この記事のゴール
本記事では、画像認識の基本的な考え方から始めて、画像分類における代表的な手法とそれぞれの特徴や違いについて解説します。
読了後には、画像認識とは何かを理解し、どのような手法があり、それぞれの手法がどのように異なるのかを把握できるようになることを目指します。
画像認識とは
画像認識とは、画像データから物体やその位置などの特徴を抽出し、識別する技術です。機械学習やディープラーニングの発展により、高精度な画像認識が可能となり、さまざまな分野で活用されています。
活用事例
画像認識技術は、私たちの生活や産業に広く応用されています。代表的な活用例として、以下のようなものがあります。
- スマホの顔認証:スマートフォンのロック解除やアプリの認証に使用
- オンライン会議の背景ぼかし:人物と背景を識別し、リアルタイムで背景をぼかす処理
- 先進運転支援システム(ADAS):車載カメラを用いて歩行者や標識を認識し、衝突回避などの支援
- 不良品検出システム:製造業での品質管理において、不良品を自動的に識別し排除
画像認識における処理フロー
画像認識の処理フローは、以下のステップで進みます。

特徴抽出と分類
特徴抽出と分類について、複数の画像の中からバナナの画像を当てることを例に考えます。
バナナの特徴は「黄色くて棒状」と捉えることができます。しかし、画像は「画素」と呼ばれる小さな点の集まりで構成されており、各画素の値が格子状に格納されたデータです。そのため、単に入力された画像を見るだけでは、黄色くて棒状の物体が写っているかどうかを判別することはできません。
そこで、何らかの方法を用いて画像から「黄色の度合い」や「球体の度合い」などの情報を取得します。これらを特徴量と呼び、画像から特徴量を取り出すことを特徴抽出といいます。
画像の特徴量を定めることで、画像を「特徴空間」と呼ばれる空間に射影できます。例えば、「黄色度合」と「球体度」という2種類の特徴量を用いると、各画像は2次元の特徴空間に射影され、以下のように配置されます。

次に分類について説明します。分類とは、特徴空間をいくつかの領域に分割し、それぞれにクラス情報(「バナナ」「バナナ以外」など)を付与することです。
分類を行う際、異なるクラスに属するデータを分けるために設けられる境界を識別境界といいます。識別境界は、データの分布に応じて異なり、単純な場合には直線で表現できますが、より複雑な分布では曲線や非線形の境界が必要になることもあります。
識別境界を適切に設定することで、「バナナ」なのか「バナナ以外」なのかを正しく分類することができます。
画像分類から手法を理解する
画像分類とは、入力画像をあらかじめ設定した物体の種類の中からもっともらしいものを一つ選択するタスクです。近年の機械学習やディープラーニング(DNN)の発展により、さまざまな手法が開発されています。ここでは、代表的な画像分類手法について紹介します。
- 多クラスロジスティック回帰(機械学習)
- フィードフォワードニューラルネットワーク(FNN)
- 畳み込みニューラルネットワーク(CNN)
- Vision Transformer(ViT)
多クラスロジスティック回帰
まずは画像分類の主要なモデルの基礎ともなっている多クラスロジスティック回帰で画像分類を実施します。
特徴抽出(画像データの整形)
画像は通常、縦×横のピクセルの集まりで構成されていて、28×28ピクセルの白黒画像の場合、合計で28×28=784個の数値で表されています。しかし、このまま各数値を扱うのはモデルが処理しにくいため、画像データを1つの長いベクトルに変換します。具体的には、画像の左上から右下へと順番に並べ、784個の数値を1列にした784次元のベクトルにします。このベクトルが、モデルの入力データとなります(画像の平坦化)。画像の平坦化については、下記の動画がわかりやすく参考となります。
カラー画像の場合は赤(R)・緑(G)・青(B)の3つの色(チャネル)を持つため合計で28×28×3 = 2352となります。
その後正規化を行いますが、正規化については画像分類以外でもよく使われるため割愛します。また、このベクトルを特徴量として扱うことが可能ですし、このベクトルを用いて新たな特徴量を作成することも可能です。
分類
-
モデルでの予測(分類)
分類をするためにはまずクラスごとに、それぞれ1つずつ「線形関数(=識別境界)」を作る必要があります。線形関数とは、次のような形をした計算式です。これを全クラス分計算します。z_i = w_i^T x + b_i -
x -
w_i _i -
b_i -
z_i _i
-
-
ソフトマックスによる確率変換
各クラスのスコアz_i
ここで使うのがソフトマックス関数です。P(y=i∣x)= \frac{\exp(z_i)}{\sum_{j=1}^{N} \exp(z_j)} これにより、すべてのクラスの確率の合計が1(100%)になり、どのクラスの可能性が高いかがわかるようになります。
例えば、モデルが1枚の画像を処理した結果、ソフトマックス関数を適用した後に以下のような確率が出力されたとします。- 猫:0.70(70%)
- 犬:0.20(20%)
- 鳥:0.10(10%)
この場合は最も確率が高い「猫(70%)」が、モデルの最終的な予測結果となります。
このようにして、多クラスロジスティック回帰を用いた画像分類が完了します。
モデルの特徴
多クラスロジスティック回帰では識別境界を直線(超平面)でしか考えることができないため、分類するには表現不足となることがあります。また特徴量を手動で作成する必要があるため、特徴量エンジニアリングの質にモデルの精度が大きく左右されます。
フィードフォワードニューラルネットワーク(FNN)
フィードフォワードニューラルネットワーク(FNN)は、多クラスロジスティック回帰を拡張したモデルであり、DNNの一種です。多クラスロジスティック回帰では入力に対して線形変換を適用し、ソフトマックス関数で分類を行いますが、FNNは全結合層を複数重ね、各層で線形変換と非線形関数(ReLUなど)を適用することで、より複雑な非線形関数を学習できます。
FNNは基本的に、「入力層」→「全結合層」→「全結合層」→「(最終)全結合層」→「出力層」というように入力から出力へと信号が一方向に伝播するような構成となっています。(全結合層の数はモデルにより異なります。)
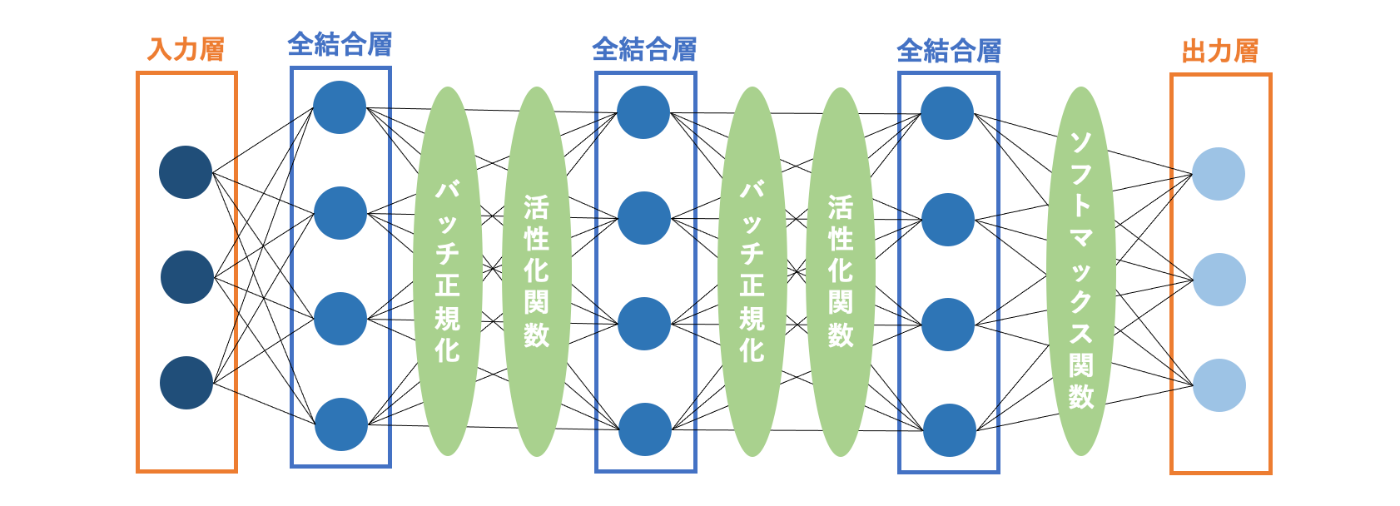
特徴抽出
-
全結合層 & 活性化関数
FNNには1つ以上の全結合層があり、各層のニューロンが入力データの特徴を学習します。全結合層は、入力と出力の間に線形変換を行いますが、単体では複雑なパターンを捉えることができません。そこで、活性化関数(例:ReLU)を全結合層と併用することで、線形変換に非線形性を加え、データの特徴をより適切に変換することができます。具体的には、全結合層に通すことで次元を変換し、活性化関数を適用することで非線形変換を行います。この変換によって、識別境界を直線(平面)で引けるようにデータを再配置することが可能となります。(↓イメージ)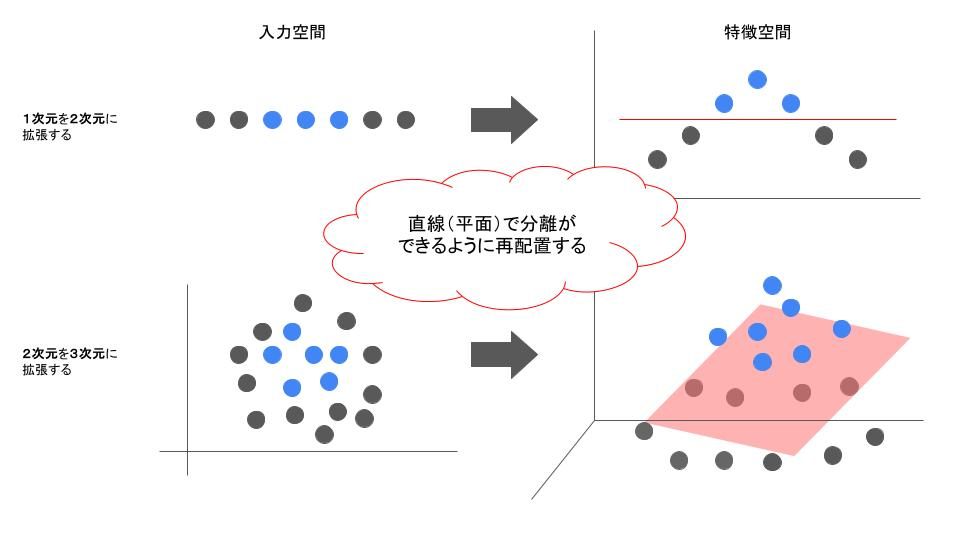
活性化関数によって、ネットワークはデータの持つ複雑な特徴や非線形な関係を学習できるようになります。特に画像分類のようなタスクでは、単純なエッジや色の情報だけでなく、それらの組み合わせから高次の特徴(例:形状や構造)を捉えることが可能になります。これにより、より高度な特徴抽出が行われ、最終的な分類の精度向上が期待できます。
FNNでは画像データのような2次元の空間情報をそのまま扱えないため、画像内の局所的な空間的な関係(例えば、隣接するピクセル間の関係)を捉えることができません。そのため、画像から有用な特徴を手動で抽出する必要があることが多いです(例: HOG、SIFTなど)。
分類
分類は多クラスロジスティックと同様です。最後の全結合層で各クラスに対応した線形関数を作成します。その後ソフトマックス関数を適用することで、確率的なクラス分類を行います。
モデルの特徴
非線形な活性化関数を用いることで、線形モデルよりも複雑なパターンの学習が可能になります。ただし、入力に画像などの空間構造をもつデータをそのまま使う場合、構造を無視して処理するため、局所的な特徴の抽出が苦手です。また、パラメータ数が多くなりやすい傾向があります。
畳み込みニューラルネットワーク(CNN)
畳み込みニューラルネットワーク(CNN, Convolutional Neural Network)はDNNの一種で、畳み込み演算を活用して画像の特徴を抽出します。畳み込み演算により、局所的なパターンを検出し高次元の特徴を学習することが可能になります。
今回はCNNの中でも広く用いられているResNet18を使用して画像分類を実施しまが、まずはCNNの構造について説明します。
-
CNNの構造
CNNは主に「入力層 (INPUT)」→「畳み込み層 (Convolution)」→(「活性化関数」→)「プーリング層(Pooling)」→「全結合層 (Fully_Connected)」→「出力層 (OUTPUT)」で構成されています
特徴抽出
-
畳み込み層(Convolution)
まずは畳み込みについて説明します。畳み込みとは、合成積とも呼ばれ2つの関数から1つの関数を作る演算です。今回の画像(2次元)で言うと、画像データとカーネルと呼ばれるフィルタの2つから1つの値を算出します。
カーネル(フィルタ)とは、畳み込み層で用いられる小さな行列で、一般的に3×3や5×5などの小さな正方行列が用いられます。カーネル内の値によって、画像をぼかす処理であったり、境界を判別したりすることが可能となります。カーネル内の値を変更することで、どのような処理ができるかは下記の動画が参考になります。
-
プーリング層(Max_pooling)
-
抽出された特徴が、画像の中で少しずれたり位置が変わったりしても、正しく捉えられるよう、「位置に関する情報」を上手に削ぎ落としています。

-
-
ResNetとは
続いて、ResNetとはCNNと何が異なるかについて説明します。
ResNetは、通常のCNNと異なり「残差ブロック」を導入しているのが特徴です。
通常のCNNでは層を増やすことでより高次元の特徴を獲得することは知られていましたが、単純に層を重ねるだけでは性能が悪化していくという問題がありました。これは、層が深くなるにつれて勾配が消失しやすくなり、学習が進まなくなるためです。
そこでResNetは、スキップ接続を導入し、層を飛び越えて元の特徴マップを加えることで、この問題を軽減し、より深いネットワークでも効果的に学習できるようになりました。-
通常のCNNとResNetの違い
- 通常のCNN(下図の左): 入力 → 畳み込み層 → 活性化関数 → 出力
- ResNet(下図の右): 入力 → 畳み込み層 → スキップ接続(Shortcut Connection) → 活性化関数 → 出力

スキップ接続によって「学習すべき変化量(残差)」だけを学習するため、勾配が消えにくくなり、非常に深いネットワークでも学習しやすくなります。
(補足) 残差ブロックとは、スキップ接続を含む計算単位(ブロック) のことを指します。
-
分類
基本のCNNの最終層ではFNNと同様に全結合層が採用され、この層で畳み込み層から得られた特徴マップ(3次元)を、分類のための1次元ベクトルに変換しています。一方でResNetの最終層では、グローバル平均プーリング(GAP)層が適用されています。グローバル平均プーリングとは各特徴マップの空間全体の平均値を計算して、1つの数値に集約する操作を行います。GAPを用いる利点は、全結合層と異なり学習パラメータが不要になるので計算コストを下げることが可能です。
また、別モデルにはGAPを適用してから全結合層、出力層としているモデルもあるみたいです。( MobileNetなど)
モデルの特徴
画像や音声などの空間的・時間的構造をもつデータに強く、畳み込み層により局所的な特徴を自動で抽出できます。パラメータ数もFNNに比べて少なく効率的です。ただし、入力の局所性に強く依存するため、長距離の関係性を捉えるのはやや苦手です。
Vision Transformer(ViT)
Vision Transformer(ViT)は、畳み込みを用いずにアテンション機構を活用して画像を処理する手法です。ViTは下記の流れで処理を行なっています。
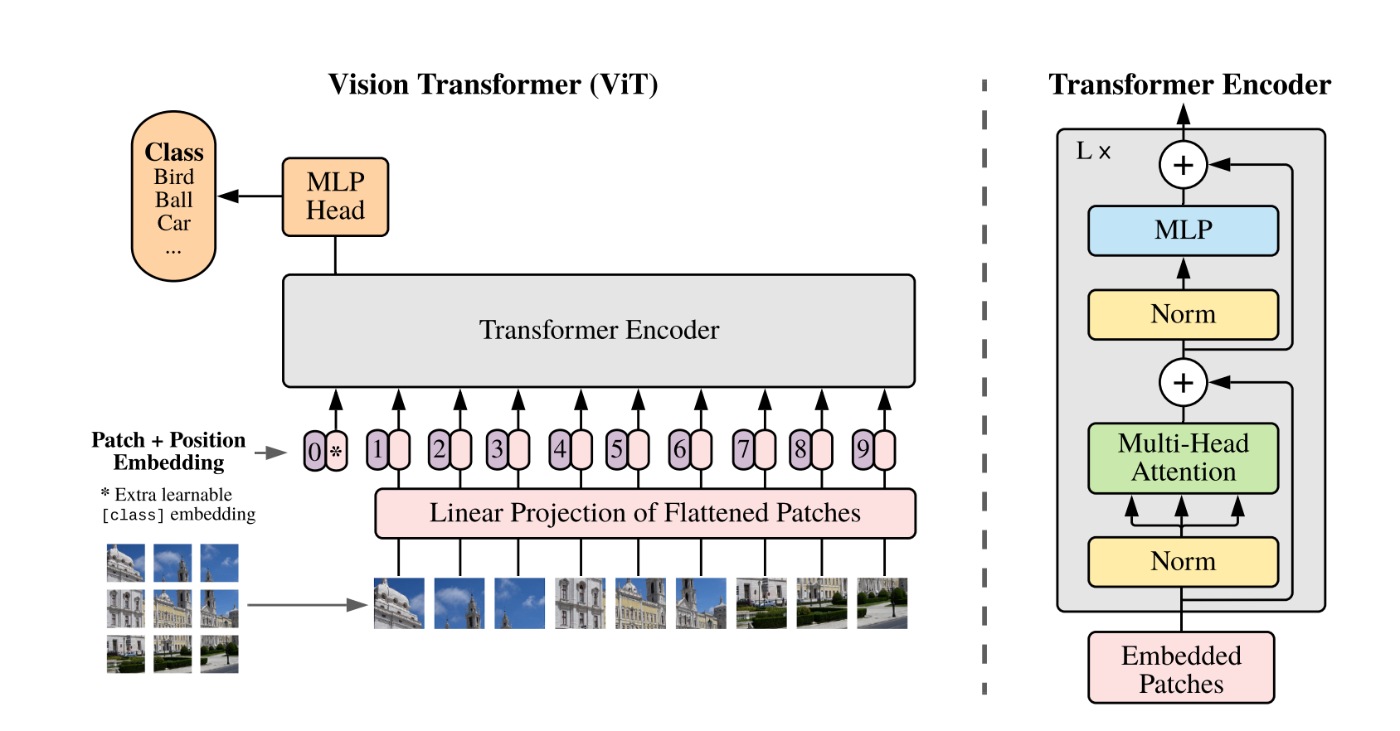 出典:https://arxiv.org/abs/2010.11929
出典:https://arxiv.org/abs/2010.11929
特徴抽出
-
画像の分割(パッチ化)
ViTはTransformerのモデルを一部丸々使用しているモデルです。しかしTransformerではテキストを入力することでトークン化していました。しかしViTでは画像を入力する必要があります。そこで画像を分割し単語のように扱うようにしました。
画像の分割(パッチ化)とは、大きな画像を小さな領域(パッチ)に分割することです。画像を固定サイズのパッチに分割し、それをトークンとして処理します。例えば、28×28ピクセルの画像を14×14のパッチに分割すると、合計4個(2×2)のパッチが得られます。これにより、画像を自然言語処理のように扱うことができるようになります。
-
パッチ埋め込み
各パッチの画素をそれぞれ1列に並べなおすことでベクトルになります。このパッチごとのベクトルに全結合層を適用することで、各ベクトルは学習を通じてより良いベクトル表現を獲得することが可能になります。この全結合層による変換をパッチ埋め込みと呼びます。 -
CLSトークン追加、位置埋め込み
入力画像から取得したベクトルは、画像の局所的な特徴を表しています。そこで、画像全体の特徴を示すトークンとしてCLSトークンを新たに付与します。つまりここまでで、ベクトルはパッチ数 + 1(CLS)作られたことになります。
位置埋め込みとは、入力データの並び順や空間的な位置情報をモデルに伝えるための手法です。Transformerは本来、順番に関する情報を持たないため、画像の各パッチがどの位置にあったのかを補足する必要があります。ViTでは、各パッチに位置情報を加算することで、画像の空間構造を考慮した処理が可能になります。 -
Transformerエンコーダ

Transformerエンコーダは、自己注意(Self-Attention)機構を活用して入力データ間の関係を学習します。画像分類でのViTは、分割したパッチ埋め込みとCLSトークンをエンコーダに入力し、重要と思われる画像パッチを選別し、その重要度に応じて画像情報を集約する処理を行っています。
エンコーダは複数の層で構成され、各層でマルチヘッド自己注意(Multi-Head Self-Attention)とフィードフォワードネットワーク(FNN)を適用し、特徴を学習します。このプロセスを通じて、画像全体の意味的な特徴を統合して、分類やその他のタスクに適した表現を生成します。
分類
ViTではTransformerエンコーダを通した後、CLSトークンの出力ベクトルを獲得しますがこのベクトルは画像の特徴を表しているだけで、分類(例えば「猫 or 犬」)には直接使えません。そこで登場するのがMLPヘッドです。MLPヘッドとは全結合層とレイヤー正規化で構成されています。

MLPヘッドを使うことで、特定のクラス数に整えることができます。最後に、ソフトマックス関数を適用し、各クラスに対する確率を出力することで分類を行います。
モデルの特徴
画像をパッチに分割し、それぞれをトークンとして扱うことで、長距離の関係性やグローバルな特徴の抽出が可能です。自己注意機構により画像全体の文脈を捉えやすく、CNNよりも柔軟な表現が可能です。しかし、畳み込みのような帰納バイアス(画像認識に特化した考え方の癖)を持たないため、効果的に学習させるには大量の学習データと計算資源が必要となります。データが少ない場合には、事前学習済みモデルの活用やデータ拡張が重要になります。
まとめ
下記に、画像分類で使用される代表的な手法の特徴をまとめます。
- 従来の機械学習ベースの手法(多クラスロジスティック回帰) は、計算コストが低くシンプルなモデルですが、識別境界を直線(超平面)でしか表現できないため、複雑なパターンの分類には不向きです。また、特徴量は手動で設計する必要があり、精度は特徴量エンジニアリングの質に大きく依存します。
- CNN(畳み込みニューラルネットワーク) は、畳み込み層により局所的な特徴を自動で抽出でき、画像内の位置変動に強いのが特徴です。比較的少ない学習データでも高い性能を発揮しますが、離れた領域間の関係性を捉えるのはやや苦手です。
- ViT(Vision Transformer) は、画像をパッチに分割し、各パッチをトークンとしてTransformerに入力することで、画像全体のグローバルな関係性を学習できます。高い柔軟性を持つ一方で、CNNのような局所性のバイアスがないため、効果的な学習には大量のデータと計算資源が必要です。
本記事では、代表的な画像分類手法の概要を紹介しましたが、これら以外にもさまざまなアプローチが存在します。興味があれば、ぜひ調べてみでください。
参照文献

Discussion