💡 はじめに
Data CloudはAgentforceのデータ基盤としてAgentがアクションを完成するために必要な企業の情報を提供する役割を果たしています。
本記事ではAgentを構成するRAGアーキテクチャの重要機能であるData CloudのベクトルDBを活用してAgentへ会話コンテキストともっとも関連性の高い情報を提供するアプローチを説明します。そして、その中でも柔軟性と実現難易度のバランスが一番すぐれたSalesforce Flow + Data Cloud Connect REST APIのqueryDataV1の組み合わせでData CloudのベクトルDBへ検索クエリーを投げて、Agentへ関連情報を提供する方法をハンズオン形式で説明します。
AgentアクションにおけるSalesforceフローの役割
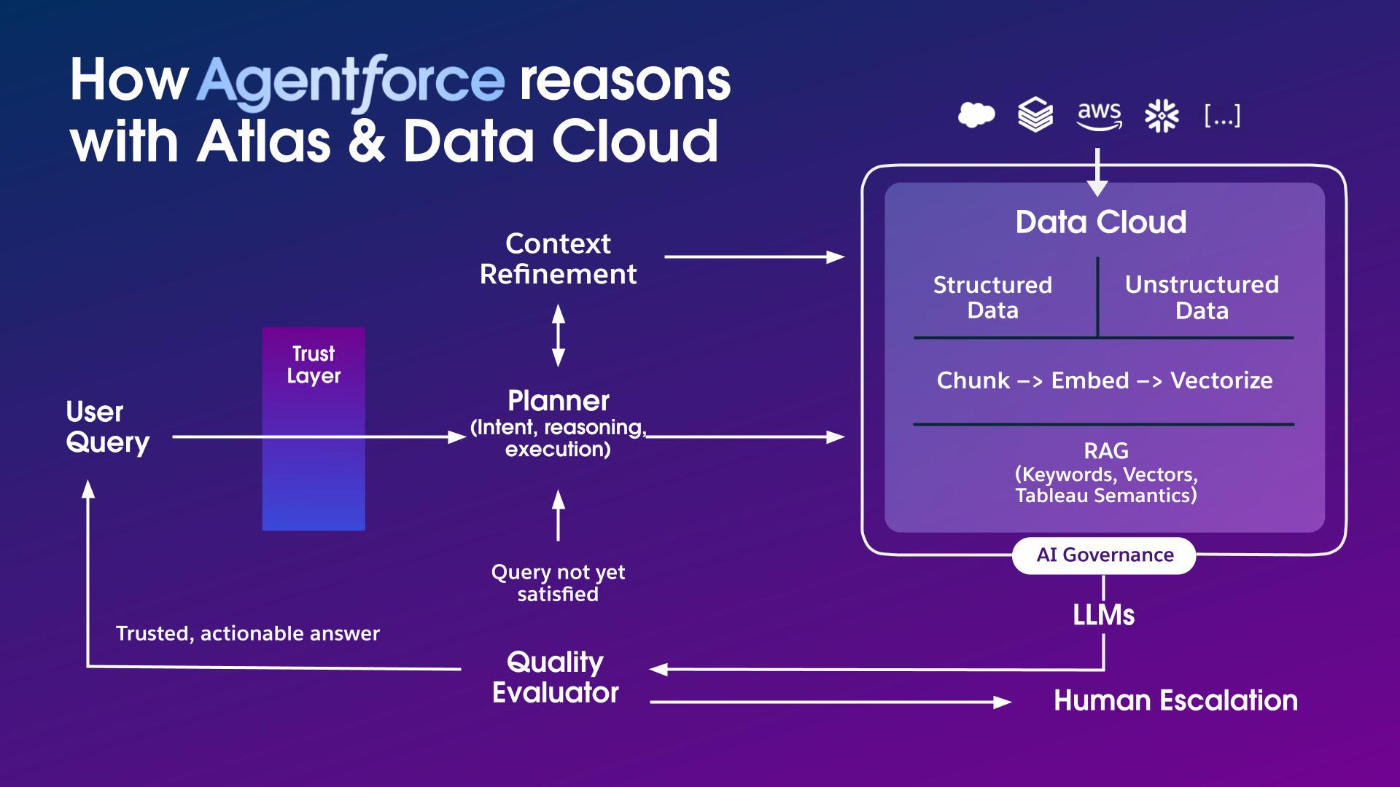
Agentforceではユーザーの意図をAtlas Reasoning Engineを利用して識別し、タスクを完成するためのアクション実行プランが作成されます。そして、Agentは各アクションの中でタスクを完成するために必要な情報を収集したり、業務ロジックとおりにデータを処理したり、結果のサマリを生成したりします。
AgentforceではAgentアクションを定義する際にApex、フロー、PromptTemplate、APIなどのツールから選ぶことができますが、その中でもノーコードで情報を収集できたり、業務ロジックを実行できるSalesforceフローを採用するケースが結構多いです。
Salesforceフローでベクトル検索を実現
Salesforceフローの強力な自動化機能とData CloudのAI機能を組み合わせることで、コードを書かずに高度なベクトル検索(類似性検索)を実装できます。SalesforceフローではSalesforceあるいはData Cloudのレコードを取得したり、ActionでData Cloudのレトリーバーを指定してベクトル検索を行うこともできますが、もう一つの選択肢としてHttpコールアウト機能を利用してData CloudのConnect REST APIを実行してベクトル検索を行うこともできます。このアプローチではレトリーバーで実現しずらい柔軟なSQLベースのデータ検索及び抽出を実現できるようになりますし、Hybrid検索時にさらにチューニングパラメータを渡してHybrid検索のランキングアルゴリズムを調整することができるようになります。
実現ユースケースの例
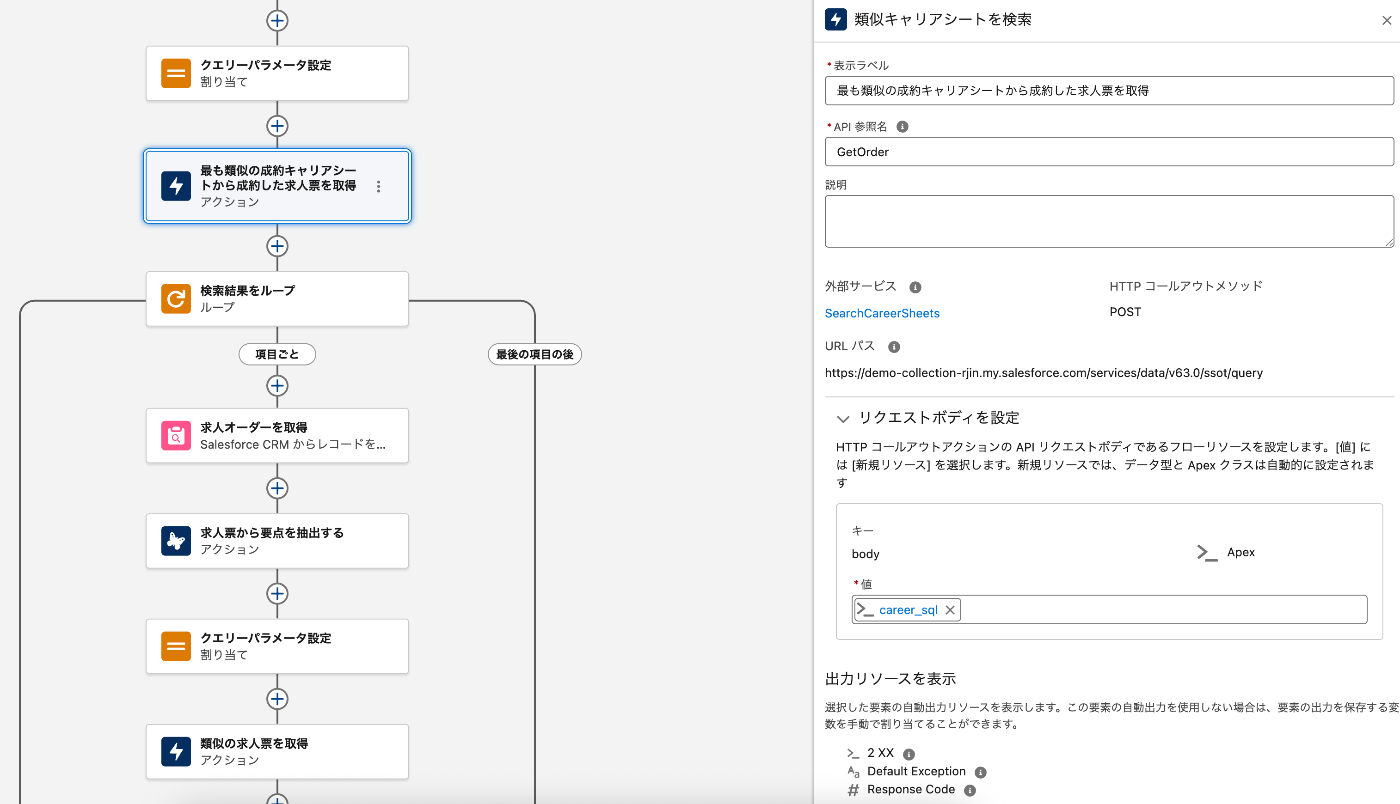
人材紹介の業務においてAgentにキャリアシートを渡しておすすめの求人オーダーを回答するAgentを構築する際に上記のようなフローベースのAgentアクションを用意して、入力したキャリアシートの情報を使ってData CloudのベクトルDBに対して検索クエリーを実行し、過去の成約事例から類似のキャリアを持つ人が成約していた求人情報を検索し、更にこの求人情報に類似している募集中の求人情報を検索することができます。
このアプローチのメリットはData CloudのベクトルDBとデータモデルを活用して一気に必要な情報までSQLで結合して取得できるところです。
ではどのように設定すればフローのHttpコールアウトアクションを利用してData Cloud Connect REST APIを実行してベクトル検索を実行できますか?
実現手順
Data Cloudへ接続するためのSalesforceで接続アプリケーションを作成
-
Data Cloud組織で、[設定]から[アプリケーション] >> [アプリケーションマネージャ]に移動します。
-
[新規接続アプリケーション]をクリックします。
-
以下の情報を入力します。
- 接続アプリケーション名: Data Cloud Connect REST API
- API参照名: Data_Cloud_Connect_REST_API
- 取引先責任者メール: システム管理者のメールアドレス
-
[OAuth設定の有効化]にチェックを入れると、追加の設定項目が表示されます。
-
[コールバックURL]にダミーのURLを設定する、この時点ではダミーのURLで構いません(例: https://localhost/callback)。
-
[選択したOAuth範囲]で、以下の項目を選択し、[追加]ボタンで右側のボックスに移動させます。
- Data Cloudデータに対して ANSI SQLクエリを実行(cdp_query_api)
- Data Cloudプロファイルデータを管理(cdp_profile_api)
- いつでも要求を実行(refresh_token、offline_access)
- APIを介してユーザデータを管理(api)
-
[保存]をクリックします。警告メッセージが表示された場合は、[続行]をクリックしてください。
- 保存後、作成した接続アプリケーションの詳細ページに自動的にリダイレクトされます。
- 作成された接続アプリケーションのページで [コンシューマの詳細を管理] をクリックし、表示される コンシューマキー (Client ID) と コンシューマシークレット (Client Secret) を安全な場所に控えておきます。
認証プロバイダの作成
次に、先ほど作成した接続アプリケーションを使って、SalesforceがData Cloudに認証するための設定を行います。
- [設定] > [クイック検索]で「認証プロバイダ」と入力し、選択します。
- [新規]をクリックします。
- プロバイダタイプで[Salesforce]を選択します。
- 以下の情報を入力します。
- 名前: Salesforceなど、わかりやすい名前を入力します。
- URL 接尾辞: 自動的に入力されます。
- コンシューマキー: ステップ1で控えたコンシューマキーを貼り付けます。
- コンシューマシークレット: ステップ1で控えたコンシューマシークレットを貼り付けます。
- 承認エンドポイントURL: (ご自身のSalesforce組織の[私のドメイン]のURLとSalesforceのデフォルトOAuth2.0の承認エンドポイントを利用)
例: https://abcd.my.salesforce.com/services/oauth2/authorize - トークンエンドポイントURL: (ご自身のSalesforce組織の[私のドメイン]のURLとSalesforceのデフォルトOAuth2.0のトークンエンドポイントを利用)
例: https://abcd.my.salesforce.com/services/oauth2/token - デフォルトの範囲:
api refresh_token cdp_profile_api cdp_query_apiと入力します。
- [保存]をクリックします。
- 保存後の画面下にあるコールバックURLをステップ1で作成した接続アプリケーションのコールバックURLへ設定して正しいコールバックURLに更新します。
指定ログイン情報を設定
この設定により、フローからAPIを呼び出す際に、Data CloudのエンドポイントURLや認証情報を直接記述する必要がなくなり、安全で管理しやすくなります。
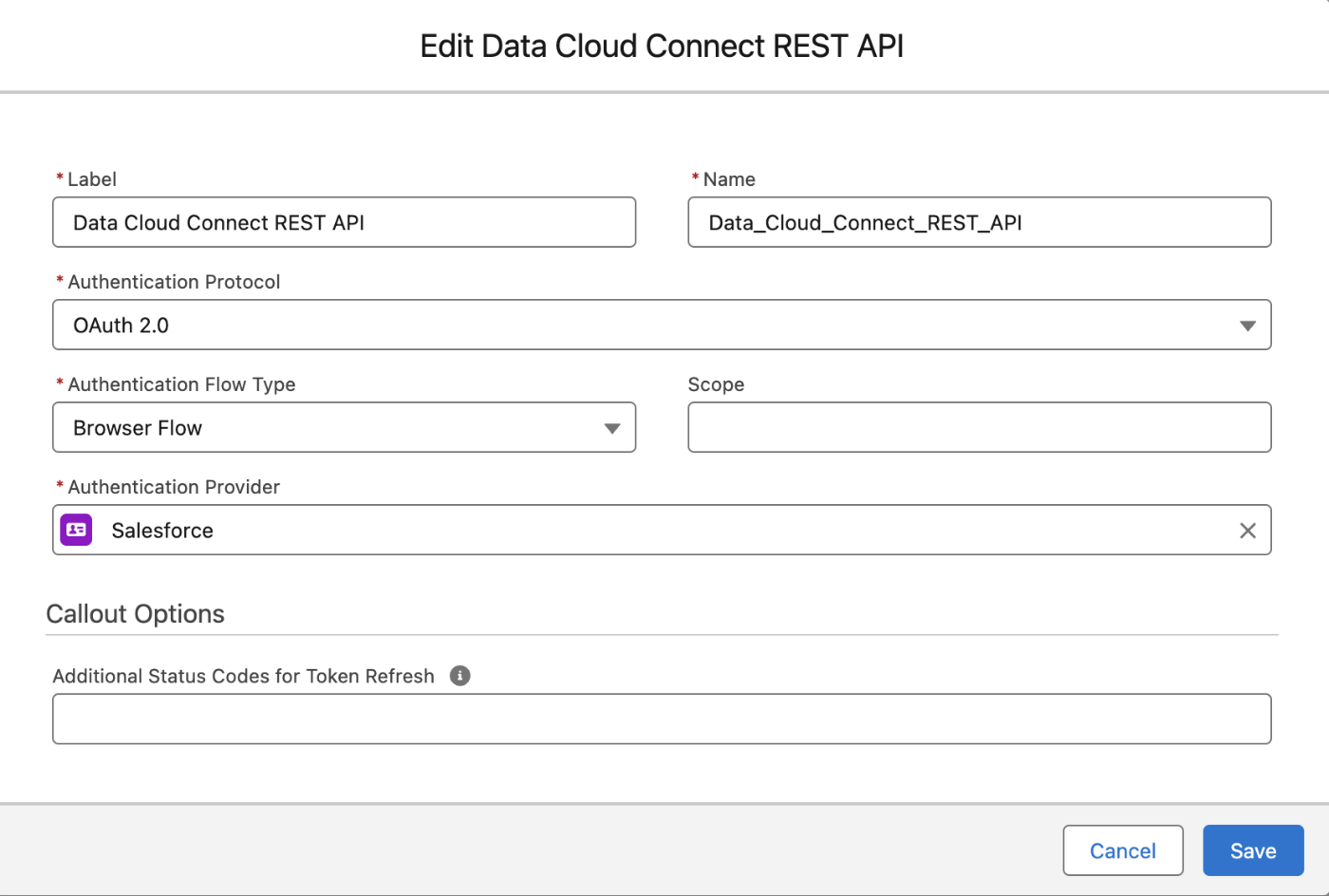
外部資格情報の作成
- [設定] > [クイック検索] で「指定ログイン情報」と入力し、選択します。
- [外部ログイン情報] タブを選択し、[新規] をクリックします。
- 以下の情報を入力します。
- 表示ラベル: Data_Cloud_Connect_REST_APIなどわかりやすい名前を入力します。
- 名前: 自動的に入力されます。
- 認証プロトコル: [OAuth 2.0]を選択します。
- 認証フロー種別: [ブラウザーフロー]を選択します。
- 範囲: 空白のままにする
- 認証プロバイダ: ステップ2で作成した認証プロバイダ(Salesforce)を選択します。
- [保存] をクリックします。
- 保存後、同じページ内を下にスクロールし、[プリンシパル]セクションを見つけます。
- [新規] をクリックします。
- 名前に「Salesforce_ext_cred_access」のような任意の値を入力します。
- ID種別は
指定ユーザを選択します。 - 範囲やシーケンス番号などの他の項目は、特に要件がなければデフォルト設定のままで構いません。
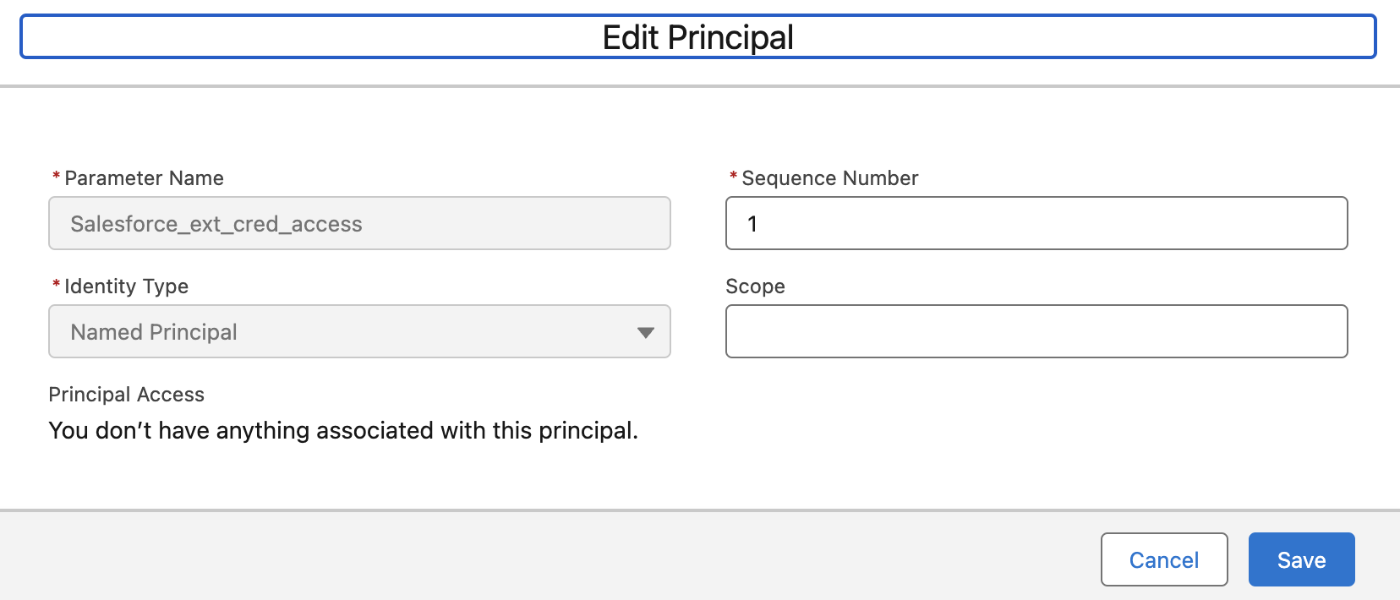
- [保存] をクリックします。
- [設定] > [ユーザ] > [権限セット] に移動し、[新規] をクリックします。
- 表示ラベルに「DC ORG 01 External Credential Access」のような任意の名前を入力し、[保存] をクリックします。(API 参照名は自動的に入力されます。)
- 権限セットの設定ページを下にスクロールし、
外部ログイン情報プリンシパルアクセスというセクションを見つけます。 - [編集] をクリックし、利用可能なプリンシパルの中から先ほど作成した「Salesforce_ext_cred_access」を選択して有効化し、[保存] をクリックします。
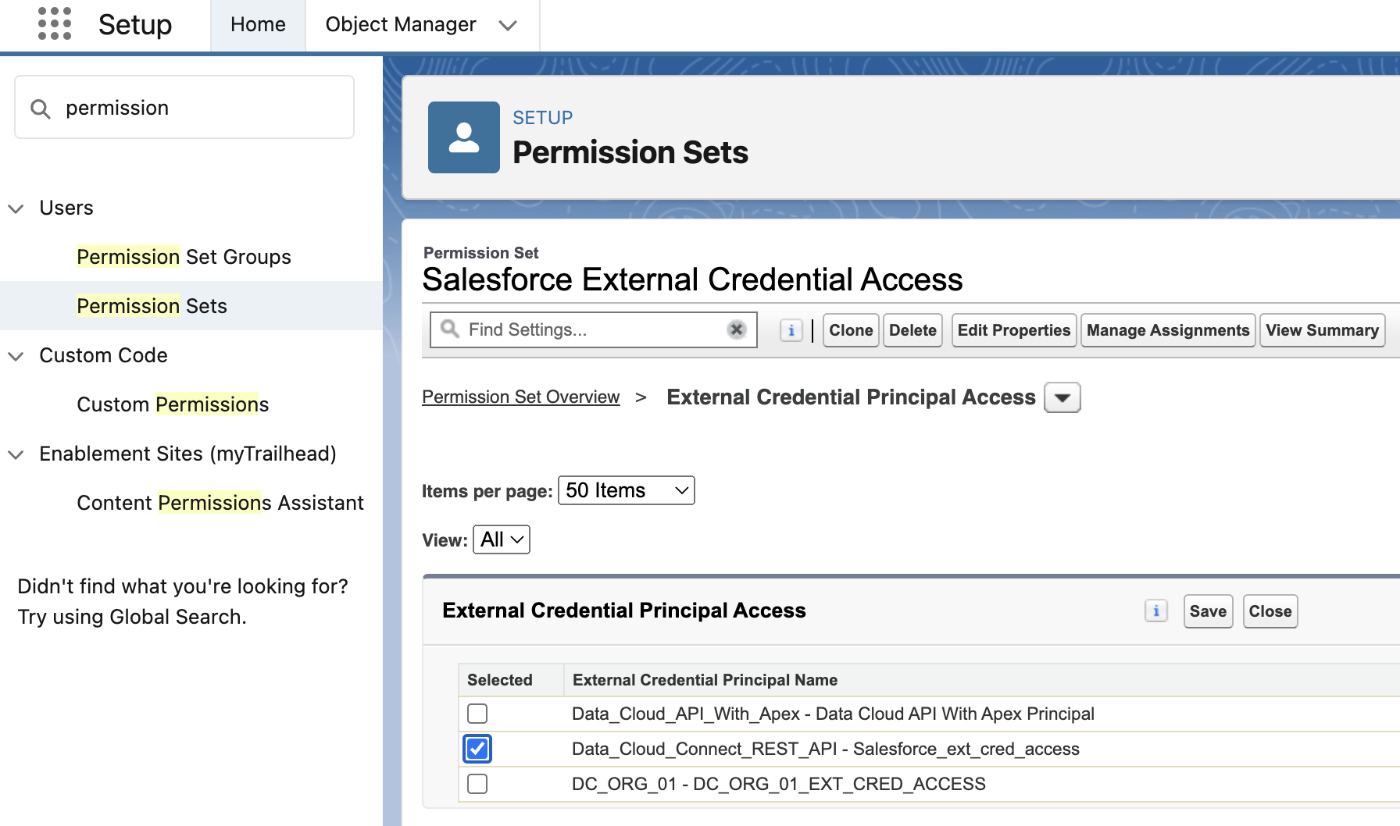
- 最後に、この権限セットをテストを行うユーザ(ほとんどの場合は現在ログインしているご自身のユーザ)に割り当てます。
- 外部資格情報のページに戻って7で作成したプリンシパルの[認証]を右側のメニューで行います。

- 正しく設定されていれば、ブラウザが起動され[許可]をおして認証済みに設定できます。
指定ログイン情報の作成
- [指定ログイン情報]タブに戻り、[新規]をクリックします。
- 以下の情報を入力します。
- 表示ラベル: Data_Cloud_Connect_REST_APIなどわかりやすい名前を入力します。
- 名前: 自動的に入力されます。
- URL: ご自身のSalesforce組織の[私のドメイン]のURLを入力します。形式は https://abcd.my.salesforce.com)です。
- 外部資格情報: 先ほど作成した外部資格情報(Data_Cloud_Connect_REST_API)を選択します。
- [保存]をクリックします。
フローの作成とHTTPコールアウトの設定
本記事ではテストのために、上記の高度な検索インデックス設定を利用せず、SalesforceのWinter25PDFをAgentforceデータライブラリに登録してRagFileUDMO_SI_index__dlmという自動に作成された検索インデックスを利用してSQLベースでセマンティック検索を実施できるフローを作成します。なお、POCや機能検証以外で検索インデックスを構築する場合、こちらの簡易設定ではなく、必ず高度な検索インデックス設定を利用してください。
では、いよいよData CloudのQuery APIをフローからノーコードで呼び出す準備が整えました。
次はフローを作成してHttpコールアウトアクションを定義します。Httpコールアウトを設定すると外部サービス及び外部サービスのIn/OutをキャプチャーできるApexクラスが自動で作成されます。
自動起動フローを作成
- 自動起動フローを新規作成して任意の名称で入力で使用可能なテキストタイプの変数を定義します。
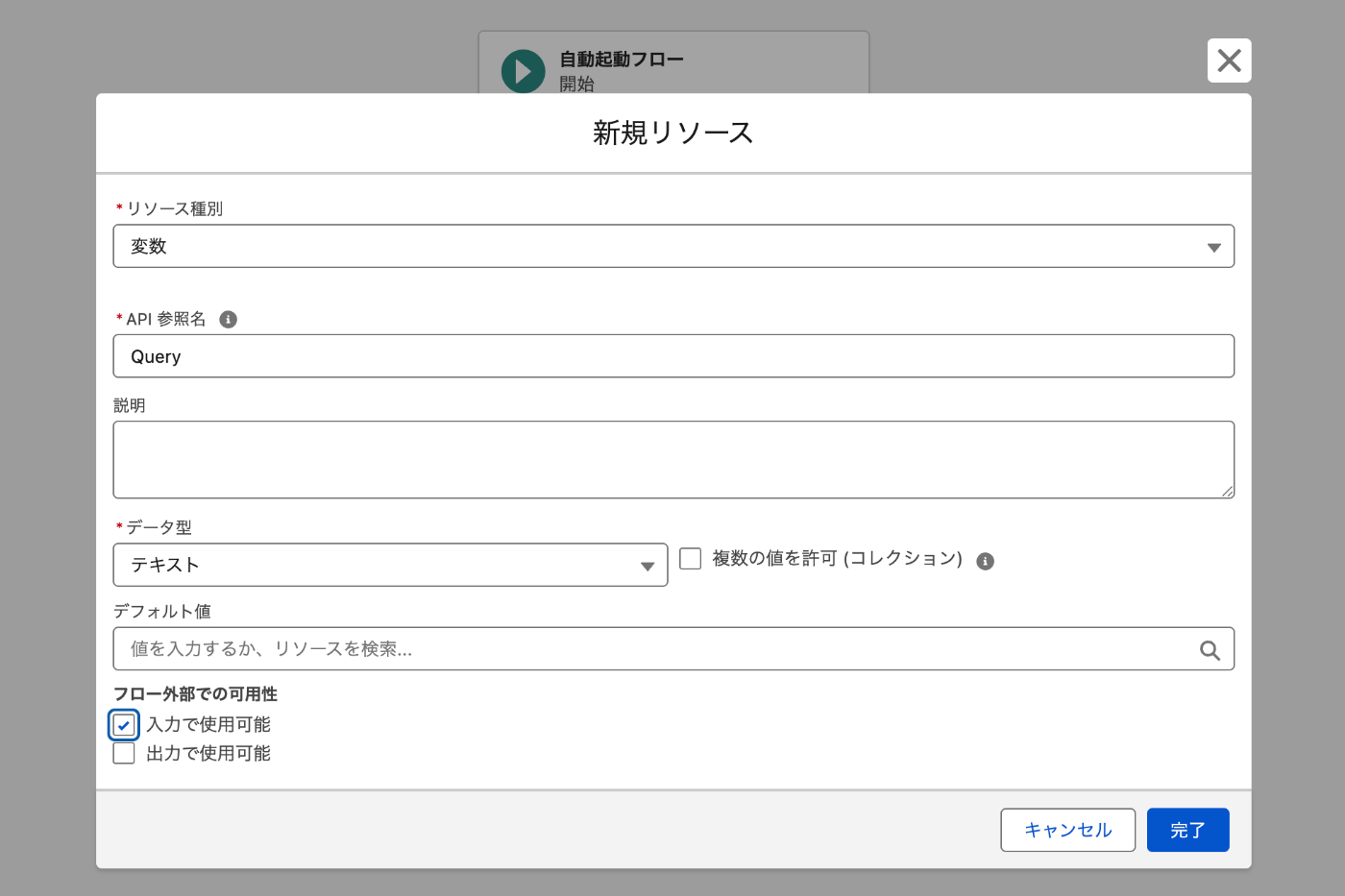
この入力用変数は将来Agentのアクションからユーザーからのクエリーが自動に設定されます。
例:ZoomInfoコネクタについて - SQLクエリーを構成するテキストテンプレート変数を新規作成し、事前にData Cloudのクエリーエディターでテスト済みのSQLを貼り付て、
hybrid_search関数に1で作成した入力用テキスト変数を組み込みます。
そして、テキストテンプレート変数を設定する際に必ずプレインテキスト入力モードでSQLを入力する必要があります。
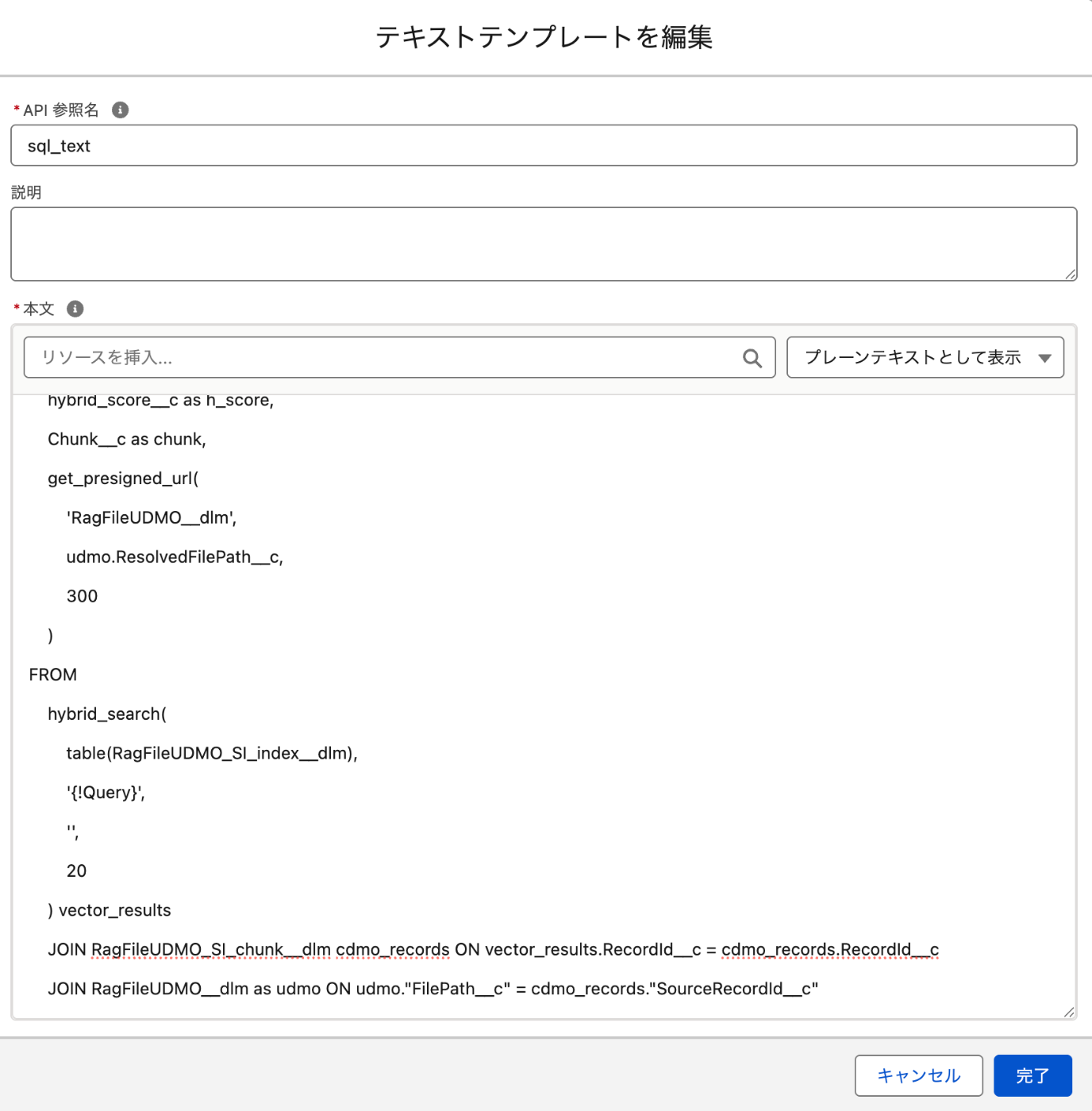
下記のサンプルSQLは検索時に各種類似スコアと関連するChunk内容、Agentforceデータライブラリで添付したPDFのURLを返すように定義しました。Data CloudのUDMOでリンクしたファイルはget_presigned_url関数を利用して一時的にアクセスできるURLを生成できます。
参考:Query Unstructured Data Using Query API
SELECT
keyword_score__c as key_score,
vector_score__c as v_score,
hybrid_score__c as h_score,
Chunk__c as chunk,
get_presigned_url(
'RagFileUDMO__dlm',
udmo.ResolvedFilePath__c,
300
)
FROM
hybrid_search(
table(RagFileUDMO_SI_index__dlm),
'{!Query}',
'',
20
) as vector_results
JOIN RagFileUDMO_SI_chunk__dlm as cdmo_records ON vector_results.RecordId__c = cdmo_records.RecordId__c
JOIN RagFileUDMO__dlm as udmo ON udmo.FilePath__c = cdmo_records.SourceRecordId__c
ORDER BY
h_score DESC;
- フローに新しいActionノードを追加し、Action選択欄の一番下にある
Httpコールアウトを作成をクリックしてHttpコールアウトを新規作成します。- 名前: 任意の名称を選択する。
- 指定ログイン情報: 前の手順の最後に作成した指定ログイン情報を選択する。
例:Data_Cloud_Connect_REST_API

- 次へを押す。
- 表示ラベル: 任意の名称を指定。
例:ナレッジ検索 - メソッド: POST
- URLパス:
/services/data/v64.0/ssot/query
Data Cloud Connect REST APIのqueryDataV1を利用するようにAPIのURLパスを設定します。 - 次へを押す。
- サンプルJson要求:前のテキストテンプレートに設定したSQLをリクエストBodyのフォーマットにあわせてJson形式で設定します。注意しないといけないのはSQLの中ではシングルクォーテーションのみ利用可能です。

下記は本設定で利用しているSQLのサンプルです。
{
"sql": "SELECT
keyword_score__c as key_score,
vector_score__c as v_score,
hybrid_score__c as h_score,
Chunk__c as chunk,
get_presigned_url(
'RagFileUDMO__dlm',
udmo.ResolvedFilePath__c,
300
)
FROM
hybrid_search(
table(RagFileUDMO_SI_index__dlm),
'{!Query}',
'',
20
) as vector_results
JOIN RagFileUDMO_SI_chunk__dlm as cdmo_records ON vector_results.RecordId__c = cdmo_records.RecordId__c
JOIN RagFileUDMO__dlm as udmo ON udmo.FilePath__c = cdmo_records.SourceRecordId__c
ORDER BY
h_score DESC;"
}
- 確認を押して、次へを押します。
確認ボタンを押すと赤いエラーIconが出ますが、そのまま次へへ進んで大丈夫です。 - スキーマ用に接続を選択して次へを押します。

- サンプル応答接続画面で、確認ポタンを押して実際にAPIからレスポンスを取得するようにします。そうすると自動にAPIのレスポンスをパースできるApexクラスが生成されます。

- 保存ボタンで設定を保存します。
- Actionノードの名称を任意に設定し、リクエストのキー項目で新規リソースを作成を選んで新規のApexタイプの変数を作成し、前で作成したSQLを格納したテキストテンプレートを後でアサインするようにします。

- Httpコールアウトのアクション前に割り当てノードを追加して、前で作成したSQLを格納したテキストテンプレートを上記のApexタイプの変数のsqlパラメータに設定します。

- この時点でフローを保存してDebugしてみましょう。任意のクエリーテキストを入れて検索アクションが成功に実行できることを確認できます。

- 検索結果の活用は要件次第ですが、フローをAgentのアクションから直接呼び出す場合は一旦検索結果をフローのプロンプトアクションに渡してプロンプトで結果を生成したほうが、回答の品質の向上に繋がります。あるいは下記のように結果をループして次の業務ロジックに組み込むこともできます。検索結果のJsonはApex変数によっていパースされて簡単に利用できるので、下記のようにdataパラメータに保持されているリストタイプの変数をループできます。

最後に
Agentへ品質の高いデータを提供することでより精度の高い回答が生成できるようになりますので、Data Cloudの機能とSalesforceのフローを組み合わせしてノーコードでありながら柔軟かつ力強いAgentアクションを実現できるようになります。

Discussion