はじめに
データアナリティクスラボ株式会社です。
先日、データソリューション事業部のメンバーで「atmaCup #17」に参加しました!
本記事ではその結果と取り組みについてご紹介させていただきます。
参加メンバー
メンバー①:宮澤
入社2年11か月。マーケティングに関する分析・モデル構築に従事しており、社内では生成AIの研究活動を行っています。
メンバー②:力岡
入社2年7か月。金融に関する分析や生成AI関連の開発に従事しており、社内でも生成AIの研究活動を行っています。
メンバー③:関田
入社1年5か月。深層学習や最適化の研究業務に従事しており、社内でも量子技術の研究活動を行っています。
コンペ概要
atmaCupとは、atma株式会社が主催するオンサイトデータコンペティションです。このコンペはオフラインで実際に集まってコンペを行うのが特徴ですが、現在はコロナウイルス感染防止のためオンラインでの開催がメインとなっています。
コンペ期間中には初心者向け講座が開催されたり、ディスカッションも活発で基本的に日本語でやり取りされるため、Kaggleはハードル高いなと感じている人にもおすすめです。
#17 のページがこちらです。
今回のテーマ
#17 のテーマは「洋服をおすすめするかどうかを予測せよ!」というものでした。
ユーザーの属性と商品に対するレビューのデータから、その商品がおすすめされたかどうかの予測精度を競うというお題です。
データ概要としては以下の通りで、カラム数はさほど多くなく、レビューテキストが主な情報となりそうなことがわかります。
train.csv test.csv
Clothing ID: 衣服のID
Age: レビューをしている人の年齢
Title: レビューのタイトル
Review Text: レビューの本文
Rating: レビューでつけた点数。この列は学習用データでのみ提供されます。
Recommended IND: レビューした人が、この商品をおすすめするかどうか。今回のコンペではこの値が1になる確率を予測してください。学習用データでのみ提供されます。
Positive Feedback Count: 他のユーザーからつけられたイイネの数。
clothing_master.csv
Clothing ID: 衣服のID. train 並びに test.csv の Clothing ID と紐付けられます.
DIvision/Department/Class Name: 衣服のカテゴリ。右に行くほど細かいカテゴリを表します。
https://www.guruguru.science/competitions/24/data-sources より引用
結果
さっそく結果ですが、最終的にはPublic LBで4位、Private LBでは11位という結果でした!
コンペ中盤ではPublicで1位をキープしている時間帯もあったため、少し悔しい結果になりました。


解法
ここからは私たちの取り組み(解法)について説明させていただきます。
LLM(Public: 0.9755 Private: 0.9763)
今回最も予測に寄与するであろうデータとしては、Title と Review Text が考えられました。そこで、テキスト情報をもとに「おすすめするかどうか」を予測するために、言語モデルを使ったアプローチを試みました。
microsoft/deberta-v3-large
まずはよくNLPコンペで使われているBERT系の発展モデルであるmicrosoft/deberta-v3-largeを使いました。trainデータでクロスバリデーションを行ってファインチューニングをしました。
テキストの前処理としては、Title と Review Textを改行で繋げて一つのテキストとしました。
学習の設定は以下の通りです。
# トレーニングの設定
training_args = TrainingArguments(
output_dir='./results', # トレーニング結果の出力ディレクトリ
evaluation_strategy="steps", # 各エポック終了後に評価
eval_steps=100, # 評価の頻度
learning_rate=2e-5, # 学習率
per_device_train_batch_size=16, # バッチサイズ
per_device_eval_batch_size=32, # 評価時のバッチサイズ
num_train_epochs=3, # トレーニングのエポック数
weight_decay=0.01, # 重み減衰
load_best_model_at_end=True, # 最良のモデルをロード
metric_for_best_model='roc_auc', # 最良モデルの評価指標
save_steps=500, # モデルの保存頻度
logging_steps=100, # ログの出力頻度
)
このファインチューニング後モデルでのPublicスコアは 0.9688 (Private 0.9690) でした。
google/gemma-2-9b-it
DeBERTaはEncoder-onlyモデルで分類タスクに優れているとされていますが、よりパラメータの大きなDecoder-onlyモデルでも同等かそれ以上の精度が出るのではないかと考え、いくつかのLLMを使ってみました。
Decoder-onlyモデルの場合、プロンプトに対して生成するトークンの対数尤度にsoftmax関数を通すことで、分類の確率のように扱うことができると考え、以下のように実装してみました。
プロンプトの前処理
def format(title, review):
system = "You are an excellent assistant. You give review information about a garment and you predict whether the reviewer will recommend the garment. Answer “1” if you expect the reviewer to recommend the garment, or “0” if you do not expect the reviewer to recommend the garment. Do not answer anything other than the label.\n\n"
context = f"Review Title:\n{title}\n\nReview Text:\n{review}\n\n"
answer_format = "Recommended: "
return system + context + answer_format
予測処理
def pred(text):
input_ids = tokenizer.encode(text, return_tensors="pt").to(device)
# 生成
output = model.generate(
input_ids,
return_dict_in_generate=True,
output_scores=True,
max_new_tokens=1,
do_sample=False,
)
# 生成されたステップのスコア(logits)を取得
logits = output.scores[0]
# "1"と"0"のトークンIDを取得
token_0_id = tokenizer.convert_tokens_to_ids("0")
token_1_id = tokenizer.convert_tokens_to_ids("1")
# "1"と"0"に対するlogitsを抽出
logits_0 = logits[:, token_0_id]
logits_1 = logits[:, token_1_id]
# "1"と"0"のlogitsだけでソフトマックスを適用
selected_logits = torch.tensor([logits_0.item(), logits_1.item()], device=device)
probs = F.softmax(selected_logits, dim=-1)
# 各トークンの確率
prob_0 = probs[0].item()
prob_1 = probs[1].item()
# 1である確率を返す
return prob_1
学習しない状態でどの程度の精度が出るかを確認したところ、trainに対してROC-AUCが0.95近くのスコアであり、testに対してもPublicスコア 0.9519 の精度となりました。
Gemma2の予測結果に対して誤差分析をすると、「商品自体はいいが自分には合わなかった」というようなレビューでおすすめをしているデータに対する予測を外している傾向が見えました。例えば以下のようなものがありましたが、実際にはおすすめしていますが、予測は非おすすめとなっていました。
Title:
Didn't work for my curvy hips
Review:
This jacket is really pretty and unique. unfortunately the material around the waist area does not lay flat like it does in the picture. i'm 5 ft 6 in and a size 6. i ordered the medium. it fit well but the material around the waist area jutted out making me look really wide. disappointed to have to return this.
これはGemma2の事前学習および事後学習の結果として得られる予測傾向であることがわかるため、追加学習で調整することが可能です。
そこで、LoRAを用いてGemma2にファインチューニングを行うことで補正することを試みました。
学習設定
peft_config = LoraConfig(
r=16, # LoRAのランクを設定
lora_alpha=16, # LoRAの拡張係数を設定
lora_dropout=0.05, # LoRAのドロップアウト率を設定
bias="none", # バイアスの設定
task_type="CAUSAL_LM", # タスクタイプの設定(因果言語モデル)
target_modules=["q_proj", "k_proj", "v_proj", "o_proj", "gate_proj"] # LoRAが適用されるモジュールを指定
)
training_arguments = TrainingArguments(
num_train_epochs: 3,
per_device_train_batch_size: 8,
per_device_eval_batch_size: 8,
gradient_accumulation_steps: 2,
optim: "paged_adamw_8bit",
learning_rate: 1e-5,
lr_scheduler_type: "cosine",
max_seq_length: 256,
neftune_noise_alpha: None,
packing: False,
weight_decay=0.001,
fp16=False,
bf16=False,
max_grad_norm=0.3,
max_steps=-1,
warmup_ratio=0.3,
group_by_length=True,
こちらの設定で5-foldクロスバリデーションでファインチューニングをした結果の平均値を取ったところ、Publicスコアが 0.9519から 0.9755 (Private 0.9763) まで向上しました。
基本特徴量 + Embedding + GBDT(Public: 0.9740 Private: 0.9748)
基本特徴量
次の特徴量を作成しました。TitleおよびReview Text以外に利用できる特徴量が限られていたため、主にテキストデータに基づく特徴量となっています。
-
Title,Review Textの欠損フラグ -
Title,Review Textの文字数と単語数 -
Ageの5歳ごとにグループ分け -
Positive Feedback Countの正規化 -
Title,Review TextのRoBERTaの感情分析 -
Title,Review TextのDoc2Vecによるベクトル化とICAによる次元圧縮 - カテゴリ値のOne-Hot Encoding
Embedding
以下のEmbeddingモデルを使用して、テキストデータをベクトル化しました。後述しますが、gte-Qwen2-7B-instructとSFR-Embedding-Mistralの重要度が高かったです。
- BAAI/bge-en-icl
- Alibaba-NLP/gte-Qwen2-7B-instruct
- Salesforce/SFR-Embedding-Mistral
- multilingual-e5-large
ベクトル化を行う際のテキストは以下のプロンプトテンプレートに従って作成しました。このテキストは、文章形式で作成するか、構造化情報として単純に箇条書きにするかで比較しましたが、前者の方が精度が高かったため、こちらを採用しています。
プロンプトテンプレート
Instruct: Based on the review information, does the reviewer recommend this clothing item
Query: The reviewer is {Age} years old and reviewed a {DIvision Name}/{Department Name}/{Class Name}. The title of the review is '{Title}' and the review states: '{Review Text}' . Based on this review, would the reviewer recommend this item?
実際のプロンプト例
Instruct: Based on the review information, does the reviewer recommend this clothing item
Query: The reviewer is 25 years old and reviewed a General/Bottoms/Skirts. The title of the review is '3-season skirt!' and the review states: 'Adorable, well-made skirt! lined and very slimming. i had to size up b/c it runs a bit snug around the waist. however, it's worth it b/c this will match many long and short sleeve tops!' . Based on this review, would the reviewer recommend this item?
GBDT
上記で作成した全ての特徴量を用いて、LightGBMとXGBoostで学習を行いましたが、どちらのモデルでも精度にほとんど差はありませんでした。以下はLightGBMにおける特徴量重要度の結果ですが、ベクトル化による特徴量が上位を占めているという状況でした。
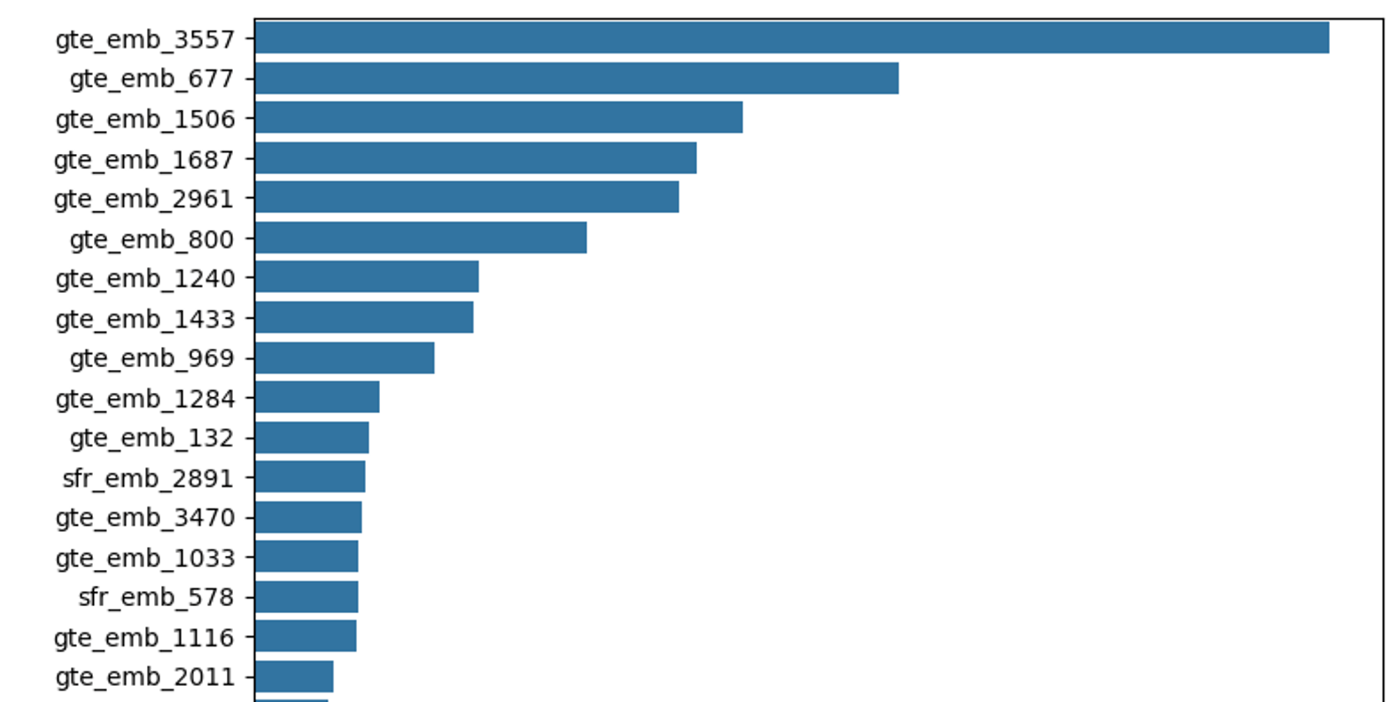
最終的に、LightGBMにおけるPublicスコアは 0.9740 (Private 0.9748)、XGBoostにおけるPublicスコアは 0.9732 (Private 0.9745) でした。
アンサンブル + ルールベース処理(Public: 0.9761 Private: 0.9770)
Gemma2、LightGBM、XGBoostの予測結果を8:1:1の比率で加重平均し、アンサンブルを行いました。これらのモデルは、Title, Review Text の内容に基づいて推論を行うため、欠損データに対しては固定のスコアがついたり、AgeやPostive Feedback Countなどの特徴量から推定されたスコアが付与されることになります。しかし、両方が欠損しているデータに限定すると、AUCは0.5となり、全く予測精度が出ていない状況でした。そこで、アンサンブル後には、Titleおよび Review Textの両方が欠損しているデータに対しては、一定のルールベース処理を適用しました。
ルールベース処理
trainデータとtestデータの特徴量分布に大きな違いが見当たらなかったため、trainデータと同様のルールベース処理がtestデータにもよく当てはまるという仮定を置いています。この仮定のもと、trainデータの特徴量を可視化し、ルールベースでのラベル付け処理を施しました。
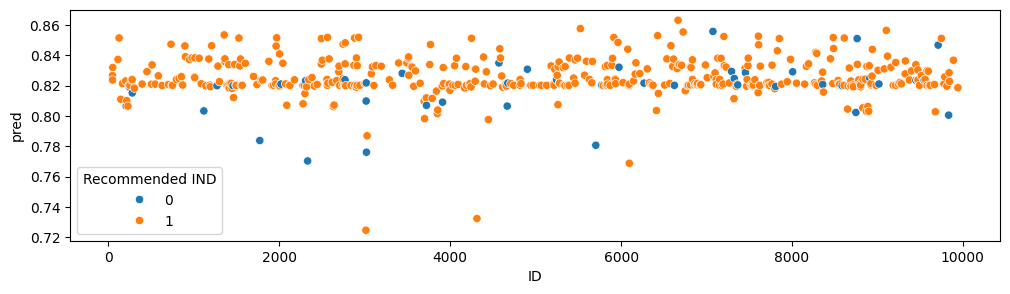
例えば、Positive Feedback Count は以下のような分布でした。横軸がレビューのID、縦軸がPositive Feedback Count です。
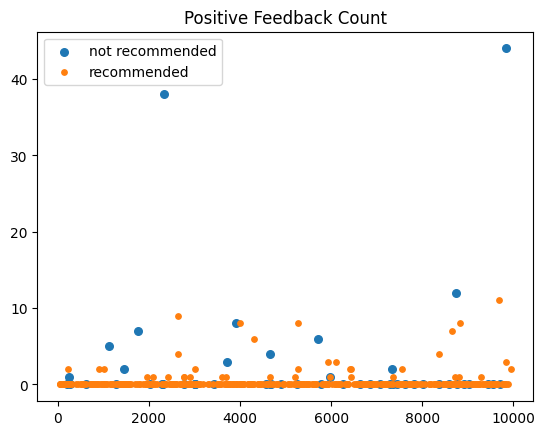
これを見ると、Positive Feedback Count が極端に大きいレビューは必ずおすすめしていないということがわかります。「有名で信頼されているレビュワーがレビューしたため、コメントが付いていなくても多くの人が Positive Feedback を行った」などと考えれば納得できる傾向です。
したがって、Titleおよび Review Textの両方が欠損しているデータに対しては、Positive Feedback Count が20より大きければラベルを0とする、というルールを設けました。
同様に、他の全ての特徴量について可視化を行いました。その結果、おすすめする/しない が大きく偏って分布していた特徴量として以下がありました。
-
Class Name= Fine gauge -
Class Name= Jeans -
Class Name= Layering -
Class Name= Legwear
以下のグラフの横軸はレビューのID、縦軸はClass Name が箇条書きにしている各項目に等しい (1) か否 (0) かです。
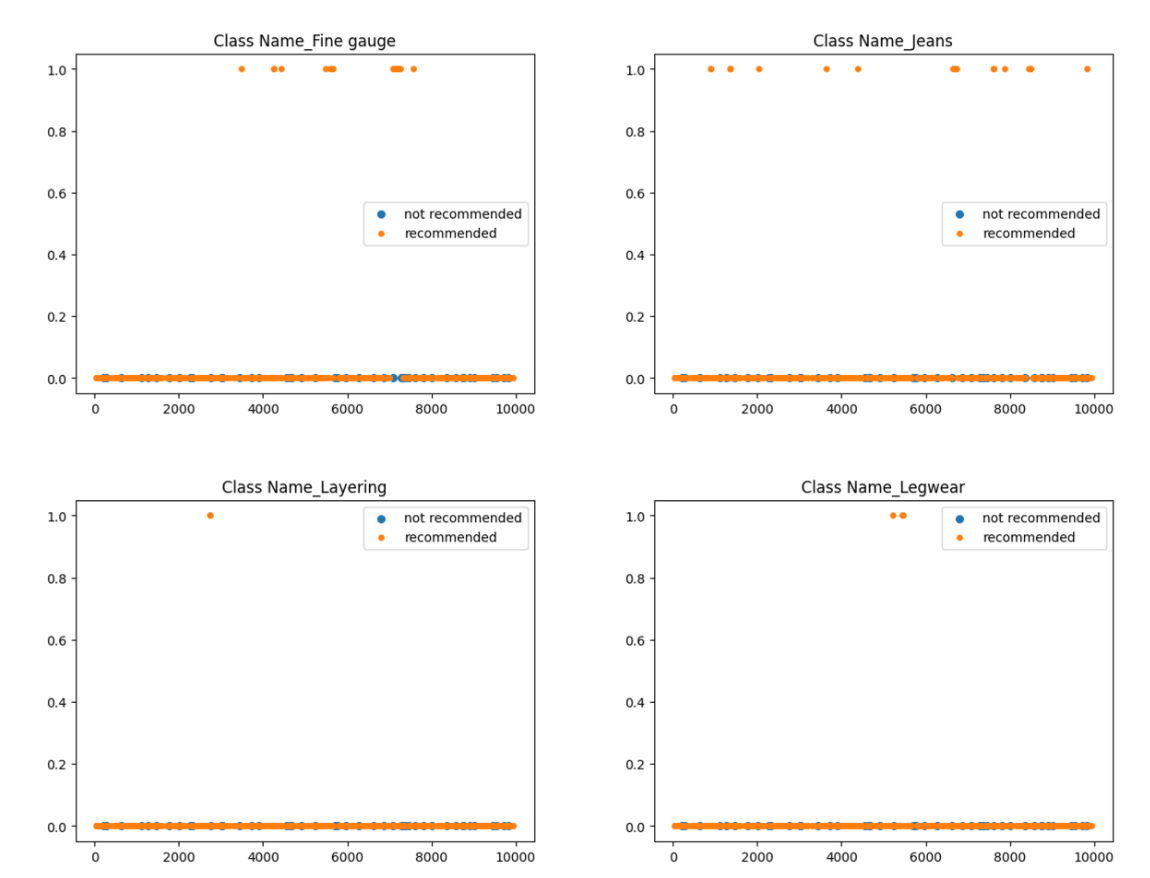
上記項目に関するルールベース処理を追加した結果、Titleおよび Review Textの両方が欠損しているデータに対するAUCは向上しました。具体的な値は変数の組み合わせ方やラベルの付け方によって変動しますが、最大でAUC 0.6030まで向上させることができました。
上記の分析の結果から、ルールベース処理は以下のように行いました。学習データの傾向から、スコアを気持ち程度調整しているといった内容になります。結果的にルールベース処理前後で、スコアはほとんど変わらなかったので、大きな効果はなかったのかなと思います。
-
Positive Feedback Count> 20 → 0 -
Class Name= Fine gauge &Clothing IDの平均推薦率 > 80% → (1+score*2)/3 -
Class Name= Jeans &Clothing IDの平均推薦率 > 80% → (1+score*2)/3 -
Class Name= Layering &Clothing IDの平均推薦率 > 80% → (1+score*2)/3 -
Class Name= Legwear &Clothing IDの平均推薦率 > 80% → (1+score*2)/3
最終的にアンサンブルとルールベース処理を行った結果の推移は以下の通りとなります。
| 手法 | Public Score | Private Score |
|---|---|---|
| Gemma2 | 0.9755 | 0.9763 |
| LightGBM | 0.9740 | 0.9748 |
| XGBoost | 0.9732 | 0.9745 |
| アンサンブル+ルールベース | 0.9761 | 0.9770 |
試したが効かなかったこと、やれなかったこと
グラフニューラルネットワーク (GNN) モデル構築
今回の予測タスクはレコメンドしているか否かということで、「レコメンドといえばGNN」と思いモデル構築を試みました。
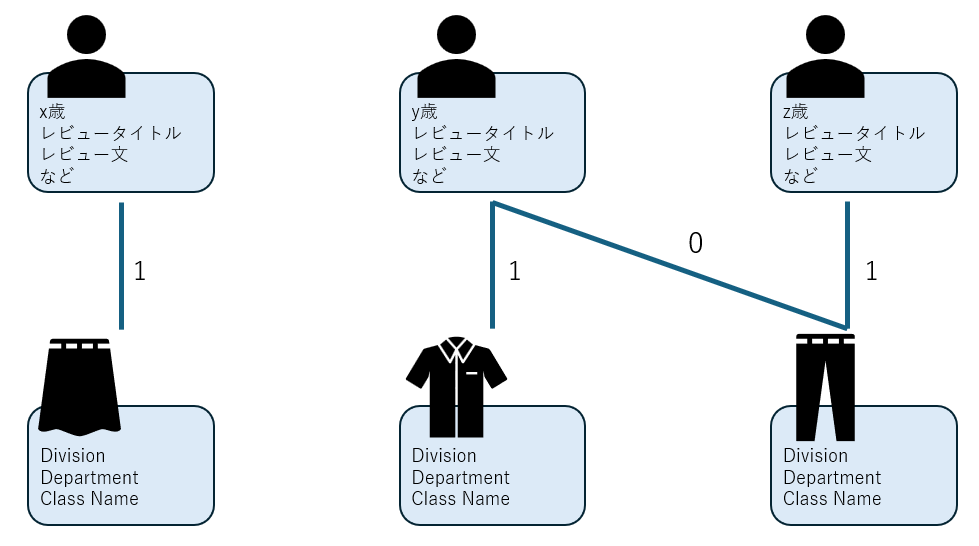
作成したGNNモデルの概要は以下の通りです。
- ノード(2種類。Heterogeneous Graphと呼ばれます。)
- レビュワー: 特徴量として、年齢やベクトル化されたレビュー文などを持つ。
- 服: 特徴量として、服のカテゴリを持つ。
- エッジ
- レビュワーノードおよび服ノードを結ぶ。レビューが存在するノード間にのみエッジを形成する。
- エッジの重みに1 (おすすめする) または 0 (おすすめしない) を与える。
- ノードの特徴を基にエッジの重みを学習・予測する。
結果としては、trainデータのうち学習に使用していない20%のノードに対して最高AUCが0.8584でした。試しに学習に用いたノードに対しても予測を行ったところ、そのAUCは0.9265で、学習データに対する予測ですら上位成績には及ばない結果となりました。
モデルのチューニングはほとんど行っていない状態ではありましたが、この状態から短期間で0.97台へ向上させるのは難しそうだと判断し、GNNモデル構築はここで終了としました。
Title、Review Textが欠損しているデータのモデル構築
最終的にはルールベースの処理を行いましたが、TitleおよびReview Textの両方が欠損しているデータ専用のモデル構築も試みました。両方が欠損しているデータは約500件程度しかなかったため、以下の3つのパターンでモデルを構築し、精度比較を行いました。
- 両方欠損しているデータのみで学習(AUC: 0.5476)
- すべてのデータを使用し、両方欠損しているデータに重みを付けて学習(AUC: 0.5560)
- 欠損のないデータで学習した後、両方欠損しているデータで転移学習(AUC: 0.6478)
結果として、転移学習が最も高い精度を示しましたが、下記の分布のように0と1の区分が明確にできておらず、またアンサンブルモデルを構築する時間もなかったため、結果をどう組み込むか判断がつかず、途中で断念しました。学習データのサンプル数が少なく、過学習の可能性も考えられるため、ここにあまり多くの時間をかけるべきではなかったかなと後悔しています。
上位解法について
上位解法は主にatmaCup #17のディスカッションにあがっています。
上位の解法は基本的に私たちの取り組みと大きくは変わらず、Gemma2-9B-itをファインチューニングしてレビューのテキストデータから予測するのがほとんどでした。逆に言えばDeBerta, LightGBMのみにとどまっていた場合、上位まで食い込むのは難しかったようです。
似た解法のなかでも自分たちにはなかった細かな工夫が見られましたので、そちらを取り上げたいと思います。
1. Pseudo Labeling
Pseudo Labelingは、半教師あり学習の一手法で、ラベルのないデータに対して擬似的にラベルを付与する手法です。以下の手順で行われます。
- 少量のラベル付きデータでモデルを訓練する。
- 訓練したモデルを用いて、ラベルのないデータにラベルを予測する。
- 予測されたラベルを擬似ラベルとして使用し、元のラベル付きデータと組み合わせて再度モデルを訓練する。
- 3で得られたモデルを使い、再度ラベルのないデータのラベルを予測し、その結果を基に擬似ラベルを生成して訓練を繰り返す。
擬似ラベルは誤ったラベルが含まれる可能性がありますが、Pseudo Labelingはある種の正則化効果が期待されており、ラベル付きデータが少ない場合に発生しやすい過学習を軽減すると言われています。上位解法の中では、Gemma2でテストデータの疑似ラベルを作成し、debertaで学習するということが行われていました。

Pseudo Labelingの全体像(引用: https://www.ai-shift.co.jp/techblog/3161)
2. Auxiliary loss
Auxiliary loss は「補助損失」と呼ばれるもので、ニューラルネットワークの訓練の途中で分岐させたサブネットワークで損失計算を行うものです。
代表的な利用例はGoogleNetという画像認識モデルでの利用で、以下のようなアーキテクチャのイメージになります。これによって、ネットワークの中間層に直接誤差が伝搬され、勾配消失を防いだり、過学習を防いだりする効果があるようです。

Auxiliary lossのイメージ(引用:Going Deeper with Convolutions
今回のコンペにおいては(他の解法を見る限りではおそらく)中間層での損失計算というよりは、メインとなる損失に小さな重みをかけた補助損失を足すという実装をしている(例えばメイン損失 + 0.2*補助損失)と思われました。したがってアンサンブル学習に近い形になっていると思われます。
補助損失に使っていたのはRatingという商品に対する評価のカラムを用いているようでした。Ratingは予測対象であるReccomended INDと強い相関を持っているため、補助損失として機能する可能性が高く、過学習を防いで汎化性能を高める効果があったのだと考えられます。
おわりに
社内のメンバーでatmaCupに参加するのは2回目でしたが、前回よりは大きく順位を上げることができました。平日を2日含む計3日間(48時間)という短期間のコンペであり、実装からスコア改善まで大変でしたが、ディスカッションにはあがっていなかったが上位で共通していた解法を自分たちで発見でき、一時的にPublic LBで1位をキープできていたのは嬉しい体験でした。
また次回以降も参加して入賞を目指していきたいと思います!
最後までお読みいただきありがとうございました。

Discussion