Background
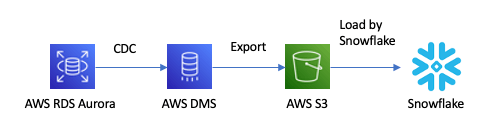
AWS DMS and Snowpipe would be one of the most popular tools when you replicate data from on-premise database or AWS RDS database to Snowflake table in near real time because of the following reasons.
- AWS DMS (Data Migration Service) is AWS's official database migration service.
- AWS DMS does not support Snowflake but can export data to S3 bucket.
- Once new file is upload in S3 bucket, Snowpipe can load the file to target Snowflake table immediately.
If you choose this approach, you will load entire transaction history of the source table to target table. If you want to know the latest records for each primary key or unique key instead of entire history, you also need to maintain the latest records in another table using Stream and Task just like the upper pipeline in the following diagram.
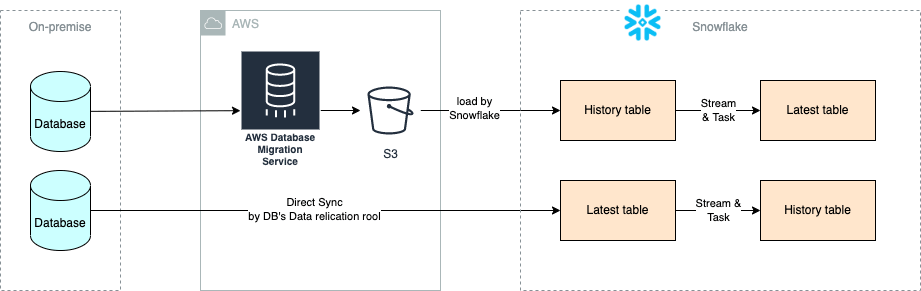
This is cost-efficient approach as compute cost for Snowpipe is quite cheap, but you might feel you do not want to implement Stream and Task just to replicate data.
Some RDBMS also provides database migration tool that can directly sync source table to target table in Snowflake just like the lower pipeline in the above diagram. This can reduce development cost compared with DMS and Snowpipe approach, so I tried this in my project, but it turns out that warehouse cost for this type of high frequent data loading is quite expensive.
This issue would also happen when you use ETL service like Fivetran. It is not an issue on specific tool. I will explain why high frequent data loading is expensive in this article.
Why warehouse cost for high frequent data loading is expensive?
- (1) DMS and Snowpipe
- (2) Direct table sync by DB migration tool
If you compare how warehouse is used in these 2 approaches, you would notice that (1) Snowpipe approach uses Snowflake managed warehouse, which automatically optimize computing resources used in your workload and warehouse cost. This can reduce warehouse cost. See below URL for more about Snowpipe cost.
On the other hand, (2) direct table sync by DB migration tool uses a user managed warehouse. In our project, default configurations for the warehouse was like follows. If the tool loads data frequently such as every minute, it would keep the warehouse running. Snowflake also start new warehouse when new data comes in before the auto suspend time has passed.
- Multi cluster warehouse
- Default scaling policy: Snowflake tries to keep latency minimum by starting a new warehouse
- Default auto suspend time: 10 minutes
Snowflake warehouse cost is calculated based on warehouse size * a number of warehouses * duration of warehouse running instead of data volume. Even if data volume is small, warehouse cost would increase if more warehouses runs in longer time. See the below URLs for more about warehouse cost.
What can we do to reduce warehouse cost?
As already explained, Snowflake warehouse cost is calculated based on warehouse size * a number of warehouses * duration of warehouse running.
In this pricing model, high frequent small data loading is not cost-efficient. So it would be better to think if you really need it and the cost is acceptable. If not, you should decrease frequency of data loading such as hourly, daily, etc. and load larger amount of data at a time and stop the warehouse.
In that case, you can change the following configurations if you prefer minimum cost approach. Note that warehouse cache is cleared once when a warehouse is restarted. There is some latency to restart a warehouse, so there are some risk that latency of your queries would increase.
- Set economy to scaling policy: Snowflake will try not to start new warehouse
- Make auto suspend time shorter than the default value (10 minutes)
Summary
In this article, I have explained Snowflake warehouse pricing model, especially for the case where you use external ETL tool such as AWS DMS or Fivetran. Depending on your use case and budge for infra cost, you need to understand the pricing model and change configurations of your warehouse to optimize your warehouse workload and computing cost.

Snowflake データクラウドのユーザ会 SnowVillage のメンバーで運営しています。 Publication参加方法はこちらをご参照ください。 zenn.dev/dataheroes/articles/db5da0959b4bdd
Discussion