この記事はSnowflake Advent Calendar 2021の5日目の記事です。
Snowflakeの便利なSQL構文「マルチテーブルINSERT」を紹介します!
マルチテーブルINSERTとは?
その名の通り、複数テーブルに一括でデータを挿入できるSQL構文です。
VALUES句を使うこともできますが、INSERT ALL INTO ... SELECT ... のように使えば、サブクエリで取得した結果を複数テーブルに挿入することができます。
面白いのが「条件付きマルチテーブルINSERT」です。when ... then ... の構文で、取得した結果を行ごとに判定して複数テーブルに振り分けて挿入することができます。これを使うと何億行のデータであっても、行ごとの値に応じたデータの振り分け先をINSERTの1文で制御することができます。
何がうれしいの?いつ使うの?
マルチテーブルINSERTは標準SQLではありませんが、Snowflake以外にもマルチテーブルINSERTが実装されているDBMSはあります。わざわざクライアント側に一度取得して一行ずつ判定ロジックを挟む必要がなく、膨大な量のデータ変換を全てDB側で処理できるので、性能的に非常に有利です。
しかもさらにSnowflakeでは、Snowpipe、ストリーム、タスク等と一緒に利用してデータパイプラインを構築するときに、このマルチテーブルINSERTが絶大な威力を発揮します。
Snowflakeには、バッチサーバやジョブ管理ツールがなくても単独でデータロードからデータマート作成までを自動で実行できる機能がそろっています。下図参照。
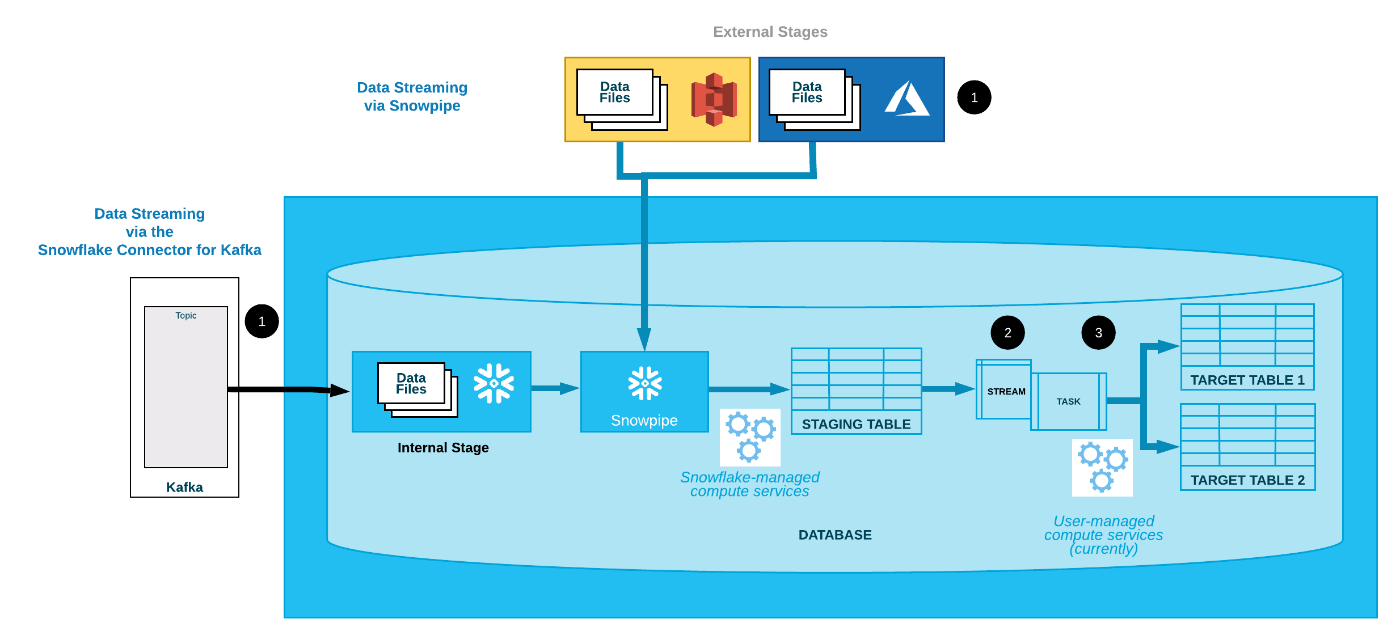
引用:https://docs.snowflake.com/ja/user-guide/data-pipelines-intro.html
通常、SnowpipeやKafka Connectorでロードされるテーブル(ステージングテーブル)は、そのままでは分析等に使いづらいため、マートテーブルに変換されることになります。このとき、ストリームとタスクを使えば、Snowflake単体でステージングテーブルにデータが着弾したことを自動的に検知し、変換クエリを実行することができます。
このような構成でよくあるのが、ステージングテーブルには全てのデータが集まるものの、マートテーブルは複数分類ごとに作成しなければならない、というような状況です。(図でもSTAGING TABLEは一つですが、TARGET TABLEは複数に分かれていますよね)
ここで、一回のTask実行で複数のマートテーブルを作成する必要が出てきます。マルチテーブルINSERTの出番です。
やってみる
簡単な例でやってみましょう。Snowpipeやストリーム、タスクの設定については別の記事に譲るとして、今回は単純にステージングテーブルに溜まったデータを2つのテーブルに振り分ける簡単なマルチテーブルINSERTを実行してみます。
以下のようなソースデータ(CSVファイル)があるとします。
1,A,100
2,B,200
3,A,300
4,A,400
5,B,500
上記のデータをステージングテーブル(STAGING_TABLE)にロードし、それを2つのマートテーブル(MART_TABLE_AとMART_TABLE_B)にカテゴリーごとに格納します。3つのテーブルの定義は以下の通りです。
create table STAGING_TABLE (ID number, CATEGORY varchar, NUM number);
create table MART_TABLE_A (ID number, CATEGORY varchar, NUM number);
create table MART_TABLE_B (ID number, CATEGORY varchar, NUM number);
STAGING_TABLEにデータをロードします。今回はWebUIからサクッとロードしてしまったので省略。
そしてマルチテーブルINSERTです。STATING_TABLEから全レコードを取得してwhen ... then ...でカテゴリーA/Bを振り分けます。
insert all
when CATEGORY = 'A' then
into MART_TABLE_A
when CATEGORY = 'B' then
into MART_TABLE_B
select ID, CATEGORY, NUM from STAGING_TABLE
;
上記を実行すると、こんな結果が返ってきます。うまくいってそうですね。
| number of rows inserted into MART_TABLE_A | number of rows inserted into MART_TABLE_B |
|---|---|
| 3 | 2 |
各テーブルを見てみると、MART_TABLE_Aには以下のデータが挿入されています。
| ID | CATEGORY | NUM |
|---|---|---|
| 1 | A | 100 |
| 3 | A | 300 |
| 4 | A | 400 |
そしてMART_TABLE_Bには以下のデータ。
| ID | CATEGORY | NUM |
|---|---|---|
| 2 | B | 200 |
| 5 | B | 500 |
1つのSQL文でテーブルを読み取って中身を見て2つのテーブルに振り分けることが簡単に実現できているのがわかるでしょうか。
さらにストリームとタスクを定義して、ストリームの差分データのみを参照するようなマルチテーブルINSERTのタスクを作れば、自動的にステージングテーブルの変更を検知して複数テーブルにデータを配分するデータパイプラインの完成です。
ELTがはかどる!
今回はとても単純な例でしたが、サブクエリ内で複数テーブルを結合したり、when句に関数を使った複雑な条件を設定したり、挿入先テーブルの判定にelseを使うこともできます。SQLによるデータ変換の幅がぐっと広がって、使い方は無限にありそうですよね。
近年、データの変換ロジックがDBの外側に置かれるETL(Extract(抽出)→Transform(変換)→Load(ロード))ではなく、DBに格納してからデータを変換するELT(Extract(抽出)→Load(ロード)→Transform(変換) )がデータエンジニアリングにおける主流になってきています。
Snowflakeはそのスケーラビリティや柔軟性から、元々とてもELT向きのDBです。先述の通りストリームやタスク等、ELT向けの機能も豊富に揃っています。
その中で、ワンクエリの中にロジックを書いてデータ変換できるこのマルチテーブルINSERTを使いこなせると、さらに効率的にSnowflakeの中でのデータ変換ができるのではないでしょうか。
マルチテーブルINSERTを上手に使って、ELTしましょう!

Snowflake データクラウドのユーザ会 SnowVillage のメンバーで運営しています。 Publication参加方法はこちらをご参照ください。 zenn.dev/dataheroes/articles/db5da0959b4bdd
Discussion