本記事では、Amazon Data Firehose というサービスを使用して CloudWatch ログを S3 Tables の Iceberg テーブルに対してニアリアルタイムに配信する方法について紹介します。また、Snowflake で Iceberg REST カタログ統合を構成して、配信先 Iceberg テーブルを Snowflake からも参照可能にするところまでやってみたいと思います。
Amazon Data Firehose について
概要
Amazon Data Firehose は、ストリーミングデータのニアリアルタイムな配信プラットフォームを簡単に構築できるマネージドサービスです。以前は Amazon Kinesis Data Firehose というサービス名でしたが、2024年2月9日に名称変更されました。[1]
ストリーミングデータのソースとしては、Amazon Kinesis Data Streams や Amazon Managed Streaming for Apache Kafka (MSK) の他、Firehose ストリームに直接レコードを送信するための Direct PUT API を提供しており、様々な取り込みソースに対応できます。また、指定可能な宛先はソースの種類によって異なりますが、S3 や OpenSearch Service, Redshift といった他 AWS サービス、Snowflake, Splunk のような外部製品など様々なものをサポートしており、SIEM や IoT のようなリアルタイム性の求められるユースケースにおいて有用なサービスだと思います。
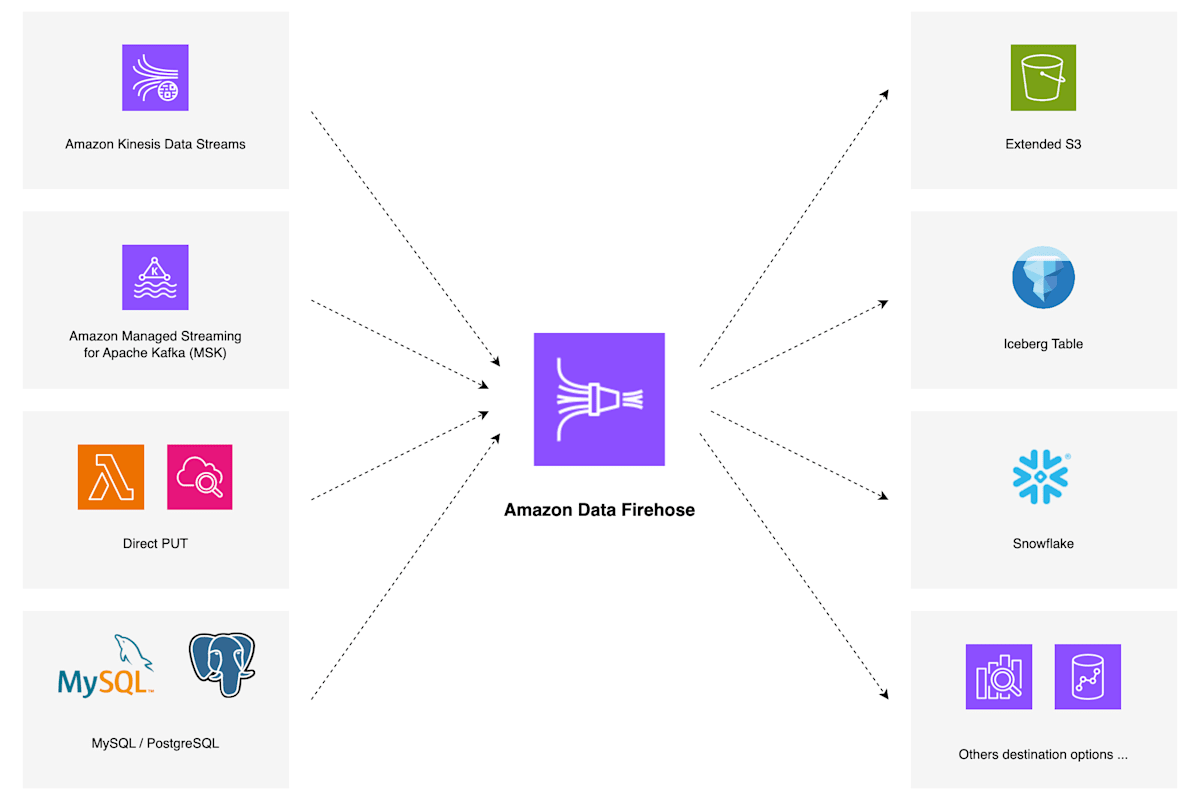
Data Firehose はマネージドサービスとして以下のような機能を提供しています。
- 指定のデータサイズ・時間間隔でバッファリングする
- ソースから受け取ったレコードを宛先に配信する前に Lambda 関数でデータ変換する
- 配信失敗レコードに関する情報を S3 に自動退避する
Apache Iceberg テーブル対応
Amazon Data Firehose は、2024年10月に S3 の Apache Iceberg テーブルが宛先として指定可能になっており、その後の AWS re:Invent 2024 で発表された S3 Tables の Iceberg テーブルについても現在サポートされています。
Iceberg テーブルにデータを蓄積しておくことで、AWS 各種サービスだけでなく Snowflake など他プラットフォームからのアクセスも容易になります。
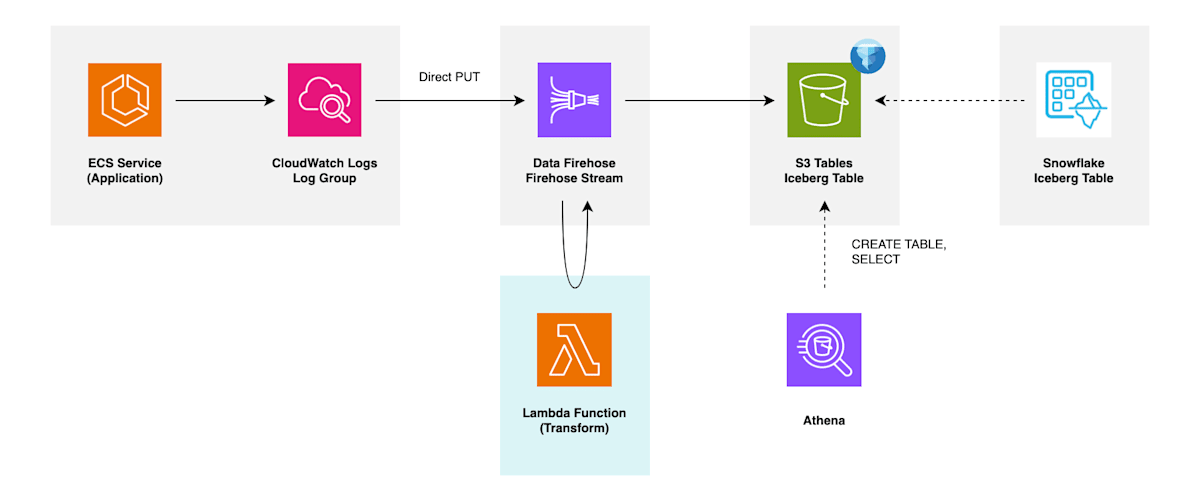
アーキテクチャ
今回構築するアーキテクチャは以下の通りです。(番号は以降で紹介する実装の順序を示します)
アプリケーションが稼働する ECS サービスから CloudWatch ロググループに出力されるログを、Firehose ストリームに送信し、Lambda 関数による簡単なデータ変換を施した後、配信先である Iceberg テーブルに生に近い状態で書き込んでいきます。
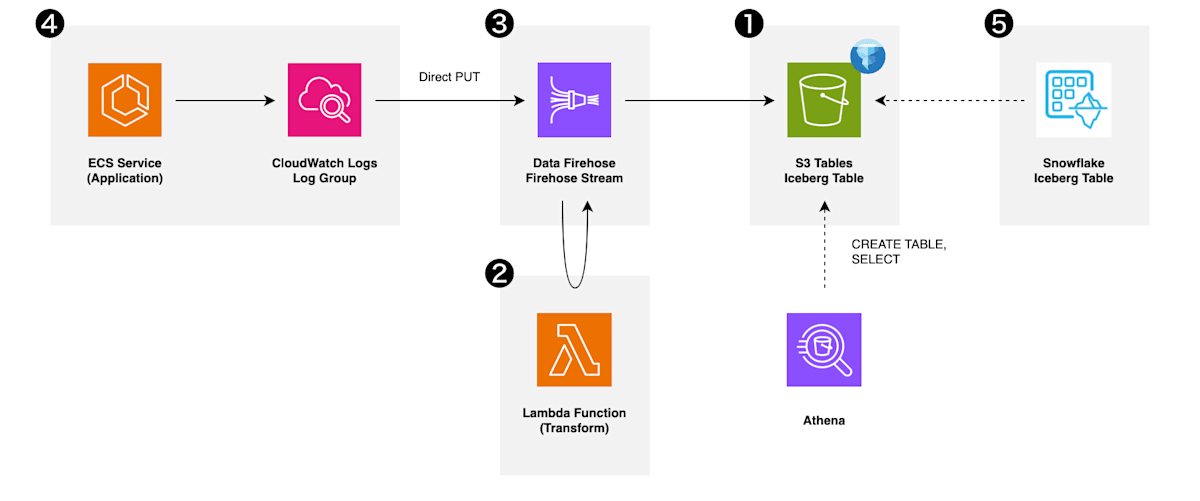
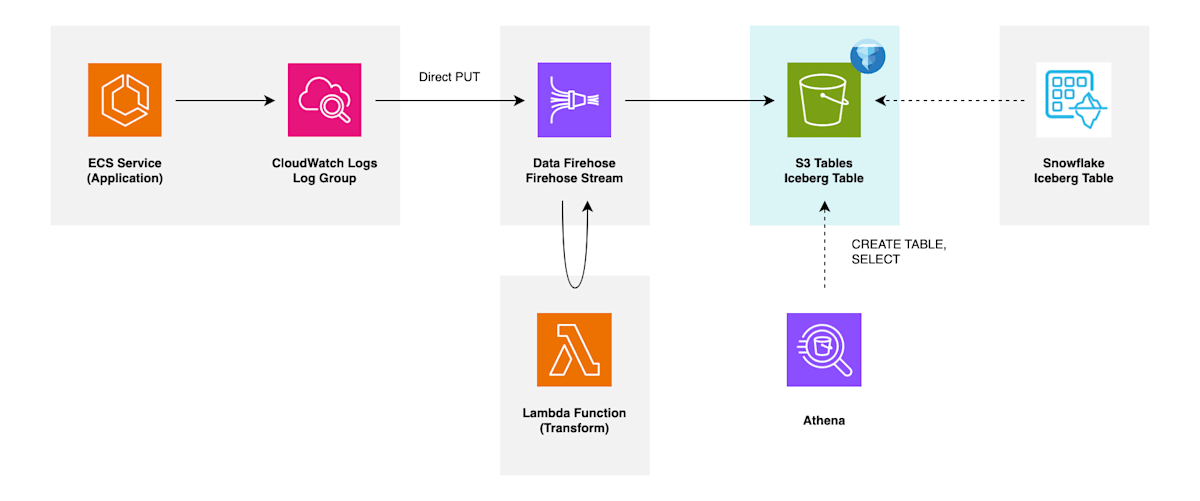
配信先 Iceberg テーブルとして Glue Iceberg, S3 Tables のどちらにも対応しているようですが、本記事では S3 Tables を扱います。また、生に近いログデータを Snowflake 内でデータモデリングしていくことなどを想定して、Snowflake からも参照できるように設定していきます。
ソースとする CloudWatch ロググループは何でも良いですが、筆者環境に こちらの記事 で構築したセルフホスト版 Lightdash のロググループがあるので、今回はこれを使用するものとします。
実装
以降で具体的な実装方法について説明していきます。
各種リソースの実装は基本的に Terraform で示すものとします。
S3 Tables テーブル
配信先となる S3 Tables 関連リソースを作成していきます。
リソースの分け方に対する考え方として、今回は以下のような想定で進めます。
-
テーブルバケット -
my-cwlogs... CloudWatch ログ全般を管理 -
名前空間 -
lightdash... Lightdash 関連の CloudWatch ログ全般を管理 -
テーブル -
all_records... Lightdash の全ログを蓄積するテーブル
テーブルリソースについては、目的ごとに分けるような想定をしています。例えば、特定コンテナのイベントに絞り、かつよりリッチな情報を蓄積するテーブルなどは、別テーブルとして管理できるような分け方にしています。
テーブルバケット・名前空間の作成
Iceberg テーブルが所属するテーブルバケット・名前空間を作成します。
# Table Bucket
resource "aws_s3tables_table_bucket" "cwlogs" {
name = "my-cwlogs"
maintenance_configuration = {
iceberg_unreferenced_file_removal = {
status = "enabled"
settings = { non_current_days = 10, unreferenced_days = 3 }
}
}
}
# Namespace
resource "aws_s3tables_namespace" "lightdash" {
namespace = "lightdash"
table_bucket_arn = aws_s3tables_table_bucket.cwlogs.arn
}
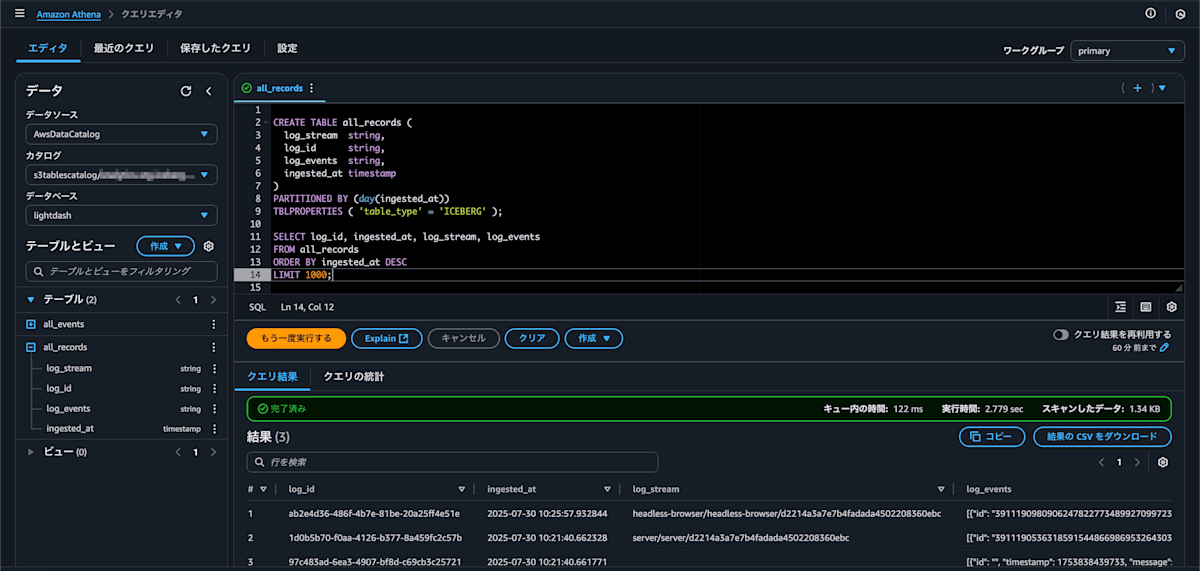
テーブル作成
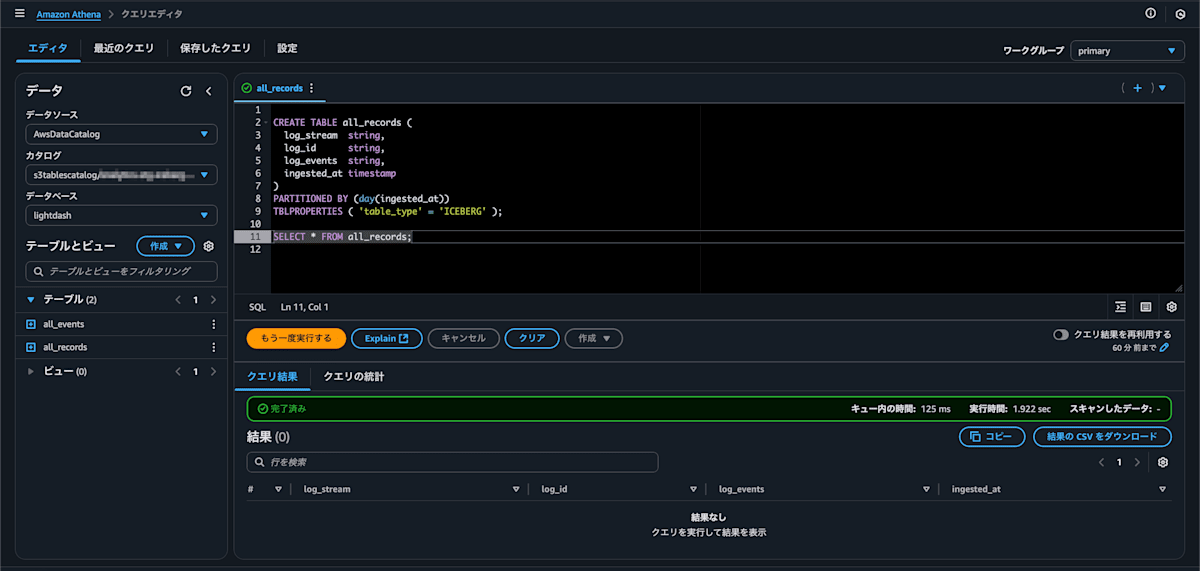
Athena で Iceberg テーブルを作成します。(参考: 公式ドキュメント)
CREATE TABLE all_records (
log_stream string, -- ログストリーム名(コンテナ名などを含む)
log_id string, -- UUID で生成した Iceberg テーブル内の一意キー
log_events string, -- ログ中身
ingested_at timestamp -- データ変換が実行された時刻(配信遅延評価用途)
)
PARTITIONED BY (day(ingested_at))
TBLPROPERTIES ( 'table_type' = 'ICEBERG' );
テーブル作成後、左メニューのテーブル一覧にテーブル情報が表示され、SELECT 文を実行して成功することを確認できます。(レコードはまだ投入していないので結果行はありません)
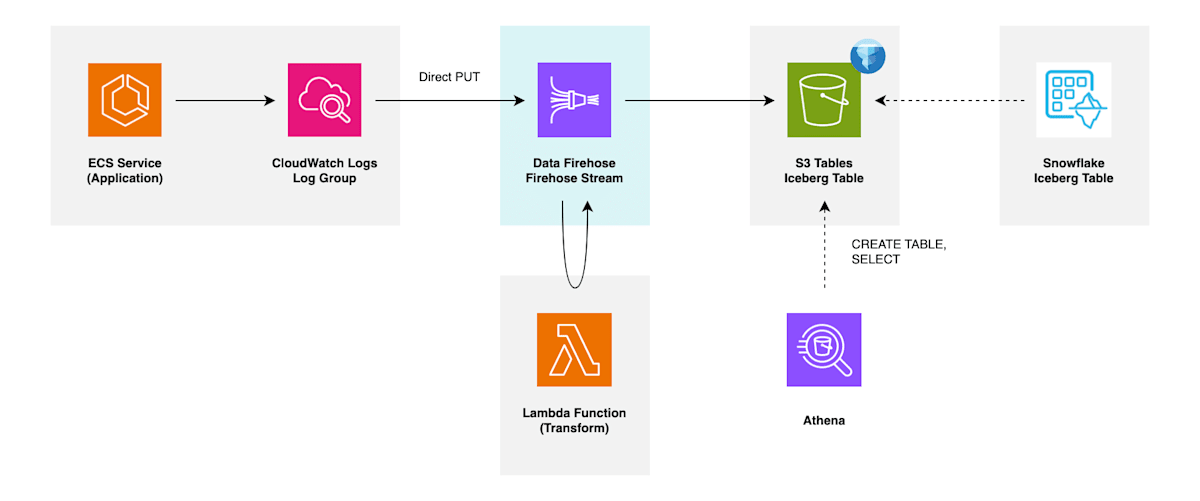
データ変換用 Lambda 関数
Firehose ストリームが受け取ったレコードを、配信先に出力する前にデータ変換するための Lambda 関数を用意していきます。
CloudWatch ロググループからサブスクリプションフィルターを通して流れてくる各レコードの中身は、解凍した状態で以下のような形式になっています。
{
"messageType": "DATA_MESSAGE",
"owner": "000011112222",
"logGroup": "/ecs/lightdash/lightdash",
"logStream": "headless-browser/headless-browser/xxxxxxxx",
"subscriptionFilters": ["filter-to_firehose-cwlogs_lightdash"],
"logEvents": [
{"id": "123...001", "timestamp": 1753499380000, "message": "[INFO] msg1"},
{"id": "123...002", "timestamp": 1753499380000, "message": "[INFO] msg2"}
]
}
これをデータ変換処理によって Iceberg テーブルが想定する以下のような形式に整形し、Firehose ストリームに返す処理を実装します。
{
"log_stream": "headless-browser/headless-browser/xxxxxxxx",
"log_id": "cfcf0e4f-c88d-4bbc-856e-ac815e885980",
"log_events": "[{\"id\": \"123...001\", \"timestamp\": 1753499380000, \"message\": \"[INFO] msg1\"}, {\"id\": \"123...002\", \"timestamp\": 1753499380000, \"message\": \"[INFO] msg2\"}]",
"ingested_at": "2025-07-26T12:15:00.000000+09:00"
}
ハンドラスクリプトの実装例を以下に示します。
ハンドラスクリプト実装例
import base64
import gzip
import json
import uuid
from datetime import datetime
from zoneinfo import ZoneInfo
from aws_lambda_powertools import Logger
logger = Logger()
ZONE_INFO = ZoneInfo('Asia/Tokyo')
@logger.inject_lambda_context(log_event=True)
def handler(event, _):
output_records = []
error_record_count = 0
for record in event['records']:
record_id = record['recordId']
record_data = json.loads(gzip.decompress(base64.b64decode(record['data'])))
log_stream = record_data['logStream']
try:
output_record_data = {
"log_stream": log_stream,
"log_id": str(uuid.uuid4()),
"ingested_at": datetime.now(ZONE_INFO).isoformat(),
"log_events": json.dumps(record_data['logEvents']),
}
logger.info(f"Output record data: {output_record_data}")
payload = base64.b64encode(json.dumps(output_record_data).encode())
output_record = {
"recordId": record_id,
"result": "Ok",
"data": payload.decode(),
}
output_records.append(output_record)
except Exception as e:
logger.error(e)
error_record_count += 1
raw_record = {
"recordId": record_id,
"result": "ProcessingFailed",
"data": record['data'],
}
output_records.append(raw_record)
logger.info(f"Failed to process {error_record_count}/{len(output_records)} records")
return {"records": output_records}
CloudWatch ロググループ (Direct PUT) がソースである場合処理済みの各レコードは、以下のパラメータが必要になります。
| パラメータ | 説明 |
|---|---|
recordId |
Lambda 関数呼び出し時に Data Firehose から渡される値。 Dire Firehose への返却時にも同一の値がセットされている必要がある。 |
result |
各レコードのデータ変換ステータス。 指定可能な値: ( Ok: 正常, Dropped: 意図的な削除, ProcessingFailed: 失敗) |
data |
base64 エンコード後の変換されたデータペイロード |
(参考: Required parameters for data transformation - Amazon Data Firehose Developer Guide)
Firehose ストリーム
Firehose ストリーム、およびそれに付随するリソースを作成していきます。
エラー配信用 S3 バケット
アーキテクチャ図にはありませんが、Firehose ストリームが使用する S3 バケットを作成します。配信先が S3 でない場合でも、配信エラー時のログがここで作成するバケットに書き込まれ、トラブルシューティングに役立てることができます。
Firehose 用ロール
Firehose ストリームが使用する IAM ロールを作成します。
resource "aws_iam_role" "firehose" {
name = "FirehoseRole-${local.stream_name}"
assume_role_policy = data.aws_iam_policy_document.firehose_assume_role.json
}
data "aws_iam_policy_document" "firehose_assume_role" {
statement {
actions = ["sts:AssumeRole"]
effect = "Allow"
principals {
type = "Service"
identifiers = ["firehose.amazonaws.com"]
}
}
}
resource "aws_iam_role_policy" "firehose" {
name = "FirehoseRolePolicy-${local.stream_name}"
role = aws_iam_role.firehose.id
policy = data.aws_iam_policy_document.firehose.json
}
ポリシードキュメントの実装例は長くなるので以下に記載します。詳細は 公式ドキュメント をご確認ください。
ポリシードキュメント実装例
data "aws_iam_policy_document" "firehose" {
statement {
sid = "S3TableAccessViaGlueFederation"
actions = [
"glue:GetTable",
"glue:GetDatabase",
"glue:UpdateTable"
]
resources = [
"arn:aws:glue:${var.region}:${var.account_id}:catalog/s3tablescatalog/*",
"arn:aws:glue:${var.region}:${var.account_id}:catalog/s3tablescatalog",
"arn:aws:glue:${var.region}:${var.account_id}:catalog",
"arn:aws:glue:${var.region}:${var.account_id}:database/*",
"arn:aws:glue:${var.region}:${var.account_id}:table/*/*",
]
}
statement {
sid = "S3DeliveryErrorBucketPermission"
actions = [
"s3:AbortMultipartUpload",
"s3:GetBucketLocation",
"s3:GetObject",
"s3:ListBucket",
"s3:ListBucketMultipartUploads",
"s3:PutObject",
]
resources = [
"arn:aws:s3:::${data.aws_s3_bucket.firehose.id}",
"arn:aws:s3:::${data.aws_s3_bucket.firehose.id}/*"
]
}
statement {
sid = "RequiredWhenUsingKinesisDataStreamsAsSource"
actions = [
"kinesis:DescribeStream",
"kinesis:GetShardIterator",
"kinesis:GetRecords",
"kinesis:ListShards",
]
resources = [
"arn:aws:kinesis:${var.region}:${var.account_id}:stream/${local.stream_name}"
]
}
statement {
sid = "RequiredWhenDoingMetadataReadsANDDataAndMetadataWriteViaLakeformation"
actions = [
"lakeformation:GetDataAccess",
]
resources = ["*"]
}
statement {
sid = "RequiredWhenUsingKMSEncryptionForS3ErrorBucketDelivery"
actions = [
"kms:Decrypt",
"kms:GenerateDataKey"
]
resources = [
"arn:aws:kms:${var.region}:${var.account_id}:key/*"
]
condition {
test = "StringEquals"
variable = "kms:ViaService"
values = ["s3.${var.region}.amazonaws.com"]
}
condition {
test = "StringLike"
variable = "kms:EncryptionContext:aws:s3:arn"
values = ["arn:aws:s3:::${data.aws_s3_bucket.firehose.id}"]
}
}
statement {
sid = "LoggingInCloudWatch"
actions = [
"logs:PutLogEvents",
]
resources = [
"arn:aws:logs:${var.region}:${var.account_id}:log-group:/aws/kinesisfirehose/${local.stream_name}:*",
"arn:aws:logs:${var.region}:${var.account_id}:log-group:/aws/kinesisfirehose/${local.stream_name}:log-stream:*",
]
}
statement {
sid = "RequiredWhenAttachingLambdaToFirehose"
actions = [
"lambda:InvokeFunction",
"lambda:GetFunctionConfiguration",
]
resources = [
data.aws_lambda_function.processor.arn,
"${data.aws_lambda_function.processor.arn}:*",
]
}
}
Sid RequiredWhenAttachingLambdaToFirehose の Lambda 関数呼び出しのポリシーについて、関数名だけでなく関数バージョンも含む形式でないと呼び出しに失敗します。
Firehose ストリーム
Iceberg テーブルを配信先とする Firehose ストリームを作成します。
resource "aws_kinesis_firehose_delivery_stream" "default" {
name = local.stream_name
destination = "iceberg"
iceberg_configuration {
role_arn = aws_iam_role.firehose.arn
catalog_arn = join("/", [
"arn:aws:glue:${var.region}:${var.account_id}:catalog",
"s3tablescatalog",
var.destination_configuration.catalog_name
])
buffering_size = 5
buffering_interval = 300
s3_configuration {
role_arn = aws_iam_role.firehose.arn
bucket_arn = data.aws_s3_bucket.firehose.arn
error_output_prefix = join("/", [
"streams",
local.stream_name,
"error",
"created_date=!{timestamp:yyyy}-!{timestamp:MM}-!{timestamp:dd}",
"!{firehose:error-output-type}",
""
])
}
destination_table_configuration {
database_name = "lightdash"
table_name = "all_records"
unique_keys = ["log_id"]
}
processing_configuration {
enabled = "true"
processors {
type = "Lambda"
parameters {
parameter_name = "LambdaArn"
parameter_value = "${data.aws_lambda_function.processor.arn}:$LATEST"
}
}
}
}
server_side_encryption { enabled = true }
}
iceberg_configuration ブロック内の属性について、いくつか言及しておきます。詳細は 公式ドキュメント をご確認ください。
-
catalog_arn... 配信先 Iceberg テーブルが存在する S3 Tables テーブルバケットに該当するカタログ ARN を指定します。(テーブルバケット ARN ではありません) -
s3_configuration... エラー配信先の S3 プレフィックスなどの設定を行います。 -
destination_table_configuration... 配信先 Iceberg テーブルに書き込むためのルーティング情報(データベース名・テーブル名)、主キーを構成するカラムなどを指定します。 -
processing_configuration... データ変換用 Lambda 関数に関する設定を行います。
取り込みソース
Firehose ストリームに送信する準備が整ったので、データ生成元の設定をしていきます。

今回は CloudWatch ロググループが取り込みソースになるので、該当のロググループにサブスクリプションフィルターを設定して送信を開始します。
data "aws_cloudwatch_log_group" "default" {
name = "/ecs/lightdash/lightdash"
}
data "aws_iam_role" "cwlogs_to_firehose" {
name = "CloudWatchLogsToFirehoseRole"
}
resource "aws_cloudwatch_log_subscription_filter" "default" {
name = "filter-to_firehose-cwlogs_lightdash"
role_arn = data.aws_iam_role.cwlogs_to_firehose.arn
log_group_name = data.aws_cloudwatch_log_group.default.name
filter_pattern = ""
destination_arn = aws_kinesis_firehose_delivery_stream.default.arn
}
しばらく経過した後、配信先 Iceberg テーブルに対する SELECT 文を発行してみると、データが正常に配信されていることを確認できます。
SELECT log_id, ingested_at, log_stream, log_events
FROM records
ORDER BY ingested_at DESC
LIMIT 1000;
Snowflake カタログ統合
Iceberg REST カタログ統合 を構成し、Snowflake の Iceberg テーブルを作成していきます。
カタログ統合の構成方法については以下の記事にて解説しています。
こちらの手順に沿って構成したカタログ統合 CATALOG_INT_REST__ICEBERG_CWLOGS を用いて、Snowflake 上で Iceberg テーブルを作成します。
CREATE OR REPLACE ICEBERG TABLE mydb.cwlogs.lightdash__all_records
CATALOG = 'CATALOG_INT_REST__ICEBERG_CWLOGS'
CATALOG_NAMESPACE = 'lightdash'
CATALOG_TABLE_NAME = 'all_records'
AUTO_REFRESH = TRUE
;
Iceberg テーブルの作成が完了すると、Snowsight 上で SELECT 文を発行してデータを参照できるようになっていることを確認できます。また、AUTO_REFRESH = TRUE [2] によってメタデータ更新を自動的にポーリングするように設定しているため、S3 Tables テーブルに新規レコードが追加されると Snowflake 側にも反映されることを確認できます。
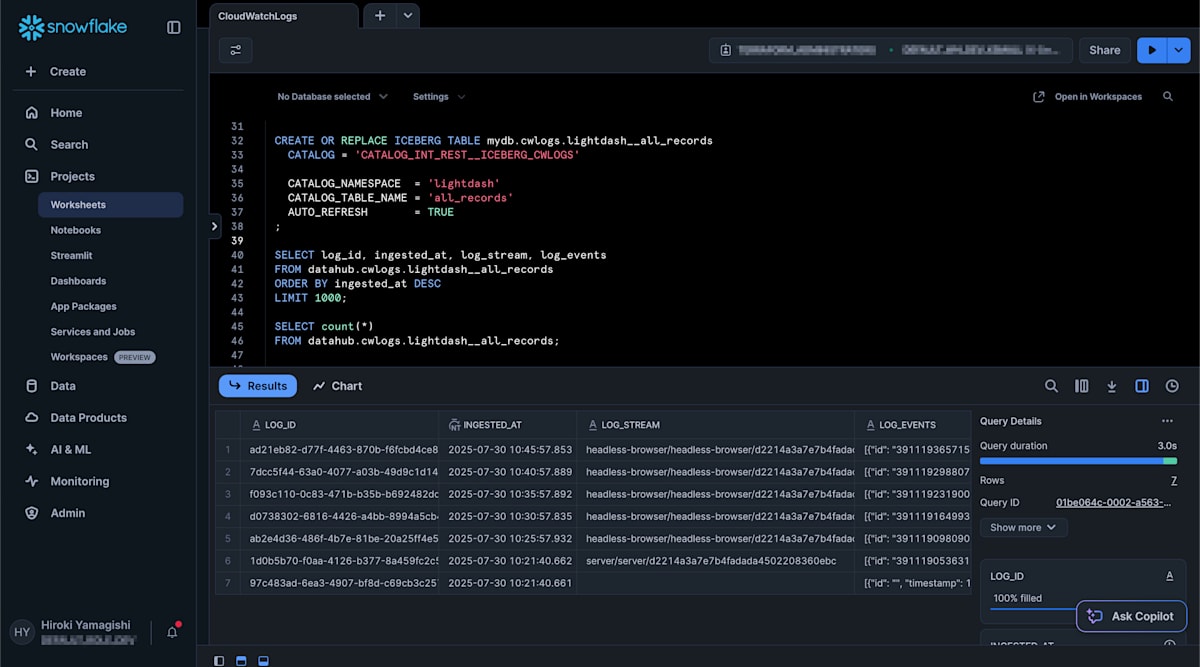
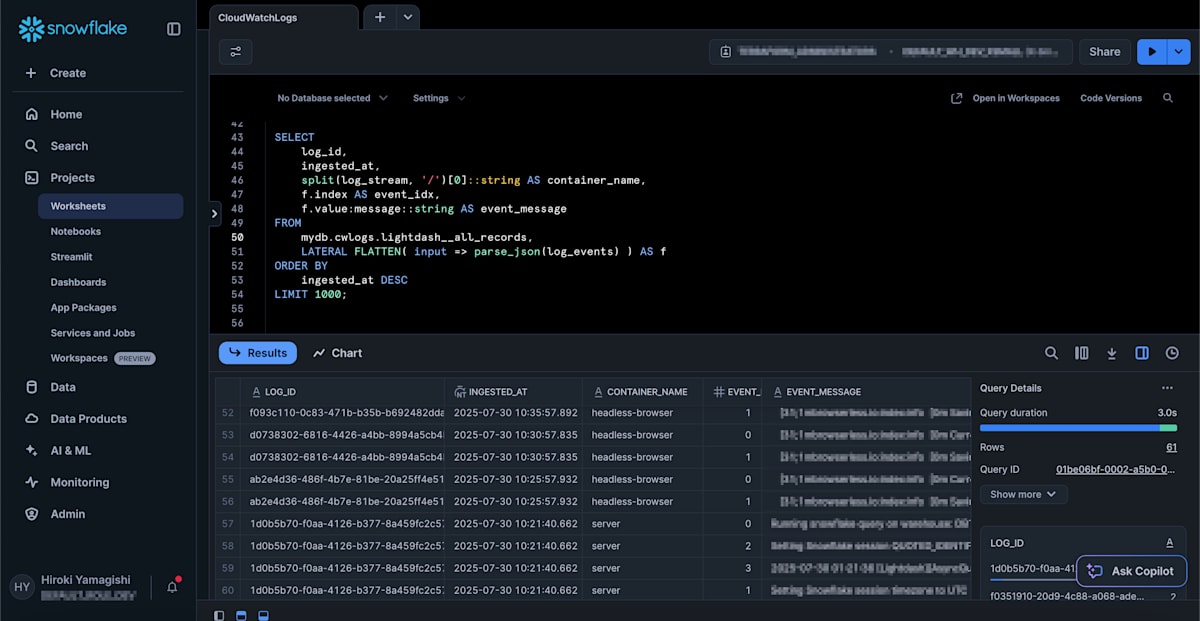
log_events カラムには複数のログイベント情報が格納されていますが、以下のように FLATTEN を使用することでイベント毎に 1 レコードとして出力することも可能です。
SELECT
log_id,
ingested_at,
split(log_stream, '/')[0]::string AS container_name,
f.index AS event_idx,
f.value:message::string AS event_message
FROM
datahub.cwlogs.lightdash__all_records,
LATERAL FLATTEN( input => parse_json(log_events) ) AS f
ORDER BY
ingested_at DESC
LIMIT 1000;
実装に関する説明は以上です。
さいごに
CloudWatch ログを Data Firehose 経由で S3 Tables の Iceberg テーブルに配信し、Snowflake から参照する方法について書いてみました。
昨年 Data Firehose の Iceberg サポートのリリースを読んだ時にも思いましたが、ETL 構築なく Snowflake へのニアリアルタイムなデータ取り込みを実現できるインパクトは大きいなと、今回実際にやってみて改めて感じました。今回は CloudWatch ログを取り上げましたが、Direct PUT API を用いて Lambda 関数などからも送信できて柔軟性が高いので、今後より活用の幅を広げていきたいと考えています。
最後まで読んでいただき、ありがとうございました。
参考
- Amazon Data Firehose データストリームを Apache Iceberg 形式のテーブル配信機能を試す! - DevelopersIO
- リソースリンクなしでAmazon Data FirehoseからAmazon S3 Tablesへのデータ配信を試してみた - DevelopersIO
- Kinesis Data Firehose で「Lambda.InvokeAccessDenied」が発生するときの対処方法 - DevelopersIO
-
Amazon Data Firehose (旧 Amazon Kinesis Data Firehose) のご紹介 ↩︎
-
Apache Iceberg™ テーブルの自動リフレッシュ - Snowflake Documentation ↩︎

Snowflake データクラウドのユーザ会 SnowVillage のメンバーで運営しています。 Publication参加方法はこちらをご参照ください。 zenn.dev/dataheroes/articles/db5da0959b4bdd
Discussion