初めに:Entity Resolutionとは
Entity Resolutionは、異なるデータセットや同一データセット内で、同一の実体を指す複数のレコードを識別し、統合するプロセスを指します。
データの入力ミスや、表記ゆれ、複数の情報源からの統合などにより、同じ対象を指しているにもかかわらず、異なるレコードとして扱われることがあります。Entity Resolutionでは、こうした同一人物や同一商品など、実際には同じ対象を指す複数のレコードを正確に結びつけることで、データの一貫性と正確性を保ちます。
本記事では、Entity Resolutionの代表的な手法について、部品の表記ゆれやサプライヤー情報の重複、異なるシステム間でのデータ統合など、Entity Resolutionが必要とされる場面が多く想定できる製造業のデータ(部品表、顧客情報など)を例として入力・出力データの例を交えながら説明します。
対象読者:データクレンジングやEntity Resolution、名寄せに興味がある方
Entity Resolutionの代表的な手法
ルールベース
ルールベースのEntity Resolutionとは、あらかじめ定義した条件(ルール)に従って、レコード同士が同一のエンティティかどうかを判断する手法です。ルールには、単純なIDの完全一致だけでなく、部分一致や、後述するような類似度スコアの閾値と組み合わせた複雑な条件を含めることも可能です。
ルールベースのEntity Resolutionでは、どのルールでレコードが一致したかが明確で、さらに、単純なルールの場合には実装がシンプルで複雑な計算が不要です。一方で、データが増えるとルールが複雑化し保守が困難になる可能性がある、完全一致などのルールではタイポや表記揺れに弱く曖昧な一致に対応できない、などのデメリットがあります。
ルールが明確な場合や、法規制対応などで「なぜ一致したか」を説明する必要がある場合に適しています。
実践例:部品IDによるルールベースのEntity Resolution
ここでは、製造業の部品管理を例に、部品ID(部品コード)が同じレコードが同一エンティティを指すM-BOM(製造部品表)とE-BOM(設計部品表)、組み立て工程検査表の間で、同一部品を識別するルールベースのEntity Resolutionを行います。
E-BOM
| 部品ID | 部品名 |
|---|---|
| TC-L15P | TechCraft Pro 15 |
| MB-L15-01 | マザーボードAssy |
| CPU-12700H | インテル Core i7-12700H |
M-BOM
| 部品ID | 部品名 |
|---|---|
| MB-L15-01 | マザーボードAssy |
| CPU-12700H | Core i7-12700H |
| WIFI-AX211 | Wi-Fi 6Eモジュール |
| DP-15.6-4K | ディスプレイパネル |
組み立て工程検査表
| 項目 | 部品コード | 部品名称 |
|---|---|---|
| 1 | MB-L15-01 | マザーボードベース |
| 2 | RAM-32GB | DDR5-4800 32GB |
| 3 | WIFI-AX211 | Wi-Fi 6Eモジュール |
部品ID(部品コード)が同じものを同一エンティティとして統合します。
結果:統合済みエンティティ一覧
| Entity_id | 部品ID | 部品名 | records |
|---|---|---|---|
| 1 | TC-L15P | TechCraft Pro 15 | E-BOM_TC-L15P |
| 2 | MB-L15-01 | マザーボードAssy | E-BOM_MB-L15-01, M-BOM_MB-L15-01, 検査表_1 |
| 3 | CPU-12700H | インテル Core i7-12700H | E-BOM_CPU-12700H, M-BOM_CPU-12700H |
| 4 | WIFI-AX211 | Wi-Fi 6Eモジュール | M-BOM_WIFI-AX211, 検査表_3 |
| 5 | DP-15.6-4K | ディスプレイパネル | M-BOM_DP-15.6-4K |
| 6 | RAM-32GB | DDR5-4800 32GB | 検査表_2 |
E-BOMの2行目とM-BOMの1行目、組み立て工程検査表の1行目など、IDが一致する組み合わせが同一エンティティとして統合済みエンティティ一覧では一レコードとして記録されます。
recordsカラムは、Entity Resolutionの結果として統合されたレコード群を示します。同一と判定された複数のレコードが、どのデータソースのどの行に由来するかを記録することで、統合済みエンティティの構成要素を追跡可能にしています。
類似度スコア
同一エンティティかどうかを、文字列などの類似度を数値化して評価する手法です。
完全一致ではなく、「どれくらい似ているか」を測ることで、タイポや表記揺れにも対応できます。しかし、閾値の調整が必要で、類似度スコアの算出法によっては計算コストが高くなります。
類似度の評価にはさまざまな手法があり、それぞれに特徴と適した用途があります。ここでは代表的な3つの手法を紹介します。
Levenshtein距離(編集距離)
2つの文字列を一致させるために必要な「挿入・削除・置換」の最小操作回数を求めて文字列の類似度を評価する方法です。距離が小さいほど類似度が高い、という評価です。
タイポやスペルミスに強く、文字列の部分的な一致を捉えることができます。長い文字列では計算コストが高くなります。
実践例:スペルミス等を含む、名前とメールアドレスによるEntity Resolution
製造業のカスタマーサポートを例に、顧客名簿と問い合わせ記録の間で、同一人物を識別するLevenshtein距離を用いたEntity Resolutionを行います。Levenshtein距離を用いることで、ローマ字の表記ゆれやスペルミスに柔軟に対応することが出来ます。
顧客名簿
| RECORD_ID | 氏名 | メールアドレス |
|---|---|---|
| 1 | YAMADA Taro | taro.yamada@example.com |
問い合わせ記録
| RECORD_ID | 氏名 | メールアドレス |
|---|---|---|
| 1 | Yamada Tarou | tarp.yamada@example.com |
| 2 | Yamada Hanako | hanako.yamada@example.com |
| 3 | YAMADA Taro | yamada.tech@example.jp |
氏名とメールアドレスについてそれぞれ大文字に統一したうえでLevenshtein距離を求め、以下の式で類似度を算出します。ここでは、氏名およびメールアドレスの類似度がともに0.9以上の場合、同一人物であるとします。
例えば、「YAMADA Taro」と「Yamada Hanako」の比較では、名字部分については大文字化後同一であるので一致するまでの操作は0回であり、TAROとHANAKOについて、T→H、R→N、Aの挿入、Kの挿入の4回の操作で一致することから、Levenshtein距離は0+4=4となります。比較する2つの文字列のうち長い方の文字列の長さは「Yamada Hanako」の13であることから、類似度は1-(4/13)≒0.692となります。
結果:類似度評価結果
| RECORD_ID | レコード1 | レコード2 | 氏名の類似度 | メールアドレスの類似度 | is_match |
|---|---|---|---|---|---|
| 1 | 問い合わせ記録_1 | 顧客名簿_1 | 0.917 | 0.917 | True |
| 2 | 問い合わせ記録_2 | 顧客名簿_1 | 0.692 | 0.840 | False |
| 3 | 問い合わせ記録_3 | 顧客名簿_1 | 1.000 | 0.417 | False |
結果:統合済みエンティティ一覧
| Entity_id | 氏名 | メールアドレス | records |
|---|---|---|---|
| 1 | YamadaTaro | Taro.Yamada@example.com | 問い合わせ記録_1,顧客名簿_1 |
| 2 | YamadaHanako | hanako.yamada@example.com | 問い合わせ記録_2 |
| 3 | YAMADATaro | yamada.tech@example.jp | 問い合わせ記録_3 |
ペア比較結果は、Entity Resolutionの過程で行われたレコード間の類似度評価の詳細を示しています。
Jaccard係数
2つの集合の共通部分の割合から類似度を評価する方法です。カテゴリカルな属性や複数の要素を持つデータに適しています。
集合の重複度を直感的に評価できますが、差集合が多いとスコアが下がりやすく、集合の要素の並び順や要素内の部分的な一致(例:"apple" と "pineapple")は考慮しません。
実践例:異なる形式のデータによるEntity Resolution
製造業の部品在庫管理を例に、製品名や規格、材質等が異なる形式で格納されている在庫管理システムと購買明細の間で、同一製品を識別するルールベースのEntity Resolutionを行います。
在庫管理システム
| RECORD_ID | 製品名 | 型番 | 材質 | 製造者 |
|---|---|---|---|---|
| 1 | 六角ボルト | M6×55-JP | ステンレス | ABC工業 |
購買明細
| RECORD_ID | 製品名 | 品番 | 製造者 |
|---|---|---|---|
| 1 | 六角ボルト 半ねじ(ステンレス) | M6×55 | ABC工業 |
| 2 | 六角ボルト 半ねじ(鉄/ドブ) | 12×55 | ABC工業 |
製品名、型番、材質、製造者(製品名、品番、製造者)をスペース、ハイフン、括弧(全角・半角)で分割してトークン化し、Jaccard係数を算出します。ここでは、Jaccard係数が0.6以上の場合、同一製品であるとします。
例えば、トークン化により、在庫管理システムのRECORD_ID:1のレコードでは、['六角ボルト', 'M6×55', 'JP', 'ステンレス', 'ABC工業']、購買明細のRECORD_ID:1のレコードでは、['六角ボルト', '半ねじ', 'ステンレス', 'M6×55', 'ABC工業']という集合が作成されます。
共有の要素は['六角ボルト', 'ステンレス', 'M6×55', 'ABC工業']、共通しない要素は['半ねじ', 'JP']であるため、Jaccard係数は共通部分の要素数/和集合の要素数 = 4/6 ≒ 0.67となります。
結果:類似度評価結果
| RECORD_ID | レコード1 | レコード2 | 類似度 | is_match |
|---|---|---|---|---|
| 1 | 在庫管理システム_1 | 購買明細_1 | 0.667 | True |
| 2 | 在庫管理システム_1 | 購買明細_2 | 0.125 | False |
結果:統合済みエンティティ一覧
| Entity_id | 製品名 | 型番 | 製造者 | records |
|---|---|---|---|---|
| 1 | 六角ボルト | M6×55-JP | ABC工業 | 在庫管理システム_1, 購買明細_1 |
| 2 | 六角ボルト 半ねじ(鉄/ドブ) | 12×55 | ABC工業 | 購買明細_2 |
Cosine類似度
2つのベクトル間の角度のコサイン値を用いた類似度の計算手法です。例えば、評価対象の文字列をEmbeddingによってベクトル化し、2つのベクトル間の角度のコサイン値で類似度を評価するような方法です。ベクトルの大きさではなく、方向性のみに着目するため、文書の長さや単語数の違いに影響されにくいというメリットがあります。一方で、絶対的な値の大きさ違いが重要な意味を持つデータには適しません。
Cosine類似度は、Embeddingのような意味ベースのベクトルのほか、ベクトル化の手法としてTF-IDF(Term Frequency - Inverse Document Frequency)を用いて使われることもあります。TF-IDFは、単語の出現頻度と、逆文書頻度(多くの文書に登場するか、特定の文書にのみ出現するか)を用いて重要な単語を計算する手法です。
実践例:多言語製品データのEntity Resolution
ここでは、製造業の部品管理を例に、異なる言語で記載されているM-BOM(製造部品表)と購買明細の間で、多言語のテキスト埋め込み用のモデルでベクトル化を行い同一部品を識別するCosine類似度によるEntity Resolutionを行います。
M-BOM
| 部品ID | 部品名 | 調達先 |
|---|---|---|
| MB-L15-01 | マザーボードAssy | TechComp株式会社 |
| CPU-12700H | Core i7-12700H | Intel Corp. |
| WIFI-AX211 | Wi-Fi 6Eモジュール | NetComp Inc. |
| DP-15.6-4K | ディスプレイパネル | ディスプレイテック株式会社 |
購買明細_英語
| RECORD_ID | Product number | Product name | Manufacturer |
|---|---|---|---|
| 1 | DP-15.6 | 15.6-inch 4K IPS Display Panel | DISPLAYTECH, INC |
| 2 | WIFI-AX211 | Wi-Fi 6E module | NetComp |
部品ID、部品名、調達先(Productnumber、Productname、Manufacturer)をスペース区切りで一つの文字列に結合し、多言語のテキスト埋め込み用のモデルであるmultilingual-e5-largeでベクトル化します。
Cosine類似度を計算し、ここでは類似度が0.9以上でマッチとします。
結果:類似度評価結果
| RECORD_ID | レコード1 | レコード2 | 類似度 | is_match |
|---|---|---|---|---|
| 1 | M-BOM_MB-L15-01 | 購買明細_英語_1 | 0.806 | False |
| 2 | M-BOM_MB-L15-01 | 購買明細_英語_2 | 0.825 | False |
| 3 | M-BOM_CPU-12700H | 購買明細_英語_1 | 0.793 | False |
| 4 | M-BOM_CPU-12700H | 購買明細_英語_2 | 0.796 | False |
| 5 | M-BOM_WIFI-AX211 | 購買明細_英語_1 | 0.779 | False |
| 6 | M-BOM_WIFI-AX211 | 購買明細_英語_2 | 0.962 | True |
| 7 | M-BOM_DP-15.6-4K | 購買明細_英語_1 | 0.905 | True |
| 8 | M-BOM_DP-15.6-4K | 購買明細_英語_2 | 0.794 | False |
結果:統合済みエンティティ一覧
| Entity_id | 部品名 | 部品ID | 調達先 | records |
|---|---|---|---|---|
| 1 | Wi-Fi 6Eモジュール | WIFI-AX211 | NetComp Inc. | M-BOM_WIFI-AX211, 購買明細_英語_2 |
| 2 | ディスプレイパネル | DP-15.6-4K | ディスプレイテック株式会社 | M-BOM_DP-15.6-4K, 購買明細_英語_1 |
| 3 | マザーボードAssy | MB-L15-01 | TechComp株式会社 | M-BOM_MB-L15-01 |
| 4 | Core i7-12700H | CPU-12700H | Intel Corp. | M-BOM_CPU-12700H |
グラフベース
エンティティ間の関係性をノードとエッジで表現するグラフDBを使用し、パターンを探索する手法です。
エンティティ間の関係性を活用でき、直接的な一致がなくても、ネットワーク構造の類似性から同一性を推定することが可能です。ただし、使用するにはグラフ構造を構築する必要があります。
グラフアルゴリズム
ノード(点)とエッジ(線)で構成されるグラフ構造でデータを格納するグラフデータベースを用いて、ノード間の類似度のペアごとの算出(Node Similarity)や、エッジを通じてつながる範囲を抽出し、それぞれの接続コンポーネントをクラスタとして識別するコミュニティ検出アルゴリズム(Weakly Connected Components(WCC))を用いる手法です。たとえば、Node Similarity によって類似度スコアが高いノード同士をエッジでつなぎ、そのグラフにWCCを適用することで、同一エンティティと推定されるノード群(マッチグループ)を抽出できます。
ノードのつながりを考慮してEntity Resolutionを行うことが出来、直接的な一致がなくても、ネットワーク構造の類似性から同一性を推定できます。また、関係性を視覚的に把握できます。
一方で、グラフ構造を構築する必要があり、エッジの重み付けが精度に大きく影響する、類似度スコアの設計の難易度が高いといったデメリットがあります。
実践例:グラフデータベースでのノードのつながりを使用したEntity Resolution
製造者と製造部品、グループ等のノードとその間の関連を示すエッジが格納されたグラフデータベースにおいて、グラフ上の関係性をもとに同一製造者を推定します。ここでは、Neo4j Graph Data Science(GDS)ライブラリのNode Similarityを使用して、隣接ノード集合のJaccard類似度を計算し類似度スコアが高いノード同士をエッジでつなぎます。
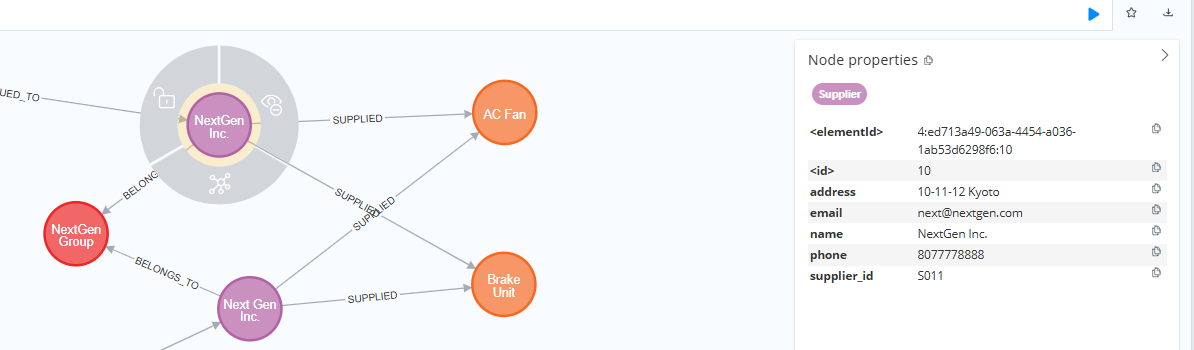
Supplierノード間で、指定したリレーションでつながる隣接ノード集合の類似度(Jaccard類似度)を計算し、類似度が 0.6 以上のペアに POTENTIAL_MATCH リレーションを作成します。

埋め込み+機械学習ベース
ノードの接続関係をNode2Vecなどで自動的にベクトル化(埋め込み)して特徴量を作成し、2つのノード間にリンクが存在するか予測(リンク予測)することで関係性を含む複雑な構造を学習させます。この方法では、既知のリンク情報を学習し、未知のリンク(潜在的な関係)を予測可能です。一方で、ベクトル化やベクトル学習に時間やコストがかかり、教師データが必要となります。
機械学習ベース
機械学習を用いたEntity Resolutionでは、ルールを人手で定義するのではなく、データから自動的にパターンを学習して、同一エンティティかどうかを判定します。例えば、特徴量(例:名前の類似度、住所の一致率、電話番号の一致など)を使って、分類モデル(ロジスティック回帰、ランダムフォレストなど)を学習させる教師あり学習のアプローチが一般的です。
機械学習を用いたEntity Resolutionのメリットは、複数の属性を総合的に評価できる点と、曖昧な一致にも柔軟に対応できる点です。一方で、デメリットとして、手法やモデルによっては説明性が低くなることもあること、また、教師あり学習のアプローチを用いた場合には良質な教師データ(正解ラベル付きのマッチ・ノンマッチペア)が必要であることなどがあげられます。
分類モデルの一例として、ロジスティック回帰は、一連の特徴量から、値が特定のカテゴリに属する確率を予測し、確率が閾値を超えるかどうかでマッチ/ノンマッチを判定する手法です。ロジスティック回帰は、他の複雑な機械学習モデルに比べて軽量で、実装やトレーニングが容易という利点があります。一方で、外れ値の影響を受けやすく、非線形な関係を捉えるのが難しいという制約もあります。
まとめ
Entity Resolutionには様々な手法があり、使用するデータの特徴や目的に合わせて適切な手法を選択することが非常に重要です。
さらに、どの手法を選ぶかだけでなく、実行時の効率性も重要な観点です。特に、大規模なデータセットでEntity Resolutionをする際などには、すべてのレコードペアを比較すると計算量が膨大になるため、比較対象をあらかじめ絞り込む処理が重要です。これを「ブロッキング」と呼びます。
例えば、郵便番号や製品カテゴリなどの属性が一致するレコード同士だけを比較対象にすることで、計算コストを大幅に削減できます。
以下に、本記事で取り上げたEntity Resolution手法を比較した表を示します。各手法の特徴、処理内容、メリット・デメリット、そして製造業を想定した具体的な適用例をまとめています。
| 手法 | ルールベース | 類似度スコア | グラフベース | 機械学習ベース | |||
|---|---|---|---|---|---|---|---|
| 代表的な指標・技術 | 完全一致、部分一致 | Levenshtein距離 | Jaccard係数 | Cosine類似度 | グラフアルゴリズム | グラフ埋め込み+機械学習 | ロジスティック回帰 |
| 処理 | あらかじめ定義されたルール(条件)に基づいて、同一のエンティティかどうかを判断。 | 2つの文字列を一致させるために必要な操作の最小操作回数を算出。 | 2つの集合の共通部分の割合を算出。 | 2つのベクトル間の角度のコサイン値を用いて類似度を計算。 | ノード間の類似度のペアごとの計算や、接続コンポーネントの特定。 | ノードの接続関係をベクトル化(埋め込み)して特徴量を作成し、ノード間のリンクを予測。 | 特徴量を使って類似性を学習し、カテゴリに属する確率を予測。 |
| メリット | どのルールで一致したかが明確。明確な一致ルールがある場合に有効。 | タイポやスペルミスに強い。部分的な一致を捉えることができる。 | 集合の重複度を直感的に評価できる。 | ベクトルの方向性のみに着目するため文の長さや単語数に影響されにくい。 | ノードのつながりを考慮出来る。関係性を視覚的に把握できる。 | 手動で特徴量を設計する必要がなく、複雑なネットワーク構造に強い。 | 複数の属性を組み合わせて柔軟で効果的な照合が可能。 |
| デメリット | 完全一致等のルールではタイポや表記揺れに弱く、曖昧な一致に対応できない。 | 長い文字列では計算コストが高い。基本的にはスペルミスなどわずかな違いがあるものしか検知できない。 | 差集合が多いとスコアが下がりやすい。集合の要素の並び順や部分的な一致は考慮しない。 | ベクトルの大きさを無視する。 | エッジの重み付けが精度に大きく影響し、類似度スコアの設計が難しい。 | ベクトル化やベクトル学習にコストがかかる、教師データが必要。 | 精度向上には良質なトレーニングデータが必要。なぜ一致したか、説明性が低い場合がある。 |
| 有効なケース | BOMや部品表などの部品データの、一意な部品IDでの統合 | 名前、住所、メールアドレスなどのスペルの揺れやタイポのある情報をもとに顧客情報の統合 | 登録情報をトークン化して集合として扱い、異なるシステムの部品を統合 | 多言語モデルを用いてベクトル化して類似度を計算し、使用言語の異なるシステム間での統合 | 「同じ部品を供給している」「同じ工場に納品している」といった構造的な類似性を捉えた、異なるシステムに登録された同一サプライヤーの統合 | サプライチェーン全体の構造を活用し、異なるシステムに登録された同一サプライヤーを統合 | 部品名・型番・寸法などの多数の属性から、同一部品を分類・統合 |
Entity Resolutionのアプローチには、それぞれに得意な領域と限界があります。製造業のように、構造化データ・非構造化データ・ネットワーク構造が混在する環境では、複数の手法を組み合わせて使うハイブリッド戦略も有効です。
最後までお読みいただきありがとうございました。本記事がEntity Resolutionの理解と活用の一助となれば幸いです。
Discussion