この記事はSnowflake Summit 2024のBuilders Boothで上映されていた動画の中でTipsとしてショートデモ発表した内容です。そういえばブログにしていなかったので改めて記事化します。
SELECT句の「*」とは
標準SQLにおいて、「*」はSELECT句で「すべての列」を示すことができるワイルドカードです。
select * from customer;
これで、列が100個あるテーブルであろうと、SELECT句に列挙せずにすべての列を表示することができます。簡単ですね。
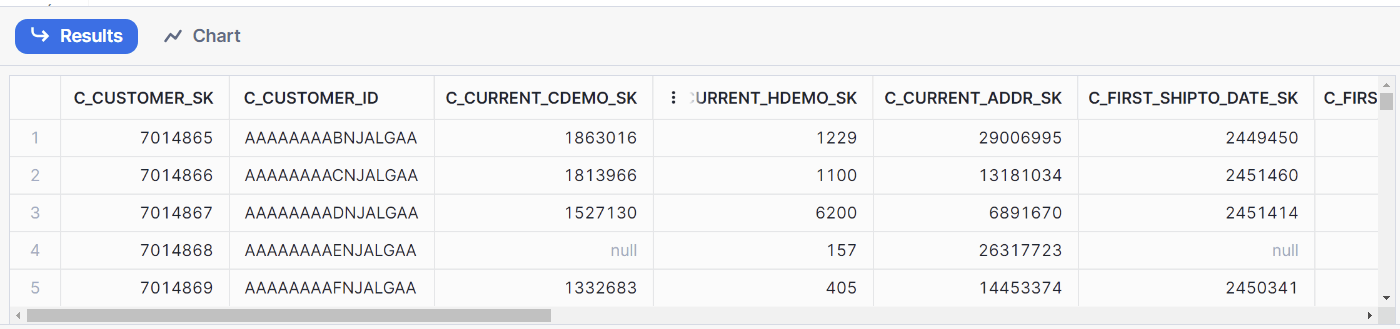
※本記事内サンプルクエリはすべてTPC-DSのCUSTOMERテーブルを例にしています。
開発の世界ではご法度
まず注意事項ですが、SQL開発の世界では*を容易に使うのはアンチパターンですので気を付けましょう。
OLTP的なアプリケーションであっても、大規模データ処理であっても、列を指定しないことはパフォーマンスに悪い影響を与えます。IO最小化の観点でもちろん選択列は最小限に抑えるべきですし、仮にすべての列を指定する場合であっても、コンパイラに無駄な負荷を掛けることになるため、列名はすべて記述すべきです。
またパフォーマンスだけでなく、管理面でみてもクエリに*を使ってしまうと、テーブルのどの状態を求めていたのかがあとからわからなくなってしまうというデメリットもあります。ALTER TABLEによる列変更の影響が調査できなくなるのはもちろん、それと似たような話で、Snowflakeの場合はViewの定義内で*を使っている際に元テーブルの列追加されると、Viewに対するクエリが(そのクエリが追加列を使っていなくても)すべてエラーになります。
アドホッククエリではよく使われる
商用システムに組み込まれるようなクエリではご法度の*ですが、使い捨てのアドホッククエリでは普通によく使われます。
このテーブルにはどんなデータが入っていたっけ?こういうクエリを叩いてみたらどんな結果になるかな?データをすべて出力して突合しよう、などなど、分析の過程、クエリを開発する途中の段階、運用中のオペレーション等です。SQL作成者の負担軽減はもとより、そういったアドホックな場面で多くの列を持つテーブルの場合は、列名を指定しないことでむしろミスや勘違いを防ぐことのメリットが大きいとも言えるかもしれません。
SnowflakeはSQLを書く人にとてもやさしいプロダクトなので、このアドホッククエリを書く人のためのちょっと珍しい方言(標準SQLにない文法)を持っています。それが今回お伝えする*の特殊な文法です。
文法
公式ドキュメントは以下をご確認ください。とはいえこれはSELECT全体のドキュメントなので、今回は*絡みのところを絞ってご紹介します。
SELECT <カラム>, *, <カラム>
私が個人的に最もよく使うシンプルに魅力的な文法が、*と普通のカラム指定を併用する方法です。何も特殊なことはなく、普通にカンマで繋ぐことができます。単なるカラムだけでなく、式を指定することももちろんできます。
select c_birth_year||c_birth_month, * from customer;

これ、単純だけどとても便利じゃないですか?例えばアドホッククエリを投げるなかで、スカラ関数でデータを加工したいな、というとき、元データをそのまま横に置きつつ、関数の結果を確認できます。私は非常に多用しています。
SELECT * EXCLUDE <カラム>
逆にEXCLUDEを使うことで、特定の列だけを結果から除外することもできます。
select * exclude c_last_review_date from customer;
※わかりづらいので結果表は省略します
これも様々な利用方法がありますね。例えば更新タイムスタンプ列を除いて実データのみを抽出したり、二つの表から更新タイムスタンプ列を除いてUNION、MINUS(EXCEPT)、INTERSECTしたりする際に、サブクエリでEXCLUDEを使えばかなりシンプルにSQLを書くことができます。こういったクエリは使い捨ての運用SQLで発生しがちで、全カラムを羅列することはミスにもつながるため、EXCLUDEのありがたみがわかる場面です。
SELECT * ILIKE ('<パターン>')
ここから先は私はそんなに多用はしていませんが、面白い機能ではあるので人によっては重宝するかもしれません。
ILIKEを使うことで、結果列をパターンマッチングで選択することができます。
select * ilike '%birth%' from customer;

どんなカラムの多い横長なテーブルでも、命名規則に従って一定のカラムを抜き出すようなことができます。
SELECT * RENAME <カラム> AS <別名>
RENAMEは*を使いつつ、カラム名にASによる別名を付けることができます。
select * rename c_customer_id as customer_id from customer;
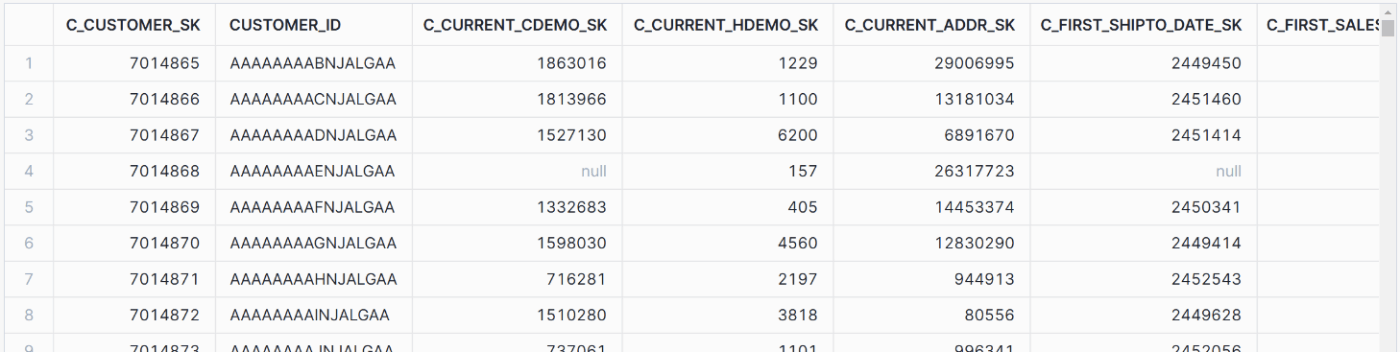
簡易レポートとしてこのまま別名をヘッダとしてCSVに出力しても良いですし、サブクエリでも使える場面があるかもしれません。
SELECT * REPLACE (<式> AS <カラム>)
ここまでは列の有無をいじったり列名を変更できるものでしたが、REPLACEは列の値を変更することができてしまいます。
select * replace ('ID-' || c_customer_id AS c_customer_id) from customer;
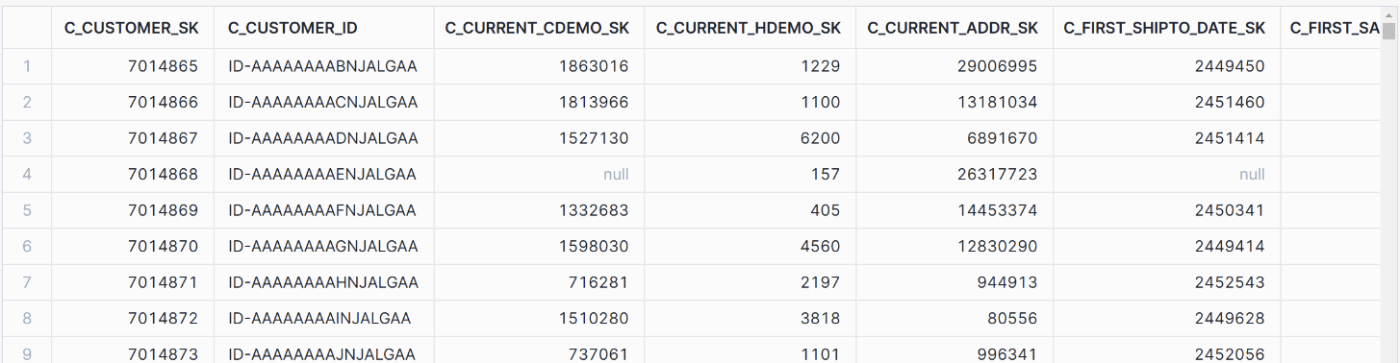
ここまで行くと個人的にはあまり*で対応したくない気もしますが、RENAMEともども簡易レポーティングとして使えるかもしれません。
おわりに
使い捨てクエリを書くことの多いデータエンジニアの方にとっては、いくつか使えるものもあったのではないでしょうか。慣れてしまうとこの方言がないDBMSを使いづらく感じてしまうかもしれません。
こういった標準SQLではない方言の世界もなかなか面白いものです。Snowflakeにも最初から全部実装されていたわけではなく、順次使い勝手の向上の一環として追加されてきています。以下のリリースノートのリストを見ると、他にも面白い実装が数多くあります。今年(2024年)のものでいうと、末尾カンマを無視してくれる改善はかなりヒットでした。
ということで、今回は深淵なるSnowflake SQLの世界のごく一部として、*を使った文法のご紹介でした!

Snowflake データクラウドのユーザ会 SnowVillage のメンバーで運営しています。 Publication参加方法はこちらをご参照ください。 zenn.dev/dataheroes/articles/db5da0959b4bdd
Discussion