本記事の背景
BI や アドホック分析用に Snowflake 上のデータを加工したい場合、大抵の場合は、SQL でデータ加工ロジックを作り、ビューやテーブルを作成することが多いと思います。一方で、SQL で実現が困難な処理を実装する場合、Snowflake 版 Spark Data Frame API である Snowpark は有力なオプションの1つです。
ただ、2022年4月10日現在、Snowpark は Scala API のみ GA になっており、Python APIのステータスは Private Preview であり、まだ本番環境では利用できない状態です。筆者のチームでは、AWS において Snowpark Python API の代替になりうる筆頭候補はサーバレス Spark 環境である AWS Glue であると考えて、Glue から Snowflake に接続して、データ処理を行う環境の検証を実施していました。
ここで筆者の企業では、セキュリティの観点で Snowflake への接続はプライベート接続のみに限定しており、VPC Endpoint から AWS Priavte Link を経由して Snowflake に接続する必要があります。よって Private Link 経由での接続方法について調査と検証を行いました。本記事では、その設定方法について紹介します。
前提となるネットワーク構成
本記事の前提となるネットワーク構成は以下の通り。

- 自社のクラウドサービスとして AWS を利用しており、Snowflake の クラウドサービスは AWS を選択している。
- 両 AWS アカウント内の VPC 間は、Private Link で接続されている。Private Link の設定方法については以下を参照のこと。
- Glue ジョブは自社 AWS アカウントの VPC Endpoint から Private Link を経由して、Snowflake に接続する。
- 筆者の環境のように接続先の JDBC データストア (今回は Snowflake) が VPC 内にある場合、その VPC の設定をした Glue Connection を利用する必要がある。https://docs.aws.amazon.com/glue/latest/dg/connection-JDBC-VPC.html
- 筆者が検証した範囲では、Glue connection は Snowflake の JDBC URL を直接サポートしていない。Glue Connection がサポートしていない JDBC URL をサポートする目的で、Glue connector という機能が提供されているため、Connector から Connection を作成する。
Glue の環境設定
ここからは実際に Private Link 経由で Snowflake に接続する Glue ジョブを作成していきます。
前提 - Private Link 設定が完了している
本記事では、前提として以下の設定が完了しているものとします。
- 自社の AWS アカウントと Snowlake の VPC が既に Private Link で接続されている。
- VPC 内部から Snowflake のプライベートエンドポイントに接続できる。
環境していない場合は、以下のドキュメントを参照の上、設定を完了してください。
- https://docs.aws.amazon.com/vpc/latest/privatelink/endpoint-services-overview.html
- https://docs.snowflake.com/en/user-guide/admin-security-privatelink.html
Glue connector の作成
前述の通り、Snowflake の JDBC URL に対応するには Glue Connector を作成する必要があります。Glue Connector を作成するには、以下の通り、Glue Studio から Connector を作成してください。
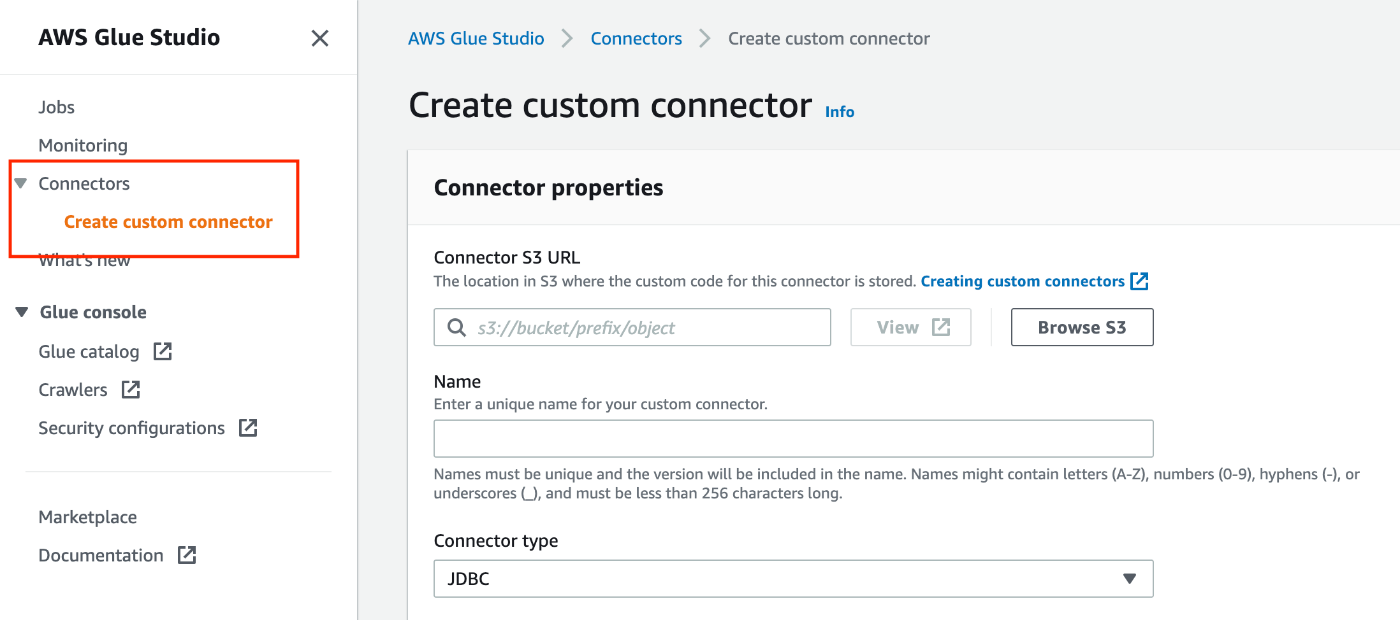
- Connector S3 URL: コネクタのカスタムコードを配置するS3 URL
- Name: コネクタの名前
- Connector type: JDBC
- Class name:
net.snowflake.client.jdbc.SnowflakeDriver - JDBC URL base:
https://$account-id.$region-name.privatelink.snowflakecomputing.com:443/-
$account-id及び$region-nameは、自社の環境に合わせて変更してください。
-
- URL parameter delimiter:
& - Description: 任意
Glue connection の作成
作成した Connector の詳細画面から Glue Connection が作成できます。以下の通り、Connection を作成してください。
- Name: connection の名前
- Description: 任意
- Connection access
- Connection credential type: default
- Additional URL parameters: 任意
- JDBC URL にパラメタを追加できます。URL については以下のドキュメントを参照。
- https://docs.snowflake.com/en/user-guide/jdbc-configure.html#jdbc-driver-connection-string
- Network options
- VPC: Private Link を設定した VPC を選択
- Subnet: Private Link を設定した VPC のサブネットを選択
- Security groups: Glue ジョブ用のセキュリティグループを選択。
- セキュリティグループには以下のURLにあるとおり、インバウンド設定とアウトバウンド設定を実施してください。
- https://docs.aws.amazon.com/glue/latest/dg/setup-vpc-for-glue-access.html
Snowflake ドライバ の取得
今回は JDBC で接続し、データを Spark Data Frame にロードするため、以下のドライバが必要です。以下 URL からダウンロードしてさい。
- JDBC https://docs.snowflake.com/en/user-guide/jdbc-download.html
- Spark https://docs.snowflake.com/en/user-guide/spark-connector-install.html
- Glue version 3.0 で対応している Scala バージョンは 2.12 のため、
spark-snowflake_2.12を選択してください。
- Glue version 3.0 で対応している Scala バージョンは 2.12 のため、
取得したドライバの jar ファイルは S3 バケットにアップロードしてください。Glue ジョブから参照する必要があります。
Glue job の作成
作成した Glue connection の詳細画面から新規のジョブを作成できます。以下の通り、設定してください。
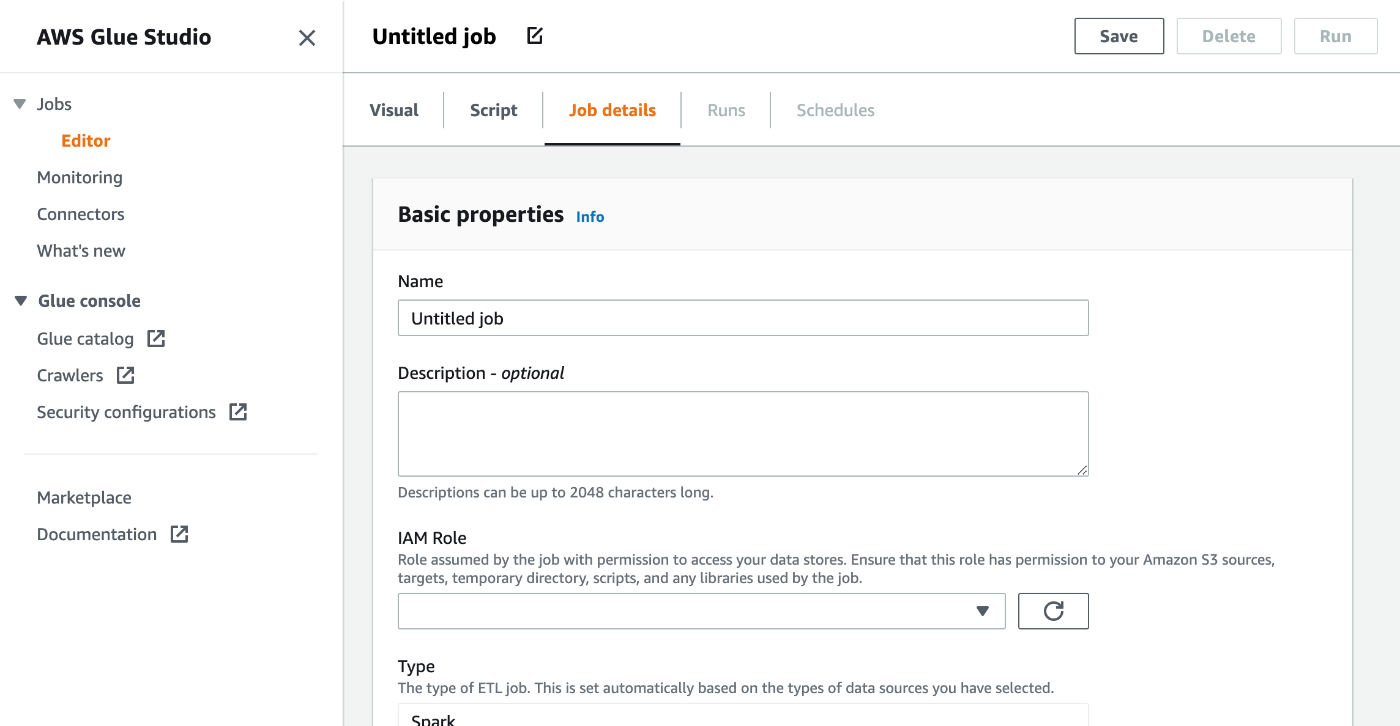
- Basic properties
- Name: Glue job の名前
- Description: 任意
- IAM Role: Glue job 用のIAM roleを指定
- IAM Role には少なくとも
AWSGlueServiceRoleをつける必要があります。またドライバを配置したS3バケットへの参照権限をつけてください。 - それ以外のサービスにアクセスする場合は、必要に応じてIAM policy を設定してください。詳細は以下を参照。
- https://docs.aws.amazon.com/glue/latest/dg/using-identity-based-policies.html#access-policy-examples-aws-managed
- IAM Role には少なくとも
- Type: Spark
- Glue version: 3.0
- Language: Python 3
- その他はデフォルトのまま。必要に応じて変更してください。
- Advanced properties
- Script filename: 通常はジョブ名と同じ
- Script path: スクリプトを配置する S3 の URL
- Spark UI logs path: ログを配置する S3 の URL
- Temporary path: 作業ディレクトリの S3 URL
- Connections: 先ほど作成した connection を選択
- Libraries
- Dependent JARs path: JDBC と Spark のドライバの S3 URL。URLをつなぐ際は、コロン
,をつけてください。 - (例)
s3://mybucket/snowflake-jdbc-xxx.jar,s3://mybucket/snowflake-spark-xxx.jar
- Dependent JARs path: JDBC と Spark のドライバの S3 URL。URLをつなぐ際は、コロン
- Job parameters
- 再利用性を高めるため、接続設定はパラメタとして与えます。今回はパスワードを直接記述しますが、本番環境で使う場合は、Secret Manager から取得するようにしてください。
- URL:
https://$account-id.$region-name.privatelink.snowflakecomputing.com:443/-
$account-id及び$region-nameは、ご自身の環境に合わせて変更してください。
-
- ACCOUNT: Snowlake アカウント名
- WAREHOUSE: ウェアハウス名
- DB: データベース名
- SCHEMA: スキーマ名
- USERNAME: ユーザ名
- PASSWORD: パスワード
- Script
- ロックを外し、以下のサンプルコードをコピーしてください。本サンプルでは、テーブルのデータをロードし、別のテーブルに書き込みます。
-
"table_name"、"new_table_name"は、ご自身の環境に合わせて変更してください。 - https://community.snowflake.com/s/article/How-To-Use-AWS-Glue-With-Snowflake
import sys
from awsglue.transforms import *
from awsglue.utils import getResolvedOptions
from pyspark.context import SparkContext
from awsglue.context import GlueContext
from awsglue.job import Job
from py4j.java_gateway import java_import
SNOWFLAKE_SOURCE_NAME = "net.snowflake.spark.snowflake";
## @params: [JOB_NAME, URL, ACCOUNT, WAREHOUSE, DB, SCHEMA, USERNAME, PASSWORD]
args = getResolvedOptions(sys.argv, ['JOB_NAME', 'URL', 'ACCOUNT', 'WAREHOUSE', 'DB', 'SCHEMA', 'USERNAME', 'PASSWORD'])
sc = SparkContext()
glueContext = GlueContext(sc)
spark = glueContext.spark_session
job = Job(glueContext)
job.init(args['JOB_NAME'], args)
java_import(spark._jvm, "net.snowflake.spark.snowflake")
## uj = sc._jvm.net.snowflake.spark.snowflake
spark._jvm.net.snowflake.spark.snowflake.SnowflakeConnectorUtils.enablePushdownSession(spark._jvm.org.apache.spark.sql.SparkSession.builder().getOrCreate())
sfOptions = {
"sfURL" : args['URL'],
"sfAccount" : args['ACCOUNT'],
"sfUser" : args['USERNAME'],
"sfPassword" : args['PASSWORD'],
"sfDatabase" : args['DB'],
"sfSchema" : args['SCHEMA'],
"sfWarehouse" : args['WAREHOUSE'],
}
## Read from a Snowflake table into a Spark Data Frame
df = spark.read.format(SNOWFLAKE_SOURCE_NAME).options(**sfOptions).option("dbtable", "table_name").load()
## Perform any kind of transformations on your data and save as a new Data Frame: df1 = df.[Insert any filter, transformation, or other operation]
## Write the Data Frame contents back to Snowflake in a new table
df.write.format(SNOWFLAKE_SOURCE_NAME).options(**sfOptions).option("dbtable", "new_table_name").mode("overwrite").save() job.commit()
Glue job の実行
Save ボタンを押してジョブを保存した後、Run ボタンを押すとジョブが実行されます。設定に問題なければ、ステータスが Succeeded でジョブが終了します。新しいテーブルが作成されているか確認してください。
まとめ
本記事では、SQL で実現できないデータ処理ロジックを実装する手段として Glue を紹介しました。
- Glue で Private Link 経由で Snowflake プライベートエンドポイントに接続するには、VPC 設定をした Glue connection を作成する必要があります。
- Snowflake JDBC URL は Glue connection で直接サポートしていないため、Glue connector から Connection を作成する方法を紹介しました。
本記事が筆者と同じく Private Link ありで Snowflake を利用されている方の参考になれば幸いです。

Snowflake データクラウドのユーザ会 SnowVillage のメンバーで運営しています。 Publication参加方法はこちらをご参照ください。 zenn.dev/dataheroes/articles/db5da0959b4bdd
Discussion