ、基礎となるデータの品質向上にも注力することが重要と考えます。
Snowflakeの進化は急速であり、これからもデータエンジニアリングの世界に大きな変革をもたらすことでしょう。
最後に。
「Snowflake進化早すぎぃいぃぃぃ!!!!」

Snowflake データクラウドのユーザ会 SnowVillage のメンバーで運営しています。 Publication参加方法はこちらをご参照ください。 zenn.dev/dataheroes/articles/db5da0959b4bdd
Discussion