はじめに
はじめまして。データアナリティクスラボ株式会社 データソリューション事業部の本多と申します。
LLMのファインチューニングを行うことでネガポジ分析(感情分析)のタスク特化を行いました。ネガポジ分析をどのモデル・どの程度の学習件数で行うと良いモデル(正解率・学習時間・出力時間)が作成できるのかについて検証しましたので、結果をご紹介します。
取り組んだ内容
今回は入力した文章に対して「ポジティブ」or「ネガティブ」の単語のみを出力するモデルを作成することを目標とします。タスク特化を行い、以下の3つについて検証を行います。
検証結果をもとに今回の分析内での最良モデルを決定します。
- 学習件数と正解率の関係
- パラメータ数やインストラクションモデルによる正解率・学習時間・出力時間の比較
- Llama系モデルとBERT系モデルの比較
前提知識
まず初めに、今回の検証で必要となる前提知識について簡単に紹介いたします。すでにご存知の方は飛ばしていただければと思います。
スケーリング則
「スケーリング則」とは、OpenAIの研究チームが2020年1月に発表した論文「Scaling Laws for Neural Language Models」で提唱されました。内容は、モデルのパラメータ数やデータ件数などが増えれば増えるほど精度が向上するという法則のことです。つまり、時間と費用を掛けた巨大なモデルほど高い性能を発揮できるということです。
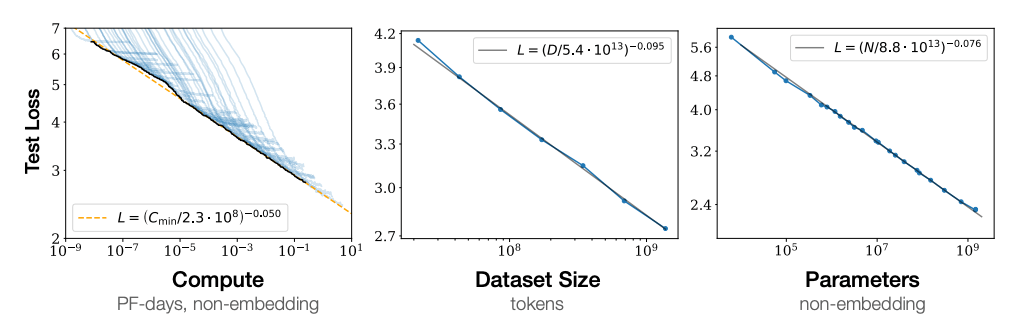 縦軸はLossを表しており、小さいほど精度が高いことを示します。
縦軸はLossを表しており、小さいほど精度が高いことを示します。
横軸はそれぞれ、「計算量」「データ数」「パラメータ数」を表しています。
スケーリング則に従い、今回の検証では学習件数やパラメータ数が多いほど精度が高くなることが予測されます。
BERT系モデルとLlama系モデルの違い
BERTとLlamaはどちらも大規模言語モデル(LLM)の一種で、Transformerの構造を利用しています。大きな違いとしてはBERTはエンコーダーのみを、Llamaはデコーダーのみを使用している点です。
エンコーダーを使用するBERTは文脈の前後関係を考慮して単語を理解します。一方のLlamaは次の単語を予測することに特化しています。
そのため一般的には以下のように言われています。
- BERT:主に文章の理解や分類、質問応答などのタスクに適している
- Llama:テキスト生成や会話など、より幅広いタスクに対応できる
またBERT系モデルの出力方法は指定したラベル(今回であれば「ポジティブ」と「ネガティブ」)のどちらの確率が高いかを計算し、確率の高いラベルを出力します。
一方でLlama系モデルは回答となる文章を一から生成します。つまりファインチューニングを行う際に、文章とするのではなく単語として回答することも学習する必要があります。
例)
- 入力文章:ネガティブかポジティブかを判定してください。「この食べ物は美味しいです。」
- BERT系モデル出力:「ポジティブ」
- Llama系モデル出力:「私はポジティブだと思います。なぜならば...」
以上を考慮して今回のネガポジ分析では、分類を得意としており出力方法までは学習する必要のないBERT系モデルの方が精度が良くなることが予測されます。
選定モデル
今回使用したモデルは以下の4つです。
-
tohoku-nlp/bert-base-japanese-v3- BERT系モデル
-
elyza/ELYZA-japanese-Llama-2-7b- Llama系モデル
- パラメータ数 70億
-
elyza/ELYZA-japanese-Llama-2-7b-instruct- Llama系モデル
- パラメータ数 70億
- 対話精度を向上させることを目的に事後学習済み
-
elyza/ELYZA-japanese-Llama-2-13b- Llama系モデル
- パラメータ数 130億
ファインチューニングの流れ
BERT系モデルとLlama系モデルではファインチューニングの流れやコードが一部異なります。今回はBERT系モデルのファインチューニングの大まかな流れを記載します。
データセットの準備
以下のポジネガ分析用に一般公開されているデータを使用します。
(label=0がポジティブ、label=1がネガティブです。)
DatasetDict({
train: Dataset({
features: ['sentence', 'label', 'review_id'],
num_rows: 187528
})
validation: Dataset({
features: ['sentence', 'label', 'review_id'],
num_rows: 5654
})
})
{'sentence': ['面白いから見てみな、と言われみた。ホラーとして面白いかと思ったら、ほんとにコメディおもしろかった。志村うしろ!は事前確認。的なルールとかイイね♪'], 'label': [0], 'review_id': ['R2WSEN6JAQLHE5']}
{'sentence': ['みんながみんな非常識な行動してる映画としか見れなかった。日本の描写が酷い(苦笑)あんな女子高生いないよ。見れば見るほど不快感が増す・・こんな映画初めてですね。ブラピもこんな映画に出ないで欲しい・・'], 'label': [1], 'review_id': ['RUICK2QUT5EFX']}
学習データ・検証データ共に、ポジティブとネガティブの割合が1:1となるように振り分けます。以下は学習データ(train_dataset)の作成コードです。
dataset_split = dataset['train']
# ラベルごとにデータをフィルタリング
positive_samples = dataset_split.filter(lambda x: x['label'] == 0)
negative_samples = dataset_split.filter(lambda x: x['label'] == 1)
# ラベル毎に同じ割合となるようにデータを取得する
positive_samples = positive_samples.shuffle(seed=42).select(range(1000))
negative_samples = negative_samples.shuffle(seed=42).select(range(1000))
# サンプリングしたデータを結合してtrain_datasetを作成(2,000件)
train_dataset = concatenate_datasets([positive_samples, negative_samples])
同様の作業をvalidationに対しても行いvalid_datasetを作成します。
トークナイザの設定、データセットの前処理
データセットのテキストをモデルの入力形式に対応するように変換します。作業としては、トークン分割とトークンのIDへの変換です。
from transformers import AutoTokenizer
# モデルを指定
model_name = "tohoku-nlp/bert-base-japanese-v3"
# モデル名からトークナイザを読み込む
tokenizer = AutoTokenizer.from_pretrained(model_name)
読み込んだトークナイザを利用し、テキストを変換します。
変換する関数として preprocess_text_classification関数を作成します。この関数では、トークナイザにsentenceを与え、トークンID・マスク・セグメント埋め込みのIDに変換しています。
from transformers import BatchEncoding
def preprocess_text_classification(
example: dict[str, str | int]
) -> BatchEncoding:
"""文書分類の事例のテキストをトークナイズし、IDに変換"""
encoded_example = tokenizer(example["sentence"], max_length=512)
# モデルの入力引数である"labels"をキーとして格納する
encoded_example["labels"] = example["label"]
return encoded_example
train_datasetおよび、valid_datasetに対してpreprocess_text_classification関数を適用します。
encoded_train_dataset = train_dataset.map(
preprocess_text_classification,
remove_columns=train_dataset.column_names,
)
encoded_valid_dataset = valid_dataset.map(
preprocess_text_classification,
remove_columns=valid_dataset.column_names,
)
----------------------------
{'input_ids': [2, 24683, 12488, 5538, 456, 481, 460, 384, 458, 13317, 494, 481, 449,...],
'token_type_ids': [0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0,...],
'attention_mask': [1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1,...],
'labels': 0}
モデルの準備
今回使用するデータのラベルには、positive・negativeのみでなくneutralが含まれていたため、neutralのラベルを削除します。
from collections import Counter
# ラベルごとの件数をカウント
label_counts = Counter(train_dataset['label'])
# 件数が0のラベル(neutral)を削除
filtered_label_mapping = {
label: (id, count)
for id, (label, count) in enumerate(label_counts.items())
if count > 0
}
# ラベル名とIDを表示
class_label = train_dataset.features["label"]
filtered_label_mapping_with_names = {
class_label.names[id]: (id)
for id in filtered_label_mapping.keys()
}
# 結果を表示
print(filtered_label_mapping_with_names)
--------------------------------------
{'positive': 0, 'negative': 1}
モデルの読み込みにAutoModelForSequenceClassificationを使用し、今回出力するラベル・ラベル数を指定します。
from transformers import AutoModelForSequenceClassification
label2id = {label: id for id, label in enumerate(filtered_label_mapping_with_names)}
id2label = {id: label for id, label in enumerate(filtered_label_mapping_with_names)}
model = AutoModelForSequenceClassification.from_pretrained(
model_name,
num_labels=2, # ラベル数を指定
label2id=label2id, # ラベル名からIDへの対応を指定
id2label=id2label, # IDからラベル名への対応を指定
)
LoRAの設定
LoRAとはPEFT手法の一種です。PEFT手法とは、ファインチューニングを行う際に全てのパラメータを再調整するのではなく、一部のパラメータのみを更新することで計算コストを大幅に削減します。target_modulesで調整対象とする層を指定します。
from peft import (
LoraConfig,
PeftModel,
prepare_model_for_kbit_training,
get_peft_model
)
# 全層をターゲットとするためのモジュール名
target_modules = [
"attention.self.query", "attention.self.key", "attention.self.value",
"attention.output.dense", "intermediate.dense", "output.dense"
]
# モデルをkbit訓練のために準備
model = prepare_model_for_kbit_training(model)
# LoRaの設定を定義
peft_config = LoraConfig(
r=16, # LoRAのランクを設定
lora_alpha=16, # LoRAの拡張係数を設定
lora_dropout=0.05, # LoRAのドロップアウト率を設定
bias="none", # バイアスの設定
task_type="CAUSAL_LM", # タスクタイプの設定(因果言語モデル)
target_modules=target_modules # LoRAが適用されるモジュールを指定
)
# LoRAを適用したモデルを取得
model = get_peft_model(model, peft_config)
学習方法の設定・実行
学習率や評価方法などを決定します。
from transformers import TrainingArguments
training_args = TrainingArguments(
output_dir="./results", # 結果の出力ディレクトリ
num_train_epochs=3, # 訓練のエポック数
per_device_train_batch_size=2, # 各デバイスのバッチサイズ
gradient_accumulation_steps=2, # 勾配の蓄積ステップ数
optim="paged_adamw_8bit", # オプティマイザーの種類
save_steps=100, # 保存するステップ間隔
logging_steps=5, # ログを記録するステップ間隔
learning_rate=5e-6, # 学習率
weight_decay=0.001, # 重み減衰
fp16=False, # FP16精度での計算を使用しない
bf16=False, # BF16精度での計算を使用しない
max_grad_norm=0.3, # 勾配の最大ノルム
max_steps=-1, # 最大ステップ数
warmup_ratio=0.3, # ウォームアップの比率
group_by_length=True, # 長さに基づいてデータをグループ化
lr_scheduler_type="constant", # 学習率のスケジューラタイプ
eval_strategy="steps", # 評価のストラテジー
eval_steps=100, # 評価を行うステップ間隔
save_total_limit=1, # 保存するチェックポイントの最大数
load_best_model_at_end=True, # 訓練終了時に最良のモデルをロード
metric_for_best_model="accuracy", # 最良のモデルを決定する評価指標
greater_is_better=True, # メトリクスが小さいほど良い場合はFalse
report_to="wandb"
)
今回は、正解率が高くなるように学習させたいため、compute_accuracy関数を作成しTrainerのcompute_metricsに指定します。trainer.train()で学習を実行します。(wandbの設定コードはここでは割愛します。)
import numpy as np
def compute_accuracy(
eval_pred: tuple[np.ndarray, np.ndarray]
) -> dict[str, float]:
"""予測ラベルと正解ラベルから正解率を計算"""
predictions, labels = eval_pred
# predictionsは各ラベルについてのスコア
# 最もスコアの高いインデックスを予測ラベルとする
predictions = np.argmax(predictions, axis=1)
return {"accuracy": (predictions == labels).mean()}
from transformers import Trainer
trainer = Trainer(
model=model,
train_dataset=encoded_train_dataset,
eval_dataset=encoded_valid_dataset,
data_collator=data_collator,
args=training_args,
compute_metrics=compute_accuracy,
)
trainer.train()
参考にLlama系のモデルの学習コードについても、以下に記載します。
実装コード
import gc
import os
import torch
from datasets import load_dataset, concatenate_datasets, Dataset
import warnings
import pandas as pd
import random
from collections import Counter
import matplotlib.pyplot as plt
from transformers import (
AutoModelForCausalLM,
AutoTokenizer,
BitsAndBytesConfig,
HfArgumentParser,
TrainingArguments,
logging,
TextStreamer,
BatchEncoding
)
from peft import (
LoraConfig,
PeftModel,
prepare_model_for_kbit_training,
get_peft_model
)
from trl import SFTTrainer
from torch.utils.data import DataLoader
from datetime import datetime
from tqdm import tqdm
from collections import Counter
from trl import DataCollatorForCompletionOnlyLM
model_name = "elyza/ELYZA-japanese-Llama-2-7b"
dataset = load_dataset("shunk031/JGLUE", name="MARC-ja")
# ラベルごとのカウントを関数として定義
def count_labels(dataset):
return Counter(dataset['label'])
dataset_split = dataset['train']
# ラベルごとにデータをフィルタリング
positive_samples = dataset_split.filter(lambda x: x['label'] == 0)
negative_samples = dataset_split.filter(lambda x: x['label'] == 1)
# ラベル毎に同じ割合となるようにデータを取得する
positive_samples = positive_samples.shuffle(seed=42).select(range(1000))
negative_samples = negative_samples.shuffle(seed=42).select(range(1000))
# サンプリングしたデータを結合してtrain_datasetを作成
train_dataset = concatenate_datasets([positive_samples, negative_samples])
dataset_split = dataset['validation']
# ラベルごとにデータをフィルタリング
positive_samples = dataset_split.filter(lambda x: x['label'] == 0)
negative_samples = dataset_split.filter(lambda x: x['label'] == 1)
# ランダムに100件ずつサンプリング
positive_samples = positive_samples.shuffle(seed=42).select(range(100))
negative_samples = negative_samples.shuffle(seed=42).select(range(100))
# サンプリングしたデータを結合してvalid_datasetを作成
valid_dataset = concatenate_datasets([positive_samples, negative_samples])
# 件数が0のラベルを削除
filtered_label_mapping = {
label: (id, count)
for id, (label, count) in enumerate(label_counts.items())
if count > 0
}
# 量子化の設定
bnb_config = BitsAndBytesConfig(
load_in_4bit= True, # 4bitでモデル読み込み
)
# 事前学習モデルの読み込み
model = AutoModelForCausalLM.from_pretrained(
model_name,
quantization_config=bnb_config, # 量子化設定を適用
device_map="auto", # GPUの自動割り当て
torch_dtype="auto",
trust_remote_code=True,
)
# モデル名からトークナイザを読み込む
tokenizer = AutoTokenizer.from_pretrained(model_name, trust_remote_code=True)
tokenizer.padding_side = "right"
tokenizer.pad_token = tokenizer.eos_token
#正解回答をラベルではなくテキストに変換する
def preprocess_text_classification(
example: dict[str, str | int]
) -> BatchEncoding:
"""文書分類の事例のテキストをトークナイズし、IDに変換"""
encoded_example = tokenizer(example["sentence"], max_length=512)
# モデルの入力引数である"labels"をキーとして格納する
encoded_example["labels"] = example["label_text"]
return encoded_example
def change_label(item):
if item['label'] == 1:
item['label_text'] = 'ネガティブ'
elif item['label'] == 0:
item['label_text'] = 'ポジティブ'
return item
t_dataset = train_dataset.map(change_label)
v_dataset = valid_dataset.map(change_label)
encoded_train_dataset = t_dataset.map(
preprocess_text_classification,
remove_columns=t_dataset.column_names,
)
encoded_valid_dataset = v_dataset.map(
preprocess_text_classification,
remove_columns=v_dataset.column_names,
)
# モデルをkbit訓練のために準備
model = prepare_model_for_kbit_training(model)
# LoRaの設定を定義
peft_config = LoraConfig(
r=16, # LoRAのランクを設定
lora_alpha=16, # LoRAの拡張係数を設定
lora_dropout=0.05, # LoRAのドロップアウト率を設定
bias="none", # バイアスの設定
task_type="CAUSAL_LM", # タスクタイプの設定(因果言語モデル)
target_modules=["q_proj", "k_proj", "v_proj", "o_proj", "gate_proj"] # LoRAが適用されるモジュールを指定
)
# LoRAを適用したモデルを取得
model = get_peft_model(model, peft_config)
# キャッシュ削除
gc.collect()
torch.cuda.empty_cache()
# EOSトークンの取得
EOS_TOKEN = tokenizer.eos_token
# プロンプトフォーマット
def formatting_prompts_func(example):
output_texts = []
for i in range(len(example['sentence'])):
DEFAULT_SYSTEM_PROMPT = "あなたはネガティブかポジティブかを判別する優秀な機械です。ネガティブorポジティブのみを出力します。"
B_INST, E_INST = "[INST]", "[/INST]"
B_SYS, E_SYS = "<<SYS>>\n", "\n<</SYS>>\n\n"
prompt = "{bos_token}{b_inst} {system}{prompt} {e_inst} ".format(
bos_token=tokenizer.bos_token,
b_inst=B_INST,
system=f"{B_SYS}{DEFAULT_SYSTEM_PROMPT}{E_SYS}",
prompt=example['sentence'][i],
e_inst=E_INST,
)
text = f"""{prompt}\n\nAnswer: {example['label_text'][i]}{EOS_TOKEN}\n"""
output_texts.append(text)
return output_texts
response_template_ids = [22550, 29901]
collator = DataCollatorForCompletionOnlyLM(response_template_ids, tokenizer=tokenizer)
# トレーニングの設定(正解率を基に学習するとエラーとなったためLlama系モデルはLossを基に学習を行っています。)
training_arguments = TrainingArguments(
output_dir="./results", # 結果の出力ディレクトリ
num_train_epochs=3, # 訓練のエポック数
per_device_train_batch_size=2, # 各デバイスのバッチサイズ
gradient_accumulation_steps=2, # 勾配の蓄積ステップ数
optim="paged_adamw_8bit", # オプティマイザーの種類
save_steps=100, # 保存するステップ間隔
logging_steps=5, # ログを記録するステップ間隔
learning_rate=5e-6, # 学習率
weight_decay=0.001, # 重み減衰
fp16=False, # FP16精度での計算を使用しない
bf16=False, # BF16精度での計算を使用しない
max_grad_norm=0.3, # 勾配の最大ノルム
max_steps=-1, # 最大ステップ数
warmup_ratio=0.3, # ウォームアップの比率
group_by_length=True, # 長さに基づいてデータをグループ化
lr_scheduler_type="constant", # 学習率のスケジューラタイプ
evaluation_strategy="steps", # 評価のストラテジー
eval_steps=100, # 評価を行うステップ間隔
save_total_limit=1, # 保存するチェックポイントの最大数
load_best_model_at_end=True, # 訓練終了時に最良のモデルをロード
metric_for_best_model="loss", # 最良のモデルを選択するためのメトリクス
greater_is_better=False, # メトリクスが小さいほど良い場合はFalse
)
# SFTTrainerの設定
trainer = SFTTrainer(
model=model,
train_dataset=t_dataset,
eval_dataset=v_dataset,
peft_config=peft_config,
formatting_func=formatting_prompts_func,
data_collator=collator,
tokenizer=tokenizer,
max_seq_length=512,
args=training_arguments,
packing = False
)
loader = DataLoader(trainer.train_dataset, collate_fn=collator, batch_size=2)
batch = next(iter(loader))
trainer.train()
検証結果
以下に検証結果の一覧を掲載します。
BERT系モデルは'positive' or 'negative'を出力するようにしているため、正解率 = 50%はランダムに出力しているのと同じです。
Llama系モデルでの正解率は、最初の5文字が正しい回答(ポジティブorネガティブ)と一致している場合を正解としています。そのため正解ラベルがポジティブの場合、「私はポジティブだと思います。」は不正解、「ポジティブ」や「ポジティブです。」は正解としています。最初の5文字を判断基準とした理由は、学習後の出力全てにおいて「ポジティブ」or「ネガティブ」から始まっていたことから、集計の簡略化のために最初の5文字を判断基準としました。
| モデル | 学習件数 | FT前正解率 | FT後正解率 | 学習時間 | 1件あたりの回答時間 |
|---|---|---|---|---|---|
| tohoku-nlp/bert-base-japanese-v3 | 2,000 | 52.0% | 87.0% | 4分 | 0.14s |
| tohoku-nlp/bert-base-japanese-v3 | 5,000 | 52.0% | 92.0% | 2分 | 0.14s |
| tohoku-nlp/bert-base-japanese-v3 | 10,000 | 52.0% | 93.7% | 4分 | 0.14s |
| tohoku-nlp/bert-base-japanese-v3 | 20,000 | 52.0% | 95.2% | 8分 | 0.14s |
| elyza/ELYZA-japanese-Llama-2-7b | 2,000 | 4.5% | 93.0% | 223分 | 7.63s |
| elyza/ELYZA-japanese-Llama-2-7b-instruct | 2,000 | 68.0% | 95.0% | 222分 | 8.22s |
| elyza/ELYZA-japanese-Llama-2-13b | 2,000 | 67.0% | 96.5% | 445分 | 2.57s |
まずはファインチューニング前の正解率を確認します。
BERT系モデルの正解率は52%と、ランダム同等の正解率となりました。
Llama-7bモデルでは正解率が4.5%と、ほとんど正解できませんでした。出力結果には「私は、」と始まる回答が散見されました。ちなみに出力形式は問わず、ラベル(ポジティブかネガティブか)を理解できていた割合は全体のうち51%でした。つまりLlama系モデル(特にLlama-7bモデル)はファインチューニングで入力文章を理解することと、単語で(もしくは文頭でラベルを)出力することの2点を学習する必要がありそうです。
一方でLlama-13bモデルやLlama-7b-instructモデルでは正解率が60%を超えており、他のモデルと比較すると比較的ファインチューニング前でも正解率が高くなりました。ラベルを理解しているのは全体の70%(Llama-13bモデル)でした。
以降はファインチューニング後の結果について、それぞれの視点で確認します。
-
学習件数と正解率の関係検証
BERT系モデルで学習件数別に正解率を比較します。
2,000件〜20,000件の学習データでは、学習件数が多いほど精度が高くなりました。これはスケーリング則と一致した結果となりました。学習件数をさらに増やせば、正解率はより高くなるかもしれません。
-
パラメータ数やインストラクションモデルによる正解率・学習時間・出力時間の検証
Llama系モデルで結果を比較します。
同じ学習件数でファインチューニングを行った後の正解率は7bモデルで93.0%、13bモデルで96.5%の正解率となり、パラメータ数が大きいほど正解率の高いモデルとなりました。またインストラクションモデルでファインチューニングを行うと、パラメータ数の同じ7bモデルよりも正解率が高く、95.0%になりました。
次に学習時間とパラメータ数を比較します。学習時間は7bモデルで223分、13bモデルで445分となり、パラメータ数に比例して学習時間が伸びていると言えます。(使用しているGPUはL4 GPUです。)

一件あたりの回答出力時間は、パラメータ数が大きいほど短くなリました。
本来であればパラメータ数が多くなると推論時の計算量が増えるため、回答の出力時間も長くなると考えられますが、今回の結果は逆となりました。なぜ今回はパラメータ数が大きいほど回答の出力時間が短くなったか解決することはできませんでした。(1トークンあたりの出力秒数も確認しましたが、同様の結果となりました。)
当初の検証内容にはありませんでしたが、Llama系モデル内でもパラメータ数によりファインチューニング後の出力が大きく異なったのでご紹介します。
Llama-7bモデルではファインチューニングを単語のみ出力するよう学習をしても、単語の後に理由を出力しようとしてしまいます。出力トークン数を10トークンに制限しているため「理由」までで出力が止まっていますが、トークン数を制限しなければ続いて理由を回答していそうです。
一方でLlama-13bモデルではファインチューニング後はしっかりと単語のみを出力するようになりました。
またLlama-7bモデル・13bモデルともに不正解となった出力では、出力方法は文頭にラベルが出力されていましたが、ラベルが不正解となっていました。- Llama-7bモデルの出力結果
入力文章 出力回答 正解ラベル 正解フラグ 説明書をネットで確認しないといけないのが煩わしいが、十分な機能です。日本メーカーは良いです。 ポジティブ 理由 ポジティブ TRUE 良い映画です。購入して良かった。自分にとっては永久保存板です。 ポジティブ 理由 ポジティブ TRUE ウィルス対策としてBitdefender、AVG,Avastなどいつも使ってる安心感のあるフリーアプリがkindleで全滅なのは心外ですが、nexusやwindowsでは必需品です。 ネガティブ 理由 ポジティブ FALSE 映画は凄く良かったです。Blu-rayユーザーにDVDはただにゴミ。押し付けは本当に止めるべき。日本語吹き替えももう廃止して欲しいです。 ポジティブ 理由 ネガティブ FALSE - Llama-13bモデルの出力結果
入力文章 出力回答 正解ラベル 正解フラグ 説明書をネットで確認しないといけないのが煩わしいが、十分な機能です。日本メーカーは良いです。 ポジティブ ポジティブ TRUE 良い映画です。購入して良かった。自分にとっては永久保存板です。 ポジティブ ポジティブ TRUE ウィルス対策としてBitdefender、AVG,Avastなどいつも使ってる安心感のあるフリーアプリがkindleで全滅なのは心外ですが、nexusやwindowsでは必需品です。 ネガティブ ポジティブ FALSE 映画は凄く良かったです。Blu-rayユーザーにDVDはただにゴミ。押し付けは本当に止めるべき。日本語吹き替えももう廃止して欲しいです。 ネガティブ ネガティブ TRUE -
Llama系モデルとBERT系モデルの比較
学習件数を2000件としたモデル同士で比較すると、BERT系モデルの正解率は87.0%、Llama系モデルでは96.5%となりLlama系モデルの方が正解率が高い結果となりました。
一方で学習時間や、一件あたりの出力時間はBERT系モデルが圧倒的に短くなりました。モデル 学習前正解率 学習後正解率 学習時間 一件あたりの出力時間 BERT 56.0% 87.0% 4分 0.14s Llama-13b 67.0% 96.5% 445分 2.57s
まとめ
今回、ネガポジ分析のタスク特化を行い最も高い正解率となったのはelyza/ELYZA-japanese-Llama-2-13b の96.5%でした。しかし、学習時間や出力時間はBERT系モデルの方が優れており、総合的にモデルの良さを判断するとtohoku-nlp/bert-base-japanese-v3 での20,000件学習時(正解率95.2%)が最良のモデルということができます。もし学習するデータ件数が少ない場合は、BERT系モデルにとらわれず、Llama系モデルを使うのも良いかもしれません。
| モデル | 学習件数 | FT前正解率 | FT後正解率 | 学習時間 | 1件あたりの回答時間 |
|---|---|---|---|---|---|
| (最良モデル):tohoku-nlp/bert-base-japanese-v3 | 20,000 | 53.0% | 95.2% | 8分 | 0.14s |
| elyza/ELYZA-japanese-Llama-2-13b | 2,000 | 67.0% | 96.5% | 445分 | 2.57s |
最後に
LLMのファインチューニングを初めて行ってみて、学習データがあれば比較的簡単にファインチューニングを行えることがわかりました。また、BERT系モデルとLlama系モデルの結果がここまで大きく違うことに驚きました。すでにelyza/Llama-3-ELYZA-JP-8Bなど新しいモデルも出てきているので、今回使用しなかったモデルでも引き続き検証してみたいと思います。
最後まで読んでいただきありがとうございました。
参考文献
山田育矢、鈴木正敏、山田康輔、李凌寒.『大規模言語モデル入門』.技術評論社.2024年

Discussion