GENIAC第2期成果/データグリッド:汎用動画生成基盤モデルと選択的編集モジュールの開発
はじめに
こんにちは。
DATAGRIDのAIエンジニアの脇坂です。
データグリッドでは、経済産業省およびNEDOが推進する日本の生成AIの開発力強化に向けたプロジェクト「GENIAC」第2期の支援のもと、Vision系基盤モデルの開発に取り組みました。
当社は2017年創業の京都大学発AIスタートアップとして、GAN(敵対的生成ネットワーク)や拡散モデルといった生成AIやそれらを活用した合成データをコア技術として、創業以来製造業をはじめとする多様な産業分野へAIデータソリューションを提供してまいりました。本プロジェクトでは、これまで培ってきた生成AIに関する知見や技術を活かし、ユーザーの意図を的確に反映できる動画・画像生成基盤モデルを開発いたしました。
本記事では、GENIACプロジェクトを通じて開発したText-to-Video(T2V)モデルおよびVideo-to-Video(V2V)Inpaintモデルに関する開発ノウハウと、その評価結果についてご報告します。
Vision系基盤モデル開発の概要
本プロジェクトでは、主に以下の2つのVision系基盤モデルの開発に注力しました。
- Text-to-Video (T2V)モデル: テキストによる指示(プロンプト)から動画を生成するモデル。
- Video-to-Video (V2V) Inpaintモデル: 動画内の特定領域を、周囲と調和するように自然に修復・編集するモデル。
これらのモデル開発において、データ準備の効率化と再現性確保のため、ComfyUIを用いたワークフロー構築や、Kubernetesを活用した並列処理を導入しました。
他社大規模モデルとの比較(参考情報)
動画生成AIの分野では、世界的に大規模なモデル開発が進んでいます。参考として、いくつかのモデルの情報を以下に示します。
-
Goku (ByteDance社):
- データセット: Panda70Mから11M動画、自社収集データ25M動画など。
- モデルサイズ: 1B~8Bパラメータ。
-
HunyuanVideo (Tencent社):
- モデルサイズ: 13Bパラメータ。
当社の取り組み(OpenSoraPlanベース)では、独自に収集したロイヤリティフリーの動画から0.16M件を選定し、これを学習データセットとして活用しました。 このデータセットを用い、現時点で2.7Bパラメータのモデルを中心に開発を進めています。これら大規模モデルの動向も注視しつつ、効率的な学習と高品質な生成を目指しています。
Text-to-Video (T2V) モデル開発
データ準備のノウハウ
T2Vモデルの学習データ準備においては、OpenSoraPlanで用いられているデータ前処理手法を参考に、前述の独自収集した0.16M件のロイヤリティフリー動画データセットをベースに、高品質な動画とテキストのペアを効率的に収集・整備しました。
具体的なノウハウとしては、以下の点が挙げられます。
- データ前処理の共通化: OpenSoraPlanと同様の基準で動画のフィルタリング、リサイズ、フレーム抽出などを行い、学習データの品質を担保。
- ワークフローの構築と自動化: データ収集から前処理、学習データのパッケージングに至る一連のプロセスをComfyUI上でワークフローとして構築しました。これにより、手作業を削減し、再現性の高いデータ準備を実現しました。
- 分散処理による高速化: 大量の動画データの処理には時間を要するため、Kubernetesを活用して前処理タスクを並列実行し、データ準備期間を大幅に短縮しました。
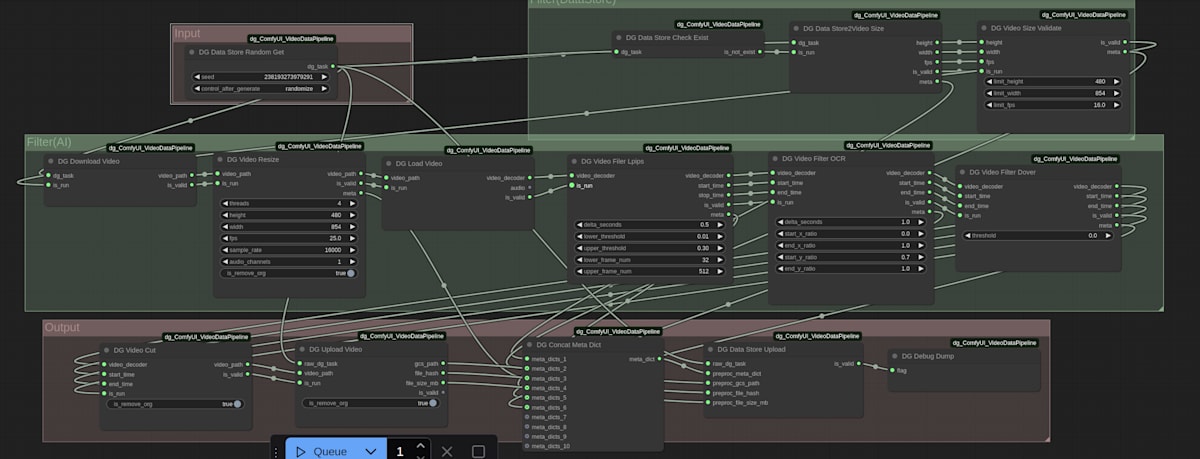
図1: ComfyUIを用いたデータ前処理・キュレーションワークフローの例
T2Vモデルの評価結果
開発したT2Vモデルの性能を、標準的な評価指標であるFVD (Fréchet Video Distance) およびVBenchを用いて評価しました。FVDは値が低いほど、生成動画と実動画の分布が近いことを示します。
FVD (sky_timelapse)
表1: T2VモデルのFVD (sky_timelapse) 評価結果
| Model | FVD↓ |
|---|---|
| Open-Sora-Plan-v1.3.0 | 42.19 |
| DATAGRID-Open-Sora-Plan-v1.3.0-0.16M (当社開発モデル) | 37.78 |
| Latte | 42.67 |
当社の開発モデル(DATAGRID-Open-Sora-Plan-v1.3.0-0.16M)は、ベースラインとなるOpen-Sora-Planや他のモデルと比較して、FVDスコアの改善が見られました。
表2: T2Vモデルによる生成動画の比較 (FVD評価、sky_timelapse)
| 元動画 | latte | Open-Sora-Plan-v1.3.0 | DATAGRID-Open-Sora-Plan-v1.3.0-0.16M |
|---|---|---|---|
 |
 |
 |
 |
上のGIF比較では、当社のDATAGRID-Open-Sora-Plan-v1.3.0-0.16Mモデル が、元動画の構図や雰囲気をより忠実に再現しているように見受けられます。例えば、元動画には存在しない月が Open-Sora-Plan-v1.3.0では生成されていますが、当社モデルではそのような不自然なオブジェクトの追加は見られません。また、latteと比較して、空の色合いや地平線のディテールが向上している傾向が確認できます。
VBench
VBenchは、動画生成品質を多角的に評価するベンチマークです。以下の表は、主要な評価項目におけるスコアを示しています。
表3: T2VモデルのVBench評価結果
| Model | quality score | semantic score | total score | subject consistency | background consistency | temporal flickering | motion smoothness | dynamic degree | aesthetic quality | imaging quality | object class | multiple objects | human action | color | spatial relationship | scene | appearance style | temporal style | overall consistency |
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| OpenSoraPlan.v.1.3.0 | 0.810 | 0.606 | 0.769 | 0.986 | 0.983 | 0.993 | 0.990 | 0.282 | 0.590 | 0.618 | 0.630 | 0.365 | 0.81 | 0.823 | 0.382 | 0.341 | 0.206 | 0.231 | 0.246 |
| DATAGRID-Open-Sora-Plan-v1.3.0-0.16M (当社開発モデル) | 0.814 | 0.594 | 0.770 | 0.975 | 0.981 | 0.995 | 0.991 | 0.477 | 0.589 | 0.553 | 0.679 | 0.305 | 0.83 | 0.844 | 0.305 | 0.291 | 0.206 | 0.232 | 0.245 |
VBenchによる多角的な評価では、dynamic degree、object class、human action、colorといった項目でベースラインモデルからの改善が見られました。これらの改善傾向は、当社が独自に収集・整備した0.16Mのロイヤリティフリー動画からなるデータセットの特性が反映された結果と考えられます。このデータセットが持つ多様なシーン、リアルな動きのパターン、そして様々なオブジェクトの視覚的特徴が、モデルの表現力向上に寄与した可能性があります。一方で、imaging qualityやspatial relationshipといった一部の項目ではスコアに課題も確認されており、これらは独自データセットのさらなる質の向上や量的な拡充、および学習手法の継続的な最適化を通じて、引き続き改善に取り組んでまいります。
表4: T2Vモデルによる生成動画のVBench観点別比較
| 観点 | プロンプト | Open-Sora-Plan-v1.3.0 | DATAGRID-Open-Sora-Plan-v1.3.0-0.16M |
|---|---|---|---|
| dynamic degree | an airplane accelerating to gain speed |  |
 |
| object class | a bicycle |  |
 |
| human action | A person is ice skating |  |
 |
| color | A pink bird |  |
 |
| imaging quality | this is how I do makeup in the morning |  |
 |
| spatial relationship | a kite on the top of a skateboard, front view |  |
 |
V2V (Inpaint) モデル開発
データ準備のノウハウ
V2V Inpaintモデルは、動画内の不要なオブジェクトを自然に消したり、一部を修正したりする際に活用できます。このモデルの学習には、高品質なマスク動画データが不可不可です。
- マスク自動アノテーション: Meta AI社のSAM2 (Segment Anything Model 2) とMicrosoft社のFlorence2といった最新のモデルを活用し、動画内の対象オブジェクトに対するマスクを自動で生成するパイプラインを構築しました。これにより、従来は多大な人手と時間を要していたアノテーション作業の大幅な効率化とコスト削減を実現しました。
- 品質管理: 自動生成されたマスクデータに対して、人手によるレビューを実施。尤度の閾値を設定することで、品質の高いマスク動画のみを厳選して学習に使用しました。
- ワークフローと分散処理: T2Vモデルと同様に、ComfyUIによるワークフロー構築とKubernetesでの並列処理を導入し、データ準備の迅速化を図りました。
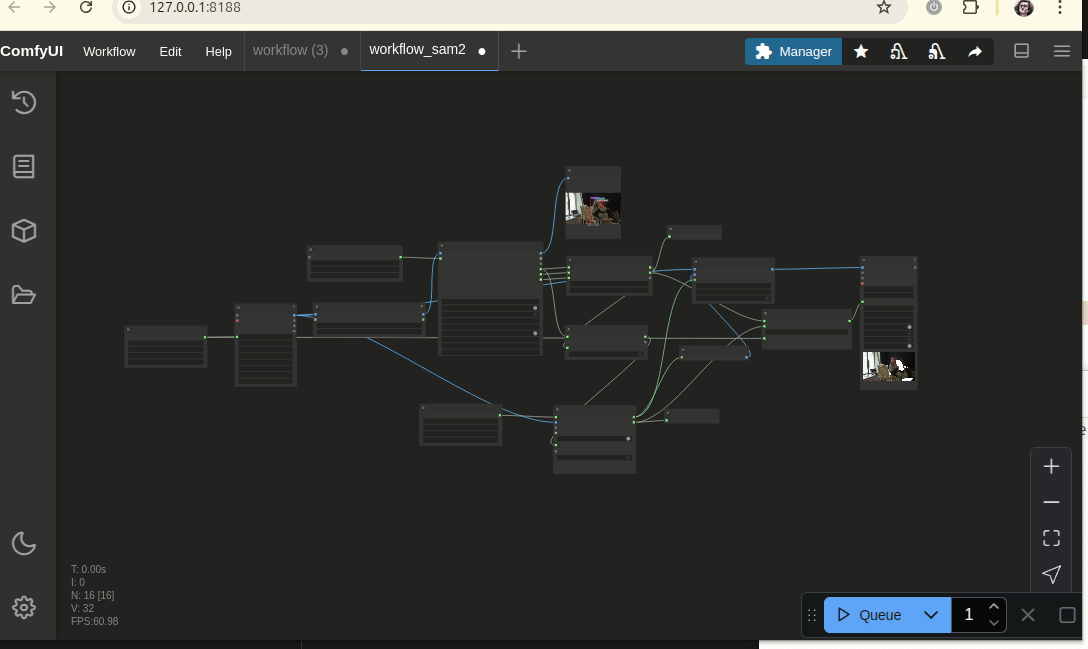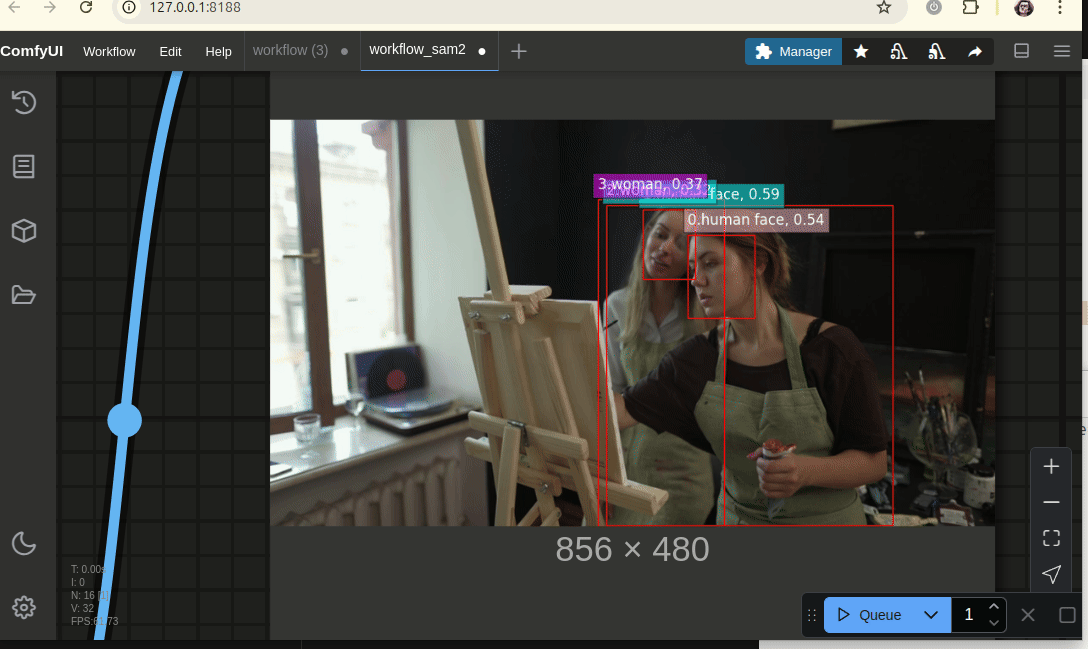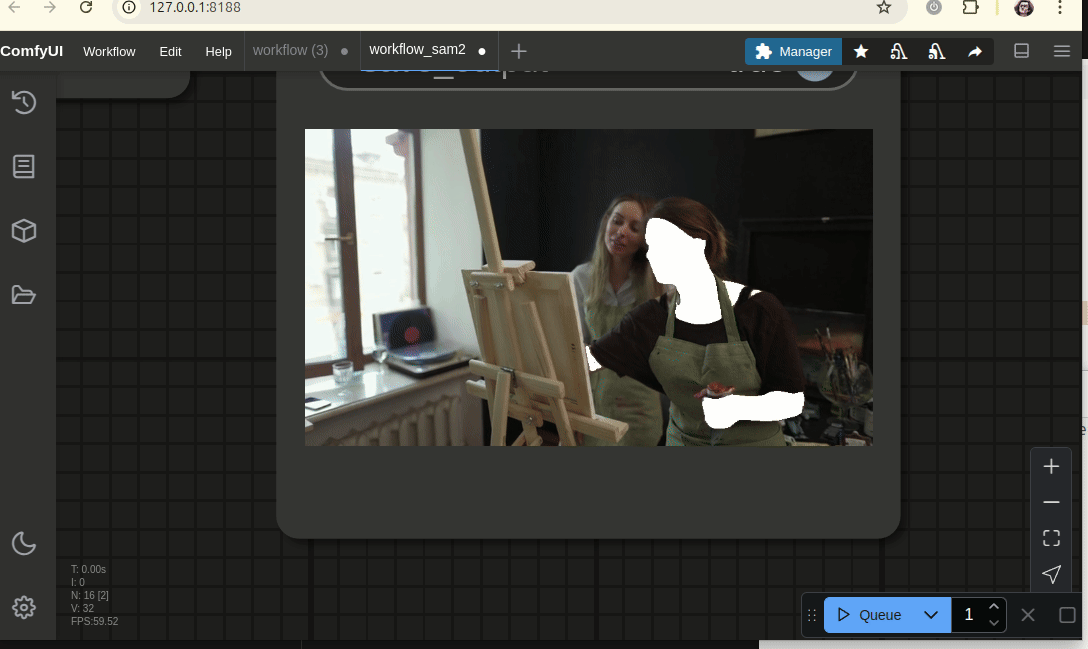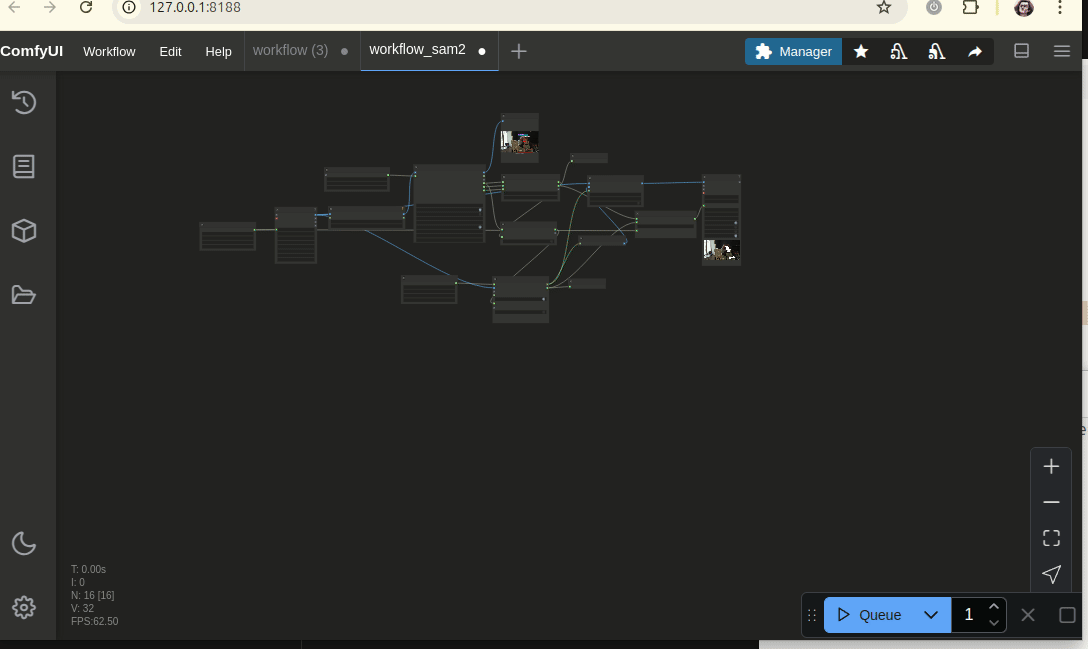
図2: SAM2とFlorence2を活用したマスク自動アノテーションとComfyUIワークフローの例
V2V (Inpaint) モデルの評価結果
開発したV2V Inpaintモデルの性能を、Fram-ACC (Frame Accuracy: フレームごとのピクセル精度)、Tem-Con (Temporal Consistency: 時間的一貫性)、Pixel-MSE (Pixel Mean Squared Error: ピクセル単位の平均二乗誤差) といった指標で評価しました。Fram-ACCとTem-Conは値が高いほど、Pixel-MSEは値が低いほど性能が良いことを示します。
表5: V2V (Inpaint) モデルの評価結果 (Fram-ACC, Tem-Con, Pixel-MSE)
| Model | Fram-ACC↑ | Tem-Con↑ | Pixel-MSE↓ |
|---|---|---|---|
| OpenSoraPlan.v.1.3.0 | 0.6428 | 0.9882 | 1.1403 |
| DATAGRID-Open-Sora-Plan-v1.3.0-0.16M-Inpaint (当社開発モデル) | 0.6520 | 0.9902 | 0.9544 |
表6: V2V (Inpaint) モデルによる動画編集の例
| 元動画 | プロンプト (短縮) | マスク | DATAGRID-Open-Sora-Plan-v1.3.0-0.16M(Inpaint) |
|---|---|---|---|
 |
A juicer pours orange juice into a container. ・・・Morning juice-making scene. |  |
 |
 |
A reddish-brown cat resting in a grassy field, ・・・relaxed and content. |  |
 |
V2V (Inpaint)モデルの評価では、プロンプトとマスクに基づいて、動画内の指定されたオブジェクト(例:コンクリートミキサー、狐)を自然に編集できています。
- コンクリートミキサーの例では、マスクで指示されたコンクリートミキサーが除去され、背景が自然に補完されています。オレンジジュースが注がれる様子は維持しつつ、主要なオブジェクトが違和感なく編集されています。
- 狐の例では、プロンプトに従い、元の動画にいた狐が猫として自然に描き換えられています。元の動画の雰囲気と調和しつつ、指示されたオブジェクトへの変更が行われています。
いずれの例でも、マスクされた領域の境界が周囲の映像と滑らかに繋がり、時間的なちらつきも少なく、高品質なインペインティングが実現できています。
当社の開発モデルは、ベースラインと比較して全ての指標で改善が見られ、より高精度かつ時間的に安定したインペインティングが可能になったことを示唆しています。
まとめと今後の展望
本GENIACプロジェクトを通じて、当社はユーザーの意図に沿った効率的な動画・画像生成を可能にするVision系基盤モデル(T2Vモデル、V2V Inpaintモデル)の開発を進め、一定の成果を得ることができました。特に、独自収集したロイヤリティフリー動画データセットの活用、ComfyUIやKubernetesを活用したデータ処理・学習パイプラインの効率化、SAM2やFlorence2といった最新AIモデルの導入によるアノテーション作業の自動化は、今後の基盤モデル開発を加速させる上で重要なノウハウとなると考えています。
開発した基盤モデルは、映像編集やコンテンツ制作といったクリエイティブ業務の効率化はもちろんのこと、製造業における外観検査シミュレーションデータの生成や、医療分野における希少疾患の画像データ拡張など、多岐にわたる分野での応用が期待されます。
成果物の公開について
本プロジェクトで開発した推論コードや学習済みモデルについては、以下のプラットフォームでの公開を予定しています。
- 推論コード: https://github.com/DATAGRID-Research-org/Open-Sora-Plan
- 学習済みモデル: https://huggingface.co/DATAGRID-research/DATAGRID-Open-Sora-Plan-v1.3.0-0.16M
これらの成果が、日本の生成AI開発コミュニティ全体の発展に少しでも貢献できれば幸いです。
Discussion