本記事は Snowflake Advent Calendar 2023 Series 1 の 2 日目の記事です。
記事の背景
筆者の所属では、数年前に ELT サービスの Fivetran が導入され、本番環境ですでに長期間にわたってデータソースからデータウェアハウスにデータを投入するパイプラインが稼働しています。
Fivetran は数百ものデータソースや転送先に対応しており、即座に ELT パイプラインがノーコードで作成できるため、 OSS でいえば Airflow 、 クラウドサービスでああれば、 AWS Step Function 、Google Workflow などのワークフローツール・サービスで ELT パイプラインを全て自前で実装するのに比べると、大幅に開発コストを削減できます。
さらに Fivetran は dbt に対応しているため、 Fivetran でデータウェアハウスに取り込んだ生データに対して、 dbt によるデータ変換まで一気通貫で行う ELT パイプラインを簡単に実現できます。
データ活用部署から見れば、データソースからデータウェアハウスまでデータを投入する箇所のビジネス価値はあまり大きくない(あるいは限りなくゼロに近い)と言えるでしょう。なるべく ELT パイプラインの開発・運用コストを低減し、本番環境へのデータ投入をより短時間に行い、よりビジネスに近いモデリングやデータ活用に時間を使えることは、データエンジニアリングチームにとって大きなメリットがあります。
ここまで Fivetran の活用が進んだ筆者のチームですが、 Fivetran がサポートしていないデータソースについては、 Fivetran 導入以前から開発・保守されていた独自の ELT フレームワーク( Apache Beam のジョブを Airflow から起動し、データ取得・変換・投入などを行う)が継続して使われていました。この独自フレームワークを使った開発は Fivetran を導入したパイプラインに比べて、学習コストが高く、新規パイプラインの開発工数が多いため、 Fivetran 未サポートのデータソースにも Fivetran を使えないかとチームで議論し、タイトルにあるカスタムコネクタについて調査が始まりました。
カスタムコネクタ(Fivetran Functions)について
Fivetran のカスタムコネクタは、正式名称は Functions と呼ばれており、その名の通り、 AWS Lambda/Azure Functions/Google Cloud Functions といった各クラウドプロバイダーの Function as a Service を使って未対応のデータソースに接続できます。
アーキテクチャは以下の通りで、 Fivetran が HTTPS リクエストで Function を起動し、 Function はデータソースに接続し、データを取得した後、 HTTPS レスポンスを Fivetran に返答します。 Fivetran は受け取ったデータを転送先に同期します。
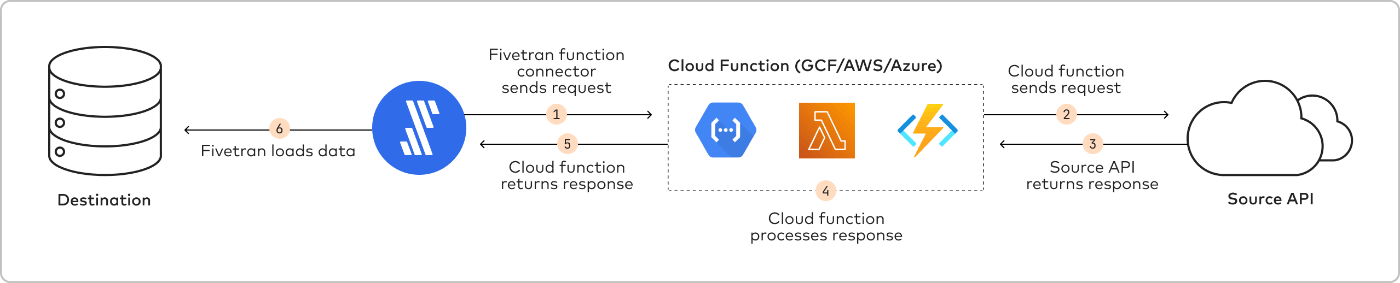
データ同期の流れ
Function を使ったデータ同期の流れは以下の通りです。
- 認可: クラウドサービスの IAM ロールを使って、Fivetran によるクラウドサービスへのアクセスを認可する。
- 初期同期: Fivetran は空の状態を提供することで、初期データ同期を開始する。 Function で初期セットのデータと現在の同期状態 (cursor) のセットを返答する。
- 解析: Fivetran は Function が返したデータを解析する。データは標準フォーマットに従っている必要がある。
- 処理: Fivetran は各エンティティに対してテーブルを作成する。 Fivetran はエンティティの各要素について型キャストとテーブルのカラムに対するマッピングを行う。転送先のデータ型で対応していないデータを変換する。
- ロード: Fivetran は、自動的にコネクタごとにスキーマを 1 つ作成する。マッピングされたソースオブジェクトは1つ以上の正規化済みテーブルに対応付けできる。 Fivetran は、 Function の応答で指定した内容に基づいてテーブルを作成する。 Fivetran は、データの初期ダンプに基づいてテーブルを作成する。
- 更新: Fivetran は定期的に Function をコールし、データの次のセットを取得する。 Function の応答に新しいテーブルが追加された場合は、 Fivetran は新しいテーブルを作成する。
- 論理削除(Soft delete): Fivetran は、データソースでレコード削除が検出された場合、_fivetran_deleted カラムを true にすることで、転送先テーブルのレコードを物理削除せず、論理削除したとマーキングする。フル再同期の際にのみ、このオプションを使い、差分同期の際には使わないことが推奨されている。
Function の HTTP リクエスト・レスポンス応答について
FaaS を使った Function は決められた HTTPS リクエスト・レスポンスのフォーマットを満たす必要があります。フォーマットの詳細は以下を参照ください。
リクエスト例
{
"agent" : "<function_connector_name>/<external_id>/<schema>",
"state": {
"cursor": "2018-01-01T00:00:00Z"
},
"secrets": {
"apiToken": "abcdefghijklmnopqrstuvwxyz_0123456789"
},
"sync_id": "468b681-c376-4117-bbc0-25d8ae02ace1"
}
レスポンス例
{
"state": {
"transaction": "2018-01-02T00:00:00Z",
"campaign": "2018-01-02T00:00:01Z"
},
"insert": {
"transaction": [
{"id":1, "amount": 100},
{"id":2, "amount": 50}
],
"campaign": [
{"id":101, "name": "Christmas"},
{"id":102, "name": "New Year"}
]
},
"delete": {
"transaction": [
{"id":3},
{"id":4}
],
"campaign": [
{"id":103},
{"id":104}
]
},
"schema" : {
"transaction": {
"primary_key": ["id"]
},
"campaign": {
"primary_key": ["id"]
}
},
"hasMore" : true,
"softDelete":["transaction"]
}
スキーマ定義などそのほか、Function が実装すべき要件がありますので、詳しくはドキュメントを参照ください。
各クラウドサービスプロバイダごとのセットアップガイド
各クラウドプロバイダごとに Functions のセットアップ方法が異なります。以下を参照ください。
- AWS Lambda https://fivetran.com/docs/functions/aws-lambda
- Azure Functions https://fivetran.com/docs/functions/azure-functions
- Google Cloud Functions https://fivetran.com/docs/functions/google-cloud-functions
本番環境で Function を利用する際のアクセス制限
デフォルトだと FaaS の HTTPS のエンドポイントはインターネットに公開されてしまい、 IAM のクレデンシャルで認証はするものの、誰でもアクセスできてしまい、サイバー攻撃を受けるリスクが高まります。少なくとも Fivetran のグローバル IP アドレスからのみアクセスできるようにするなど、一定のアクセス制限を設定することが望ましいでしょう。各サービス FaaS のエンドポイントにネットワークレベルでアクセス制限を設ける方法は提供されています。
おわりに
本記事では、 ELT サービスの Fivetran について、 Functions という機能を使い、各クラウドプロバイダが提供する FaaS と接続することで、 Fivetran 未対応なデータソースに対しても ELT パイプラインが作成できることを紹介しました。
本記事を執筆段階では、 PoC 段階のため、詳細は記載できませんでした。 PoC が完了し、本番へ投入できた暁にはぜひ本番で利用した上での知見を紹介したいと思います。

Snowflake データクラウドのユーザ会 SnowVillage のメンバーで運営しています。 Publication参加方法はこちらをご参照ください。 zenn.dev/dataheroes/articles/db5da0959b4bdd
Discussion