Streamlit in SnowflakeによるAI分析アプリ(PythonもSQLも苦手でもAI分析が出来るプリセットパッケージアプリ)
Snowflake × AIで変わる!データ分析の新しいカタチ
「データ分析の民主化」を5分で体験してみませんか?
✅ SQLを書けない人でも自然言語でデータ分析
✅ 分析結果をAIが自動で考察・レポート化
✅ 美しいグラフを数クリックで作成
✅ 社内の非エンジニアにも即座にデモ可能
この記事で紹介するStreamlit in Snowflakeアプリなら、上記すべてがプログラミング不要で実現できます。
今回は、特に非エンジニアもしくはプログラミングが苦手な人でもコピペベースでアプリを作れるように、プリセットパッケージ化しておりますので、Snowflakeのユーザーであればすぐにでも利用が出来ます。(なのでGitからの取得とかもありません。)
このAIアプリを体験いただき、皆さんのSnowlfake活用をステップアップの一助となれば幸いです!
どんな風に使ったらいいの?
段階的アプローチ:
- PoC段階: 記事のコードをそのまま使用(社内デモやAIアプリのひな型として)
- パイロット段階: 自社データでの検証、基本的なカスタマイズ(より実践的な活用)
- 本格運用段階: 監視、ログ、セキュリティ強化(商用や業務アプリとしてリリース)
今回の機能では、1,2まで十分に活用できる内容になっています!3の辺りの実装は私もまだまだ不勉強なので一緒に勉強していきましょう!
Streamlit in Snowflakeの基礎概念
Streamlit in Snowflakeは、Snowflakeのウェブインターフェース(Snowsight)上で直接Streamlitアプリケーションを開発・実行できる統合開発環境です。このプラットフォームでは、Pythonの知識のみでデータ分析アプリケーションを構築でき、HTMLやCSS、JavaScriptなどのフロントエンド技術の習得は不要です。
アプリケーション開発では、コードエディタとアプリケーションプレビューが並行して表示される環境が提供されます。これにより、開発者はコードの変更を即座に視覚的に確認でき、迅速な反復開発が可能となります。
1.プリセットパッケージアプリの機能概要
それではこのプリセットされたアプリの機能イメージを最初にお伝えしたいと思います。非エンジニアの方にとっては具体的な実装よりもどういう機能があるのかが重要だと考えています。
このアプリは、指定されたテーブルに対する自然言語でのクエリ実行とその結果のグラフ表示とAI考察をそれぞれタブを切り替えて実行出来るAI分析サービスを完全に体験できるようになっています。
■タブ切替でSQLの出力結果/可視化/AI考察の欲張り構成



画面構成
トップ画面
- データベースとスキーマ、テーブルの指定が可能(複数選択)
- そのテーブルに対する構成情報とサンプリングデータ
質問入力欄
- 選択したテーブルに対して質問を入力
- 質問情報とテーブル構成とサンプリングデータ情報を元にSQLを生成
データ出力
- SQL実行結果を表形式で出力
- 並び替えや順番移動が可能
グラフ出力
- SQL実行結果を任意のグラフ形式で出力
- 表示したいグラフ形式を選択肢、ピボット条件を選択
AI考察
- SQL実行結果に対するAIによる考察を出力
- 追加質問のアドバイスも表示
- 出力結果のテキストダウンロード機能
アプリケーションアーキテクチャの解説
本アプリは「AIを活用した分析サービス」を実現するために以下の6つの明確な機能ブロックで構成されています。
- 初期設定・ライブラリインポートブロック - 必要なライブラリの読み込みと基本設定
- データベースメタデータ管理ブロック - Snowflakeのデータベース構造探索機能
- グラフ可視化ブロック - 動的なデータ可視化とユーザーインタラクション
- AI SQL生成ブロック - COMPLETE関数を活用した自然言語処理
- AI分析考察ブロック - 実行結果に対する洞察生成
- ユーザーインターフェースブロック - 統合されたフロントエンド体験
これらのソースをStreamlitに貼り付けるだけで、誰でもすぐにこのアプリを動かす事ができ、また自身のロールに閉じて実行されるため、確認や検証も容易です。
そんな簡単なはずがない!と思うかもしれませんが、実際に動作を確認していただくことで、その効果を実感できます。
またエキスパートの方々にとっても、それぞれの領域を分ける事で学びが得られるように構成を工夫しましたので、それぞれのパートを見てもらえればと思います。
2.アプリ作成手順
今まで全くStreamlitアプリを触ったことがない方もこの手順で行う事で環境構築が出来るようになっています!
手順
1.Streamlitの起動
2.アプリ設定の実施(ライブラリインストールを画面からポチポチ)
3.この記事のソースをコピペ
オプション手順(モデル最適化)
4.クロスリージョン推論の設定(claude-4-sonnentなどが利用可能になります)
5.モデルをmistral-large2をclaude-4-sonnentに変更
1.Streamlitアプリの立ち上げ
プロジェクトよりStreamlitの選び、右上の+ streamlitアプリボタンを教えてください。
アプリタイトルとアプリの場所を選んでください。(任意のデータベースとスキーマ)
任意のウェアハウスを選んでください。(最初はXSやSなどが良いと思います。)

2.アプリ設定の実施
作成が終わるとデフォルトのソースが反映されたアプリが立ち上がります。
プログラミングが苦手な人はすでにこの段階で拒絶感があると思いますが、乗り切りましょう。

まず、最初に左上のパッケージメニューから、matplotlib、plotlyの2つのパッケージをインストールしてください。


3.ソースの貼り付け
インストールが終わったら、デフォルトアプリのソースを全て削除して、以下のソース一式をそのまま貼り付けてください。貼り付けが終わったら、実行を押してください。
プログラムソース一式
# 1.初期設定・ライブラリインポートブロック
# ライブラリインポート
import streamlit as st
import pandas as pd
import json
import requests
import numpy as np
import matplotlib.pyplot as plt
import plotly.express as px
import plotly.graph_objects as go
from snowflake.snowpark.context import get_active_session
from snowflake.snowpark.exceptions import SnowparkSQLException
# Streamlitの設定
st.set_page_config(layout="wide")
# タイトルとアプリの説明
st.title("自然言語分析の標準設計アプリ")
st.markdown("このアプリはSnowflakeのCOMPLETE関数を使用して自然言語からSQLクエリを生成し実行した後、結果に対する分析考察を提供します。")
# セッション情報の取得
session = get_active_session()
# ダウンロード機能のfragment関数
@st.fragment
def download_analysis_fragment(analysis_result):
"""分析結果のダウンロード機能(fragment化で再描画を防ぐ)"""
st.markdown("### 📄 考察内容のダウンロード")
analysis_text = analysis_result.encode('utf-8')
st.download_button(
label="📄 考察をテキストファイルでダウンロード",
data=analysis_text,
file_name="ai_analysis_result.txt",
mime="text/plain",
key="download_analysis_button"
)
# 2.データベーメタデータ管理ブロック
# データベース、スキーマ、テーブル(ビュー含む)のリストを取得する関数
def get_databases():
"""Snowflakeで利用可能なデータベースの一覧を取得する"""
df = session.sql("SHOW DATABASES").collect()
return [row["name"] for row in df]
def get_schemas(database):
"""選択されたデータベース内のスキーマの一覧を取得する"""
df = session.sql(f"SHOW SCHEMAS IN DATABASE {database}").collect()
return [row["name"] for row in df]
# データベース、スキーマ、テーブル(ビュー含む)のリストを取得する関数
def get_databases():
"""Snowflakeで利用可能なデータベースの一覧を取得する"""
df = session.sql("SHOW DATABASES").collect()
return [row["name"] for row in df]
def get_schemas(database):
"""選択されたデータベース内のスキーマの一覧を取得する"""
# データベース名をクォート
quoted_database = f'"{database}"'
df = session.sql(f"SHOW SCHEMAS IN DATABASE {quoted_database}").collect()
return [row["name"] for row in df]
def get_tables(database, schema):
"""選択されたデータベースとスキーマ内のテーブル、ビュー、マテリアライズドビュー、ダイナミックテーブルの一覧を取得する"""
try:
quoted_database = f'"{database}"'
quoted_schema = f'"{schema}"'
# INFORMATION_SCHEMAを使用してすべてのテーブル型オブジェクトを取得
query = f"""
SELECT
table_name,
table_type
FROM {quoted_database}.INFORMATION_SCHEMA.TABLES
WHERE table_schema = '{schema}'
AND table_type IN ('BASE TABLE', 'VIEW', 'MATERIALIZED VIEW', 'DYNAMIC TABLE')
ORDER BY table_name
"""
df = session.sql(query).collect()
# 型情報を除去してテーブル名のみを返す
return [row["TABLE_NAME"] for row in df]
except Exception as e:
# フォールバック: 従来のSHOW TABLESとSHOW VIEWSを組み合わせ
st.warning(f"INFORMATION_SCHEMA使用時にエラーが発生しました。代替方法を使用します: {str(e)}")
objects = []
quoted_database = f'"{database}"'
quoted_schema = f'"{schema}"'
try:
# テーブルを取得
df_tables = session.sql(f"SHOW TABLES IN {quoted_database}.{quoted_schema}").collect()
objects.extend([row["name"] for row in df_tables])
except:
pass
try:
# ビューを取得
df_views = session.sql(f"SHOW VIEWS IN {quoted_database}.{quoted_schema}").collect()
objects.extend([row["name"] for row in df_views])
except:
pass
try:
# マテリアライズドビューを取得
df_mviews = session.sql(f"SHOW MATERIALIZED VIEWS IN {quoted_database}.{quoted_schema}").collect()
objects.extend([row["name"] for row in df_mviews])
except:
pass
return sorted(list(set(objects))) # 重複除去とソート
def get_table_structure(database, schema, table):
"""テーブルの構造(カラム情報)とコメントを取得し、業務重要度順に並び替える"""
try:
quoted_database = f'"{database}"'
quoted_schema = f'"{schema}"'
quoted_table = f'"{table}"'
# DESCRIBE TABLEでカラム情報とコメントを取得
df = session.sql(f"DESCRIBE TABLE {quoted_database}.{quoted_schema}.{quoted_table}").collect()
result_df = pd.DataFrame(df)
if not result_df.empty:
# 業務重要度順にカラムを並び替え(除外対象カラムを含む)
priority_columns = ['name', 'type', 'comment', 'primary key', 'policy name']
# 除外するカラムを定義
exclude_columns = ['kind', 'null?', 'unique key', 'check', 'expression']
# 実際に存在するカラムのみを抽出(除外カラムを除く)
existing_priority_cols = [col for col in priority_columns if col in result_df.columns]
# 残りのカラム(優先度の低いもの)から除外カラムを除く
remaining_cols = [col for col in result_df.columns
if col not in existing_priority_cols and col not in exclude_columns]
# 新しいカラム順序
new_column_order = existing_priority_cols + remaining_cols
# カラム順序を変更
result_df = result_df[new_column_order]
# 列名を日本語化(除外カラムを除く)
column_mapping = {
'name': 'カラム名',
'type': 'データ型',
'comment': 'ビジネス用語・説明',
'policy name': 'ポリシー名',
'default': 'デフォルト値',
'privacy domain': 'プライバシードメイン'
}
# 存在するカラムのみリネーム
rename_mapping = {k: v for k, v in column_mapping.items() if k in result_df.columns}
result_df = result_df.rename(columns=rename_mapping)
# コメントが空の場合の表示を改善
if 'ビジネス用語・説明' in result_df.columns:
result_df['ビジネス用語・説明'] = result_df['ビジネス用語・説明'].fillna('(説明なし)')
return result_df
except Exception as e:
# ビューの場合はDESCRIBE VIEWを試行
try:
quoted_database = f'"{database}"'
quoted_schema = f'"{schema}"'
quoted_table = f'"{table}"'
df = session.sql(f"DESCRIBE VIEW {quoted_database}.{quoted_schema}.{quoted_table}").collect()
result_df = pd.DataFrame(df)
if not result_df.empty:
# 同様の並び替え処理(除外カラムを含む)
priority_columns = ['name', 'type', 'comment', 'primary key', 'policy name']
exclude_columns = ['kind', 'null?', 'unique key', 'check', 'expression']
existing_priority_cols = [col for col in priority_columns if col in result_df.columns]
remaining_cols = [col for col in result_df.columns
if col not in existing_priority_cols and col not in exclude_columns]
new_column_order = existing_priority_cols + remaining_cols
result_df = result_df[new_column_order]
# 日本語化
column_mapping = {
'name': 'カラム名',
'type': 'データ型',
'comment': 'ビジネス用語・説明',
'policy name': 'ポリシー名',
'default': 'デフォルト値'
}
rename_mapping = {k: v for k, v in column_mapping.items() if k in result_df.columns}
result_df = result_df.rename(columns=rename_mapping)
if 'ビジネス用語・説明' in result_df.columns:
result_df['ビジネス用語・説明'] = result_df['ビジネス用語・説明'].fillna('(説明なし)')
return result_df
except Exception as e2:
st.warning(f"{table}の構造取得中にエラーが発生しました: {str(e2)}")
return pd.DataFrame()
def get_sample_data(database, schema, table, rows=5):
"""テーブル/ビューのサンプルデータを取得する"""
try:
# オブジェクト名をすべてクォート
quoted_database = f'"{database}"'
quoted_schema = f'"{schema}"'
quoted_table = f'"{table}"'
# まずテーブル型を確認
table_type_query = f"""
SELECT table_type
FROM {quoted_database}.INFORMATION_SCHEMA.TABLES
WHERE table_schema = '{schema}' AND table_name = '{table}'
"""
try:
table_type_result = session.sql(table_type_query).collect()
if table_type_result and table_type_result[0]["TABLE_TYPE"] in ['BASE TABLE', 'DYNAMIC TABLE']:
# テーブルまたはダイナミックテーブルの場合はSAMPLEを使用
return session.sql(f"SELECT * FROM {quoted_database}.{quoted_schema}.{quoted_table} SAMPLE ({rows} ROWS)").to_pandas()
else:
# ビューまたはマテリアライズドビューの場合はLIMITを使用
return session.sql(f"SELECT * FROM {quoted_database}.{quoted_schema}.{quoted_table} LIMIT {rows}").to_pandas()
except:
# INFORMATION_SCHEMAアクセスに失敗した場合はLIMITで試行
return session.sql(f"SELECT * FROM {quoted_database}.{quoted_schema}.{quoted_table} LIMIT {rows}").to_pandas()
except Exception as e:
st.warning(f"{table}のサンプルデータの取得中にエラーが発生しました: {str(e)}")
return pd.DataFrame()
def get_table_type(database, schema, table):
"""テーブル/ビューの型を取得する(オプション関数)"""
try:
quoted_database = f'"{database}"'
query = f"""
SELECT table_type
FROM {quoted_database}.INFORMATION_SCHEMA.TABLES
WHERE table_schema = '{schema}' AND table_name = '{table}'
"""
result = session.sql(query).collect()
if result:
return result[0]["TABLE_TYPE"]
return "UNKNOWN"
except:
return "UNKNOWN"
# 3.グラフ可視化ブロック
# グラフ設定用のセッション状態を初期化する関数
def initialize_graph_state(df):
"""グラフ設定用のセッション状態を初期化する"""
# データからカラム情報を取得
numeric_cols = df.select_dtypes(include=['int64', 'float64']).columns.tolist()
categorical_cols = df.select_dtypes(include=['object', 'category', 'bool']).columns.tolist()
# 必要なセッション状態を初期化
if 'graph_type' not in st.session_state:
st.session_state.graph_type = '棒グラフ'
# データに基づいて軸と設定の初期値を設定
if 'x_axis' not in st.session_state and len(df.columns) > 0:
st.session_state.x_axis = df.columns[0]
if 'y_axis' not in st.session_state and len(df.columns) > 1:
st.session_state.y_axis = df.columns[1]
if 'color_option' not in st.session_state:
st.session_state.color_option = 'なし'
if 'size_option' not in st.session_state:
st.session_state.size_option = 'なし'
if 'name_col' not in st.session_state and len(categorical_cols) > 0:
st.session_state.name_col = categorical_cols[0]
if 'value_col' not in st.session_state and len(numeric_cols) > 0:
st.session_state.value_col = numeric_cols[0]
if 'hist_col' not in st.session_state and len(numeric_cols) > 0:
st.session_state.hist_col = numeric_cols[0]
if 'bin_count' not in st.session_state:
st.session_state.bin_count = 20
if 'box_value_col' not in st.session_state and len(numeric_cols) > 0:
st.session_state.box_value_col = numeric_cols[0]
if 'category_col' not in st.session_state:
st.session_state.category_col = 'なし'
# カスタムグラフ設定用のfragment関数
@st.fragment
def graph_fragment(df):
"""ユーザーがカスタマイズ可能なグラフを表示する"""
st.subheader("グラフ設定")
# 列の型を分析
numeric_cols = df.select_dtypes(include=['int64', 'float64']).columns.tolist()
categorical_cols = df.select_dtypes(include=['object', 'category', 'bool']).columns.tolist()
# グラフタイプの選択
graph_type = st.selectbox(
"グラフタイプを選択",
["棒グラフ", "折れ線グラフ", "散布図", "円グラフ", "ヒストグラム", "箱ひげ図"],
key="graph_type"
)
# 軸の選択(グラフタイプに応じて表示を変更)
if graph_type in ["棒グラフ", "折れ線グラフ", "散布図"]:
# X軸とY軸の選択
col1, col2 = st.columns(2)
with col1:
x_axis = st.selectbox("X軸を選択", df.columns, key="x_axis")
with col2:
y_axis_options = [col for col in df.columns]
y_axis = st.selectbox("Y軸を選択", y_axis_options, key="y_axis")
# 色分けオプションの選択
color_options = ["なし"] + [col for col in df.columns if col not in [x_axis, y_axis]]
color_option = st.selectbox("色分け項目(オプション)", color_options, key="color_option")
color_col = None if color_option == "なし" else color_option
# グラフ生成
if graph_type == "棒グラフ":
fig = px.bar(df, x=x_axis, y=y_axis, color=color_col, title=f"{x_axis}ごとの{y_axis}")
elif graph_type == "折れ線グラフ":
fig = px.line(df, x=x_axis, y=y_axis, color=color_col, title=f"{y_axis}の推移")
else: # 散布図
# サイズオプションの選択
size_options = ["なし"] + [col for col in numeric_cols if col not in [x_axis, y_axis]]
size_option = st.selectbox("サイズ項目(オプション)", size_options, key="size_option")
size_col = None if size_option == "なし" else size_option
fig = px.scatter(df, x=x_axis, y=y_axis, color=color_col, size=size_col, title=f"{x_axis} vs {y_axis}")
st.plotly_chart(fig, use_container_width=True)
elif graph_type == "円グラフ":
# カテゴリと値の列を選択
col1, col2 = st.columns(2)
with col1:
name_col = st.selectbox("カテゴリ列を選択",
categorical_cols if categorical_cols else df.columns,
key="name_col")
with col2:
value_options = numeric_cols if numeric_cols else [col for col in df.columns if col != name_col]
value_col = st.selectbox("値の列を選択", value_options, key="value_col")
# 円グラフ生成
pie_df = df.groupby(name_col)[value_col].sum().reset_index()
fig = px.pie(pie_df, names=name_col, values=value_col, title=f"{name_col}ごとの{value_col}の割合")
st.plotly_chart(fig, use_container_width=True)
elif graph_type == "ヒストグラム":
# 数値列と階級数を選択
col1, col2 = st.columns(2)
with col1:
hist_col = st.selectbox("分布を表示する列を選択",
numeric_cols if numeric_cols else df.columns,
key="hist_col")
with col2:
bin_count = st.slider("ビンの数", min_value=5, max_value=100, key="bin_count")
# ヒストグラム生成
fig = px.histogram(df, x=hist_col, nbins=bin_count, title=f"{hist_col}の分布")
st.plotly_chart(fig, use_container_width=True)
else: # 箱ひげ図
# 値とカテゴリの列を選択
col1, col2 = st.columns(2)
with col1:
value_col = st.selectbox("値の列を選択",
numeric_cols if numeric_cols else df.columns,
key="box_value_col")
with col2:
category_options = ["なし"] + [col for col in categorical_cols if col != value_col]
category_col = st.selectbox("カテゴリ列を選択(オプション)",
category_options,
key="category_col")
# 箱ひげ図生成
if category_col != "なし":
fig = px.box(df, x=category_col, y=value_col, title=f"{category_col}ごとの{value_col}の分布")
else:
fig = px.box(df, y=value_col, title=f"{value_col}の分布")
st.plotly_chart(fig, use_container_width=True)
# データのグラフ表示
def visualize_data(df):
"""データフレームをグラフとして可視化する"""
# データフレームが空の場合
if df.empty:
st.warning("表示するデータがありません")
return
# データが少なすぎる場合はグラフ化しない
if len(df) < 2:
st.info("データが少ないためグラフは表示しません")
return
# セッション状態を初期化
initialize_graph_state(df)
# グラフを表示
graph_fragment(df)
# 4.AI SQL生成ブロック
# COMPLETE関数を使用してSQL生成
def generate_sql_with_llm(prompt, database, schema, tables):
"""Snowflake COMPLETE関数を使用して自然言語からSQLを生成する"""
try:
# すべてのテーブルに関する情報を収集
tables_info = []
for table in tables:
# オブジェクト名をクォート
quoted_database = f'"{database}"'
quoted_schema = f'"{schema}"'
quoted_table = f'"{table}"'
# テーブル構造の取得
table_info = session.sql(f"DESCRIBE TABLE {quoted_database}.{quoted_schema}.{quoted_table}").collect()
table_structure = "\n".join([f'"{row["name"]}" ({row["type"]})' for row in table_info])
# テーブルのサンプルデータを取得(5行)
try:
sample_data = session.sql(f"SELECT * FROM {quoted_database}.{quoted_schema}.{quoted_table} SAMPLE (5 ROWS)").collect()
sample_df = pd.DataFrame(sample_data)
sample_str = sample_df.to_string(index=False)
except Exception as e:
st.warning(f"{table}のサンプルデータの取得中にエラーが発生しました: {str(e)}")
sample_str = "サンプルデータを取得できませんでした。"
# テーブルごとの情報を追加
tables_info.append({
"name": table,
"structure": table_structure,
"sample": sample_str
})
# テーブル情報を結合したプロンプトを作成
tables_context = ""
for info in tables_info:
tables_context += f"""
テーブル名: {database}.{schema}.{info['name']}
テーブル構造:
{info['structure']}
サンプルデータ (5件):
{info['sample']}
"""
# ユーザープロンプトを作成
tables_list = ", ".join([f"{database}.{schema}.{table}" for table in tables])
full_prompt = f"""以下のテーブル構造とサンプルデータを持つテーブル [{tables_list}] に対して、
次の質問に答えるSQLクエリを生成してください:
{tables_context}
質問:
{prompt}
重要な注意事項:
- Snowflakeの標準SQLのみを使用してください
- 可能な限り素早く回答すること
- テーブル名、スキーマ名、カラム名は必ずダブルクォート(")で囲んでください
- 日本語のカラム名やテーブル名も適切にクォートしてください
- エイリアス(AS句で指定する別名)も日本語の場合は必ずダブルクォート(")で囲んでください
- 複数のテーブルに関する質問の場合は、適切なJOIN条件を使用してテーブルを結合してください
- SQLクエリのみを出力し、返事や説明などは不要です
"""
# Snowflake COMPLETE関数を使用してSQLを生成
result = session.sql("""
SELECT SNOWFLAKE.CORTEX.COMPLETE(
'mistral-large2',
?
) AS generated_sql
""", params=[full_prompt]).collect()[0]["GENERATED_SQL"]
# 余分なマークダウンや説明文を取り除き、SQLクエリだけを抽出
sql_query = result.strip()
if sql_query.startswith("```sql"):
sql_query = sql_query.split("```sql")[1]
elif sql_query.startswith("```"):
sql_query = sql_query.split("```")[1]
if "```" in sql_query:
sql_query = sql_query.split("```")[0]
# コメント行を削除
clean_lines = []
for line in sql_query.split("\n"):
if not line.strip().startswith("--") and line.strip():
clean_lines.append(line)
return "\n".join(clean_lines).strip()
except Exception as e:
st.error(f"SQL生成エラー: {str(e)}")
st.write("エラーの詳細:")
st.code(str(e))
# フォールバック: パラメータバインディングを使わない方法
try:
st.info("代替方法で再試行中...")
# シングルクォートをエスケープしてSQL文に直接埋め込む
escaped_prompt = full_prompt.replace("'", "''")
result = session.sql(f"""
SELECT SNOWFLAKE.CORTEX.COMPLETE(
'mistral-large2',
'{escaped_prompt}'
) AS generated_sql
""").collect()[0]["GENERATED_SQL"]
# 余分なマークダウンや説明文を取り除き、SQLクエリだけを抽出
sql_query = result.strip()
if sql_query.startswith("```sql"):
sql_query = sql_query.split("```sql")[1]
elif sql_query.startswith("```"):
sql_query = sql_query.split("```")[1]
if "```" in sql_query:
sql_query = sql_query.split("```")[0]
# コメント行を削除
clean_lines = []
for line in sql_query.split("\n"):
if not line.strip().startswith("--") and line.strip():
clean_lines.append(line)
return "\n".join(clean_lines).strip()
except Exception as e2:
st.error(f"SQL生成の再試行もエラー: {str(e2)}")
return None
# 5.AI分析考察ブロック
# COMPLETE関数を使用してクエリ結果の分析考察を生成
def generate_analysis_with_llm(df, original_prompt, generated_sql):
"""クエリ結果を分析してCOMPLETE関数で考察を生成する"""
try:
# データフレームの基本情報を取得
sample_data = df.head(10).to_string(index=False)
# 分析プロンプトを作成
analysis_prompt = f"""
以下のデータ分析結果について、詳細な考察とインサイトを提供してください:
【元の質問】
{original_prompt}
【実行されたSQL】
{generated_sql}
【データの基本情報】
- 行数: {len(df)}
- 列数: {len(df.columns)}
- 列名: {', '.join(df.columns)}
【サンプルデータ(10行)】
{sample_data}
以下の観点から分析と考察を提供してください:
1. データの概要と傾向
2. 注目すべき数値やパターン
3. ビジネス上の意味や示唆
4. さらなる分析のための質問例(自然言語での質問形式で提案)
重要な注意事項:
- 「さらなる分析の提案」では、SQLコードではなく、このアプリの質問入力欄に入力できる自然言語での質問例を提案してください
- 例:「月次でのトレンド分析を行いたい場合は『各月の企業別ポイント付与数の推移を教えて』」
- 例:「上位企業の集中度を知りたい場合は『上位10社のポイント付与数の合計と全体に占める割合を教えて』」
日本語で分かりやすく回答してください。
"""
# COMPLETE関数を使用して分析を生成
result = session.sql("""
SELECT SNOWFLAKE.CORTEX.COMPLETE(
'mistral-large2',
?
) AS analysis_result
""", params=[analysis_prompt]).collect()[0]["ANALYSIS_RESULT"]
return result
except Exception as e:
st.error(f"分析生成エラー: {str(e)}")
return "分析の生成中にエラーが発生しました。出力結果とグラフを参考に手動で分析を行ってください。"
# 6.ユーザーインタフェースブロック
# サイドバーにデータベース、スキーマ、テーブルの選択ボックスを配置
st.sidebar.header("データソースの選択")
# データベースの選択
databases = get_databases()
selected_database = st.sidebar.selectbox("データベースを選択", databases)
# スキーマの選択
if selected_database:
schemas = get_schemas(selected_database)
selected_schema = st.sidebar.selectbox("スキーマを選択", schemas)
else:
selected_schema = None
# テーブルの選択(複数選択に変更)
if selected_database and selected_schema:
tables = get_tables(selected_database, selected_schema)
selected_tables = st.sidebar.multiselect("テーブルを選択(複数選択可)", tables)
else:
selected_tables = []
# テーブル構造の表示(複数オブジェクト対応)
if selected_database and selected_schema and selected_tables:
for table_with_type in selected_tables:
# テーブル名から型情報を分離
if " (" in table_with_type:
table_name = table_with_type.split(" (")[0]
object_type = table_with_type.split(" (")[1].rstrip(")")
else:
table_name = table_with_type
object_type = "TABLE"
with st.expander(f"{object_type}: {table_name}"):
# テーブル構造を表示
table_structure = get_table_structure(selected_database, selected_schema, table_name)
if not table_structure.empty:
st.subheader("カラム情報")
# コメントの有無で表示方法を変更
if 'ビジネス用語・説明' in table_structure.columns:
comment_count = len(table_structure[table_structure['ビジネス用語・説明'] != '(説明なし)'])
st.info(f"💡 {comment_count}個のカラムにビジネス用語・説明が設定されています")
# 業務重要度順で表示
st.dataframe(table_structure, use_container_width=True)
else:
st.error("構造情報を取得できませんでした")
# サンプルデータの表示
try:
st.subheader(f"サンプルデータ (10件): {table_name}")
sample_data = get_sample_data(selected_database, selected_schema, table_name)
if not sample_data.empty:
st.dataframe(sample_data)
else:
st.warning("サンプルデータを取得できませんでした")
except Exception as e:
st.warning(f"サンプルデータの表示中にエラーが発生しました: {str(e)}")
# 自然言語の質問入力
st.header("質問入力")
st.markdown("選択したテーブルに対して自然言語で質問してください。LLMが適切なSQLクエリを生成し実行します。複数テーブルを選択した場合は、JOIN操作を含むクエリも生成できます。")
user_prompt = st.text_area("テーブルに関する質問を入力してください", height=100)
# SQL生成・実行ボタン(条件付きの表示と実行)
if all([selected_database, selected_schema]) and selected_tables:
execute_button = st.button("SQLを生成して実行", key="execute_button")
if execute_button and user_prompt:
with st.spinner("SQLを生成中..."):
# SQLの生成(複数テーブル対応)
generated_sql = generate_sql_with_llm(user_prompt, selected_database, selected_schema, selected_tables)
if generated_sql:
# 生成されたSQLを表示
st.subheader("生成されたSQL")
st.code(generated_sql, language="sql")
# SQLの実行
try:
with st.spinner("クエリを実行中..."):
result_df = session.sql(generated_sql).to_pandas()
# 結果の表示(タブで分ける)
result_tabs = st.tabs(["抽出結果", "グラフ表示", "AI分析考察"])
with result_tabs[0]:
st.subheader("実行結果")
st.dataframe(result_df)
# CSVダウンロードボタン
csv = result_df.to_csv(index=False).encode('utf-8')
st.download_button(
label="CSVとしてダウンロード",
data=csv,
file_name="query_result.csv",
mime="text/csv",
)
with result_tabs[1]:
st.subheader("データの可視化")
# データをグラフとして表示
visualize_data(result_df)
with result_tabs[2]:
st.subheader("AI分析考察")
with st.spinner("分析考察を生成中..."):
# COMPLETE関数を使用して分析考察を生成
analysis_result = generate_analysis_with_llm(result_df, user_prompt, generated_sql)
# 分析結果を表示
st.markdown(analysis_result)
# ダウンロード機能をfragmentとして実装
download_analysis_fragment(analysis_result)
except SnowparkSQLException as e:
st.error(f"SQL実行エラー: {str(e)}")
elif execute_button and not user_prompt:
st.warning("質問を入力してください。")
else:
st.warning("データベース、スキーマ、テーブルを選択してください。少なくとも1つのテーブルを選択する必要があります。")
# フッター
st.markdown("---")
st.caption("Created by CCC MK HOLDINGS Co.,Ltd.")

オプション手順 4.推論モデルの制約とクロスリージョン推論について
生成AIの各モデルについて、日本リージョンで利用できるモデルが少ないというか課題があります。
そのため、今回のアプリでは、AWS東日本リージョンで利用できる、mistral-large2を設定しています。
ちなみに人気のモデルである、claude-4-sonnentを使いたい場合は、クロスリージョン推論という設定をすることで自リージョン以外のモデルを実行可能となります。
自社のセキュリティポリシーなどがあると思いますので、自社で利用可能であれば、クロスリージョン推論を設定してください。
設定手順は、Data Superheroの檜山さんが書いた記事が参考になりますので、こちらを参考に実施してください。
オプション手順 5.モデル変更
3で貼り付けたソースに対し、mistral-large2をclaude-4-sonnentへの一括置換をしてください。モデルの変更により、AI考察やSQL生成の精度が各段に上がります!
具体的な変更箇所は後述のブロックのモデル指定部分の修正となります。
4.AI SQL生成ブロック
# Snowflake COMPLETE関数を使用してSQLを生成
result = session.sql("""
SELECT SNOWFLAKE.CORTEX.COMPLETE(
'mistral-large2',
?
) AS generated_sql
""", params=[full_prompt]).collect()[0]["GENERATED_SQL"]
5.AI分析考察ブロック
# COMPLETE関数を使用して分析を生成
result = session.sql("""
SELECT SNOWFLAKE.CORTEX.COMPLETE(
'mistral-large2',
?
) AS analysis_result
""", params=[analysis_prompt]).collect()[0]["ANALYSIS_RESULT"]
3.アプリの実行
このセッティングが終われば、後は使うだけです。
真ん中あたりのバーを左に折りたたんでソースを隠して、後は体験あるのみです。
分析対象の指定
折りたたんだ画面の左のメニューより検索したいテーブルをデータベース→スキーマ→テーブルと選択してください。
カスタマイズポイント
- テーブルやビューが固定なら、ここは固定にしちゃえば、選択自体が不要です。
- 業務ケースごとの選択肢(顧客分析とか日別売上実績とか)にすると分かりやすさも向上します。

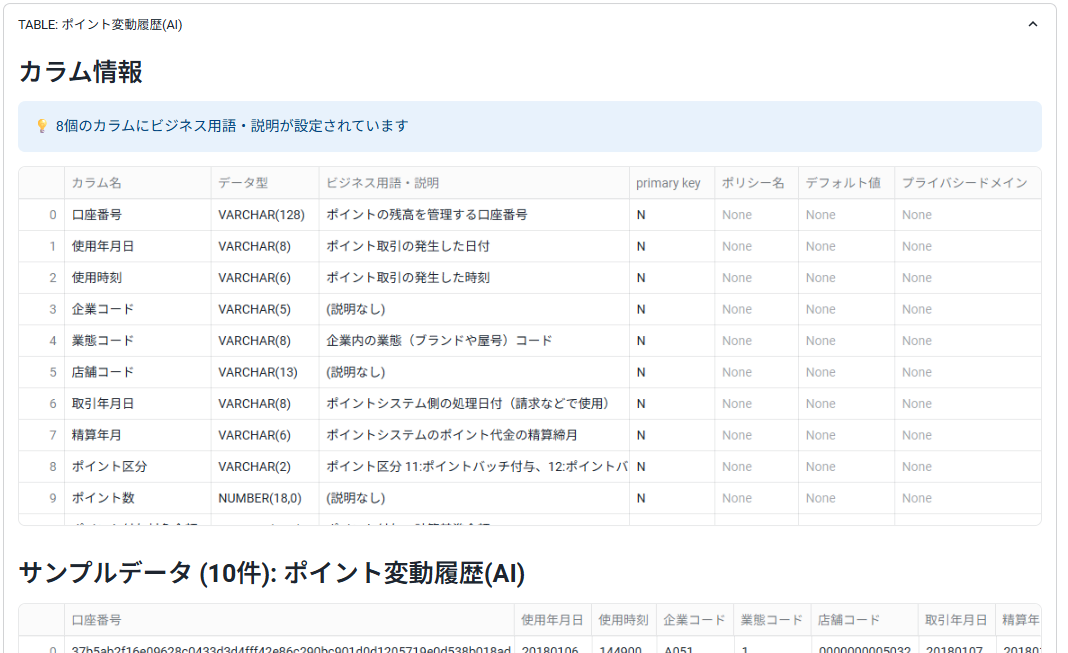
分析対象の情報確認
テーブルレイアウトやサンプリングされたデータが出力されるため、内容の確認が出来ます。
カスタマイズポイント
- 確認用として表示していますが、一般ユーザーには不要であれば非表示でも良いかなと思います。
- 似たような項目があると分かりづらいので極力シンプルな項目構成にするのが良いと思います。
質問の入力
集計したい内容や質問したい内容を入力し、「SQLを生成して実行」ボタンを押します。
生成AIにテーブル情報、サンプリングデータと質問情報をリクエストし、SQLを生成し、実行します。
カスタマイズポイント
- SQL生成に時間がかかるので、何かプロンプトやモデルを強化しても良いかもしれません。

結果出力
生成されたSQLの結果が出力されます。
カスタマイズポイント
- 一般ユーザーにはSQLの表示は不要であれば、非表示でも良いかもしれません。

グラフ出力
出力結果に対し、グラフの形式や集計の軸を選択します。

AI分析考察
出力結果に対して、生成AIが分析したレポートを出力します。
カスタマイズポイント
- コピペ機能なども追加しても良いかもしれません。
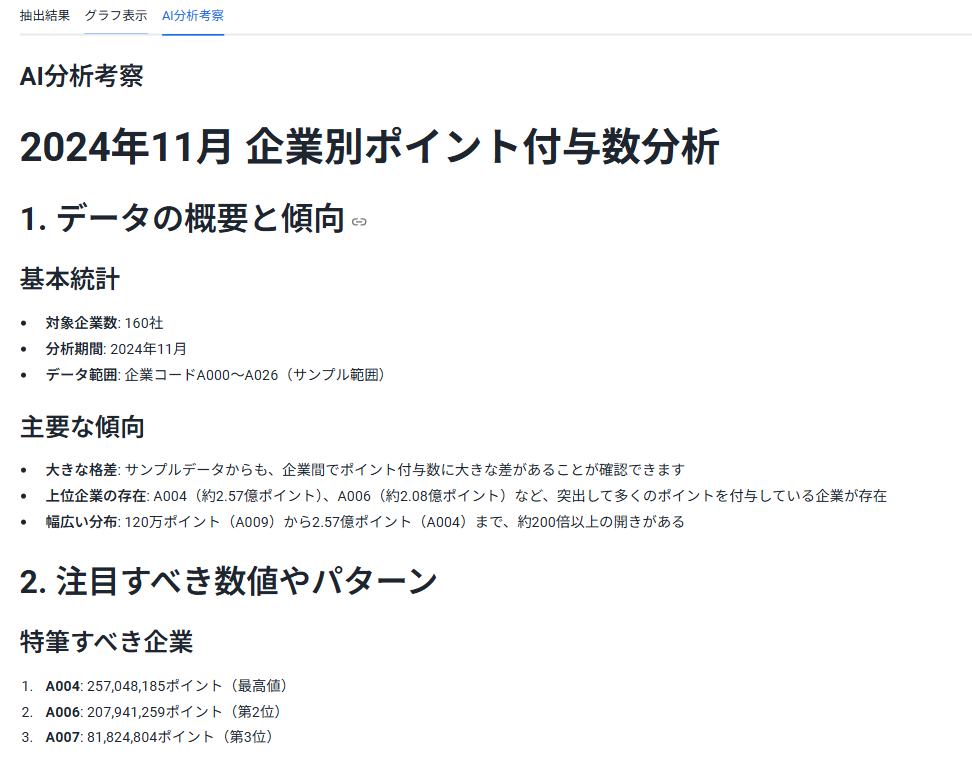
考察結果
AI分析考察
2024年11月 企業別ポイント付与数分析
1. データの概要と傾向
基本統計
対象企業数: 160社
分析期間: 2024年11月
データ範囲: 企業コードA000~A026(サンプル範囲)
主要な傾向
大きな格差: サンプルデータからも、企業間でポイント付与数に大きな差があることが確認できます
上位企業の存在: A004(約2.57億ポイント)、A006(約2.08億ポイント)など、突出して多くのポイントを付与している企業が存在
幅広い分布: 120万ポイント(A009)から2.57億ポイント(A004)まで、約200倍以上の開きがある
2. 注目すべき数値やパターン
特筆すべき企業
A004: 257,048,185ポイント(最高値)
A006: 207,941,259ポイント(第2位)
A007: 81,824,804ポイント(第3位)
パターン分析
二極化構造: 億単位のポイント付与企業と、数百万~数千万ポイントの企業に分かれる傾向
企業規模の反映: ポイント付与数は企業の事業規模や顧客基盤の大きさを反映している可能性
業界特性: 企業コードの分布から、特定の業界や事業形態に偏りがある可能性
3. ビジネス上の意味や示唆
戦略的インサイト
市場集中度: 上位数社が全体のポイント付与の大部分を占めている可能性が高く、市場の寡占化が進んでいる
顧客エンゲージメント: ポイント付与数は顧客との接点の多さや取引頻度を示す重要指標
収益機会: 上位企業は高い顧客ロイヤルティを獲得している可能性があり、ベンチマーク対象として重要
リスクと機会
依存度リスク: 特定企業への依存が高い場合、その企業の動向が全体に大きく影響
成長機会: 中下位企業には大きな成長ポテンシャルが存在
競争環境: 上位企業と下位企業の格差拡大が競争環境に与える影響
4. さらなる分析のための質問例
トレンド分析
「過去6ヶ月間の企業別ポイント付与数の推移を月次で教えて」
「前年同月と比較した企業別ポイント付与数の増減率を教えて」
集中度・分布分析
「上位10社のポイント付与数の合計と全体に占める割合を教えて」
「ポイント付与数を10段階に分けた企業数の分布を教えて」
「ポイント付与数の平均値、中央値、標準偏差を教えて」
比較・ランキング分析
「ポイント付与数上位20社のランキングを降順で教えて」
「ポイント付与数が1億ポイント以上の企業一覧を教えて」
「各企業のポイント付与数が全体平均の何倍かを教えて」
セグメント分析
「企業コードの最初の文字別にポイント付与数を集計して」
「ポイント付与数を基準に企業を大・中・小の3グループに分けて分析して」
詳細調査
「特定企業(例:A004)の過去12ヶ月のポイント付与数推移を教えて」
「ポイント付与数の急激な変動があった企業を特定して」
これらの追加分析により、より深い洞察と具体的なアクションプランの策定が可能になります。
4.アプリ設計の説明
ここからはそれぞれのブロックの詳細仕様を説明します。エキスパートの方向けですが、初心者の方も今後も開発する時の参考して理解することで自身でも開発しやすくなると思います。
1. 初期設定・ライブラリインポートブロック
ブロックの解説
このブロックは、アプリケーション全体の基盤となる部分です。
必要なPythonライブラリのインポート、Streamlitのページ設定、アプリタイトル・説明文の表示、Snowflakeセッションの確立を行います。
この段階で、以降の処理(データ取得、可視化、AI連携など)に必要な全ての環境が整います。
ソースの全文(1~37行目)
# 1.初期設定・ライブラリインポートブロック
# ライブラリインポート
import streamlit as st
import pandas as pd
import json
import requests
import numpy as np
import matplotlib.pyplot as plt
import plotly.express as px
import plotly.graph_objects as go
from snowflake.snowpark.context import get_active_session
from snowflake.snowpark.exceptions import SnowparkSQLException
# Streamlitの設定
st.set_page_config(layout="wide")
# タイトルとアプリの説明
st.title("自然言語分析の標準設計アプリ")
st.markdown("このアプリはSnowflakeのCOMPLETE関数を使用して自然言語からSQLクエリを生成し実行した後、結果に対する分析考察を提供します。")
# セッション情報の取得
session = get_active_session()
# ダウンロード機能のfragment関数
@st.fragment
def download_analysis_fragment(analysis_result):
"""分析結果のダウンロード機能(fragment化で再描画を防ぐ)"""
st.markdown("### 📄 考察内容のダウンロード")
analysis_text = analysis_result.encode('utf-8')
st.download_button(
label="📄 考察をテキストファイルでダウンロード",
data=analysis_text,
file_name="ai_analysis_result.txt",
mime="text/plain",
key="download_analysis_button"
)
設計ポイント・解説
-
ライブラリの網羅的なインポート
データ操作(pandas, numpy)、可視化(matplotlib, plotly)、Webアプリ構築(streamlit)、Snowflake連携(「Snowpark」(SnowflakeでPythonコードを実行するためのライブラリ))とサービス実装に必要な主要ライブラリを過不足なくインポートしています。 -
ユーザー体験への配慮
st.set_page_config(layout="wide")でワイドレイアウトを指定し、データ表示やグラフを広く見せる設計です。
タイトル・説明文による目的の明示で、初回利用時の理解を促進します。 -
Snowflakeセッションの即時確立
get_active_session()で認証済みのSnowflakeセッションを取得し、以降のDB操作を一元管理。
Snowflake Native App/Streamlit in Snowflakeの標準的なベストプラクティスに沿っています。 -
可読性・拡張性重視
機能ごとにインポートをグループ化し、コメントで各処理の意図を明示。今後の機能追加や保守性にも配慮されています。
活用ポイントと汎用性
-
開発基本機能
Streamlit in Snowflakeアプリ開発の基本的な機能とその活用を理解出来ます。
他のデータソースや可視化ライブラリを使う場合も、ここをベースに必要な部分だけ差し替えればよい構成です。 -
初期化処理の重要性
アプリの初期段階で「依存関係の明示」「UIの初期化」「セッション管理」を済ませるため、後続の処理がシンプルな構成になります。
これは大規模・複雑なアプリでも共通する設計原則です。(偉そうにも言ってますw) -
ユーザー体験に沿ったシンプルな構成
説明文、レイアウトは、ユーザーの第一印象や利用開始時の迷いを減らすうえで非常に重要です。
社内外問わず、業務アプリやPoCでもこのような配慮を欠かさないことが推奨されます。
カスタマイズポイント
あえてダサイ名前にしているアプリ名称は早々に変えましょうw -
Snowflake連携アプリの標準構成
Snowflakeを使った分析アプリを作る際は、get_active_session()によるセッション確立が必須です。
これにより、認証・権限管理・クエリ実行が一貫して管理でき、セキュリティや運用面でも安心です。
このブロックをしっかり理解し、活用することで、どんなデータ分析アプリでも堅牢かつ拡張性の高い基盤を構築できます。
2. データベースメタデータ管理ブロック
ブロックの解説
このブロックは、Snowflakeデータベース内のデータベース、スキーマ、テーブル、テーブル構造(カラム情報)、およびサンプルデータを取得するための関数群で構成されています。
ユーザーがGUI上でデータソースを選択したり、テーブルの詳細を確認したりする際の基礎となる機能です。
SnowflakeのSHOW/DESCRIBEコマンドやSAMPLE句を活用し、データ探索の起点を担います。
ソースの全文(37~253行目)
# 2.データベーメタデータ管理ブロック
# データベース、スキーマ、テーブル(ビュー含む)のリストを取得する関数
def get_databases():
"""Snowflakeで利用可能なデータベースの一覧を取得する"""
df = session.sql("SHOW DATABASES").collect()
return [row["name"] for row in df]
def get_schemas(database):
"""選択されたデータベース内のスキーマの一覧を取得する"""
df = session.sql(f"SHOW SCHEMAS IN DATABASE {database}").collect()
return [row["name"] for row in df]
# データベース、スキーマ、テーブル(ビュー含む)のリストを取得する関数
def get_databases():
"""Snowflakeで利用可能なデータベースの一覧を取得する"""
df = session.sql("SHOW DATABASES").collect()
return [row["name"] for row in df]
def get_schemas(database):
"""選択されたデータベース内のスキーマの一覧を取得する"""
# データベース名をクォート
quoted_database = f'"{database}"'
df = session.sql(f"SHOW SCHEMAS IN DATABASE {quoted_database}").collect()
return [row["name"] for row in df]
def get_tables(database, schema):
"""選択されたデータベースとスキーマ内のテーブル、ビュー、マテリアライズドビュー、ダイナミックテーブルの一覧を取得する"""
try:
quoted_database = f'"{database}"'
quoted_schema = f'"{schema}"'
# INFORMATION_SCHEMAを使用してすべてのテーブル型オブジェクトを取得
query = f"""
SELECT
table_name,
table_type
FROM {quoted_database}.INFORMATION_SCHEMA.TABLES
WHERE table_schema = '{schema}'
AND table_type IN ('BASE TABLE', 'VIEW', 'MATERIALIZED VIEW', 'DYNAMIC TABLE')
ORDER BY table_name
"""
df = session.sql(query).collect()
# 型情報を除去してテーブル名のみを返す
return [row["TABLE_NAME"] for row in df]
except Exception as e:
# フォールバック: 従来のSHOW TABLESとSHOW VIEWSを組み合わせ
st.warning(f"INFORMATION_SCHEMA使用時にエラーが発生しました。代替方法を使用します: {str(e)}")
objects = []
quoted_database = f'"{database}"'
quoted_schema = f'"{schema}"'
try:
# テーブルを取得
df_tables = session.sql(f"SHOW TABLES IN {quoted_database}.{quoted_schema}").collect()
objects.extend([row["name"] for row in df_tables])
except:
pass
try:
# ビューを取得
df_views = session.sql(f"SHOW VIEWS IN {quoted_database}.{quoted_schema}").collect()
objects.extend([row["name"] for row in df_views])
except:
pass
try:
# マテリアライズドビューを取得
df_mviews = session.sql(f"SHOW MATERIALIZED VIEWS IN {quoted_database}.{quoted_schema}").collect()
objects.extend([row["name"] for row in df_mviews])
except:
pass
return sorted(list(set(objects))) # 重複除去とソート
def get_table_structure(database, schema, table):
"""テーブルの構造(カラム情報)とコメントを取得し、業務重要度順に並び替える"""
try:
quoted_database = f'"{database}"'
quoted_schema = f'"{schema}"'
quoted_table = f'"{table}"'
# DESCRIBE TABLEでカラム情報とコメントを取得
df = session.sql(f"DESCRIBE TABLE {quoted_database}.{quoted_schema}.{quoted_table}").collect()
result_df = pd.DataFrame(df)
if not result_df.empty:
# 業務重要度順にカラムを並び替え(除外対象カラムを含む)
priority_columns = ['name', 'type', 'comment', 'primary key', 'policy name']
# 除外するカラムを定義
exclude_columns = ['kind', 'null?', 'unique key', 'check', 'expression']
# 実際に存在するカラムのみを抽出(除外カラムを除く)
existing_priority_cols = [col for col in priority_columns if col in result_df.columns]
# 残りのカラム(優先度の低いもの)から除外カラムを除く
remaining_cols = [col for col in result_df.columns
if col not in existing_priority_cols and col not in exclude_columns]
# 新しいカラム順序
new_column_order = existing_priority_cols + remaining_cols
# カラム順序を変更
result_df = result_df[new_column_order]
# 列名を日本語化(除外カラムを除く)
column_mapping = {
'name': 'カラム名',
'type': 'データ型',
'comment': 'ビジネス用語・説明',
'policy name': 'ポリシー名',
'default': 'デフォルト値',
'privacy domain': 'プライバシードメイン'
}
# 存在するカラムのみリネーム
rename_mapping = {k: v for k, v in column_mapping.items() if k in result_df.columns}
result_df = result_df.rename(columns=rename_mapping)
# コメントが空の場合の表示を改善
if 'ビジネス用語・説明' in result_df.columns:
result_df['ビジネス用語・説明'] = result_df['ビジネス用語・説明'].fillna('(説明なし)')
return result_df
except Exception as e:
# ビューの場合はDESCRIBE VIEWを試行
try:
quoted_database = f'"{database}"'
quoted_schema = f'"{schema}"'
quoted_table = f'"{table}"'
df = session.sql(f"DESCRIBE VIEW {quoted_database}.{quoted_schema}.{quoted_table}").collect()
result_df = pd.DataFrame(df)
if not result_df.empty:
# 同様の並び替え処理(除外カラムを含む)
priority_columns = ['name', 'type', 'comment', 'primary key', 'policy name']
exclude_columns = ['kind', 'null?', 'unique key', 'check', 'expression']
existing_priority_cols = [col for col in priority_columns if col in result_df.columns]
remaining_cols = [col for col in result_df.columns
if col not in existing_priority_cols and col not in exclude_columns]
new_column_order = existing_priority_cols + remaining_cols
result_df = result_df[new_column_order]
# 日本語化
column_mapping = {
'name': 'カラム名',
'type': 'データ型',
'comment': 'ビジネス用語・説明',
'policy name': 'ポリシー名',
'default': 'デフォルト値'
}
rename_mapping = {k: v for k, v in column_mapping.items() if k in result_df.columns}
result_df = result_df.rename(columns=rename_mapping)
if 'ビジネス用語・説明' in result_df.columns:
result_df['ビジネス用語・説明'] = result_df['ビジネス用語・説明'].fillna('(説明なし)')
return result_df
except Exception as e2:
st.warning(f"{table}の構造取得中にエラーが発生しました: {str(e2)}")
return pd.DataFrame()
def get_sample_data(database, schema, table, rows=5):
"""テーブル/ビューのサンプルデータを取得する"""
try:
# オブジェクト名をすべてクォート
quoted_database = f'"{database}"'
quoted_schema = f'"{schema}"'
quoted_table = f'"{table}"'
# まずテーブル型を確認
table_type_query = f"""
SELECT table_type
FROM {quoted_database}.INFORMATION_SCHEMA.TABLES
WHERE table_schema = '{schema}' AND table_name = '{table}'
"""
try:
table_type_result = session.sql(table_type_query).collect()
if table_type_result and table_type_result[0]["TABLE_TYPE"] in ['BASE TABLE', 'DYNAMIC TABLE']:
# テーブルまたはダイナミックテーブルの場合はSAMPLEを使用
return session.sql(f"SELECT * FROM {quoted_database}.{quoted_schema}.{quoted_table} SAMPLE ({rows} ROWS)").to_pandas()
else:
# ビューまたはマテリアライズドビューの場合はLIMITを使用
return session.sql(f"SELECT * FROM {quoted_database}.{quoted_schema}.{quoted_table} LIMIT {rows}").to_pandas()
except:
# INFORMATION_SCHEMAアクセスに失敗した場合はLIMITで試行
return session.sql(f"SELECT * FROM {quoted_database}.{quoted_schema}.{quoted_table} LIMIT {rows}").to_pandas()
except Exception as e:
st.warning(f"{table}のサンプルデータの取得中にエラーが発生しました: {str(e)}")
return pd.DataFrame()
def get_table_type(database, schema, table):
"""テーブル/ビューの型を取得する(オプション関数)"""
try:
quoted_database = f'"{database}"'
query = f"""
SELECT table_type
FROM {quoted_database}.INFORMATION_SCHEMA.TABLES
WHERE table_schema = '{schema}' AND table_name = '{table}'
"""
result = session.sql(query).collect()
if result:
return result[0]["TABLE_TYPE"]
return "UNKNOWN"
except:
return "UNKNOWN"
設計ポイント・解説
-
単一責任・役割分離
各関数は「データベース一覧取得」「スキーマ一覧取得」「テーブル一覧取得」「テーブル構造取得」「サンプルデータ取得」と明確な役割分担を持ち、保守性・再利用性が高い設計を取っています。 -
Snowflake標準コマンドの活用
SHOW DATABASES、SHOW SCHEMAS、SHOW TABLES、DESCRIBE TABLEなど、Snowflakeの公式コマンドを活用し、メタデータ取得の信頼性とパフォーマンスを両立しています。
カスタマイズポイント
固定のテーブルで分析する場合は、選択せずに値を埋め込んでしまっても良いかもしれません。 -
エラー耐性とユーザー通知
メタデータ・サンプルデータ取得時の例外処理(try-except)で、基盤機能の安定性を確保します。 -
Pandas連携による柔軟性
メタデータやデータをpandas.DataFrameとして返却することで、後続の可視化・分析処理との連携が容易です。 -
日本語環境への完全対応
現状は日本語テーブルは少ないのですが、事業部門に提供する際に日本語名称のテーブルやビューで提供することが予想されます。そのため、全てのオブジェクト名にはダブルクォートで囲む処理を実装し、「ポイント変動履歴(AI)」のような日本語を含むテーブル名でもエラーなく動作するように制御しています。 -
業務ユーザー視点のテーブル構造表示
テーブル構造表示では、技術的な詳細よりも業務で重要な情報(カラム名、データ型、ビジネス用語、主キー)を先頭に配置し、現場ユーザーが理解しやすい形に整形しています。 -
SAMPLE句による効率化
サンプルデータ取得時にSAMPLE句を使うことで、大規模テーブルでもリソース消費を抑えつつ代表的なデータを取得できます。ここは個人情報や機微情報などに対するマスキングなどをロールベースで実装しておくと良いでしょう。(営業ユーザーはマスキング、アナリストはハッシュ値、管理ユーザーはフルアクセスなど。)
活用ポイントと汎用性
-
データ探索UIの標準部品
これらの関数は、Snowflakeを使ったデータ探索・可視化アプリの標準的な部品です。
他のStreamlitアプリやバッチ処理でも、そのまま流用できる構造になっています。 -
メタデータ管理の重要性
データベースやスキーマ、テーブルの構造を動的に取得できることで、ユーザーは「どんなデータがあり、どんな分析が可能か」を直感的に把握できます。
データガバナンスやセルフサービスBIの観点でも重要な設計です。
カスタマイズポイント
コメントにビジネス情報を入れておくと生成時に効果を感じる時があります。 -
例外処理・ユーザー通知の徹底
サンプルデータ取得時のエラー通知のように、失敗時もUIが破綻しない設計は、実運用での信頼性を大きく高めます。 -
pandas連携のメリット
DataFrame形式で返すことで、可視化・AI分析・エクスポートなど、Pythonデータ分析エコシステムとの親和性が高まります。
このブロックを理解し活用することで、Snowflake上のデータ探索・可視化アプリを素早く、堅牢に構築できるようになります。
また、メタデータ管理やエラー耐性、ユーザー通知の実装例など標準的な制御としても参考になるかと思います。
3. グラフ可視化ブロック
ブロックの解説
このブロックは、データフレームの内容をもとに、ユーザーが直感的にグラフをカスタマイズしながら可視化できる機能を提供します。
Streamlitのセッション状態を使ったグラフ設定の初期化、Plotlyを活用したインタラクティブなグラフ描画、そして「どのグラフタイプでどの軸・色分け・カテゴリを使うか」を動的にUIで選択できるように設計されています。
また、データの内容に応じて適切なグラフタイプや設定項目を自動的に制御し、ユーザー体験の一貫性と柔軟性を両立しています。
このブロックでは、「“グラフを作るのって難しそう…”という声に応えるための工夫」を詰めています。
たとえば、Streamlitのセッション状態を使っており、前に選んだ設定がちゃんと残る仕様のため、何度もやり直す手間がありません。
Plotlyのインタラクティブなグラフも、触ってみると「これなら会議でもそのまま使える!!」と実感できるはずです。
A. グラフ設定用セッション状態初期化(254~287行目)
# 3.グラフ可視化ブロック
# グラフ設定用のセッション状態を初期化する関数
def initialize_graph_state(df):
"""グラフ設定用のセッション状態を初期化する"""
# データからカラム情報を取得
numeric_cols = df.select_dtypes(include=['int64', 'float64']).columns.tolist()
categorical_cols = df.select_dtypes(include=['object', 'category', 'bool']).columns.tolist()
# 必要なセッション状態を初期化
if 'graph_type' not in st.session_state:
st.session_state.graph_type = '棒グラフ'
# データに基づいて軸と設定の初期値を設定
if 'x_axis' not in st.session_state and len(df.columns) > 0:
st.session_state.x_axis = df.columns[0]
if 'y_axis' not in st.session_state and len(df.columns) > 1:
st.session_state.y_axis = df.columns[1]
if 'color_option' not in st.session_state:
st.session_state.color_option = 'なし'
if 'size_option' not in st.session_state:
st.session_state.size_option = 'なし'
if 'name_col' not in st.session_state and len(categorical_cols) > 0:
st.session_state.name_col = categorical_cols[0]
if 'value_col' not in st.session_state and len(numeric_cols) > 0:
st.session_state.value_col = numeric_cols[0]
if 'hist_col' not in st.session_state and len(numeric_cols) > 0:
st.session_state.hist_col = numeric_cols[0]
if 'bin_count' not in st.session_state:
st.session_state.bin_count = 20
if 'box_value_col' not in st.session_state and len(numeric_cols) > 0:
st.session_state.box_value_col = numeric_cols[0]
if 'category_col' not in st.session_state:
st.session_state.category_col = 'なし'
解説・設計ポイント
- データ型ごとに軸や色分け、カテゴリ、ビン数などの初期値をセッション状態に保存します。
- これにより、グラフ設定UIの一貫性と再現性が担保され、ユーザー体験が向上します。
B. グラフ設定UI・描画本体(288~392行目)
# カスタムグラフ設定用のfragment関数
@st.fragment
def graph_fragment(df):
"""ユーザーがカスタマイズ可能なグラフを表示する"""
st.subheader("グラフ設定")
# 列の型を分析
numeric_cols = df.select_dtypes(include=['int64', 'float64']).columns.tolist()
categorical_cols = df.select_dtypes(include=['object', 'category', 'bool']).columns.tolist()
# グラフタイプの選択
graph_type = st.selectbox(
"グラフタイプを選択",
["棒グラフ", "折れ線グラフ", "散布図", "円グラフ", "ヒストグラム", "箱ひげ図"],
key="graph_type"
)
# 軸の選択(グラフタイプに応じて表示を変更)
if graph_type in ["棒グラフ", "折れ線グラフ", "散布図"]:
# X軸とY軸の選択
col1, col2 = st.columns(2)
with col1:
x_axis = st.selectbox("X軸を選択", df.columns, key="x_axis")
with col2:
y_axis_options = [col for col in df.columns]
y_axis = st.selectbox("Y軸を選択", y_axis_options, key="y_axis")
# 色分けオプションの選択
color_options = ["なし"] + [col for col in df.columns if col not in [x_axis, y_axis]]
color_option = st.selectbox("色分け項目(オプション)", color_options, key="color_option")
color_col = None if color_option == "なし" else color_option
# グラフ生成
if graph_type == "棒グラフ":
fig = px.bar(df, x=x_axis, y=y_axis, color=color_col, title=f"{x_axis}ごとの{y_axis}")
elif graph_type == "折れ線グラフ":
fig = px.line(df, x=x_axis, y=y_axis, color=color_col, title=f"{y_axis}の推移")
else: # 散布図
# サイズオプションの選択
size_options = ["なし"] + [col for col in numeric_cols if col not in [x_axis, y_axis]]
size_option = st.selectbox("サイズ項目(オプション)", size_options, key="size_option")
size_col = None if size_option == "なし" else size_option
fig = px.scatter(df, x=x_axis, y=y_axis, color=color_col, size=size_col, title=f"{x_axis} vs {y_axis}")
st.plotly_chart(fig, use_container_width=True)
elif graph_type == "円グラフ":
# カテゴリと値の列を選択
col1, col2 = st.columns(2)
with col1:
name_col = st.selectbox("カテゴリ列を選択",
categorical_cols if categorical_cols else df.columns,
key="name_col")
with col2:
value_options = numeric_cols if numeric_cols else [col for col in df.columns if col != name_col]
value_col = st.selectbox("値の列を選択", value_options, key="value_col")
# 円グラフ生成
pie_df = df.groupby(name_col)[value_col].sum().reset_index()
fig = px.pie(pie_df, names=name_col, values=value_col, title=f"{name_col}ごとの{value_col}の割合")
st.plotly_chart(fig, use_container_width=True)
elif graph_type == "ヒストグラム":
# 数値列と階級数を選択
col1, col2 = st.columns(2)
with col1:
hist_col = st.selectbox("分布を表示する列を選択",
numeric_cols if numeric_cols else df.columns,
key="hist_col")
with col2:
bin_count = st.slider("ビンの数", min_value=5, max_value=100, key="bin_count")
# ヒストグラム生成
fig = px.histogram(df, x=hist_col, nbins=bin_count, title=f"{hist_col}の分布")
st.plotly_chart(fig, use_container_width=True)
else: # 箱ひげ図
# 値とカテゴリの列を選択
col1, col2 = st.columns(2)
with col1:
value_col = st.selectbox("値の列を選択",
numeric_cols if numeric_cols else df.columns,
key="box_value_col")
with col2:
category_options = ["なし"] + [col for col in categorical_cols if col != value_col]
category_col = st.selectbox("カテゴリ列を選択(オプション)",
category_options,
key="category_col")
# 箱ひげ図生成
if category_col != "なし":
fig = px.box(df, x=category_col, y=value_col, title=f"{category_col}ごとの{value_col}の分布")
else:
fig = px.box(df, y=value_col, title=f"{value_col}の分布")
st.plotly_chart(fig, use_container_width=True)
解説・設計ポイント
- グラフタイプごとにUIと描画ロジックを分岐。
- ユーザーは軸や色分け、カテゴリ、ビン数などを直感的に選択可能。
-
@st.fragmentで部分的な再描画を実現し、パフォーマンスも最適化。
C. グラフ表示ラッパー(393~411行目)
# データのグラフ表示
def visualize_data(df):
"""データフレームをグラフとして可視化する"""
# データフレームが空の場合
if df.empty:
st.warning("表示するデータがありません")
return
# データが少なすぎる場合はグラフ化しない
if len(df) < 2:
st.info("データが少ないためグラフは表示しません")
return
# セッション状態を初期化
initialize_graph_state(df)
# グラフを表示
graph_fragment(df)
解説・設計ポイント
- データ量に応じてグラフ描画の可否を判定。
- グラフ設定初期化→描画の流れを一元化し、他の処理からも簡単に呼び出せる設計。
まとめ:このブロックの活用ポイント
- グラフ設定の初期化 ユーザー体験の一貫性を担保。
- グラフ設定UI・描画本体 柔軟かつ直感的な可視化体験を実現。
- グラフ表示ラッパー エラー耐性と再利用性を高めている。
設計ポイント・解説
-
セッション状態による一貫性の維持
initialize_graph_stateで、グラフ設定(グラフタイプや軸、色分け等)をセッション状態に保存。
再描画や設定変更時もユーザーの選択が維持され、快適な操作感を実現しています。 -
データ型に基づく動的UI制御
数値型・カテゴリ型カラムを自動判別し、グラフタイプごとに適切な選択肢のみを提示。
不適切な組み合わせを防ぎ、エラーや混乱を未然に防止します。 -
Plotlyによる高機能・インタラクティブな可視化
棒グラフ・折れ線・散布図・円グラフ・ヒストグラム・箱ひげ図など多様なグラフに対応。
Plotlyのインタラクティブ性(拡大縮小、ツールチップ、凡例切替等)をフル活用しています。 -
Streamlitのfragment活用 重要ポイント
@st.fragment デコレータ(Streamlit 1.33.0以降で導入された、アプリの特定部分のみを独立して再実行する機能)でグラフ設定部分のみの部分的再実行を実現し、大量データ処理時のパフォーマンス向上に大きく貢献しています。この実装により、弊社の大規模データでも快適な操作感を維持できています。 -
データ量に応じたガード
データが空または極端に少ない場合はグラフ描画を抑止し、ユーザーに警告や情報を返すことで、UIの破綻や誤解を防止。様々な運用ケースを想定したエラー制御が出来るようにしています。
活用ポイントと汎用性
-
可視化機能としての標準化
インタラクティブなデータ探索機能の実装パターンとして応用可能です。
グラフタイプや設定項目を追加する際も、初期化・UI・描画の分離により拡張が容易となるようにしています。 -
ユーザー主導のデータ探索体験
データ型に応じた選択肢制御や、グラフのカスタマイズ性は、セルフサービスBIやデータリテラシー向上にも有効です。 -
Plotlyの活用ポイント
Plotlyを使うことで、静的なグラフに比べて「発見的な分析」や「プレゼンテーション用途」に強みを発揮します。
Streamlitとの親和性も高く、Pythonエンジニアなら短期間で高品質な可視化機能を実装できます。 -
セッション状態の活用
Streamlitアプリの設計では、セッション状態を活用することで「ユーザーごとの操作履歴」や「設定の一時保存」など、より高度な体験設計が可能になります。
このブロックを理解し活用することで、データ可視化のUXを大きく向上させ、現場のデータ活用を加速しやすくなります。
また、業務要件に応じたグラフタイプや設定項目の追加・カスタマイズも容易に行えます。
4. AI SQL生成ブロック
ブロックの解説
このブロックは、ユーザーが自然言語で入力した質問や要件をもとに、Snowflake Cortexの「COMPLETE関数」(大規模言語モデルを使ってテキスト生成を行うSnowflakeのAI機能)を活用してSQLクエリを自動生成する機能を担います。
選択されたテーブルの構造やサンプルデータをプロンプトに含めることで、AIがより文脈に沿った正確なSQLを生成できる設計です。
また、生成されたSQLから不要な説明やマークダウンを除去し、実行可能なクエリのみを抽出する処理や、エラー時のフォールバック(代替実行)も実装しています。
ソースの全文(412~539行目)
# 4.AI SQL生成ブロック
# COMPLETE関数を使用してSQL生成
def generate_sql_with_llm(prompt, database, schema, tables):
"""Snowflake COMPLETE関数を使用して自然言語からSQLを生成する"""
try:
# すべてのテーブルに関する情報を収集
tables_info = []
for table in tables:
# オブジェクト名をクォート
quoted_database = f'"{database}"'
quoted_schema = f'"{schema}"'
quoted_table = f'"{table}"'
# テーブル構造の取得
table_info = session.sql(f"DESCRIBE TABLE {quoted_database}.{quoted_schema}.{quoted_table}").collect()
table_structure = "\n".join([f'"{row["name"]}" ({row["type"]})' for row in table_info])
# テーブルのサンプルデータを取得(5行)
try:
sample_data = session.sql(f"SELECT * FROM {quoted_database}.{quoted_schema}.{quoted_table} SAMPLE (5 ROWS)").collect()
sample_df = pd.DataFrame(sample_data)
sample_str = sample_df.to_string(index=False)
except Exception as e:
st.warning(f"{table}のサンプルデータの取得中にエラーが発生しました: {str(e)}")
sample_str = "サンプルデータを取得できませんでした。"
# テーブルごとの情報を追加
tables_info.append({
"name": table,
"structure": table_structure,
"sample": sample_str
})
# テーブル情報を結合したプロンプトを作成
tables_context = ""
for info in tables_info:
tables_context += f"""
テーブル名: {database}.{schema}.{info['name']}
テーブル構造:
{info['structure']}
サンプルデータ (5件):
{info['sample']}
"""
# ユーザープロンプトを作成
tables_list = ", ".join([f"{database}.{schema}.{table}" for table in tables])
full_prompt = f"""以下のテーブル構造とサンプルデータを持つテーブル [{tables_list}] に対して、
次の質問に答えるSQLクエリを生成してください:
{tables_context}
質問:
{prompt}
重要な注意事項:
- Snowflakeの標準SQLのみを使用してください
- 可能な限り素早く回答すること
- テーブル名、スキーマ名、カラム名は必ずダブルクォート(")で囲んでください
- 日本語のカラム名やテーブル名も適切にクォートしてください
- エイリアス(AS句で指定する別名)も日本語の場合は必ずダブルクォート(")で囲んでください
- 複数のテーブルに関する質問の場合は、適切なJOIN条件を使用してテーブルを結合してください
- SQLクエリのみを出力し、返事や説明などは不要です
"""
# Snowflake COMPLETE関数を使用してSQLを生成
result = session.sql("""
SELECT SNOWFLAKE.CORTEX.COMPLETE(
'mistral-large2',
?
) AS generated_sql
""", params=[full_prompt]).collect()[0]["GENERATED_SQL"]
# 余分なマークダウンや説明文を取り除き、SQLクエリだけを抽出
sql_query = result.strip()
if sql_query.startswith("```sql"):
sql_query = sql_query.split("```sql")[1]
elif sql_query.startswith("```"):
sql_query = sql_query.split("```")[1]
if "```" in sql_query:
sql_query = sql_query.split("```")[0]
# コメント行を削除
clean_lines = []
for line in sql_query.split("\n"):
if not line.strip().startswith("--") and line.strip():
clean_lines.append(line)
return "\n".join(clean_lines).strip()
except Exception as e:
st.error(f"SQL生成エラー: {str(e)}")
st.write("エラーの詳細:")
st.code(str(e))
# フォールバック: パラメータバインディングを使わない方法
try:
st.info("代替方法で再試行中...")
# シングルクォートをエスケープしてSQL文に直接埋め込む
escaped_prompt = full_prompt.replace("'", "''")
result = session.sql(f"""
SELECT SNOWFLAKE.CORTEX.COMPLETE(
'mistral-large2',
'{escaped_prompt}'
) AS generated_sql
""").collect()[0]["GENERATED_SQL"]
# 余分なマークダウンや説明文を取り除き、SQLクエリだけを抽出
sql_query = result.strip()
if sql_query.startswith("```sql"):
sql_query = sql_query.split("```sql")[1]
elif sql_query.startswith("```"):
sql_query = sql_query.split("```")[1]
if "```" in sql_query:
sql_query = sql_query.split("```")[0]
# コメント行を削除
clean_lines = []
for line in sql_query.split("\n"):
if not line.strip().startswith("--") and line.strip():
clean_lines.append(line)
return "\n".join(clean_lines).strip()
except Exception as e2:
st.error(f"SQL生成の再試行もエラー: {str(e2)}")
return None
設計ポイント・解説
-
SQL生成特化プロンプト設計
テーブル構造とサンプルデータを含むプロンプトにより、複数テーブルのJOINを含む高精度なSQL生成を実現しています。
また日本語テーブルやエイリアスの日本語名も考慮し、ダブルクォートで囲むよう明示的に指示しています。 -
複数テーブル・JOIN対応
テーブルリストを動的にプロンプトへ反映し、「複数テーブルをJOINする場合は適切な結合条件を使う」旨も明示。
これにより実務的なデータ分析・横断集計にもAIを活用できます。 -
生成SQLのクリーンアップ
LLMの出力には説明文やマークダウン(```sql など)が含まれることが多いため、正規表現や分割処理で純粋なSQLのみを抽出。
コメント行も除去し、実行時のエラーや混乱を防止しています。
この制御は多くの開発者が課題とする実装部分ですが、こちらを参考にすることで簡単に実装ができます。 -
AI処理レイヤーの堅牢性
パラメータバインディング失敗時の自動フォールバックで、SQL生成の継続性を保証します。 -
ユーザーへの丁寧なフィードバック
エラー発生時は詳細なエラーメッセージや再試行状況をUIで明示し、原因特定や対処しやすくなるように考慮しています。
活用ポイントと汎用性
-
標準アーキテクチャとしてリファレンス
このアプリは、弊社のStreamlit in Snowflake開発における標準アーキテクチャとして位置づけようと考えています。全体的な機能を包括的に学ぶことが出来ますし、またアナリスト、エンジニア、サイエンティストと多岐に渡るスキルセットに対し、自分の強みはカスタマイズしていき、弱みの部分は標準仕様にお任せするなど、このパターンをベースとすることで、開発効率と品質の両立を図ります。特にアナリスト部門にとっては、普段経験することが少ない、データサイエンスやハンドリング部分をお任せ出来るのは大きいと思います。
-
プロンプト設計の重要性
テーブル構造、サンプルデータ、質問内容を丁寧にプロンプトへ含めることで、AIのアウトプット品質が大きく向上します。
これもAI活用の現場で最も重要な設計ポイントの一つです。 -
エラー耐性、運用性の確保
LLMの出力形式やSnowflakeの仕様差異によるトラブルにも柔軟に対応できる設計は、業務システムとしての信頼性を高めようとしています。 -
JOINや複雑なSQLも対応可能
複数テーブル選択やJOIN条件の自動生成も可能なため、単純な単表分析だけでなく、実務でよくある横断集計、複雑な分析にも応用しやすい構成にしています。
このブロックを理解し、活用することで、自然言語によるデータ分析自動化や、AIを活用した業務効率化を高品質かつ安全に実現しやすくなります。
また、プロンプト設計、エラー処理、出力クリーンアップの考え方は、他のAI連携アプリ開発にも大いに役立つのではないかと考えています。
5. AI分析考察ブロック
ブロックの解説
このブロックは、SQL実行結果(DataFrame)に対して、Snowflake CortexのCOMPLETE関数を活用し、AIによる自動的な分析、考察を生成する機能を担います。
元の質問内容、実行されたSQL、データの基本情報やサンプルデータをプロンプトに含めることで、AIが文脈を正確に把握し、ビジネス的なインサイトや次のアクション提案まで含めた多角的な分析を日本語で返す設計にしています。
エラー時の例外処理やユーザー通知も含まれ、実用性とユーザー体験に配慮されています。
なお、COMPLETE関数について以前に書いた僕の記事が参考にしていただければと思います。
ソースの全文(540~593行目)
# 5.AI分析考察ブロック
# COMPLETE関数を使用してクエリ結果の分析考察を生成
def generate_analysis_with_llm(df, original_prompt, generated_sql):
"""クエリ結果を分析してCOMPLETE関数で考察を生成する"""
try:
# データフレームの基本情報を取得
sample_data = df.head(10).to_string(index=False)
# 分析プロンプトを作成
analysis_prompt = f"""
以下のデータ分析結果について、詳細な考察とインサイトを提供してください:
【元の質問】
{original_prompt}
【実行されたSQL】
{generated_sql}
【データの基本情報】
- 行数: {len(df)}
- 列数: {len(df.columns)}
- 列名: {', '.join(df.columns)}
【サンプルデータ(10行)】
{sample_data}
以下の観点から分析と考察を提供してください:
1. データの概要と傾向
2. 注目すべき数値やパターン
3. ビジネス上の意味や示唆
4. さらなる分析のための質問例(自然言語での質問形式で提案)
重要な注意事項:
- 「さらなる分析の提案」では、SQLコードではなく、このアプリの質問入力欄に入力できる自然言語での質問例を提案してください
- 例:「月次でのトレンド分析を行いたい場合は『各月の企業別ポイント付与数の推移を教えて』」
- 例:「上位企業の集中度を知りたい場合は『上位10社のポイント付与数の合計と全体に占める割合を教えて』」
日本語で分かりやすく回答してください。
"""
# COMPLETE関数を使用して分析を生成
result = session.sql("""
SELECT SNOWFLAKE.CORTEX.COMPLETE(
'mistral-large2',
?
) AS analysis_result
""", params=[analysis_prompt]).collect()[0]["ANALYSIS_RESULT"]
return result
except Exception as e:
st.error(f"分析生成エラー: {str(e)}")
return "分析の生成中にエラーが発生しました。出力結果とグラフを参考に手動で分析を行ってください。"
設計ポイント・解説
-
分析特化プロンプト設計
実行結果の文脈(元質問・SQL・データ統計)を組み合わせ、ビジネス洞察に特化した考察を生成します。
これにより、単なる要約ではなく、データの傾向や注目点、ビジネス的な示唆、追加分析案までカバーした多角的なアウトプットが得られます。 -
観点の明示
「概要」「注目点」「ビジネス示唆」「さらなる分析提案」といった観点を明示的に指示することで、アウトプットの品質と一貫性を担保しています。
またデフォルトでは、追加質問のSQLコード提案を行ってしまうので、「このアプリの質問入力欄にそのまま入力できる自然言語での質問例」を提案するように改善しました。これにより、SQLを知らないユーザーでも継続的な分析が可能になります。 -
日本語での分かりやすい説明
実務現場を意識し、「日本語で分かりやすく」と明記。現場担当者や非エンジニアでも理解しやすいアウトプットを実現します。 -
分析レイヤーの冗長性
AI分析失敗時の手動分析ガイダンスで、業務継続性を維持します。
活用ポイントと汎用性
-
AI統合としての標準化
自然言語処理とデータ分析を組み合わせたワークフローの参考実装です。 -
プロンプト設計の重要性
分析対象の文脈(質問、SQL、データ内容)を丁寧にプロンプトへ含めることで、AIのアウトプット品質が大きく向上します。
AI活用の現場では、この「プロンプトエンジニアリング」が成果を左右します。 -
ビジネス現場での実用性
単なる数値の羅列ではなく、「意味」「示唆」「次のアクション」まで自動で提案できるため、データドリブンな意思決定を加速できます。 -
エラー時の運用配慮
AI分析が失敗しても、ユーザーが手動で分析できるようにガイドする設計は、現場運用での信頼性を高めます。
このブロックを理解し活用することで、AIによる自動分析や解釈機能を高品質かつ安全に業務へ組み込むことができます。
プロンプト設計やエラー処理の考え方は、他のAI連携アプリ開発にも大いに役立ちます。
6. ユーザーインターフェースブロック
ブロックの解説
このブロックは、Streamlitアプリ全体のユーザーインターフェースを統合的に構築する部分です。
サイドバーでのデータベース、スキーマ、テーブル選択、テーブル構造やサンプルデータの表示、自然言語での質問入力、SQL生成と実行、データ表示、グラフ、AI考察のタブ切り替え、CSVダウンロード、エラー通知、フッター表示まで、データ分析体験の一連の流れを直感的かつ整理されたUIで提供します。
A. データソース選択UI(594~615行目)
# 6.ユーザーインタフェースブロック
# サイドバーにデータベース、スキーマ、テーブルの選択ボックスを配置
st.sidebar.header("データソースの選択")
# データベースの選択
databases = get_databases()
selected_database = st.sidebar.selectbox("データベースを選択", databases)
# スキーマの選択
if selected_database:
schemas = get_schemas(selected_database)
selected_schema = st.sidebar.selectbox("スキーマを選択", schemas)
else:
selected_schema = None
# テーブルの選択(複数選択に変更)
if selected_database and selected_schema:
tables = get_tables(selected_database, selected_schema)
selected_tables = st.sidebar.multiselect("テーブルを選択(複数選択可)", tables)
else:
selected_tables = []
解説
- サイドバーでデータベース→スキーマ→テーブルやビュー(複数選択)を段階的に選ぶ設計。
- 現場ユーザーでも迷わず操作できるUXを実現。
B. テーブル構造とサンプルデータ表示(616~654行目)
# テーブル構造の表示(複数オブジェクト対応)
if selected_database and selected_schema and selected_tables:
for table_with_type in selected_tables:
# テーブル名から型情報を分離
if " (" in table_with_type:
table_name = table_with_type.split(" (")[0]
object_type = table_with_type.split(" (")[1].rstrip(")")
else:
table_name = table_with_type
object_type = "TABLE"
with st.expander(f"{object_type}: {table_name}"):
# テーブル構造を表示
table_structure = get_table_structure(selected_database, selected_schema, table_name)
if not table_structure.empty:
st.subheader("カラム情報")
# コメントの有無で表示方法を変更
if 'ビジネス用語・説明' in table_structure.columns:
comment_count = len(table_structure[table_structure['ビジネス用語・説明'] != '(説明なし)'])
st.info(f"💡 {comment_count}個のカラムにビジネス用語・説明が設定されています")
# 業務重要度順で表示
st.dataframe(table_structure, use_container_width=True)
else:
st.error("構造情報を取得できませんでした")
# サンプルデータの表示
try:
st.subheader(f"サンプルデータ (10件): {table_name}")
sample_data = get_sample_data(selected_database, selected_schema, table_name)
if not sample_data.empty:
st.dataframe(sample_data)
else:
st.warning("サンプルデータを取得できませんでした")
except Exception as e:
st.warning(f"サンプルデータの表示中にエラーが発生しました: {str(e)}")
解説
- 各テーブルの構造とサンプルデータを
st.expanderで折りたたみ表示。 - 画面の整理と情報の即時確認を両立。
C. 質問入力とSQL生成実行UI(655~721行目)
# 自然言語の質問入力
st.header("質問入力")
st.markdown("選択したテーブルに対して自然言語で質問してください。LLMが適切なSQLクエリを生成し実行します。複数テーブルを選択した場合は、JOIN操作を含むクエリも生成できます。")
user_prompt = st.text_area("テーブルに関する質問を入力してください", height=100)
# SQL生成・実行ボタン(条件付きの表示と実行)
if all([selected_database, selected_schema]) and selected_tables:
execute_button = st.button("SQLを生成して実行", key="execute_button")
if execute_button and user_prompt:
with st.spinner("SQLを生成中..."):
# SQLの生成(複数テーブル対応)
generated_sql = generate_sql_with_llm(user_prompt, selected_database, selected_schema, selected_tables)
if generated_sql:
# 生成されたSQLを表示
st.subheader("生成されたSQL")
st.code(generated_sql, language="sql")
# SQLの実行
try:
with st.spinner("クエリを実行中..."):
result_df = session.sql(generated_sql).to_pandas()
# 結果の表示(タブで分ける)
result_tabs = st.tabs(["抽出結果", "グラフ表示", "AI分析考察"])
with result_tabs[0]:
st.subheader("実行結果")
st.dataframe(result_df)
# CSVダウンロードボタン
csv = result_df.to_csv(index=False).encode('utf-8')
st.download_button(
label="CSVとしてダウンロード",
data=csv,
file_name="query_result.csv",
mime="text/csv",
)
with result_tabs[1]:
st.subheader("データの可視化")
# データをグラフとして表示
visualize_data(result_df)
with result_tabs[2]:
st.subheader("AI分析考察")
with st.spinner("分析考察を生成中..."):
# COMPLETE関数を使用して分析考察を生成
analysis_result = generate_analysis_with_llm(result_df, user_prompt, generated_sql)
# 分析結果を表示
st.markdown(analysis_result)
# ダウンロード機能をfragmentとして実装
download_analysis_fragment(analysis_result)
except SnowparkSQLException as e:
st.error(f"SQL実行エラー: {str(e)}")
elif execute_button and not user_prompt:
st.warning("質問を入力してください。")
else:
st.warning("データベース、スキーマ、テーブルを選択してください。少なくとも1つのテーブルを選択する必要があります。")
# フッター
st.markdown("---")
st.caption("Created by CCC MK HOLDINGS Co.,Ltd.")
解説
- 自然言語質問入力、SQL生成と実行、タブによる結果、グラフ、AI考察の切り替え、CSVダウンロード、エラー通知、フッター表示までを一気通貫で実装。
- 各機能の区切りごとに
st.spinnerやst.warningなどでユーザーの迷いを防止。
まとめ
- 573~594行目:データソース選択UI
- 595~633行目:テーブル構造とサンプルデータ表示
- 635~697行目:質問入力とSQL生成実行、結果表示、フッター
設計ポイント・解説
-
段階的なデータソース選択UI
サイドバーでデータベース→スキーマ→テーブル(複数選択可)と段階的に選択でき、迷いなく目的のデータに到達できる設計です。 -
テーブル構造とサンプルデータの即時確認
選択した各テーブルの構造やサンプルデータをst.expanderで折りたたみ表示し、画面の整理と情報の即時確認を両立。 -
自然言語質問→AI SQL生成→実行まで一気通貫
ユーザーは自然言語で質問を入力し、SQL生成と実行、結果確認までワンクリックで完結。
複数テーブル選択時はJOINを含むクエリも自動生成され、現場の実務に即した柔軟性を持ちます。 -
タブによる結果の整理
データテーブル、グラフ表示、AI分析考察をタブで切り替えられ、情報の整理とアクセス性が高い。 -
CSVダウンロード機能
実行結果をワンクリックでCSVとして出力でき、分析結果の二次利用やレポート作成も容易。 -
エラー時のガイダンス
SQL生成と実行、分析考察の各段階でエラーが発生した場合も、適切な警告やエラーメッセージを表示し、ユーザーの迷いを防止。 -
フッターで責任者明示
作成者名を明記し、アプリの信頼性や問い合わせ先の明確化に寄与。
活用ポイントと汎用性
-
統合アプリとしての標準化
エンドツーエンドのデータ分析体験を提供する標準機能を網羅したソリューションです。
この構成は、データ選択→構造確認→質問→SQL生成と実行→結果確認→可視化→AI分析という一連の分析フローを、エンジニア以外でも直感的に使える形で提供しています。 -
情報整理と段階的開示の重要性
サイドバーやタブ、エクスパンダを活用し、複雑な情報も見やすく整理。
これは大規模データや多機能アプリでも必須の設計思想です。 -
AIと人の協調設計
AIによる自動化(SQL生成と分析考察)と、人による操作と確認(質問入力、データ確認)をシームレスに統合。
現場でのデータリテラシー向上や、分析業務の効率化に大きく寄与します。 -
エラー処理とガイダンスの徹底
どの段階で失敗してもユーザーが迷わないようにガイダンスを徹底。
実運用を見据えたUI設計の好例です。
このブロックを理解し、活用することで、AI×データ分析の現場業務を劇的に効率化し、誰もがデータを活用できる環境を実現できます。
また、Streamlit in SnowflakeのUI設計とユーザー体験のベストプラクティスとしても非常に参考になります。
総括とまとめ:Streamlit in Snowflakeによる自然言語SQL分析アプリの全体像
1. アプリ全体の設計思想と構造
様々なデータ×AIサービスを開発していくこと想定し、汎用的な要素を整理しておくことが重要です。特に共通処理、データハンドリング、グラフ可視化そしてそれらを実行するためのTEXT2SQLとその結果に対するAI分析、それらをつなぐユーザーインタフェースとなります。それら6つの明確な機能ブロックで構成されたアプリを理解することで、それらを体系的に学ぶことができます。
-
初期設定とライブラリインポート
必要な分析と可視化、Snowflake連携ライブラリを過不足なく選定しており、UI初期化やセッション確立までを一気通貫で実施し、以降の全処理の堅牢な基盤を構築することが可能です。 -
データベースメタデータ管理
SnowflakeのSHOW/DESCRIBEコマンドを巧みに活用し、データベース、スキーマ、テーブル、テーブル構造とサンプルデータを動的に取得。「ユーザーが迷わずデータ探索する体験」ができるように設計しています。 -
グラフ可視化
データ型に応じた動的なUI制御、セッション状態による一貫した操作性、Plotlyによるインタラクティブなグラフ描画を実現しています。たとえば「現場でよくある"どの軸を選べばいいの?"という迷い」も、データの型を自動で判別するため、選べるグラフや軸が自然に出てきます。
-
AI SQL生成
Snowflake CortexのCOMPLETE関数を最大限活用することでコストを最適化しています。テーブル構造とサンプルデータをプロンプトに含める工夫で、AIの精度と実用性を最大化。出力クリーンアップやエラーハンドリングまでを意識しています。 -
AI分析考察
SQL実行結果をもとに、元質問、SQL、データ内容を巧妙にプロンプト化し、AIによる多角的な分析、インサイトと追加提案を自動生成します。 -
ユーザーインターフェース
サイドバーによるデータソース選択から、エクスパンダでの構造とサンプルデータ確認、自然言語質問、SQL生成と実行、結果表示、グラフ、AI考察のタブ切り替え、CSVダウンロード、エラー通知、フッター表示までを誰でも迷わず使えるインターフェースを目指しています。
2. 設計と実装におけるポイント
-
責務分離と保守性への深い配慮
各機能を独立した関数とブロックで設計し、拡張や修正が容易な構造を実現。エンタープライズ用途でも十分な保守性を備えた、まさにプロフェッショナルな設計です。 -
統合的プロンプト戦略
SQL生成と分析考察で異なるプロンプト戦略を採用し、各段階で最適化されたAI活用を実現しています。 -
現場ユーザーへの思いやり
各機能で特化したUX配慮を統合し、現場での実用性を最大化しています。 -
AI×人の協調設計
AIによる自動化(SQL生成と分析考察)と、人による操作と確認(質問入力、データ確認)をシームレスに統合。「現場でのデータリテラシー向上」も含めた設計思想にしています。 -
多層防御エラー制御
データ・AI・分析の各レイヤーで特化したエラー処理により、システム全体の信頼性を実現しています。
3. アプリの汎用性と活用のポイント
-
セルフサービスBIの追求
他のデータ分析アプリや業務ダッシュボードにもそのまま流用出来るように設計しています。特に「自然言語×AI×可視化×現場UX」の組み合わせは、今後のデータ活用基盤の有力な選択肢の一つとなる可能性があります。 -
プロンプト設計・AI連携の実践
LLM活用時のプロンプト設計、出力クリーンアップ、エラー時のフォールバックなど、AI連携アプリ開発の実践的なノウハウが詰まっており、様々な場面でのリファレンスに出来ます。 -
現場業務への展開
データベースやテーブル構造が頻繁に変わる現場でも、動的なメタデータ取得やサンプルデータ表示により、現場主導の柔軟な分析が可能になります。また実行するユーザーのロールに従い、テーブルのアクセス制御なども継承されるため、事故が起きにくい設計になっています。 -
教育・リテラシー向上
生成されたSQLの可視化やAI考察の自動生成は、データリテラシー教育やOJTにも大いに活用できます。
4. 菅野さんへの感謝とまとめ
今回のアプリは、弊社がいつもお世話になっている、Snowflakeの菅野さんへの僕の滅茶苦茶無茶(茶の3段活用w)な依頼から始まっています。
お願いした内容
- プログラムやSQLが苦手な人(つまり僕)でも簡単に実行出来るアプリを用意したい
- テーブルの指定とそれに対する自然言語でのクエリ、結果の可視化と考察機能があること
- COMPLETE関数を活用し、柔軟なカスタマイズとコスト効率が高いアプリであること
- それをリファレンスにし、多様なスキルセットのメンバーでも開発出来るガイドラインアプリにしたい
- 非エンジニアがAIアプリの開発と実感をできるようにし、SiSやCortexへのハードルを下げたい
そんな難題に対し、菅野さんからスーパーミラクルダイナマイトなStreamlit in Snowflakeアプリのソースを提供いただきました。そしてそんな貴重なアプリを僕が不慣れにもClaudeなどを用いて、運用目線での細かい制御や見直しを追加して、自分なりに汎用的なアプリに仕上げました。
いただいたサンプルソースは400行を超えたものでしたが、Pythonのソースを見ながら自分で、色々実運用で様々なケースを考慮した改修を加えていく中で気が付けば700行を超えてしまいました。
5. みんな使ってくれるといいな♪
元々は弊社からの要望ではあったのですが、ソースをいただき、いざ作り上げてみると、これを弊社だけのものにするのはもったいないなと思い、このテーブル選択、自然言語によるSQL生成、データ可視化、AI分析考察機能を持つアプリケーションとその解説記事を合わせて公開したいと思いました。
もちろん菅野さんにはお断りを入れた上で今回公開に至っております。
偉そうにも皆さんにシェアすることで、様々な企業のSnowflakeを活用した取組みがさらに加速し、それらは結果的にSnowflake自体の価値向上や新たな機能やサービスを生み出し、我々も含めて多くの企業のデータ×AIドリブン経営の進化の一助になったらいいなと考えております。
不勉強ながら作り上げたアプリですので、至らない点も多いかもしれませんが、皆様のご参考になれば幸いです。

Snowflake データクラウドのユーザ会 SnowVillage のメンバーで運営しています。 Publication参加方法はこちらをご参照ください。 zenn.dev/dataheroes/articles/db5da0959b4bdd
Discussion