はじめに
データソリューション事業部の宮澤です。
今回は、デジタルコンテンツの真正性の証明や改ざん検知に用いられる「電子透かし」という技術について、中でもオーディオデータにおける電子透かし技術について調査を行いました。本記事では、従来の統計的手法は簡単に触れるのみとし、研究分野で注目度が高まっているニューラルネットワークを用いた手法に注目します。また、本記事ではモデルアーキテクチャに焦点を当てるため、代表的なデータセットや評価ベンチマークについては触れないものとします。
電子透かしを取り巻く現況
電子透かしによる著作権保護・コピーガード・改ざん防止は、デジタルコンテンツの普及時から研究され続けている分野です。近年では「ディープフェイク」と呼ばれる深層生成モデルによる巧妙な偽情報が容易に生成できるようになっています。ディープフェイクは政治や防衛といった領域にも入り込んでおり、悪用されると社会的に大きな影響を及ぼす危険があります。これにより、デジタルコンテンツの真正性・信頼性を示すための対策技術の重要性は高まっています。
電子透かしの基本原理
電子透かしとは、デジタルコンテンツ(画像・動画・音声など)の中に、人間には知覚できない形で情報を埋め込む技術のことを指します。埋め込まれた情報は、著作権保護や改ざん検知の目的で利用されます。電子透かしは大きく分けると以下の考え方が存在します。
-
堅牢透かし
- 一般的な加工や劣化が加わっても埋め込んだ情報が残る透かし。再配布・再エンコードされる可能性が高いコンテンツに適しており、著作権保護や流通追跡を目的とする。
-
脆弱透かし
- わずかな加工で壊れるように設計された透かし。改ざん検知や真正性証明を目的として、医療画像や電子契約書などに用いられる。
また、電子透かしには「ゼロビット」と「マルチビット」の2つがあります。
-
ゼロビット電子透かし
- 透かしが「ある」か「ない」かだけを検出する。これによってコンテンツが本物かどうかを判定することを目的とする。
-
マルチビット電子透かし
- 透かしに複数のビット情報を埋め込み、生成元やユーザー情報を検出する。透かしに情報を与えメッセージや証跡として利用することを目的とする。
電子透かしの性能は一般的に以下の指標で評価されます。
-
Imperceptibility(知覚忠実性)
- 透かしの埋め込みによってコンテンツ自体の品質を損なわず、人間の視覚や聴覚に変化を感じさせない性質のことを指す。
-
Robustness(堅牢性)
- 埋め込んだ透かし情報が、コンテンツに施される加工や圧縮などの処理に対してどの程度耐えられるかを指す。特に堅牢透かしでは透かし除去に耐えうる手法が求められる。
-
Capacity(容量)
- どれだけの情報量(透かしビット数)をコンテンツの中に埋め込めるかを指す。一般的に埋め込む情報量が多いほど堅牢性が増すが、知覚忠実性を保ったまま埋め込む容量を大きくすることは難しく、トレードオフの関係にあるとされている。
[1] Audio Watermarking: A Comprehensive Review では、これらに加えて、Security(安全性)とComputational Complexity(計算の複雑性)が挙げられています。安全性においては、透かしの埋め込み関数を暗号鍵に依存した秘匿なものにすることが推奨されています。計算の複雑性においては、透かしの堅牢性を高めるためには複雑な処理が必要になりますが、埋め込みにかかる時間と検出にかかる時間の両観点で計算量が大きくなると実用性が低下するため、バランスを取る必要があると述べられています。
オーディオデータにおける電子透かし
基本的なシナリオは以下の通りです。特定の透かしビット情報を何らかの手法でオーディオデータに埋め込み、それを検出器で検出するという流れで構成されます。
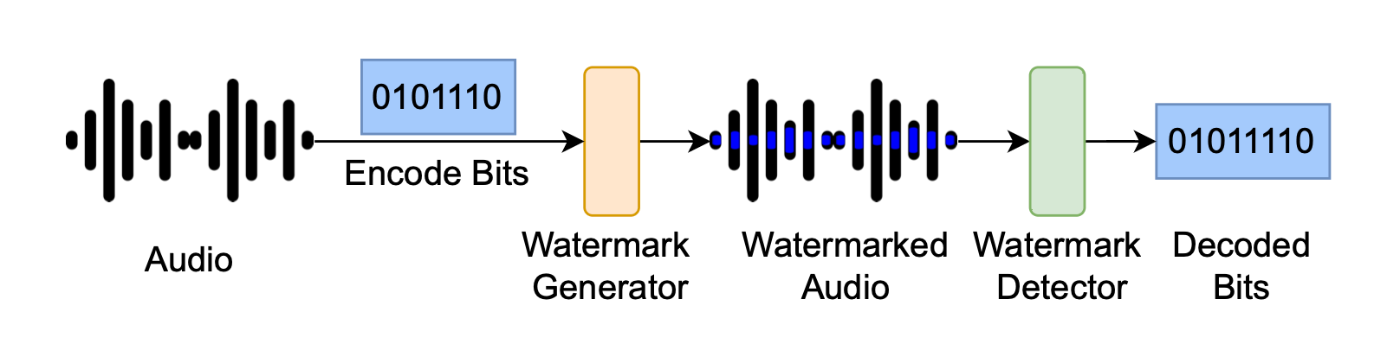
図1: [2] SoK: How Robust is Audio Watermarking in Generative AI models? より引用
代表的な手法
電子透かしの埋め込み方式は、「空間領域」と「周波数領域」に大別されます。ただし「空間領域」という考え方は、2次元信号を持つ画像データの場合に用いられます。オーディオデータは時間に沿って波形が変化する1次元信号であるため、空間よりも時間に焦点が当てられることから、ここでは「時間領域」として捉えます。したがって、オーディオデータに対する電子透かしの埋め込み方式は、「時間領域」と「周波数領域」に大別されます。
-
時間領域
- 生のデータに直接修正を加えることで透かしを埋め込む方法。最も単純な時間領域の透かし埋め込みの手法としては、音信号の最小符号ビットを電子透かしビットとして置き換える「LSB (Least Significant Bit)」がある。他にも、弱いエコーを追加する「Echo ベースの手法」や、フレームにおけるエネルギーのピーク位置を僅かにずらす「Time-aligned ベースの手法」などがある。
-
周波数領域
- 生のデータにDCT(離散コサイン変換)・FFT(高速フーリエ変換)・DWT(離散ウェーブレット変換)などの信号変換処理を適用したのち、変換後の係数(成分)に対して透かしを埋め込む方法。圧縮やノイズに対する頑健性が高く人間が知覚しない部分に埋め込むといった調整が可能である一方で、処理がやや複雑という特徴がある。
-
ハイブリッド型
- 時間領域と周波数領域の両者を用いる方法。
周波数領域の代表的な手法として以下のようなものがあります。
-
スペクトラム拡散法
- 透かしビットを暗号鍵に基づくPN系列(擬似雑音系列)で拡散し、それをDCTなどで変換した音信号に埋め込む方法。
- [1, 0, 1]のようなビット系列を[+1, -1, 0, 0, +1, -1]と変換するように、決まった鍵パターン(乱数シード)を用いて拡散することによって、局所的な破壊の影響を低減することができる。
-
パッチワーク法
- DCTなどを用いて変換した周波数領域のデータを、暗号鍵を用いたPN乱数を用いて2つの集合をランダムに抽出し、一方を僅かに増幅しもう一方を同じ量だけ減衰させて「平均の差」という統計量を作り出し、この差を検出の目印とする方法。
-
量子インデックス変調法
- DCTなどを用いて変換した周波数領域のデータに対し、量子化間隔
\Delta c' = Q_b(c)=\Delta\lfloor{\frac{c}{\Delta}}\rfloor + \frac{\Delta}{2}b
- DCTなどを用いて変換した周波数領域のデータに対し、量子化間隔
ディープラーニングの応用について
ニューラルネットワークを用いた電子透かし
ニューラルネットワークを用いた電子透かしは古くから提案されていますが、現在の主流となっているエンドツーエンドなアーキテクチャについては、音声分野よりも画像分野で進んでおり、2018年の [3] HiDDeN: Hiding Data With Deep Networks という論文において初めて Encoder - Noise - Decoder という構成が提案されました。これが後にエンドツーエンドな電子透かし埋め込み技術の基盤として利用されることになります。本論文の提案手法は以下のような形です。まずエンコーダで元画像にメッセージを埋め込み、ノイズを加えてからメッセージを抽出する構成となっています。損失は3つから構成されます。1つ目は元画像と埋め込み画像の差分、2つ目は敵対的判別器による検出誤差、3つ目は入力メッセージと抽出メッセージの差分です。これらを同時に最適化することで、元の画像に視覚的変化を与えずに情報を隠して埋め込むように学習されます。

図2: [3] HiDDeN: Hiding Data With Deep Networks より引用
音声信号におけるエンドツーエンドな深層ニューラルネットアーキテクチャの利用は、画像からやや遅れて2022年の [4] Robust speech watermarking by a jointly trained embedder and detector using a DNN で提案されたと言われています。こちらも埋め込み器と検出器の2つのニューラルネットワークで構成されており、これらが同時に学習されます。実験ではSTFT(短時間フーリエ変換)を適用したデータを入力する方法と、生の音声データを入力する方法の2つを実験したと述べられています。また、EncoderとDecoderの間には、[3] でのNoise層のようにAttack Layerという層があります。こちらには透かしに対する攻撃(実環境で起こる変換処理)を想定した処理が実装されます。この層の目的は、電子透かしを除去するような攻撃を模した学習を行うことで、透かしが除去されないような埋め込み方法を最適化するという点にあります。したがって、このようなエンドツーエンドの構成は、予め想定された攻撃に対しては頑健な埋め込みを可能とする利点があります。(本論文の実装ソースコードはこちらに掲載されているようです。)
オーディオデータにおける電子透かしのシステムデザイン
ここでは、オーディオデータにおける電子透かしの手法を体系的に整理します。[2] SoK: How Robust is Audio Watermarking in Generative AI models? では、現在のオーディオデータにおける電子透かしのシステムデザインを以下のように図解しています。大枠は上述したEncoder - Noise - Decoderの構成となっており、左の緑枠が透かしの埋め込み層、緑枠内の赤枠が攻撃層、右の青枠が透かしの検出層を表しています。透かしの埋め込みは次の5つの要素で構成されています。
- Bits Embedder:透かしビット列を高次元ベクトルへと写像し音特徴と結合しやすい形式に変換する役割を持つ。
- Feature Embedder:元のオーディオデータから周波数領域に変換するといった特徴抽出をする役割を持つ。
- Feature Combinator:ビット表現と音特徴を結合する役割を持つ。
- Watermark Embedder:実際にどの部分にどのくらい埋め込むかを学習する役割を持つ。
- Distortion Layers:起こりうる攻撃(圧縮やフィルタリング)を想定した処理を加える役割を持つ。
また、図の右側では透かし検出の役割を持つWatermark Extractorの他に、最適化する指標をOptimization Goals、堅牢性の評価をRobustness Evaluation、知覚忠実性をFidelity Evaluationとして、各構成要素が記載されています。現在のオーディオデータの透かし技術の多くは、これらの要素の組み合わせで構成されています。

図3: [2] SoK: How Robust is Audio Watermarking in Generative AI models? より引用
さらに本論文では、著作権を持つコンテンツが許可なく生成モデルに学習された場合に不正検知するための方法として、以下の2つの透かし利用方法があると述べています。図4の(a)は、生成モデルによって生成されたコンテンツに対して透かしを埋め込み、それを検出器で検出する方法を表しています。これはシンプルな方法ですが大きな問題があります。それは、生成コンテンツに対して必ず透かしを埋め込むために、生成モデル自体に透かし埋め込み用のアーキテクチャを加える必要があることです。実際には、あらゆる生成モデルに対してそれを適用するのは現実的に難しいという問題があります。次に図4の(b)は、元データに透かしを埋め込んでから生成モデルに学習をさせ、生成されたコンテンツから透かしを検出する方法を表しています。元々の著作物に透かしを埋め込んでから公開や配布をすることができるため、透かしの利用イメージとしてはこちらの方が現実的であることがわかります。一方でこの方法の場合、透かしの埋め込みに協力してもらう必要があることや、一度生成モデルの学習という処理を通すため透かしが除去されないように強い頑健性が求められるという点に難しさがあります。

図4: [2] SoK: How Robust is Audio Watermarking in Generative AI models? より引用
代表的な手法
ここからはニューラルネットワークを用いたオーディオデータにおける電子透かしの手法について、アーキテクチャや技術的な要点に注目して紹介していきます。詳細な工夫や実験結果については割愛します。
[5] DeAR: A Deep-learning-based Audio Re-recording Resilient Watermarking
- 既存手法が音声再録音(AR)による電子透かしの除去に対して脆弱であることに課題を提起する。
- アーキテクチャ
- Encoder - Distortion Layer - Decoderで構成される。

図5: [5] DeAR: A Deep-learning-based Audio Re-recording Resilient Watermarking より引用
- Encoder - Distortion Layer - Decoderで構成される。
- 技術要点
- 畳み込みニューラルネットワークを用いたエンドツーエンドの学習プロセスによる埋め込み頻度の自動探索を行う。
- 音声再録音(AR)に対するロバスト性を実現するためにDistortion Layerで歪みを再現する層を設計している。
[6] WavMark: Watermarking for Audio Generation
- 実装コード:https://github.com/wavmark/wavmark
- 既存のDNNベースの手法と比較して、高い知覚忠実性・頑健性・軽量性を示したと述べられている。
- アーキテクチャ
- Encoder - Shift Module - Attack Simulator - Decoderで構成される。
- パラメータ数:32bpsのモデルで2.5M
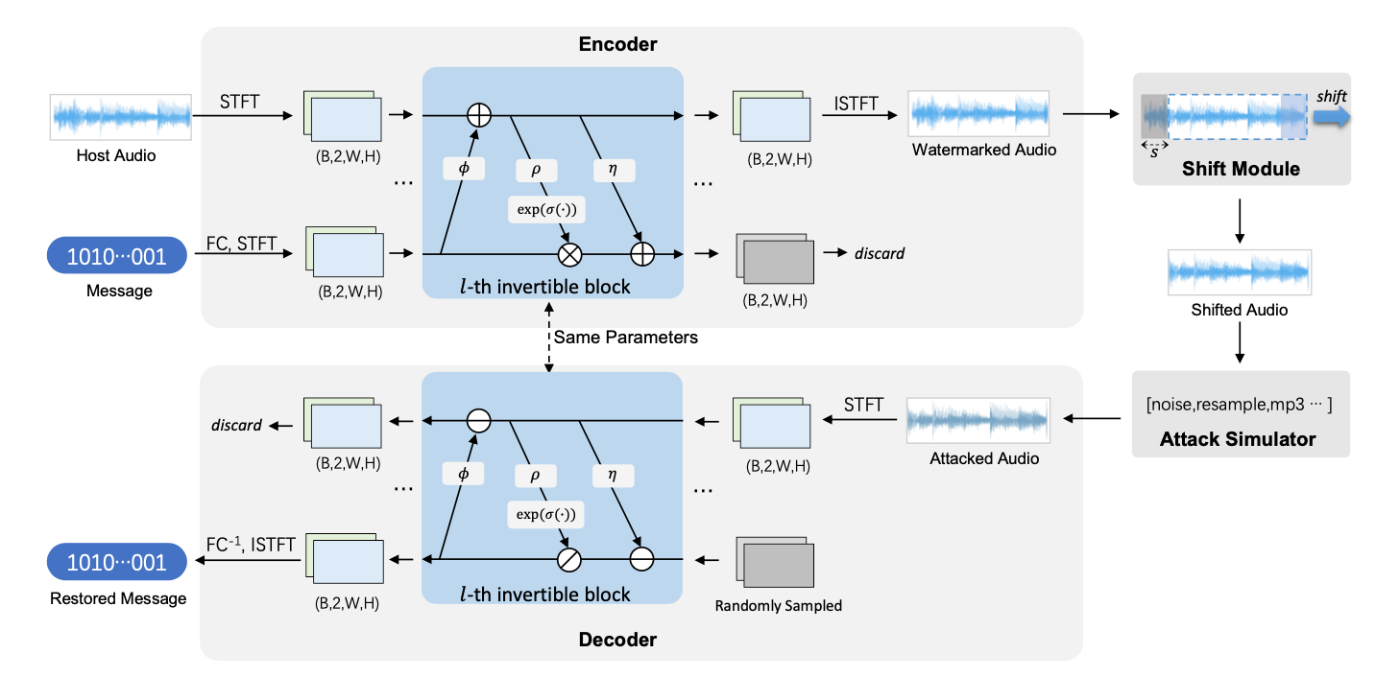
図6: [6] WavMark: Watermarking for Audio Generation より引用
- 技術要点
- 可逆ニューラルネットワークを利用し、エンコーダとデコーダで同じパラメータを共有する。
- カリキュラム学習、重み付き攻撃処理、反復エンコーディングなどの様々な学習戦略を適用する。
- カリキュラム学習は3つの段階に学習を分けている。1段階目では攻撃シミュレーターを除外し知覚忠実性に弱い制約を課して学習する。2段階目では攻撃シミュレータを導入する。3段階目では攻撃シミュレータに加え知覚忠実性に強い制約をかけて学習する。
- 重み付き学習では、攻撃に対しての結果から学習難易度が高いものに高いサンプリングの重みを割り当てて学習する。
- 反復エンコーディングでは同じ32ビットの透かしを繰り返し埋め込む。このうち10ビットを位置特定のためのパターンビットに、22ビットをペイロードとして埋め込む。検出はBFD法(Brute Force Detection)を用いて、音声全体をスライドしながら複合してもっともらしい場所を検出する。
[7] Detecting Voice Cloning Attacks via Timbre Watermarking
- 実装コード:https://github.com/TimbreWatermarking/TimbreWatermarking
- 音声クローニングによるなりすましの防止を目的とした電子透かし手法の提案。主にTTS(Text to Speech)モデルを用いた音声クローニング攻撃に焦点を当てる。
- [2]の実験で最も頑健であったと報告された手法。
- アーキテクチャ
- Watermark Embedding - Distortion Layer - Watermark Extracting で構成される。
- Embeddingには透かしビットを処理するWatermark Encoderや、音声特徴を抽出するCarrier Encoderが含まれる。

図7: [7] Detecting Voice Cloning Attacks via Timbre Watermarking
- 技術要点
- 音声全体ではなく声質そのもの(timbre)に焦点を当てたモデル。
- STFT(短時間フーリエ変換)による周波数領域への埋め込みと、埋め込み時間方向のサイズに合わせて繰り返すことによってロバスト性を強化する。また、透かし抽出時には平均化で復元する。
- 一般的な音声クローニング戦略を調査し、スケール修正・正規化・位相情報破棄・波形再構成などの処理をDistortion Layerに構築して学習させる。
[8] Proactive Detection of Voice Cloning with Localized Watermarking
- 実装コード:https://github.com/facebookresearch/audioseal
- 生成モデルによる生成コンテンツの判別が困難であるという課題に対して電子透かし手法を提案する。既存手法に対しては、非透かし音声に対する誤検出率が高いこと、局所的検出ができないことなどを課題として取り上げる。
- AudioSealという手法を提案。
- アーキテクチャ
- Generator は Encoder - (Optional Message Embeddings) - Decoder で構成され、Detector は Encoderで構成される。
- Encoderは畳み込み層やLSTMから構成される。

図8: [8] Proactive Detection of Voice Cloning with Localized Watermarking より引用

図9: [8] Proactive Detection of Voice Cloning with Localized Watermarking より引用
- 技術要点
- 局所的なサンプルレベル(1/16k秒)の解像度での透かし検出を可能とする。透かし埋め込みに対してマスクを適用することによって、部分的な透かしの有無を検出することを学習する。
- 既存のモデルを大幅に上回る検出速度を達成。また、聴覚マスキングに着想を得た新しい損失関数により既存手法よりも高い知覚忠実性を実現する。具体的には、各区間の元音声と透かしあり音声の差分を計算する際に、差分をsoftmaxで重みづけすることで、大きな違いが出た領域にペナルティを与える手法。
- 非透かし音声も学習に加えることで誤検出率を改善。
[9] IDEAW: Robust Neural Audio Watermarking with Invertible Dual-Embedding
- 実装コード:https://github.com/PecholaL/IDEAW
- 既存手法で課題となっている透かしの位置特定に焦点を当て、二重埋め込み型電子透かしモデルを設計する。
- アーキテクチャ
- Embedder - Attack Layer - Balance Block - Extractorで構成される。
- 埋め込み後に識別器(Discriminator)を用いて知覚損失を計算して学習に用いる。
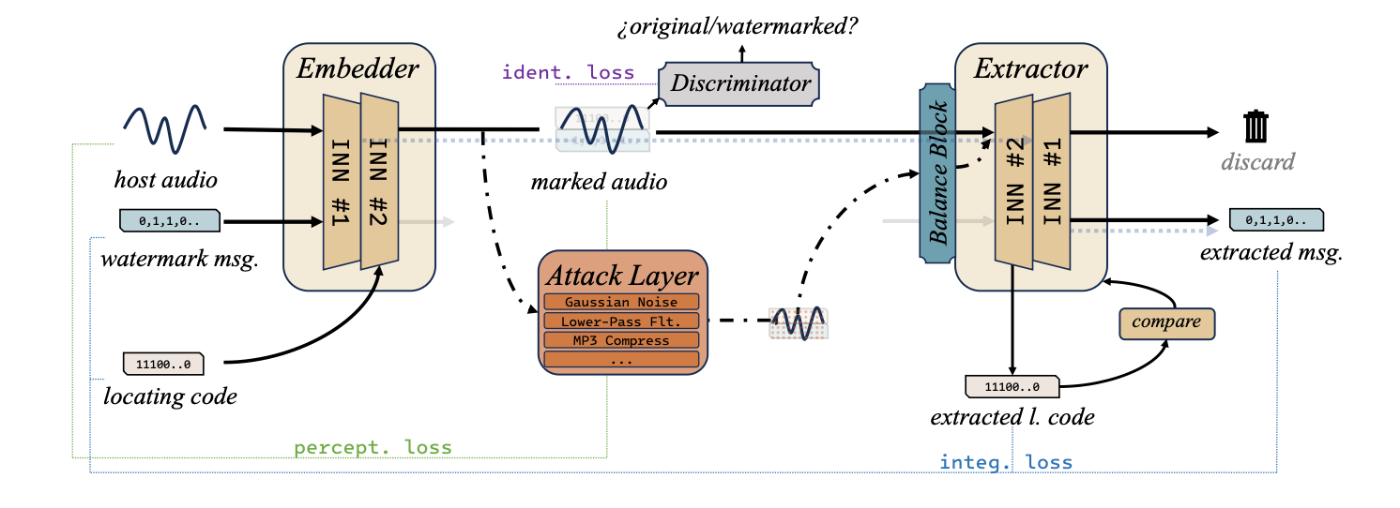
図10: [9] IDEAW: Robust Neural Audio Watermarking with Invertible Dual-Embedding より引用

図11: [9] IDEAW: Robust Neural Audio Watermarking with Invertible Dual-Embedding より引用
- 技術要点
- 電子透かしの同期コード(位置を特定する要素)とメッセージ(実際に埋め込みたい情報)を別々に埋め込むDual Embeddingを設計することによって、位置特定プロセスを高速化する。
- 可逆ネットワーク間においてエンコーダの出力とデコーダの入力のデータに攻撃層を挟むことによって分布の歪みが生じるため、これを緩和して可逆ネットワークを適切に機能させるために補正器であるバランスブロックを導入。
- 第1段階では知覚忠実性を保った透かしの埋め込みと抽出を目指し、第2段階では攻撃層とバランスブロックを加えて全体を学習するという、2段階の学習戦略を採用。
[10] MASKMARK: ROBUST NEURAL WATERMARKING FOR REAL AND SYNTHETIC SPEECH
- 比較対象とする [4] や [5] などの既存手法が、限られた変換にのみ有効であることや知覚忠実性が十分ではないことを課題として述べる。
- アーキテクチャ
- Embedder - Transform - Detectorの構成。
- Transformは他論文でのAttack Layerと同様の役割である。
- EmbedderにおけるConformer層はCNN+Transformerのハイブリッドで構成される。
- パラメータ数:Embedderが14.3M、Detectorが5.1M

図12: [10] MASKMARK: ROBUST NEURAL WATERMARKING FOR REAL AND SYNTHETIC SPEECH より引用
- 技術要点
- 透かしの埋め込み時に、各周波数ごとに乗算でマスキングを行うスペクトログラムマスクを導入。これによって無音領域にノイズを埋め込むのを防ぎ知覚忠実性を高める。
- [4] で使用されるn=6ではなくn=64のランダムな透かしキーのセットを利用することで、検出器がキーセットに過学習することを防ぐ。
[11] VoiceMark: Zero-Shot Voice Cloning-Resistant Watermarking Approach Leveraging Speaker-Specific Latents
- モデル公開先:https://huggingface.co/spaces/haiyunli/VoiceMark
- 既存手法は透かしが埋め込まれた音声が生成モデルで学習されるという前提を置いていたが、これらの手法は学習によって透かしを埋め込むことができないゼロショット音声合成モデルに対しては無効であることに課題を提起している。
- ゼロショットの音声合成モデルに対して、透かし入りプロンプトを入力することで、生成された音声に透かしが保持できる仕組みを提案する。
- アーキテクチャ
- 埋め込み器は Encoder - RVQ - Embedder - Decoder の構成。検出器はEncoder - Decoderの構成。

図13: [11] VoiceMark: Zero-Shot Voice Cloning-Resistant Watermarking Approach Leveraging Speaker-Specific Latents より引用
- 埋め込み器は Encoder - RVQ - Embedder - Decoder の構成。検出器はEncoder - Decoderの構成。
- 技術要点
- ゼロショットの推論時に使われるプロンプト音声のみで透かしが合成音声(クローン音声)に保持される。
- 事前に学習された残差ベクトル量子化モデルを利用して、話者固有の潜在表現に透かしを埋め込み、推論中に透過的に転送される。これによってゼロショット音声合成に対しても高い透かし検出率が期待される。
- 検出器の出力は透かしビットの正確性とフレームごとの透かしの存在有無であり、それぞれ損失として計算される。
- 実際のゼロショット音声合成モデルを使う代わりに「VCシミュレーション」という仕組みを用いて、ゼロショット生成モデルのような音声変換や歪みを模した処理を学習に組み込む。
- いくつかの生成モデルで実験を行い、既存手法では透かしの検出が50%程度であったのに対して、提案手法では95%の検出精度を達成した。
今後の動向
電子透かしの技術動向
[12] Deep Audio Watermarks are Shallow: Limitations of Post-Hoc Watermarking Techniques for Speech では、既存の音声透かし技術における脆弱性を述べています。本研究では、[6] [7] [10] を含む5種類のニューラルネットワークベースの音声透かし手法を用いて、合計26種類の音声変換を施した際の透かしの頑健性を評価しています。この実験の結果、特にニューラルネットワークを用いた音声変換の処理に対して、透かしの検出率がほぼゼロまで下がったと述べられています。この理由は次のように考察されています。
既存の音声透かし埋め込み手法では知覚忠実性を保つために、元の音声の浅い情報にしか干渉することができず、いわゆるノイズのような状態となっています。以下の図はグレーが元の音声の波形で、各色が手法ごとの埋め込み後の音声との差分を示しています。
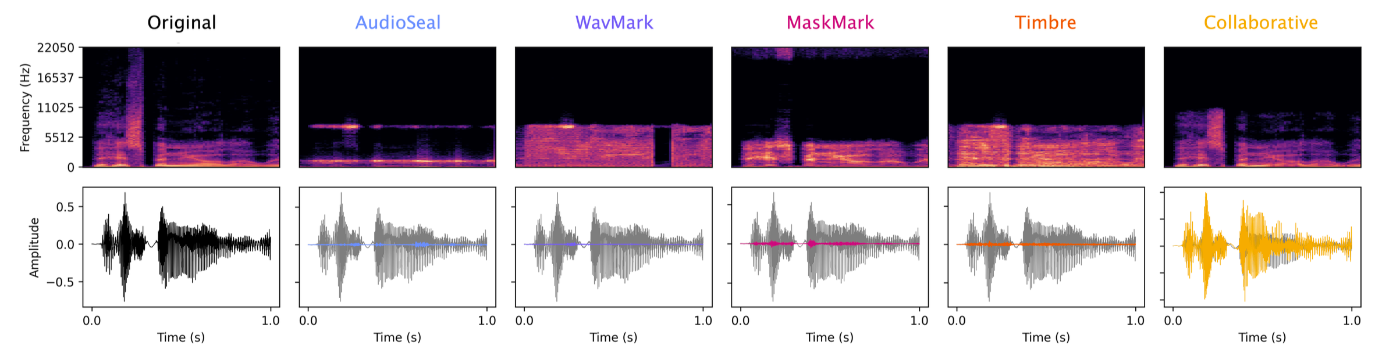
図14: [12] Deep Audio Watermarks are Shallow: Limitations of Post-Hoc Watermarking Techniques for Speech より引用
ニューラルネットワークを用いた変換手法、例えばニューラルコーデックは、元の音声を一度低次元の特徴に圧縮しそこから音声を再構成するという仕組みです。この変換処理の際に、透かしとして埋め込んだ小さな情報量は次元圧縮の過程で除去されている可能性が高いと考えられています。他にもニューラルネットワークを用いたデノイザーでは、元の音声からノイズ成分を推定して除去するため、変換の過程でノイズとともに透かし情報も除去されてしまうと考えられます。したがって、既存手法はニューラルネットワークを用いた変換技術に対して十分な堅牢性を持っていないということが示唆されます。また、このようなニューラルネットワークを用いた変換処理で透かし除去を行う際には、透かし技術としてどのモデルや手法が使われていたかを知っている必要はなく、さらに言えば透かし技術に対する専門的な知識を持たずとも、容易に透かしの除去ができると考えられます。意図的であるかどうかに関わらず、単に圧縮やノイズ除去をした際にいつの間にか透かしが除去されてしまう可能性は、実用的な観点でも課題であると言えます。
本論文の著者らは既存の電子透かし手法が無意味なものであるとは述べておらず、一定の抑止力として機能するものであることを主張しています。ただし、それに加えて、研究者たちは上述したようなシンプルかつ広範に利用できる強力な透かし除去の方法があることを考慮し、提案手法の堅牢性において適切な評価をするべきであるとも述べています。
業界の動向
テキストや画像などの生成モデルを提供するOpenAIは、こちらのブログにて、デジタルコンテンツの出所を確かめられるようにするため、標準規格づくりへの参画と技術開発を進めていると述べています。標準規格づくりにおいては、デジタルコンテンツの出所や編集履歴を証明するための国際的な標準仕様を策定する団体であるC2PAへ参画しています。技術開発においては、透かしを用いる方法とメタデータを用いる方法の両方を研究しており、音声については以下のように、OpenAIのカスタム音声モデルであるVoice Engineに透かしの技術を組み込む研究を進めていると述べています。
In addition, we’ve also incorporated audio watermarking into Voice Engine, our custom voice model, which is currently in a limited research preview. We are committed to continuing our research in these areas to ensure that our advancements in audio technologies are equally transparent and secure.
終わりに
本記事では、オーディオデータにおける電子透かし技術、とりわけニューラルネットワークを用いた透かし埋め込みと検出の手法について紹介しました。これらの手法の多くは、周波数変換した信号に透かしビットを埋め込むエンコーダ、データ圧縮などの実環境を模した攻撃(歪み)層、そして透かしビットを抽出するデコーダの3つのブロックで構成されます。様々な手法が提案され続けている一方で、最新研究 [12] では依然としてニューラルネットワークを用いた変換処理に対する検出率が低く、十分な頑健性が確立されていないことが指摘されています。OpenAIも透かし技術はなお研究段階にあると述べており、実用化には越えるべき課題が多いと考えられます。とはいえ、ディープフェイクなどの偽情報が急速に拡散する現在、コンテンツの真正性や著作権を守る技術の重要性はますます高まっていると言えるでしょう。オーディオデータに限らず、デジタルコンテンツの信頼性を支える技術の進展に、今後も注目していきたいと思います。
参考
- [1] UDDIN, Mohammad Shorif, et al. Audio Watermarking: A Comprehensive Review. International Journal of Advanced Computer Science & Applications, 2024, 15.5.
- [2] WEN, Yizhu, et al. SoK: How Robust is Audio Watermarking in Generative AI models?. arXiv preprint arXiv:2503.19176, 2025.
- [3] ZHU, Jiren, et al. Hidden: Hiding data with deep networks. In: Proceedings of the European conference on computer vision (ECCV). 2018. p. 657-672.
- [4] PAVLOVIĆ, Kosta, et al. Robust speech watermarking by a jointly trained embedder and detector using a DNN. Digital Signal Processing, 2022, 122: 103381.
- [5] LIU, Chang, et al. Dear: A deep-learning-based audio re-recording resilient watermarking. In: Proceedings of the AAAI Conference on Artificial Intelligence. 2023. p. 13201-13209.
- [6] CHEN, Guangyu, et al. Wavmark: Watermarking for audio generation. arXiv preprint arXiv:2308.12770, 2023.
- [7] LIU, Chang, et al. Detecting voice cloning attacks via timbre watermarking. arXiv preprint arXiv:2312.03410, 2023.
- [8] ROMAN, Robin San, et al. Proactive detection of voice cloning with localized watermarking. arXiv preprint arXiv:2401.17264, 2024.
- [9] LI, Pengcheng, et al. IDEAW: Robust neural audio watermarking with invertible dual-embedding. arXiv preprint arXiv:2409.19627, 2024.
- [10] O’REILLY, Patrick, et al. Maskmark: Robust neuralwatermarking for real and synthetic speech. In: ICASSP 2024-2024 IEEE International Conference on Acoustics, Speech and Signal Processing (ICASSP). IEEE, 2024. p. 4650-4654.
- [11] LI, Haiyun, et al. VoiceMark: Zero-Shot Voice Cloning-Resistant Watermarking Approach Leveraging Speaker-Specific Latents. arXiv preprint arXiv:2505.21568, 2025.
- [12] O'REILLY, Patrick, et al. Deep Audio Watermarks are Shallow: Limitations of Post-Hoc Watermarking Techniques for Speech. arXiv preprint arXiv:2504.10782, 2025.

Discussion