本記事は、Snowflake Advent Calendar 2021 の2日目です。
1日目は、Snowvillage 村長による「Snowflake 2021年 よかったこと5選」でした。
本記事では、Snowflake 版 Data Frame API である Snowpark のアプリケーションをコンテナ技術を使ってデプロイする方法について紹介します。
Snowpark をご存知ない方はこちらを参照ください。
本記事の背景
Snowpark が Preview になって以後、公式・非公式含め、Snowpark のチュートリアル記事をネット上でいくつか見つけました。どの記事も Snowpark そのものの機能やユースケースにフォーカスしており、本番環境でどうデプロイするか、どうアプリケーションを実行させるかを紹介していませんでした。
例えば、Snowpark の公式チュートリアルでは、sbt(Scala のビルドツール)をそのまま使い、以下のような簡易的な実行方法を採用しています。
- sbt run で UDFDemoSetup.scala を指定すると、ライブラリダウンロード、ソースコードのビルドが行われ、UDFDemoSetup が実行される。
- UDFDemoSetup は CSV ファイルと追加依存ライブラリを内部ステージにアップロードする。
- 次に sbt run で UDFDemo.scala を指定すると、UDFDemo が実行される (ライブラリダウンロード、ビルドは1で実行済み)。
- Snowpark アプリケーション(UDFDemo)が Snowflake にデプロイされる。
- Snowpark アプリケーション (UDFDemo) が CSV ファイルと依存ライブラリをロードする。
- 自然言語処理(センチメント分析)の実行結果をテーブルに書き込む。
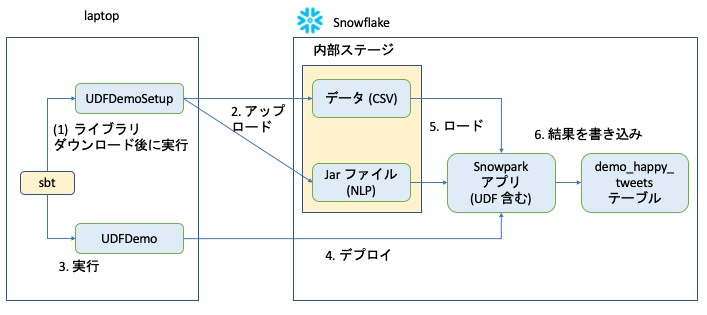
ここで本チュートリアルのアプリケーション実行方法が簡易的だと思う点は以下の通りです。
(1) sbt の対話的な実行コマンドである sbt run でアプリケーションを実行させる。
(2) 依存ライブラリを Snowflake のストレージ領域である internal stage から実行時にロードしている。
チュートリアルは Snowpark を理解するために書かれているため、Snowpark の本質的な箇所にフォーカスし、それ以外は簡易的に書くのは当然だと思います。ただ、実際に本番で使ってみようと考えた場合、どうデプロイするか決める必要があります。
私自身は普段はデータエンジニアとして、本番向けのデータパイプラインや DevOps 周りと担当することが多いので、実際、Snowpark を本番で使う場合は、どういうデプロイ方法をするのか考えたくなり、本記事を書こうと決意しました。
簡易実行方法の課題 (sbt run での実行、内部ステージからのライブラリロード)
まず冒頭に挙げた公式チュートリアルで利用されている、以下の簡易実行方法を本番で利用するとどういう問題があるか説明します。
sbt の対話的な実行コマンドである sbt run でアプリケーションを実行させる
メイン関数を指定して sbt run を実行すると初回は以下が行われます。
- 依存ライブラリをダウンロードする。
- ソースコードをビルドする。
- 実行可能バイナリを生成する。
- アプリケーションを実行する。
この方法は、開発中の動作確認には便利ですが、以下の問題があります。
- 本番環境で利用すると実行開始まで時間がかかってしまい、意図したタイミングで実行されなくなる。
- 毎回クリーンな環境で実行される場合、毎回、ライブラリのダウンロードやソースコードのビルドが走り、計算資源の無駄になる。
(注)sbt の詳細については以下の公式チュートリアルを参照ください。
依存ライブラリを Snowflake のストレージ領域である内部ステージから実行時にロードする
Stage は S3 や GCS といったクラウドストレージを抽象化したストレージ層です。いくつか種類があり、内部ストレージは Snowflake 側のストレージに相当します。
内部ステージはデータをアップロードして Snowflake 側で利用するのに簡易的で、非常に便利ですが、アプリケーション開発で利用すると以下の問題があります。
- ライブラリを Stage に上げて利用することは、複数プロジェクトが同時並行で走るアプリケーション開発において、共有フォルダでライブラリを管理するのに近いやり方。複数のアプリケーションが、異なるバージョンのライブラリを利用し始めた場合、適切なライブラリの管理が困難になる(例:別のアプリによって削除されたり、上書きされるリスクがある)。
- 実行時に意図したライブラリが意図した場所になかったり、異なるファイルが置かれていた場合、実行時にアプリケーションが異常終了してしまう。
(解決策) 事前に実行可能なアプリケーションを Docker イメージにまとめ、コンテナオーケストレーションサービスにデプロイする
ここからは私が考える本番を想定した Snowpark アプリケーションのデプロイ方法を紹介します。
以下は筆者が本番環境にデプロイする際の構成です。GitlabやAWSを前提としていますが、他のクラウドサービスでも同じことができます。
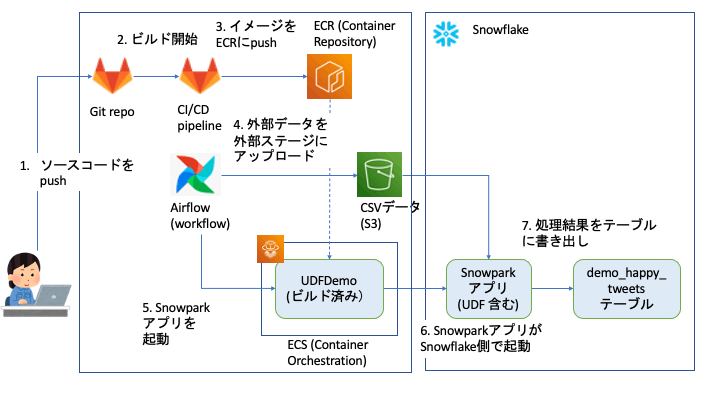
Snowpark アプリケーションを Docker イメージとしてかため、コンテナイメージリポジトリ (AWS ECR) に登録する
まずアプリケーションの依存ライブラリを実行時に解決するやり方は、実行時まで不確定要素を残すことになるので、実行前前にDockerイメージなどにかためておくのが良いでしょう。
開発・テスト時と本番時で同じイメージを利用することで、実行時の問題によってアプリケーションが起動できない・処理に失敗するリスクを低減できます。
GitリポジトリやAWS上で実現する場合は、上記図のステップ1〜3のようにPull Requestなどトリガにアプリケーションをビルドするジョブを走らせます。ジョブが成功してイメージができたら、コンテナイメージのリポジトリ(AWS であれば ECR)にイメージを登録します。
チュートリアルのサンプルコードとは異なりますが、Docker で Snowpark アプリのイメージをビルドするサンプルコートは以下のリポジトリに公開していますので、よければ参照ください。
Dockerfile では、sbt stage で依存ライブラリのダウンロード、ソースコードのビルド、実行可能 jar ファイルの生成などを行なっています。
なお、sbt には Docker イメージを直接ビルドできるプラグインがありますが、Dockerfile 相当の処理を sbt 設定ファイル上に Scala コードで書くというかなり独特な実装なため、今回は使いませんでした。ほとんどの人には Dockerfile を書く方が楽でしょう。
ワークフローツールで外部データを取得し、Snowparkアプリを起動する
元々のチュートリアルのサンプルコードでは、依存ライブラリと入力データ(ツイートを CSV にまとめたもの)を一緒に内部ステージに
上げた上で、Snowpark アプリケーションを起動しています。
前提としてセンチメント分析対象のツイートは定期的にバッチでダウンロードして処理するとした場合、本番環境では、上記図のように Airflow などのワークフローツールで一連の流れを実装します。
入力データ(ツイートをCSVに固めたもの)は外部ステージとして登録した S3 バケットに置いておき、後での再利用を想定し、COPY コマンドでテーブルに入れておいても良いと思います。
Snowpark アプリケーションのイメージは事前にコンテナリポジトリに登録してあるので、コンテナオーケストレーションサービス(AWS ECSなど)にコンテナの起動を指示すれば、Snowpark アプリケーションが起動します。コンテナ側でアプリが起動しますが、実際の処理は Snowflake 側のコンピューティングリソース内で行われます。
おわりに
今回は Snowpark の Scala API のサンプルコードを見たときのモヤモヤ(本番でどうデプロイするかな)を元に、サンプルをそのまま本番で使う場合の問題点や、自分がアプリを実装する際のデプロイ方法などを簡単に紹介しました。
デプロイ周りが気になる方の参考になれば幸いです。
なお、本記事を公開する頃には Python API のハンズオン(2021年11月30日開催)に参加済みの予定です。ハンズオン終わり次第、Python APIの概要や使ってみての所感なども記事に書きたいと思います。

Snowflake データクラウドのユーザ会 SnowVillage のメンバーで運営しています。 Publication参加方法はこちらをご参照ください。 zenn.dev/dataheroes/articles/db5da0959b4bdd
Discussion