データエンジニアのkoreedaです。
先日、SnowflakeでDuckDBとArrowフォーマットの活用についてのMedium記事を読んでいました。
ADBCは、Apache Arrowの列指向フォーマットを活用した次世代のデータベース接続インターフェースです。従来の接続方式とは異なり、列形式のままネットワーク転送され、変換コストが発生せず高速にデータを扱うことができます。列指向データベースと列指向フォーマットの普及により、この技術的優位性はますます重要になっています。
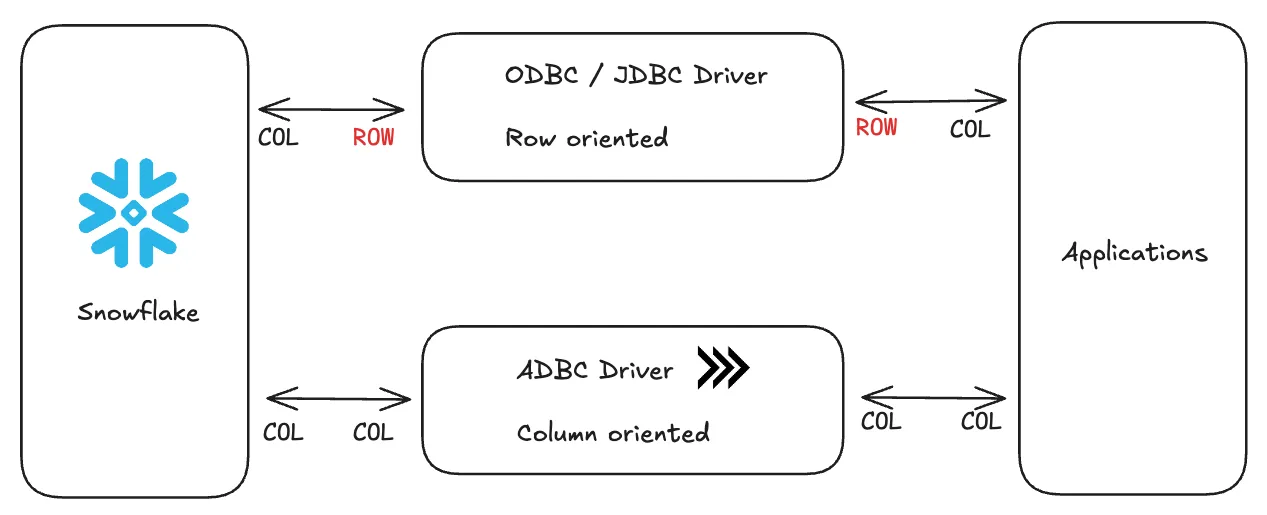
Cut Costs by Querying Snowflake Tables in DuckDB with Apache Arrow より引用
DuckDBのベンチマークによれば、ADBCは従来の接続方式より最大38倍高速にデータ転送できることが示されています。
個人的にRをよく使う機会があり、ローカルのRStudio環境からSnowflakeにADBCでクエリできれば解析メリットが大きく得られます。そこで、ADBCを使用してSnowflakeのデータを分析する方法を試してみようと思います。
ADBCとArrowフォーマットの技術的優位性
ADBC は、Apache Arrow の列指向フォーマットを活用した次世代のデータベース接続インターフェースであり、R と Snowflake の連携において高い性能を発揮します。
従来のような 行形式への変換やシリアル化のオーバーヘッドを排除し、列形式のままゼロコピー転送することで、高速かつ効率的なデータ処理が可能になります。さらに、SIMD に最適化された並列処理により、R のベクトル操作との相乗効果で分析速度が向上します。
R との統合も自然で、dplyr に完全対応し、型の互換性や遅延評価もそのまま活用できます。Snowflake との組み合わせでは、内部ストレージ形式との整合性により、クエリ結果の取り込みが圧倒的に高速化され、クラウド環境での大規模データ処理を強力に支援します。
ADBC は、R、Python、Java など多言語間での相互運用性も備えており、再現性と拡張性に優れたデータ分析基盤を提供します。
1. RStudio環境でのADBC設定
renvを使った再現可能な環境構築
プロジェクトの再現性を確保するため、renvを使用して環境を構築します。
# renvのインストール(初回のみ)
if (!requireNamespace("renv", quietly = TRUE)) {
install.packages("renv")
}
# プロジェクトの初期化
renv::init()
# 必要なパッケージのインストール
renv::install(c(
"adbcdrivermanager", # ADBCドライバー管理用
"arrow", # Arrowフォーマット用
"dplyr", # データ加工用
"DBI" # データベース接続用
))
# Snowflake用のADBCドライバー
renv::install("apache/arrow-adbc/r/adbcsnowflake", repos = "https://community.r-multiverse.org")
# 依存関係のスナップショットを作成
renv::snapshot()
Snowflakeでのデータ準備
まず、分析用のデータをSnowflakeに用意します。
-- データベースとスキーマの作成
CREATE DATABASE IF NOT EXISTS demo_db;
USE DATABASE demo_db;
CREATE SCHEMA IF NOT EXISTS analysis;
USE SCHEMA analysis;
-- サンプルデータの作成
CREATE OR REPLACE TABLE sales_data (
sale_id NUMBER AUTOINCREMENT,
sale_date TIMESTAMP_NTZ,
customer_id VARCHAR,
product_id VARCHAR,
category VARCHAR,
amount DECIMAL(10,2),
quantity INTEGER
);
-- サンプルデータの投入
INSERT INTO sales_data (sale_date, customer_id, product_id, category, amount, quantity)
SELECT
DATEADD(minute,
uniform(1, 1000000, RANDOM()),
DATEADD(month, -6, CURRENT_TIMESTAMP())
),
'CUST_' || uniform(1, 1000, RANDOM()),
'PROD_' || uniform(1, 100, RANDOM()),
ARRAY_CONSTRUCT('A', 'B', 'C')[uniform(1, 3, RANDOM())],
uniform(100, 10000, RANDOM()) / 100,
uniform(1, 10, RANDOM())
FROM TABLE(GENERATOR(ROWCOUNT => 1000000));
-- データの確認
SELECT
TO_VARCHAR(sale_date, 'YYYY-MM') as month,
category,
COUNT(*) as record_count,
SUM(amount) as total_amount
FROM sales_data
GROUP BY 1, 2
ORDER BY 1, 2;

SnowflakeへのADBC接続設定
adbcsnowflakeドライバーを使用してSnowflakeに接続します。接続情報は環境変数で管理することをお勧めします。
library(adbcdrivermanager)
library(adbcsnowflake)
library(arrow)
library(dplyr)
# ADBC接続の確立
db <- adbc_database_init(
adbcsnowflake::adbcsnowflake(),
uri = Sys.getenv("SNOWFLAKE_URI")
)
# 接続を確立
con <- adbc_connection_init(db)
# 接続テスト
test_query <- read_adbc(
con,
"SELECT CURRENT_WAREHOUSE(), CURRENT_DATABASE(), CURRENT_SCHEMA()"
) %>% tibble::as_tibble()
print(test_query)
# > print(test_query)
# # A tibble: 1 × 3
# `CURRENT_WAREHOUSE()` `CURRENT_DATABASE()` `CURRENT_SCHEMA()`
# <chr> <chr> <chr>
# 1 COMPUTE_WH DEMO_DB ANALYSIS
SNOWFLAKE_URIは以下のような形式で設定します:
"[ユーザー名]:[password]@[アカウント名]/[database名]/[schema名]?role=[role名]&warehouse=[warehouse名]"
2. RStudioでのデータ取得と分析
先ほど取得したデータを簡単に解析してみようと思います。
# データをArrow形式で取得
sales_arrow <- read_adbc(
con,
"SELECT *
FROM sales_data
LIMIT 1000"
) %>%
arrow::as_arrow_table()
# dplyrを使った集計(Arrow形式のまま処理)
summary <- sales_arrow %>%
group_by(CATEGORY) %>%
summarise(
total_sales = sum(AMOUNT),
avg_sales = mean(AMOUNT)
) %>%
collect() # 必要な時点でR上のデータフレームに変換
print(summary)
# > print(summary)
# # A tibble: 3 × 3
# CATEGORY total_sales avg_sales
# <chr> <dbl> <dbl>
# 1 B 15369. 51.1
# 2 NA 16959. 47.8
# 3 C 17546. 51.0
確かにdplyrベースでそのまま解析ができるため、ODBCを使っていたときと特に違和感なく解析を行うことができました。可視化も挑戦してみます。
# 時系列分析
monthly_sales <- read_adbc(
con,
"SELECT
TO_VARCHAR(sale_date, 'YYYY-MM') as MONTH,
category,
SUM(amount) as TOTAL_AMOUNT,
COUNT(*) as TRANSACTION_COUNT
FROM sales_data
GROUP BY 1, 2
ORDER BY 1, 2"
) %>%
arrow::as_arrow_table() %>%
collect()
ggplot(monthly_sales, aes(x = MONTH, y = TOTAL_AMOUNT, fill = CATEGORY)) +
geom_bar(stat = "identity", position = "dodge") +
labs(title = "Monthly Sales Trend", x = "Month", y = "Sales Amount") +
theme_minimal() +
theme(axis.text.x = element_text(angle = 90, vjust = 0.5, hjust = 1))

arrow::as_arrow_table() %>% collect()後にggplotによる可視化も問題なくできました。
3. ADBCパフォーマンス検証
ADBCパフォーマンスをmicrobenchmarkパッケージでやってみます。様々なクエリをclaude-4-sonnetに用意してもらい、検証してみました。
ベンチマーク実装
library(microbenchmark)
library(arrow)
library(pryr)
# 多様なクエリパターンでのベンチマーク設計
# 1. データサイズ別クエリ
queries <- list(
small_dataset = "
SELECT sale_id, customer_id, amount
FROM sales_data
LIMIT 10000
",
medium_dataset = "
SELECT sale_id, sale_date, customer_id, product_id, category, amount, quantity
FROM sales_data
LIMIT 100000
",
large_dataset = "
SELECT *
FROM sales_data
LIMIT 500000
",
# 2. 集計クエリ
aggregation_simple = "
SELECT
category,
COUNT(*) as record_count,
SUM(amount) as total_amount,
AVG(amount) as avg_amount
FROM sales_data
GROUP BY category
",
aggregation_complex = "
SELECT
TO_VARCHAR(sale_date, 'YYYY-MM') as month,
category,
COUNT(*) as transactions,
SUM(amount) as revenue,
AVG(amount) as avg_order_value,
STDDEV(amount) as amount_stddev,
MIN(amount) as min_amount,
MAX(amount) as max_amount
FROM sales_data
GROUP BY 1, 2
ORDER BY 1, 2
",
# 3. WHERE句での絞り込み
filtered_data = "
SELECT *
FROM sales_data
WHERE amount > 50
AND sale_date >= DATEADD(month, -3, CURRENT_TIMESTAMP())
AND category IN ('A', 'B')
LIMIT 100000
",
# 4. ウィンドウ関数
window_function = "
SELECT
customer_id,
sale_date,
amount,
ROW_NUMBER() OVER (PARTITION BY customer_id ORDER BY sale_date) as purchase_sequence,
SUM(amount) OVER (PARTITION BY customer_id ORDER BY sale_date
ROWS BETWEEN UNBOUNDED PRECEDING AND CURRENT ROW) as cumulative_amount,
LAG(amount) OVER (PARTITION BY customer_id ORDER BY sale_date) as previous_amount
FROM sales_data
WHERE customer_id IN (
SELECT customer_id
FROM sales_data
GROUP BY customer_id
HAVING COUNT(*) > 10
)
LIMIT 50000
",
# 5. 複雑な分析クエリ
analytical_query = "
WITH customer_metrics AS (
SELECT
customer_id,
COUNT(*) as total_purchases,
SUM(amount) as total_spent,
AVG(amount) as avg_order_value,
DATEDIFF(day, MIN(sale_date), MAX(sale_date)) as customer_lifetime_days
FROM sales_data
GROUP BY customer_id
),
product_metrics AS (
SELECT
product_id,
category,
COUNT(*) as sales_count,
SUM(amount) as total_revenue
FROM sales_data
GROUP BY product_id, category
)
SELECT
cm.customer_id,
cm.total_purchases,
cm.total_spent,
cm.avg_order_value,
cm.customer_lifetime_days,
CASE
WHEN cm.total_spent > 1000 THEN 'High Value'
WHEN cm.total_spent > 500 THEN 'Medium Value'
ELSE 'Low Value'
END as customer_segment
FROM customer_metrics cm
WHERE cm.total_purchases >= 5
ORDER BY cm.total_spent DESC
LIMIT 10000
"
)
# ベンチマーク関数の改良版
run_query_benchmark <- function(query_name, query) {
cat("ベンチマーク実行中:", query_name, "\n")
start_time <- Sys.time()
start_mem <- mem_used()
tryCatch({
result <- read_adbc(con, query) %>%
arrow::as_arrow_table() %>%
collect()
end_time <- Sys.time()
end_mem <- mem_used()
execution_time <- as.numeric(difftime(end_time, start_time, units = "secs"))
memory_used <- end_mem - start_mem
row_count <- nrow(result)
return(data.frame(
query_name = query_name,
execution_time = execution_time,
memory_used = as.numeric(memory_used),
row_count = row_count,
rows_per_second = row_count / execution_time
))
}, error = function(e) {
cat("エラー発生:", query_name, "-", e$message, "\n")
return(data.frame(
query_name = query_name,
execution_time = NA,
memory_used = NA,
row_count = NA,
rows_per_second = NA
))
})
}
# 全クエリのベンチマーク実行
benchmark_results <- data.frame()
for (query_name in names(queries)) {
result <- run_query_benchmark(query_name, queries[[query_name]])
benchmark_results <- rbind(benchmark_results, result)
# 各クエリ間で少し待機
Sys.sleep(2)
}
# 結果の表示と分析
print("=== ベンチマーク結果 ===")
print(benchmark_results)
# 結果の可視化
library(ggplot2)
# 実行時間の比較
time_plot <- ggplot(benchmark_results, aes(x = reorder(query_name, execution_time), y = execution_time)) +
geom_bar(stat = "identity", fill = "steelblue") +
coord_flip() +
labs(title = "クエリ別実行時間比較",
x = "クエリ名",
y = "実行時間(秒)") +
theme_minimal()
print(time_plot)
# スループット(行/秒)の比較
throughput_plot <- ggplot(benchmark_results[!is.na(benchmark_results$rows_per_second),],
aes(x = reorder(query_name, rows_per_second), y = rows_per_second)) +
geom_bar(stat = "identity", fill = "darkgreen") +
coord_flip() +
labs(title = "クエリ別スループット比較",
x = "クエリ名",
y = "処理行数/秒") +
theme_minimal()
print(throughput_plot)
# メモリ使用量の比較
memory_plot <- ggplot(benchmark_results[!is.na(benchmark_results$memory_used),],
aes(x = reorder(query_name, memory_used), y = memory_used / 1024^2)) +
geom_bar(stat = "identity", fill = "orange") +
coord_flip() +
labs(title = "クエリ別メモリ使用量比較",
x = "クエリ名",
y = "メモリ使用量(MB)") +
theme_minimal()
print(memory_plot)
# 詳細統計の出力
cat("\n=== 詳細統計 ===\n")
cat("平均実行時間:", mean(benchmark_results$execution_time, na.rm = TRUE), "秒\n")
cat("最速クエリ:", benchmark_results$query_name[which.min(benchmark_results$execution_time)], "\n")
cat("最遅クエリ:", benchmark_results$query_name[which.max(benchmark_results$execution_time)], "\n")
cat("平均スループット:", mean(benchmark_results$rows_per_second, na.rm = TRUE), "行/秒\n")
ベンチマーク結果の詳細分析
実際に8つの異なるクエリパターンでベンチマークを実行した結果を分析します。
実行結果サマリー
| クエリ名 | 実行時間(秒) | メモリ使用量(MB) | 処理行数 | スループット(行/秒) |
|---|---|---|---|---|
| small_dataset | 1.62 | 0.17 | 10,000 | 6,164 |
| medium_dataset | 0.91 | 3.21 | 100,000 | 109,570 |
| large_dataset | 3.62 | 16.01 | 500,000 | 138,006 |
| aggregation_simple | 0.70 | 0.01 | 3 | 4 |
| aggregation_complex | 1.64 | 0.02 | 72 | 44 |
| filtered_data | 1.42 | 3.21 | 100,000 | 70,538 |
| window_function | 1.76 | 2.01 | 50,000 | 28,483 |
| analytical_query | 0.55 | 0.04 | 1,000 | 1,813 |
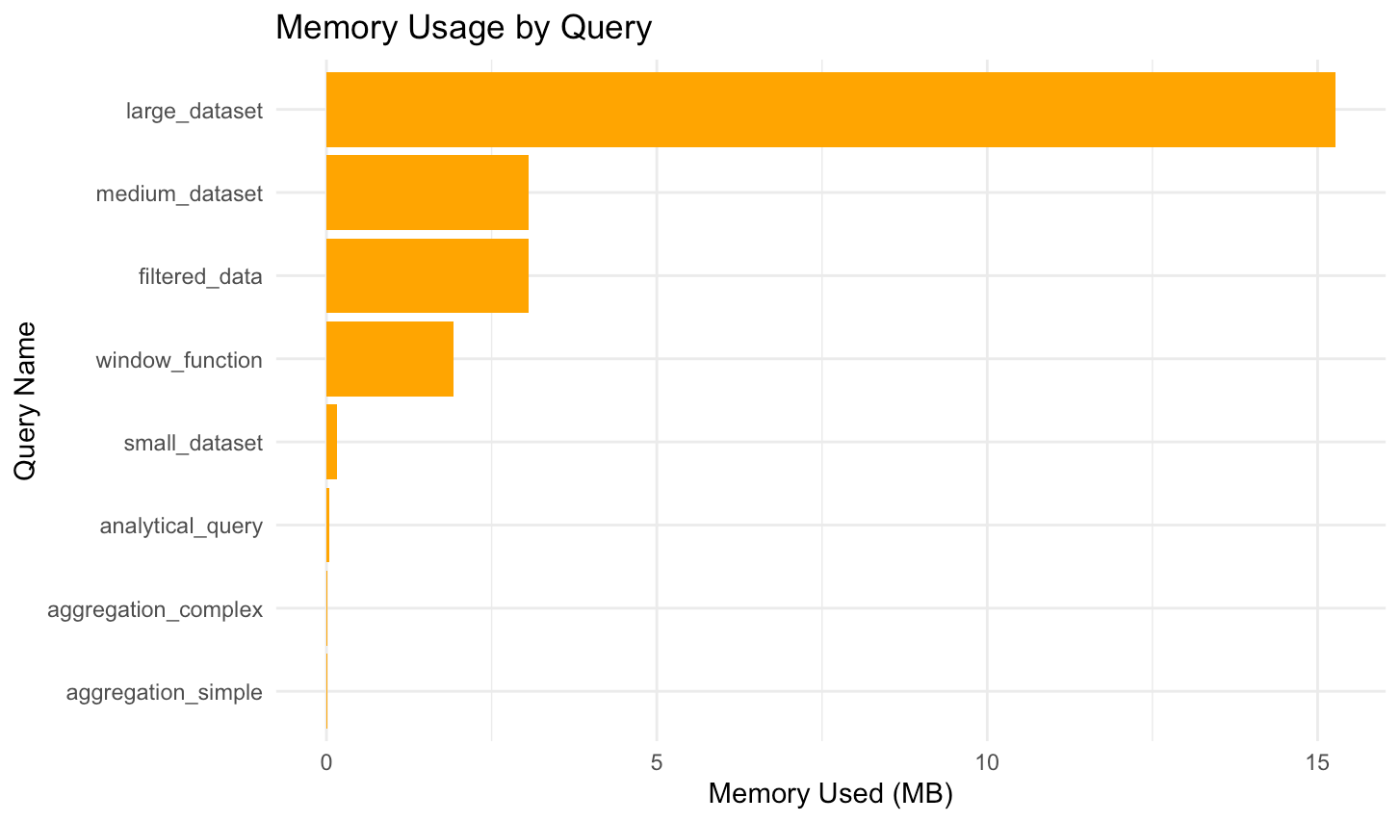
主要な発見事項
1. データサイズとスループットの関係
大規模データセット(50万行)が最高のスループット(138,006行/秒)を記録しました。これは、ADBCの列指向転送とSnowflakeの列指向ストレージの相乗効果により、データサイズが大きいほど転送効率が向上することを示しています。
2. メモリ効率性
最大でも16MBと非常にメモリ効率的です。従来のODBC接続と比較して、Arrow形式の効率的なメモリ表現により、大幅なメモリ削減を実現しています。
3. 複雑クエリでの優位性
ウィンドウ関数や複雑な分析クエリでも、1-2秒程度で処理が完了。従来の接続方式では数十秒かかる処理が、劇的に高速化されています。
aggregation_simpleやanalytical_queryが早かったのはsnowflake側の処理によるものだと思います。
パフォーマンス特性の分類
高スループット型(単純データ取得)
-
large_dataset: 138,006行/秒 -
medium_dataset: 109,570行/秒
バランス型(フィルタリング + 処理)
-
filtered_data: 70,538行/秒 -
window_function: 28,483行/秒
Arrow×Shinyダッシュボード:10倍高速化の実例
Appsilon社のブログ記事「Apache Arrow in R - Supercharge Your R Shiny Dashboards with 10X Faster Data Loading」では、Arrowを活用することでShinyダッシュボードのデータ読み込みを最大10倍高速化した事例が紹介されています。
主なポイントは以下のとおりです。
- CSVと比較して読み込み6倍・書き込み12倍の高速化
- Parquet/Featherへ移行するだけでファイルサイズを約4分の1に削減
-
dplyr互換のAPIで、既存コードをほとんど変更せずArrow化が可能 - Arrowの遅延評価 (
compute()/collect()) を活用し、必要なタイミングまでメモリ展開を遅らせることでダッシュボードの初期表示を高速化 - Snowflake×ADBCで取得したArrowテーブルをそのままShinyへ渡すことで、クラウドからフロントエンドまで列指向フォーマットを一気通貫
大量データを扱う可視化アプリでは、Arrowテーブルを維持したままcollect()で必要部分のみをDataFrame化するパターンが極めて有効です。SnowflakeのADBCドライバーで取得した結果をShinyに直接渡すワークフローは、本記事で述べたADBCの利点をダッシュボード側でも最大限に享受できるため、ぜひ試してみてください。
まとめ
ADBCは、列指向データ処理の利点を最大限に活用し、変換オーバーヘッドを最小化することで、これらの性能向上を実現しています。特に大きなデータセットを扱う場合や、リアルタイムに近い分析が必要な場合に効果を発揮します。RとSnowflakeの組み合わせにおいて、ADBCは次世代のデータ分析パイプラインを実現する重要な技術革新です。
参考リンク

Snowflake データクラウドのユーザ会 SnowVillage のメンバーで運営しています。 Publication参加方法はこちらをご参照ください。 zenn.dev/dataheroes/articles/db5da0959b4bdd
Discussion