初めに
Apache Sparkは、大規模なデータ処理を分散環境で効率的に行うためのフレームワークであり、Sparkでの処理を効率化するための機能の一つがpersist/キャッシュです。この記事では、Sparkの持つ機能の一つであるpersist/キャッシュについて、Spark初心者に向けて説明します。
概要や使い方について説明した後、実際に試した結果もご紹介します。
- 対象読者:Apache Spark初学者
- 前提知識:python、Sparkのアーキテクチャ
Sparkにおけるpersist/キャッシュとは
Sparkでは、基本的にRDDはアクションごとに毎回再計算されます。ファイルからデータを読込、トランスフォーメーションし、アクションの結果を返すという一連の動作がアクションを実行するたびに繰り返されます。
しかし、大きなデータを使う度に毎回ファイルから読み込んだり、何度も繰り返し参照するRDDを都度計算するのは、操作によっては非常に非効率的です。
そこで、SparkにはRDDをpersistすることで毎回計算しなくても再利用できるようにするpersistという機能があります。何度も使用するRDDをpersistすることで、RDDが複数回計算されることを防ぐことが出来ます。
例えば上の図(四角はRDDとする)のような場合、CをpersistすることでDを計算する場合でも、Eを計算する場合でも、Cの計算結果として保存されているキャッシュを使用することが出来、毎回ファイルからデータをロードする段階から計算をやり直す必要がなくなります。
persist/キャッシュの使い方
データのpersist:persist()
データのpersistを行う際に用います。オプションパラメータとしてストレージレベルが指定でき、指定した場所にデータが保存されます。
指定がない場合のストレージレベルのデフォルトはデータフレームでMEMORY_AND_DISK_DESER、RDDではMEMORY_ONLYです。
つまり、データフレームに対してストレージレベルを指定せずにpersistを行った場合、キャッシュはまずメモリに保存されていき、メモリに収まらないデータはディスクに書き出されます。RDDに対するpersistをストレージレベルの指定なしで行った場合、キャッシュはメモリのみに保存され、収まらなかった分は次回使われる際にも再計算されます。(_DESERはデシリアライズを意味します。ただし、Pythonではデータは常にシリアライズされます。)
注意点: persist()や後述するcache()はアクションではなく、他のトランスフォーメーションの操作同様に遅延評価されます。persist()を実行したとしても、実際にメモリやディスクにデータが保存されるのは該当のRDDを使ってアクションが実行されるときです。
キャッシュの作成:cache()
こちらもデータのキャッシュを作成する際に使用します。上記のpersist()と似ていますが、cache()ではストレージレベルの指定はできません。
ストレージレベルは固定で、persist()のデフォルトと同じくデータフレームでMEMORY_AND_DISK_DESER、RDDではMEMORY_ONLYです。
persist/キャッシュの確認方法
Spark UIのStorage
DatabricksのNotebookでSparkを実行した場合、以下のような手順でキャッシュされたRDDを確認できます。
- Databricksの左側のツールバーでクラスターを選択します。
- クラスター一覧からNotebookで使用しているクラスター名をクリックします。
- Spark UI→Storageと進みます。
- キャッシュとして保存されたデータがRDDsとして画面に表示されます。
Notebookでのコマンド実行
RDD/データフレーム名.is_cachedを実行することで、そのRDD/データフレームがpersistされているか確かめることが出来ます。
キャッシュの削除:unpersist()
RDD/データフレームのpersistを解除し、メモリおよびディスク上に保存していた該当RDD/データフレームのキャッシュデータを削除します。persistする際に用いたのがpersist()の場合でもcache()の場合でも使用可能です。
実践編
今回は、Databricksを使用して実施した、RDDおよびデータフレームのpersistの方法をご紹介します。言語はPythonを使用しています。
作業手順
使用したデータ
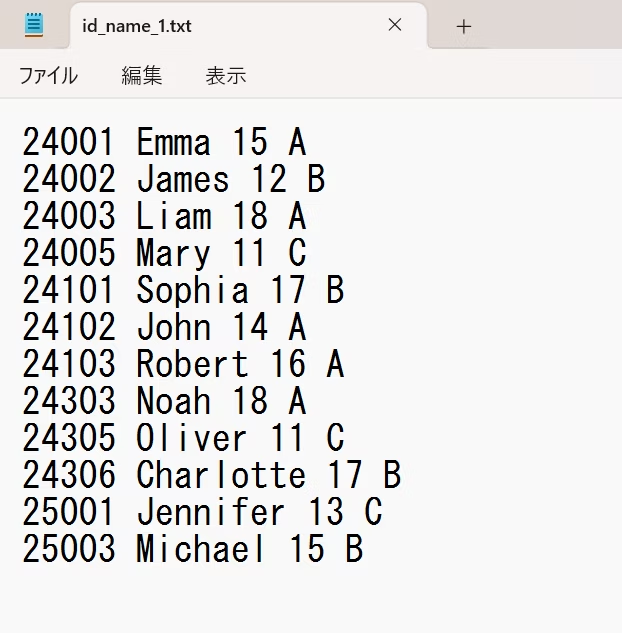
今回は、上図のような簡易的な名簿を模したようなスペース区切りのテキストファイルをDatabricksのGUIを用いてHDFS上にアップロードして使用しました。
また、データフレームでのキャッシュの作成には、下図のような、同様のデータをCSVファイルで作成したものも用いています。

データ準備
test_rdd_1 = sc.textFile("dbfs:/FileStore/tables/id_name_1.txt")
test_rdd_2 = sc.textFile("dbfs:/FileStore/tables/id_name_2.txt")
test_rdd_3 = test_rdd_1.union(test_rdd_2)
test_rdd_4 = test_rdd_3.map(lambda value: value.split(" "))
test_rdd_cached = test_rdd_4.filter(lambda value: "24" in value[0])
HDFS上のファイルを読込み、RDDを操作してデータを成形します。今回はデータのソースとして、HDFS上にアップロードした、テキストファイルを使用しました。
RDDの連結やデータの絞り込みなどの操作を行い、永続化したいRDDを作成します。
ここでは、二つのファイルを読み込んで、連結、各レコードへの関数の適用と絞り込み、という操作を行っています。この操作で、ソースファイル二つ分のデータを、レコードごとにスペースで区切った配列に変更し、配列の一つ目の要素に「24」を含むレコードのみに絞り込んだRDDを作成しました。
RDDのpersistを実行する
test_rdd_cached.persist()
test_rdd_cached.collect()
RDDを永続化し、永続化したRDDでアクションを実行します。アクションの実行で、計算された結果はメモリに保存されます。
作成されたキャッシュの確認
Spark UI
キャッシュが作成されると、下図のように、Spark UIのStorageのページでRDDsとして表示されます。

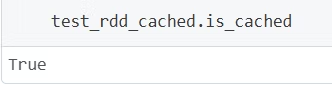
is_cachedの実行
RDD名.is_cachedを実行することでも、RDDの永続化を確認することが出来ます。
キャッシュの削除
test_rdd_cached.unpersist()
persistの解除、キャッシュの消去を行います。
データフレームでpersistを実行する
続いて、データフレームでも同様に永続化を行ってみます。
test_df_1 = spark.createDataFrame(test_rdd_cached, ['id','name','age','team'])
test_df_2 = spark.read.csv("dbfs:/FileStore/tables/id_name_3.csv", header=True, inferSchema=True)
test_df_3 = test_df_1.union(test_df_2)
test_df_3.persist()
test_df_3.count()
先ほど作成したRDDからデータフレームを作成。ファイルから読み込んだデータと連結して、永続化しました。

使ってみて確認できたこと
ストレージレベルのデフォルト
persistをストレージレベルを指定しないで実施した際には、persistしたのがRDDかデータフレームかで設定されるストレージレベルが異なる様子を実際に観察できました。
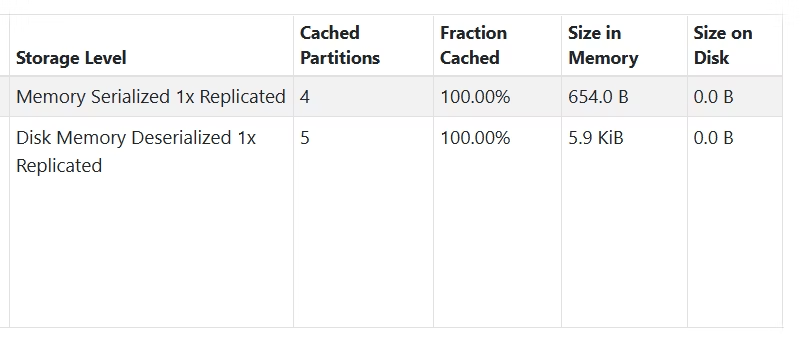
図の上段がRDDのキャッシュ、下段がDFのキャッシュです。ストレージレベルの指定なしでのストレージレベルのデフォルトが違うことが確認できます。
今回はデータ量が多くなかったため、デフォルトでMEMORY_AND_DISK_DESERに設定されるデータフレームについても、実際にデータが書き込まれたのはメモリのみでした。
persistの遅延評価
persistを実行してもそのタイミングで実際に計算結果が保存されるわけではなく、その後該当のRDDやデータフレームにアクションを実行した際にデータが保存される様子を観察できました。一方、isCachedではデータがキャッシュがストレージに保存される前でも、persistを実行していればTrueが返ってくることもわかりました。
また、persist()と違い、unpersist()は実行するとすぐにpark UIのStorageからキャッシュされたRDDが消えることが確認できました
終わりに
本記事では、Sparkのpersist/キャッシュに初めて触れる方に向け、persist/キャッシュ機能の使い方の説明と簡単な実践を行いました。
以下の関連記事セクションに記載の記事でも、Spark初心者向けに、機能を使用してみた情報が紹介されています。気になった方は是非ご覧ください。
参考文献
Sparkの公式ドキュメント:https://spark.apache.org/docs/latest/api/python/reference/index.html
Holden Karau、Andy Konwinski、Patrick Wendell、Matei Zaharia 著、Sky株式会社 玉川竜司 訳. 初めてのSpark. オライリー・ジャパン, 2015.
関連記事
Discussion