本記事の背景
本記事は、某所で密かに行われていた Snowflake DevOps 情報交換会 Season 1 最終回の議論用に共有した内容です。
本会は、 DevOps を中心に、また DevOps とは直接は関係ないテーマも含め、その時々において関心のあるテーマを取り扱っていましたが、今回は最終会ということで、本来のテーマである DevOps において、私個人が中心的テーマであると考える構成管理やデプロイの自動化について議論したいと思い、整理しました。
中心的テーマを再び取り上げようと考えたきっかけの 1 つが Snowflake Data Superhero の Tomas が LinkedIn で EXECUTE IMMEDIATE FROM という新しい構文について紹介しているのを発見したことです。これはステージ上の SQL ファイルを直接実行できるという機能です。
Tomas は本機能を Snowflake でのインフラ構成管理に使えると指摘しています。この機能がどのようにインフラ構成管理に貢献するかは検証が必要ですが、 Snowflake は最近、 Git 連携、コンテナサービスなど DevOps に関連しそうな機能を次々と発表しており、今後、 DevOps 向け機能の発展が期待できる状況になっています。
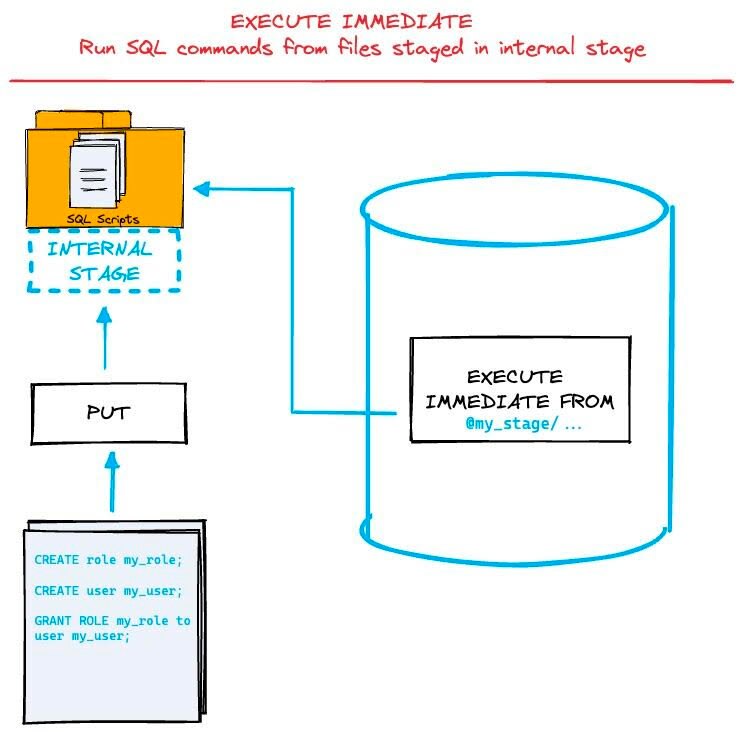
例えば、 Git リポジトリと Streamlit やワークシートを連携させ、 Snowflake 上のエディタでコードを編集し、完了したらリポジトリに push し、 CICD パイプラインが回って、コンテナサービスにアプリケーションがデプロイされたり、何らかの Snowflake リソース変更が行われることが、よりシームレスになり、開発と運用の一体化がより簡単になると予想しています。
このように将来の発展が期待できる Snowflake の DevOps 分野について、著者のこれまの取り組みと現状の課題を整理したいと思います。
用語の定義
DevOps 界隈に詳しくない方のために、著者の考える DevOps における中心的テーマの構成管理とデプロイ自動化について用語の定義について説明します。
(1) 構成管理
本番システムを構成するのに必要なアプリケーションコードや設定ファイルをテキストとして Git などバージョン管理システムに登録しておき、変更履歴管理を行うこと。
(2) デプロイの自動化
以下のような作業を Github Actions や Gitlab CICD などで自動的に行うこと。
- バージョン管理システム上に登録したアプリケーションコードや設定ファイルを自動的にビルドする。
- アプリケーション実行環境を構築する。
- 実行可能なアプリケーションを実行環境に配備する。
構成管理やデプロイの自動化に取り組む背景
現代のソフトウェア開発において、多くの場合、複数のプロジェクトが並行した状態で進みます。これらを混乱なく、調和させた状態で開発を進め、各種テスト・成果物レビューなどを通じ、品質が担保された変更だけを本番システムに組み込んでデプロイすることで、品質を安定させ、プロジェクトを安定的に進めたいというのが構成管理を導入する大きな動機です。
また、ソフトウェアのビルドやデプロイ、 DB 構成の変更はリリースのたびに繰り返すため、これを手動で行うと人為的なミスによるシステムの不具合が発生する可能性があります。また、筆者のチームには、オフショアの人、スキルレベルが様々な人が参加するため、成果物の作り方、デプロイの仕方をある程度矯正し、自由度を減らすことで、開発者のスキルによらず、誰がやっても安定的に問題なくデプロイできるようになります。
現在の Snowflake の構成管理
筆者のチームの構成管理のアプローチを決める際に大きく参考にしたのは、以下の記事です。
本記事のアプローチは以下の通りです。著者は、リソースの種類によって適切なツールが異なるため、対象によって異なるツールを選定しています。
- User / Role は SCIM を利用し、自社の IdP でアクセス権限を一元管理する。これによりユーザの二重管理を防ぐ。
- Dataset Objects (テーブルやビューなど)は、データ変換ツールとして人気のある dbt で管理する。
- その他の Database Objects は、 Schemachange (記事が執筆された当時の名前は snowchange )で管理する。
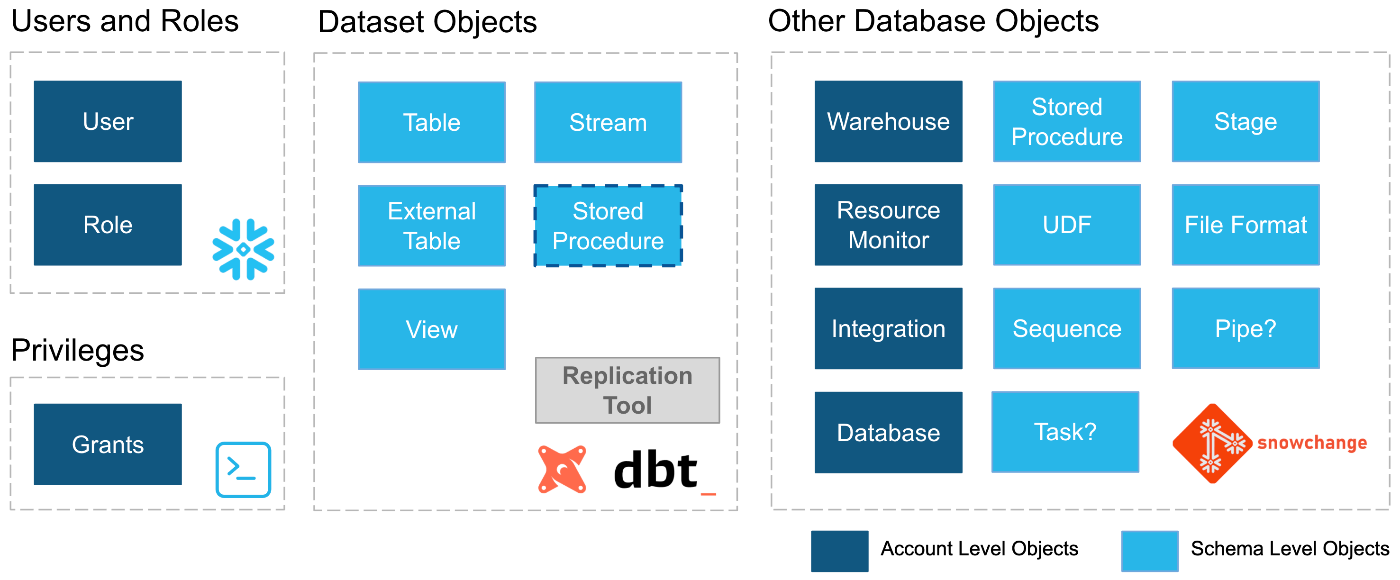
著者のチームでのアプローチ配下の通りです。ツール選定の理由は後述します。
- 以下のオブジェクト階層において、アカウントレベル、データベースレベルのオブジェクト、スキーマそのものは Terraform で管理する。
- スキーマ内のリソースは schemachange で管理する。 schemachange は flyway の DB 構成管理手法を踏襲し、Python の jinja テンプレートベースで実装された、SQL ベースの軽量 DB 変更管理ツール。
- SQLによるデータ処理のロジック(ビュー、incremental model 含む)は dbt を利用する。
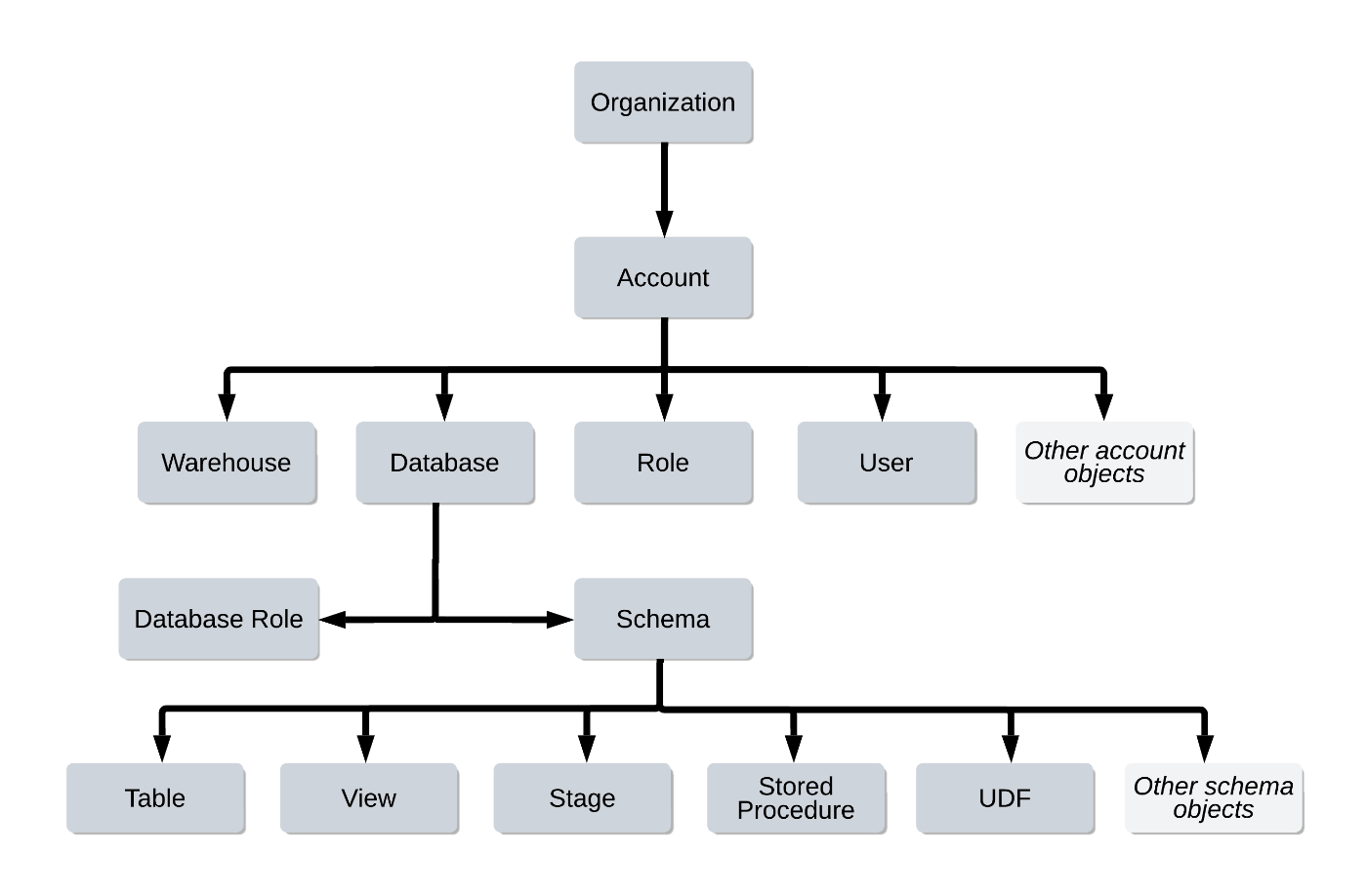
各構成管理ツールを選定した理由
当初は、前職以前で慣れていた Terraform で全ての構成管理を行うことを目指していました。筆者が考える Terraform のメリットは以下の通りです。
- 宣言 (declarative) 型の構成管理ツールであり、コードで目的の状態を記述するため、管理対象リソースの現在の状態を把握しやすい。
- ツールが実際のリソースとの変更差分を検出し、変更を適用前に影響範囲を把握できるため、変更内容をレビューしやすい。
Terraform には、このようなメリットが存在し、構成管理には適した特性のツールですが、データエンジニアリングチームにおいてデータエンジニアとして雇用されている人のスキルセットが主に SQL と Python による ETL 部分であり、 Terraform を経験している・理解している人がいないため、特にプロジェクトチームが頻繁に変更を入れる部分において Terraform を主な構成管理ツールとして推していくのは困難だと考えました。
また、ツールは宣言的でありながら、その裏側では SQL によるコマンドを生成・実行しており、内部的には命令型であるのが実態です。これにより、生成される SQL 文が期待と異なる不具合が生まれる温床になっています。この点で Terraform の動作を常に信頼できる訳ではない理由になっています。詳しい事情については Github のディスカッションを参照ください。
ここで、特にプロジェクトで頻繁に変更を入れることが多い、スキーマ内のリソースについては、 Snowflake の第一言語である SQL ベースの構成管理ツール schemachange への移行を検討しました。 schemachange のメリットは、
- SQL は Snowflake の第一言語であり、 Snowflake の機能を直接使える。
- 古典的な DB 構成管理ツールのやり方を踏襲した軽量なアプローチを利用でき、導入しやすい。
- Python の jinja テンプレートにも対応し、コード再利用が楽。
ただし、 schemachange は命令 (imperative)型であり、 DB への新規変更を新バージョンとして SQL スクリプトとして追記していく方式です。バージョン管理システムには変更差分だけが積み上がっていくことになり、リポジトリを見ても最新の状態が不明という難しさがあります。
そこで、SQL ベースのスキーマ内の構成管理、特にテーブルやビューの単発デプロイ、または incremental model を用いたデータ変換の部分については、より宣言的であり見通しも良く、業界ではデファクトになりつつある dbt を導入しました。データ変換部分の SQL による実装手段として dbt が人気が出てきたことで、ネット上に情報が豊富にあり、またデータに対するテストツールとしても使える点、パッケージやマクロで拡張が可能な点が非常に強力です。
ワークフロー
特にデータ変換ロジックをスケジュール実行する場合のワークフローについては以下の通りです。
- スキーマ内のリソースを dbt と schemachange で管理するリポジトリとそれ以外を Terraform で管理するリポジトリは分離させています。これは両領域を扱う人が全く別な上、同時に扱う必要がないためです。
- dbt と schemachange で管理するリポジトリは、 merge request をブランチにマージすると、 Gitlab CICD パイプラインが実行され、 dbt や schemachange による単発のデプロイが行われます。また、dbt のソースコード部分はコンテナイメージにビルドし、ECR に push します。
- dbt による table replace もしくは incremental update する場合のジョブは ECS タスク内で実行しており、スケジューリングはAWS MWAA の Airflowで行っています。
なお、 dbt のコマンド実行を ECS 上で行ったのは、 Airflow のバージョンが古いためです。特定の古い Airflow バージョンに依存して自由に dbt パッケージが使えなくなることを防ぐため、両者を分離させています。
詳細は以下の記事を参照ください。
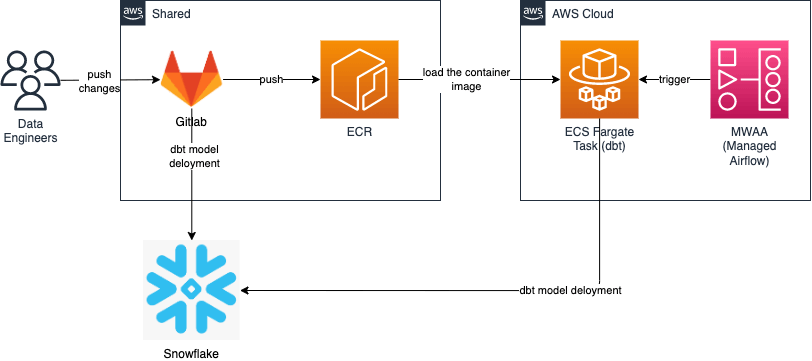
ただし、現在は Astoronomer が dbt モデルを Airflow DAG 上で実行させつつ、 dbt モデルのリネージを Airflow DAG リネージ上に表示する Python パッケージを公開しています。 dbt モデルの実行状況の把握に良いため、このパッケージを使う場合は、Airfow DAG から直接 dbt モデルを参照・実行する必要があります。
組織上の課題 - データアナリストとデータサイエンティストが DevOps のプラクティスに適応するのが困難
現在の構成になって 1 年以上運用しているため、データエンジニアリングチーム内では大きな問題点はありません。
一方で、データエンジニアリングチームと、データアナリストやデータサイエンティストが在籍するアナリティクスチームは組織が分かれており、アナリティクスチーム側でエンジニアリングスキルが不足しているため、データエンジニアリングチームが用意した一連の仕組みがうまく機能しないことが問題になっています。
データアナリストやデータサイエンティストは、ビジネスドメインの知識が豊富であり、本業のデータ分析や数学的手法に長けた人は多い一方で、 Git やスクリプトによる自動化といったエンジニアリングのプラクティスの訓練を受けている人がおらず、データエンジニアリングチームが用意した Git を使ってデプロイを自動化するやり方に抵抗感を感じる人が多くいます。
そこでデータアナリストが Notebook 上で検証したスクリプトを提供し、データエンジニアがデプロイ可能に実装し直してデプロイするというフローを取るケースもありますが、エンジニア側にタスクが溜まり、要望から応答まで時間が長くなる弊害もあります。
また、特にデータマート部分などデータアナリストやデータサイエンティストが直接管理し、柔軟に対応したい部分は、スキーマを別に切り出し、彼らが Snowflake の UI 上で、直接変更できるようにする緩和措置も行っています。手動で管理する部分と自動化パイプラインが混在すると、人為的なミスによる事故が起きる可能性が高いため、彼らが直接管理するスキーマには、データエンジニアリングチームが基本的に介在しない対応をとっています。
ただし、これを広げていくと、特にデータマート部分の大半はエンジニアリング・変更管理スキルのない人が自由に変更を加える状態になってしまい、一定のガバナンスプロセス(レビュー、承認フロー)を導入するのが無理になります。これはプロセスに実際に従うかどうかは本人の判断になり、正規プロセスをスキップしても止める手段がありません。
そこで、1年ほど前にアナリティクスチームに加入した ML エンジニアに対し、データエンジニアリングチームの取り組みを紹介し、 KT セッションを継続的に行うことで、彼を中心にして、アナリティクスチームがより Git や DevOps のプラクティスに適用できるようにスキル習得を行なっています。
おわりに
本記事では、筆者が過去 3 年半の間に確立してきた Snowflake 向けの DevOps 、特に構成管理とデプロイ自動化について紹介してきました。
エンジニアリングのバックグラウンドがある方は、本記事で紹介したアプローチを採用することで、チームとして安定的に開発やデプロイを進めることができます。
一方で、エンジニアリングの経験が乏しいデータアナリストやデータサイエンティストを本アプローチにどう適用してもらうかにも課題があります。筆者のおすすめとしては以下の通りです。
- エンジニアリングとアナリティクスを別のチームに分離せずに、一体のフルスタックデータチームとして構成すること。
- エンジニアリングのバックグラウンドがある人にデータアナリストやデータサイエンティストと共同作業してもらい、 DevOps プラクティスへの適応を段階的に行う。
このような対応を取ることで、チームとしてスキルのボトルネックを解消し、エンジニアリングスキルの低い人をスキル底上げを図ることができると考えます(実際には未検証ですが!)。もし、このような取り組みをされているチームの方は、ぜひ筆者に状況を教えてください!
以上、3年半のまとめでした。ご愛読ありがとうございました。本記事が読者の参考になれば幸いです。

Snowflake データクラウドのユーザ会 SnowVillage のメンバーで運営しています。 Publication参加方法はこちらをご参照ください。 zenn.dev/dataheroes/articles/db5da0959b4bdd
Discussion