はじめに
はじめまして。データアナリティクスラボ株式会社 データソリューション事業部の力岡と申します。普段はデータサイエンティストとして、データ分析や機械学習モデルの構築、生成AIアプリの開発などを行っています。
今回は、弊社チームで参加したKDD Cup 2024について、上位チームの解法を紹介いたします。
参加したコンペティション
私たちが参加したのは、KDD Cup 2024の「Multi-Task Online Shopping Challenge for LLMs」というコンペティションです。このコンペでは、大規模言語モデル(LLM)を活用して、オンラインショッピングに関連する複数のタスクを解決することが求められました。コンペの詳細について知りたい方は、別記事の「KDDCup参戦記① 概要と結果編」をご覧ください。
上位解法の紹介
このコンペティションの規定により、上位5位に入賞したチームは、ワークショップ論文を作成し公開することが義務付けられています。実際の論文は、以下のサイトでご覧いただけます。
今回は、私たちが参加したTrack 2において、1位から3位のチームが採用した解法について、簡潔に紹介します。
1位の解法(LB: 0.791)
解法論文:Winning Amazon KDD Cup’24
- 利用モデル:Qwen2-72B-Instruct
- 手法:QLoRA + AWQ
- 学習環境:8×A100(80GB)
本コンペにて、全てのTrackで1位を取っているNVIDIAの解法となっています。莫大な計算リソースを駆使して大量の学習データセットを生成し、それらのデータを基にFine-Tuningを実施しています。特に注目すべき点は、LoRAアダプタのアンサンブルを実施している点です。アダプタ統合の手法については全く知見がなかったので、大変勉強になりました。
解法の概要
彼らの解法は、以下のように構築されています。

解法の全体像(引用:解法論文 Figure 2)
-
学習データセットの構築
ESCI-dataやECInstructやAmazon M2などの公開データセットを利用し、18のタスクと同様の構造を持つようにデータセットを処理したのちに、Llama3-70B-InstructやGPT-4を利用してデータの多様性を高めたり、欠落した情報を補完したりすることでデータを拡張し、約50万件の学習データセットを構築しています。
-
Fine-Tuning
QLoRAを用いてモデルを量子化しつつ、微調整を行っています。学習時のハイパーパラメータは以下の図に示されている通りです。

ハイパーパラメータの設定(引用:解法論文 Table 2)
また、各Trackごとに4つの微調整されたLoRAアダプタを作成し、wise-ftと呼ばれる手法を利用して重みを統合しています。wise-ftは、異なるデータセット間の分布シフトを考慮して、複数のモデルを効果的に組み合わせるための手法で、以下の計算式で重みのアンサンブルを実施しているようです。
W_{\text{wise}} = W_{\text{base}} + \alpha \cdot W_A \cdot W_B W_{\text{base}} : baseモデルの重み W_A\cdot W_B : アダプタの重み この手法を使って、適切な比率でアダプタを組み合わせることで、精度向上が確認されました。以下の図では、Track5においてbaseモデルの重みにv8アダプターをα=0.56でかけたときに最も精度が高くなることを示しています。

LoRAアダプタの統合による精度向上(引用:解法論文 Figure 3)
-
量子化
学習後にAWQ手法を用いて、モデルを4ビットに量子化しています。AWQとGPTQの量子化を比較したところ、速度と精度がほぼ同等だったようです。
2位の解法(LB: 0.784)
解法論文:EC-Guide: A Comprehensive E-Commerce Guide for Instructionb Tuning and Quantization by ZJU-AI4H
- 利用モデル:Yi-1.5-34B
- 手法:QLoRA + GPTQ
- 学習環境:4×A40 or 8×RTX3090
このチームは、1位の解法とほとんど同じ手法を採用していますが、比較的小さいモデルであるYi-1.5-34Bを使用している点が特徴です。モデルサイズが小さいため、推論速度に余裕があり、Chain of Thoughtを導入していることがスコア向上の鍵となっていそうです。
解法の概要
彼らの解法は、以下のように構築されています。

解法の全体像(引用:解法論文 Figure 1)
-
学習データセットの構築
ECInstructやAmazon M2などの様々な公開データセットを活用し、さらに人手による加工やGPTによる自動加工を通じて、学習データセットを作成しました。生成・多肢選択・検索・ランキング・固有表現認識の5つのタスクに対して、約7.5万件の学習データセットを構築しています。
-
Fine-Tuning
QLoRAを用いてモデルを量子化しつつ、微調整を行っています。
-
量子化
学習後にGPTQ手法を用いて、モデルを4ビットに量子化しています。また、様々なモデルにおいて、量子化有無で評価したところ、Yi-1.5B-34Bが最も良い結果となったようです。

同じ学習設定における様々なモデルの評価結果(引用:解法論文 Table 2)
- Chain of Thought(推論時の工夫)
多肢選択問題に対してのみ、CoTを導入しました。具体的には質問が算術ベースの問題かを判断するために数字を数えたり、「Let’s think step by step.」というフレーズをプロンプトに含めて、正解に導く根拠を生成するように工夫しています。
3位の解法(LB: 0.781)
解法論文:Second Place Overall Solution for Amazon KDD Cup 2024
- 利用モデル:Qwen2-72B
- 手法:AWQ + プロンプト設計
- 学習環境:不明
このチームはFine-Tuningを行わず、量子化されたモデルとプロンプト設計の工夫のみで高いスコアを達成しました。他の上位チームが軒並みFine-Tuningを駆使している中、プロンプト設計のみで上位に食い込んでいるのは驚きです。リソースが限られた環境でも有効なアプローチとなり得るかもしれません。
LLMの選択
まず、8Bモデル(量子化なし)と70Bモデル(量子化あり)の性能差を検証するため、異なるサイズのLlama3モデルを利用して性能を評価しました。その結果、量子化された大きなモデルの方がはるかに優れた性能を持つことが確認されました。

モデルサイズの異なるLlama3の性能比較(引用:解法論文 Table 2)
次に、Llama、Gemma、Mistral、ChatGLM、Llama3、Qwen、Qwen2など複数のベースモデルをテストしています。これらの中でLlama3とQwen2が特に優れた性能を発揮しているため、この2つを比較した結果、Qwen2が総じて優れていることがわかり、最終的にQwen2を選択して検討を進めることになりました。
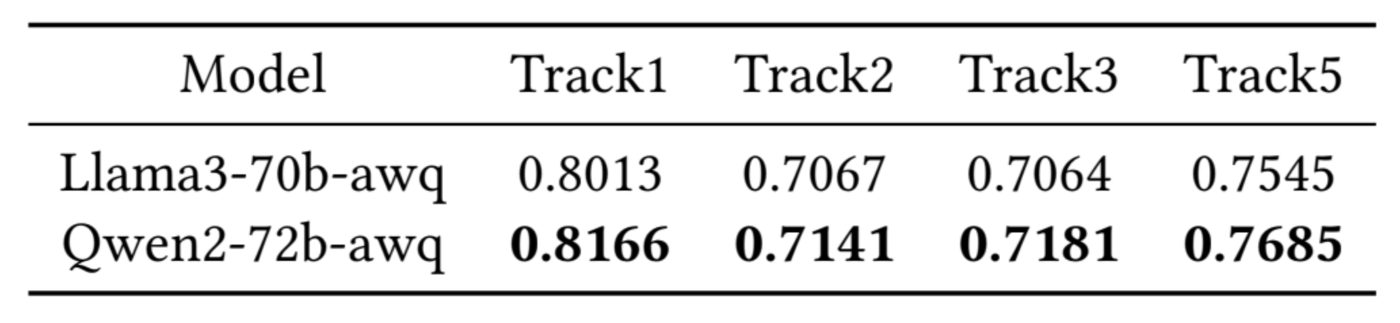
Llama3-70BとQwen2-72Bの性能比較(引用:解法論文 Table 3)
AWQのハイパーパラメータ調整
AWQの量子化プロセスにおいて、ハイパーパラメータの調整を行っています。コンペから提供されたサンプルデータセットを活用し、各パラメータを変えてそれぞれの性能を評価しています。組み合わせごとに性能差がかなりあることから、ハイパーパラメータ調整の重要度が伺えます。
- Max Data Length:一つのサンプルの最大長。これを超えるテキストは切り捨てられます。
- Block Size:各ブロックを分割する粒度。
- N_Samples:量子化処理に関与するサンプル数。

AWQのハイパーパラメータ調整(引用:解法論文 Table 4)
プロンプト設計
彼らの推論フェーズは、モデルの初期化、プロンプト設計、リクエストの作成、出力フォーマットの4つのステージから構成されています。ここでは、プロンプト設計に焦点を当てて紹介します。

全体的な推論構造(引用:解法論文 Figure 1)
Instruction(指示プロンプト)
推論時間や学習サンプルが限られている状況下では、指示プロンプトが非常に重要です。以下はこのチームの実際の指示プロンプトの例で、特に「チップを与える」という要素が、多くのトラックで一貫してパフォーマンスを向上させたようです。
Exemplar Selection(模範解答の選択)
few-shotプロンプトの要領で、タスクごとに最適な模範解答を選択し、回答精度を高めています。具体的な手法は以下の通りです。
Sub-task Division:タスクを生成、多肢選択、検索などのサブタスクに分割し、それぞれに特化したExemplarを選択。
Fixed Exemplars:サブタスクごとに関連するカテゴリから選ばれた固定の模範解答を使用。
Dynamic Exemplars:模範解答をサブカテゴリで固定するのではなく、バッチごとに異なる模範解答をプロンプトに追加。特に、多肢選択のタスクではDynamic Exemplarsの導入が精度向上に貢献しており、テストセットと開発セットの分布の違いを緩和したと考えられます。

Dynamic Exemplarsによる実験結果(引用:解法論文 Table 7)
さいごに
KDDCup2024の上位3チームの解法を紹介しました。やはり、大規模言語モデルという名前の通り、高精度を実現するためには、大規模なパラメータを持つモデルと豊富なデータセットを用いて学習させることが不可欠であると再認識しました。LLMのコンペでは、潤沢な計算資源を確保できない個人勢にとっては、非常に厳しい戦いとなりそうです。
とはいえ、アダプタのアンサンブルやプロンプト設計など、学ぶべき点が非常に多くありました。今後もこのようなコンペに挑戦し続け、上位の成績を残せるよう努力していきたいと思います。
関連記事
KDDCup参戦記① 概要と結果編
KDDCup参戦記② データ準備編
KDDCup参戦記③ RAG/ファインチューニング編
KDDCup参戦記④ モデルマージ編
KDDCup参戦記⑤ 上位解法の紹介 ◀ イマココ

Discussion