データエンジニアのkoreedaです。
Frosty Fridayに出演する機会を頂きました。私が今回チャレンジする問題は、Week 69です。
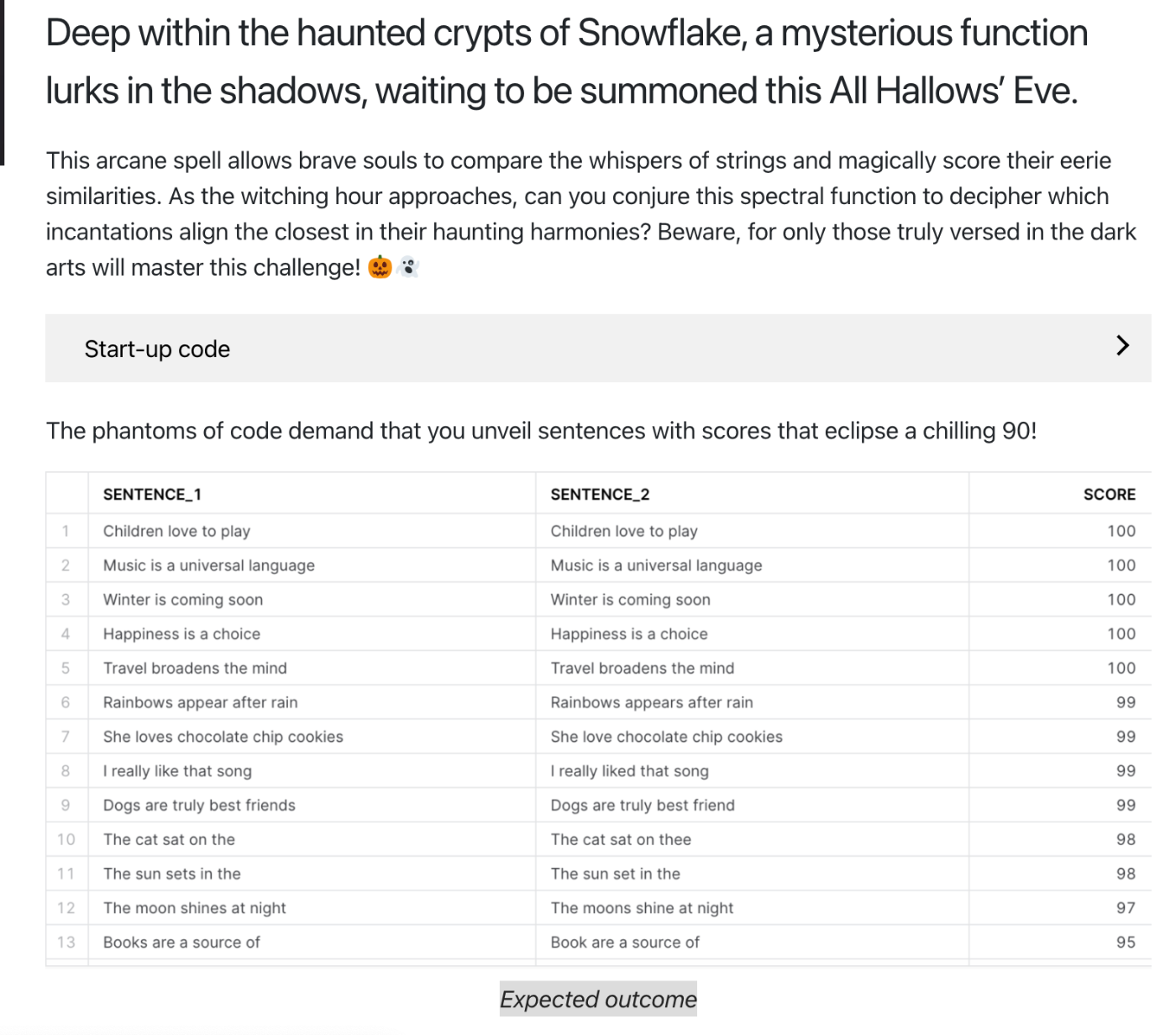
問題の趣旨を簡単に説明すると、「2つのカラムの文章の類似度をスコアで表してください」というところに集約するかと思います。文章の類似度を測る方法は、昨今のベクトル検索などでもトレンドな技術領域で様々な解法が考えられます。色々な実装パターンにチャレンジしてみたのでまとめてみます。
前準備
前準備
CREATE OR REPLACE TABLE sentence_comparison(sentence_1 VARCHAR, sentence_2 VARCHAR);
INSERT INTO sentence_comparison (sentence_1, sentence_2) VALUES
('The cat sat on the', 'The cat sat on thee'),
('Rainbows appear after rain', 'Rainbows appears after rain'),
('She loves chocolate chip cookies', 'She love chocolate chip cookies'),
('Birds fly high in the', 'Birds flies high in the'),
('The sun sets in the', 'The sun set in the'),
('I really like that song', 'I really liked that song'),
('Dogs are truly best friends', 'Dogs are truly best friend'),
('Books are a source of', 'Book are a source of'),
('The moon shines at night', 'The moons shine at night'),
('Walking is good for health', 'Walking is good for the health'),
('Children love to play', 'Children love to play'),
('Music is a universal language', 'Music is a universal language'),
('Winter is coming soon', 'Winter is coming soon'),
('Happiness is a choice', 'Happiness is a choice'),
('Travel broadens the mind', 'Travel broadens the mind'),
('Dogs are our closest companions', 'Cats are solitary creatures'),
('Books are portals to new worlds', 'Movies depict various realities'),
('The moon shines brightly at night', 'The sun blazes hotly at noon'),
('Walking is beneficial for health', 'Running can be hard on knees'),
('Children love to play outside', 'Children love to play'),
('Music transcends cultural boundaries', 'Music is a universal language'),
('Winter is cold and snowy', 'Winter is coming soon'),
('Happiness comes from within', 'Happiness is a choice'),
('Traveling opens up perspectives', 'Travel broadens the mind');
select * from sentence_comparison;
こんなイメージでデータができれば成功です。
Snowflake類似度関数の概要
類似度の比較という文脈に置いて、文字列ベースの類似度判定と文章の意味的類似度の2軸が存在します。
文章同士を直接文字列として比較する手法として、Snowflake標準関数にはJAROWINKLER_SIMILARITY(ジャロ・ウィンクラー類似度)とEDITDISTANCE(レーベンシュタイン距離)があります。これらは文中のスペルや表記の違いを検出するのに適しており、短いテキストや単語レベルの比較に向いています。一方で、文章の意味的類似度にはAI_EMBED関数やai_similarity関数といったベクトル検索技術を活用します。
1. 文字列ベースの類似度判定手法
JAROWINKLER_SIMILARITY (ジャロ・ウィンクラー類似度)
FF week69 の解答にはJAROWINKLER_SIMILARITY関数を使います。
2つの文字列間の類似度を0~100の整数値で返す関数です。100が完全一致、0が全く共通部分が無いことを意味します。大文字・小文字は区別せず比較されますが、空白や句読点など文字上の差異はスコアに影響します。
ジャロ・ウィンクラー距離については下記が詳しかったです。ここでは詳細なロジックの解説は割愛します。
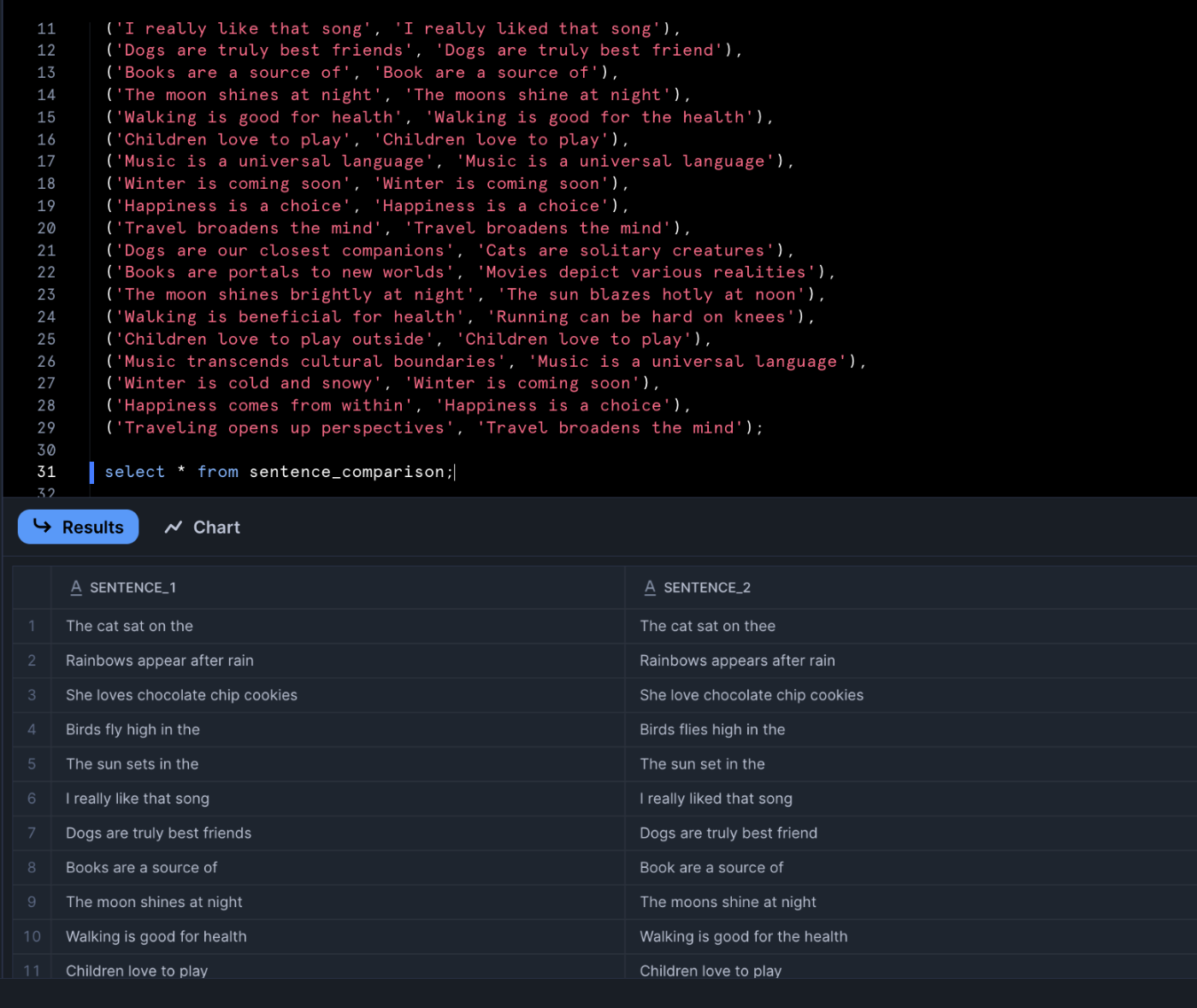
JAROWINKLER_SIMILARITY関数を用いた解法は以下になります。
select sentence_1, sentence_2, JAROWINKLER_SIMILARITY(sentence_1, sentence_2) as score
from sentence_comparison
order by score desc;

Frosty Friday week69 解答
JAROWINKLER_SIMILARITY関数は句読点や余分な空白が異なるだけでもスコアが下がります。
CREATE OR REPLACE TABLE sentence_comparison_1(sentence_1 VARCHAR, sentence_2 VARCHAR);
INSERT INTO sentence_comparison_1 (sentence_1, sentence_2) VALUES
('The cat sat on the tree.', 'The cat sat on the tree');
select
sentence_1,
sentence_2,
jarowinkler_similarity(sentence_1, sentence_2) as semantic_score
from sentence_comparison_1;
この通り、「.」が含まれるか含まれないかだけでスコアが99になりました。

上記のように、スペルが1文字違う程度であれば90以上のスコアがでます。
JAROWINKLER_SIMILARITYは計算量も比較的小さく、短い文字列同士なら文字数の積に比例し高速に動作します。不要な記号類は事前に除去するといった前処理が必要になります。また長い文章や語順の大きく異なる文章同士では意味を捉えられない点に注意が必要です。
EDITDISTANCE (レーベンシュタイン距離)
こちらは解答ではないのですが、文字列ベースの類似度判定手法として紹介します。
EDITDISTANCE関数は2つの文字列間のレーベンシュタイン距離(編集距離)を返す関数です。これは一方の文字列を他方に変換するのに必要な挿入・削除・置換の最小回数で表され、数値が小さいほど類似していることを意味します。
SELECT
EDITDISTANCE('She loves chocolate chip cookies', 'She loves chocolate chip cookies') as semantic_score_1,
EDITDISTANCE('She loves chocolate chip cookies', 'She love chocolate chip cookies') as semantic_score_2
;
semantic_score_1は完全一致、semantic_score_2は一文字削除("loves"→"love")を行った結果です。semantic_score_2は1と表示されます。

このように差分の絶対量が直感的に得られるため、何文字違うかを正確に知りたい場合に有用です。
さっきの例だとこのような結果になります。
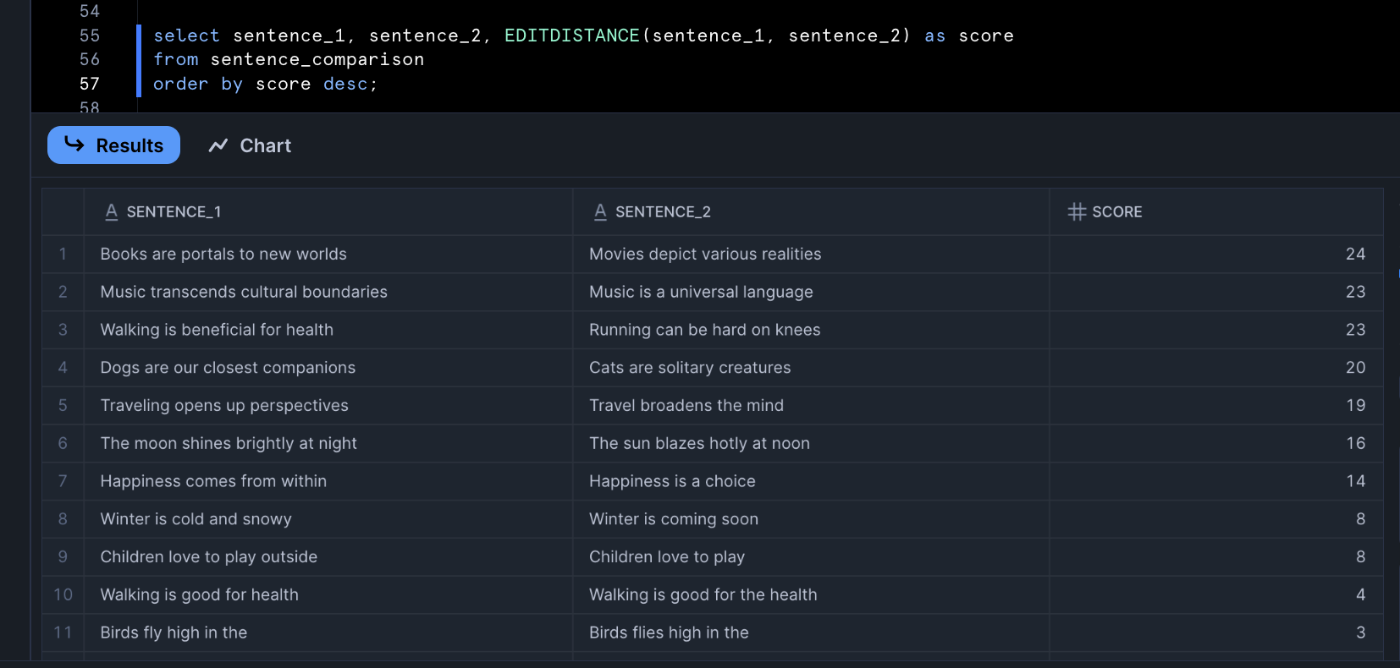
▶ 使い分けのポイント
短い文字列(氏名や商品コードなど)のあいまい比較にはJAROWINKLER_SIMILARITYやEDITDISTANCEが活用され、特に転置や一部欠損を含む場合はJaro-Winklerのほうが高い類似度を示します。一方、どれだけ異なるかの絶対量を重視するならEDITDISTANCEが有用です。
2. 埋め込みベースの意味的類似度手法
AI_EMBED関数
FF week69はなにの類似度を測るのかという定義がなく、文章の類似度で90 点を超えるスコアで文章を明らかにすることを要求されています。(Expected outcome で答えの画像が示されていますが、一旦気にしないことにします。)
類似度を測るといえばベクトル検索技術が今風で有効だと思いますが、文章の「意味的な近さ」を測るには、単語の表面上の一致ではなく文意をベクトル表現に埋め込んで比較する方法が有効です。Snowflakeは、AISQLによりテキストの埋め込みベクトル生成や類似度計算をSQL関数でサポートしています。
用意されているデータセットは文章の意味も類似しているため、意味的な近さのベクトル検索でも今回の解答となります。実装例を示します。
WITH emb AS (
SELECT
sentence_1,
sentence_2,
AI_EMBED('snowflake-arctic-embed-l-v2.0', sentence_1) AS v1,
AI_EMBED('snowflake-arctic-embed-l-v2.0', sentence_2) AS v2
FROM sentence_comparison
)
SELECT
sentence_1,
sentence_2,
CAST(ROUND(VECTOR_COSINE_SIMILARITY(v1, v2) * 100, 0) AS INT) AS VECTOR_COSINE_SIMILARITY
FROM emb
ORDER BY VECTOR_COSINE_SIMILARITY DESC;

AI_EMBED関数を用いたFrosty Friday week69 別解1
AI_EMBED関数でテキストから特徴ベクトルを取得できます。埋め込み(Embedding)とはテキストや画像の特徴を捉えた数値ベクトルで、類似度計算やクラスタリングに利用できます。埋め込みベクトル同士の類似度計算にはコサイン類似度が使われ、Snowflakeではベクトル型に対してVECTOR_COSINE_SIMILARITY関数にて類似度を定量します。
ベクトル類似性を測るものとしてVECTOR_COSINE_SIMILARITY関数以外にも、
- タクシー距離やマンハッタン距離をベースとしたVECTOR_L1_DISTANCE関数
- ユークリッド距離をベースとしたVECTOR_L2_DISTANCE関数
があるので、興味がある方は公式ドキュメントのベクトル類似関数ページを御覧ください。
※Embedding 関数について菅野 翼さんの記事を参考にさせていただきました。
AI_SIMILARITYによる直接比較
個別に埋め込みを扱わずシンプルに2つの文章の類似度スコアだけが欲しい場合、AI_SIMILARITY(input1, input2)関数が便利です。これは内部で両方の入力を埋め込みベクトルに変換し、そのコサイン類似度に基づくスコアを直接返す関数です。テキスト同士の場合、デフォルトでsnowflake-arctic-embed-l-v2モデルが使われ、-1~1の範囲の浮動小数点値が返却されます。実装例を示します。
select
sentence_1,
sentence_2,
CAST(ROUND(ai_similarity(sentence_1, sentence_2) * 100, 0) AS INT) AS ai_similarity,
from sentence_comparison
ORDER BY ai_similarity DESC;

ai_similarity関数を用いたFrosty Friday week69 別解2
AI_EMBED関数と比べて、ベクトル化の処理を加えずに一発で類似度を測ることができます。
このように埋め込みベースの類似度は言い回しや語順、表記揺れに影響されにくく、文の意味的な近さを定量化できます。値が1に近ければ内容がほぼ同義であり、0に近ければ関連性が薄いことを示します。従来の文字列類似度と異なり、同義語や言い換えにも高スコアを与える点が大きなメリットです。
3. 2つ以上のセットの類似性の推定
Jaccard類似性係数という2つのセット間の類似性を比較する方法も存在します。MinHash関数を使用して、2つ以上のデータセット間のおおよその類似性を推定できます。実装例は下記です。
-- 1) 行に番号をふる(ペアID)
WITH pairs AS (
SELECT ROW_NUMBER() OVER (ORDER BY (SELECT NULL)) AS pair_id, sentence_1, sentence_2
FROM sentence_comparison
),
-- 2) 前処理(小文字化 & 句読点除去)
clean AS (
SELECT
pair_id,
LOWER(REGEXP_REPLACE(sentence_1, '[^\\w\\s]', '')) AS s1,
LOWER(REGEXP_REPLACE(sentence_2, '[^\\w\\s]', '')) AS s2
FROM pairs
),
-- 3) 単語に分割(それぞれ“集合”化の前段)
tokens AS (
SELECT pair_id, 's1' AS side, t.value::string AS token
FROM clean, LATERAL FLATTEN(input => SPLIT(s1, ' ')) t
WHERE t.value IS NOT NULL AND t.value <> ''
UNION ALL
SELECT pair_id, 's2' AS side, t.value::string AS token
FROM clean, LATERAL FLATTEN(input => SPLIT(s2, ' ')) t
WHERE t.value IS NOT NULL AND t.value <> ''
),
-- 4) 各文章ごと(pair_id×side)に MinHash 署名を作成
sketch AS (
SELECT
pair_id,
side,
MINHASH(100, token) AS mh -- k=100(精度↑なら200,256など)
FROM tokens
GROUP BY pair_id, side
)
-- 5) 同じ pair_id の2つの署名を集約して近似Jaccardを算出
SELECT
p.sentence_1,
p.sentence_2,
APPROXIMATE_JACCARD_INDEX(mh)*100 AS jaccard_sim
FROM sketch
JOIN pairs p USING (pair_id)
GROUP BY p.sentence_1, p.sentence_2, pair_id
ORDER BY jaccard_sim DESC;
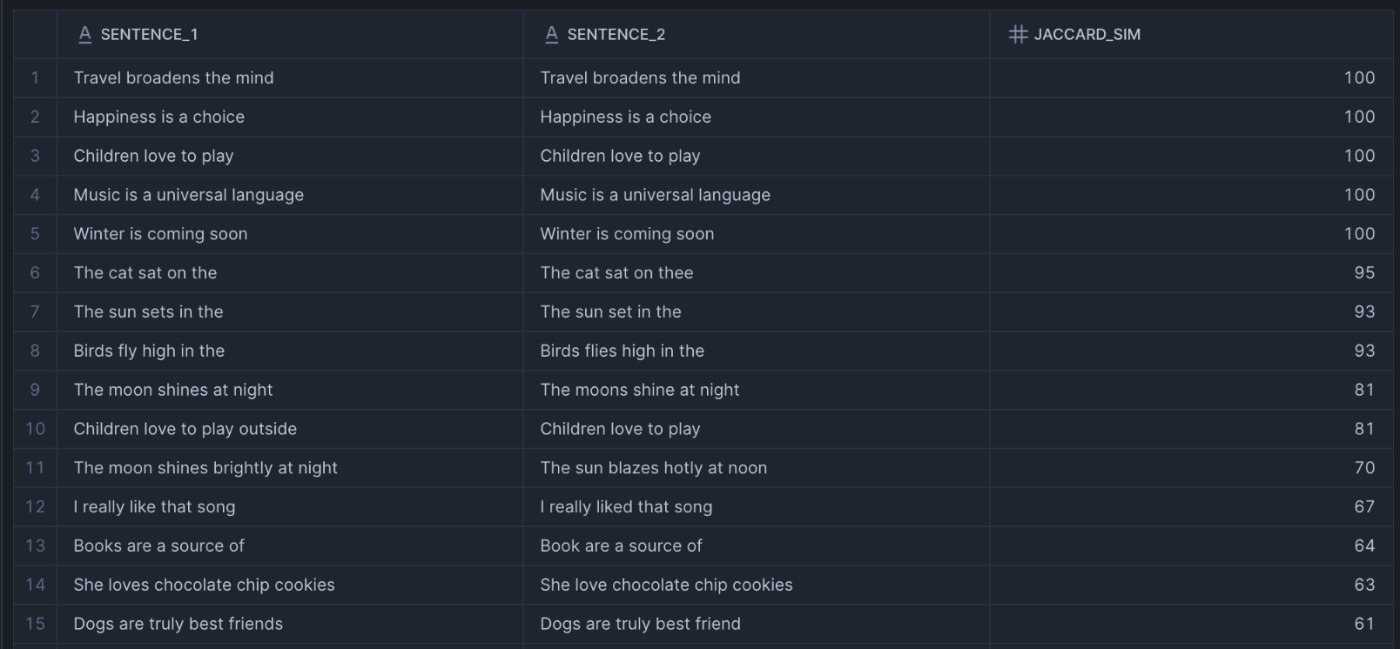
Minhash関数の結果 Frosty Friday week69 別解3
このクエリでは、MinHashを使って2つの文章の近似Jaccard類似度を計算しています。処理の流れは以下の通りです。
- 前処理: 文章を小文字化し、句読点を除去
- トークン化: 文章を単語に分割して集合化
- MinHash署名作成: 各文章に対してMinHash署名を生成(k=100)
-
近似Jaccard計算:
APPROXIMATE_JACCARD_INDEXで類似度を算出
MinHashの利点は、大規模なテキストデータでも高速処理が可能なことです。完全なJaccard係数の計算はO(n²)の時間がかかりますが、MinHashを使えばO(k)(kは署名サイズ)で近似値を求められます。
特に語順が異なる文章(例:「I like SQL」vs「SQL I like」)でも高い類似度を検出できるため、文章の意味的な類似性を判定したい場合に有効です。
手法比較
以上の手法をスコアの範囲・解釈、メリット・注意点の観点でまとめます。
| 類似度手法 | Snowflake関数 | スコアの範囲 | 意味・解釈【※1】 | メリット【※2】 | 注意点・適用例【※3】 |
|---|---|---|---|---|---|
| ジャロ・ウィンクラー類似度 | JAROWINKLER_SIMILARITY(s, t) |
0 ~ 100 (整数値) | 100=完全一致、0=共通部分なし。 大文字小文字は無視(case-insensitive) |
軽微なタイポ・転置に強い 例: “ootaka” vs “ootaki” → 93 |
空白や句読点の差もスコア低下要因 長文や語順違いには不向き |
| レーベンシュタイン距離 | EDITDISTANCE(s, t) |
0 ~ max(len) | 0=完全一致、値が大きいほど差異大。 文字列長に依存(非正規化) |
差分の絶対量が把握可能 例: “playing” vs “play” → 3 (ing削除) |
スケール不定で閾値設定が必要 転置を単一操作とみなさない |
| 埋め込みコサイン類似度 |
AI_SIMILARITY(s, t)(または AI_EMBED→VECTOR_COSINE_SIMILARITY) |
-1 ~ 1 (実数値) | 1=意味が等しい、0=意味的に無関係。 ※通常0~1で評価 |
文の意味を比較可能(言い換え検出) 例: “fast” vs “quick” → 高スコア |
AIモデル推論コストあり 結果の説明性が低い(ブラックボックス) |
| MinHash(近似Jaccard) |
MINHASH(...) + APPROXIMATE_JACCARD_INDEX(...)
|
0 ~ 1 (実数値) | 1=集合が完全一致、0=共通要素なし | 大規模テキスト比較に効率的 例: "I like SQL" vs "SQL I like" → 1.0 |
近似なので完全一致では誤差あり n-gram/単語分割前処理が必要 |
各手法の特徴を踏まえた使い分けの指針をまとめると、
-
文字列の表記ゆれ検出 → JAROWINKLER_SIMILARITY
- 顧客名、住所、商品名の重複排除に最適
-
編集コストの定量化 → EDITDISTANCE
- データ品質チェックや差分の具体的把握に有効
-
意味的類似性の判定 → AI_SIMILARITY
- 検索機能、レコメンデーション、FAQ自動応答に活用
-
大規模テキスト比較 → MinHash + APPROXIMATE_JACCARD_INDEX
- 重複文書検出、類似記事発見、大量テキストの前処理に最適
適切な手法を選択することで、データクレンジングの精度と効率を大幅に向上させることができます。
終わりに
いかがだったでしょうか?
今回は、Snowflakeの類似度関数を紹介しました。文字列ベースや意味ベースで使い分けられると良いでしょう。個人的に文字列ベースはdbt testなどデータ品質の確認で活用し、文意ベースだとユーザー検索やレコメンデーション機能などで威力を発揮すると感じています。AI_SIMILARITY関数に至っては、昨今のSnowflakeが提唱するSimplicityを体現する関数だなと感じました。
最後まで読んでいただき、ありがとうございました!

Snowflake データクラウドのユーザ会 SnowVillage のメンバーで運営しています。 Publication参加方法はこちらをご参照ください。 zenn.dev/dataheroes/articles/db5da0959b4bdd
Discussion