はじめに
データソリューション事業部の宮澤です。
今回は、ログ取得のためのPythonライブラリである logging, 実験管理ツールである Wandb, CLI構築ツールである tyro を用いて、簡単に始められる実験管理の方法を紹介します。Wandbについては11月にリリースされた W&B LEET も使ってみました。また、タイトルで「軽量な」と述べているのは、本記事ではマルチノードを使うような大規模な実験や大量の設定を並列で回すような実験を想定しておらず、個人レベルで簡単に始められる実験を想定しているためです。
本記事はDAL Tech Blog Advent Calendar 2025として投稿しました。全ての記事は以下からご確認いただけます。
AIエンジニアリング入門シリーズ
| カテゴリ | 記事 |
|---|---|
| 開発の基礎 | Pythonによる開発の基礎(uv, Ruff, dataclass, Pyright, Git hooks) |
| 実験管理 | logging, Wandb, tyroで始める軽量な実験管理(本記事) |
本記事の目的
本記事では、画像データを用いた分類モデル学習の実験管理を題材にして各ツールについて紹介します。こちらの記事によって、読者の方が機械学習モデルの実験管理を始められるようサポートすることを目的としています。
サンプルのテンプレートをGitHubリポジトリに公開します。題材である画像分類モデルの学習までしかコードを記述していませんが、追記やカスタムをすれば便利にお使いいただけるかと思います。
本記事の概要
本記事では「実験管理」という大きなテーマに関連して、いくつかのツールやそれらの役割を紹介するため、まずは全体像をお伝えしておきます。主に紹介するツール/ライブラリはlogging, wandb, tyroですが、これらが実験管理にどのように役立っているのかを整理したのが以下の図です。紹介順とは異なりますが、tyroを使って実験設定をCLIに反映し、実行中のログをloggingで記録し、学習推移をWandbで監視する、といった役割分担になっています。

以降の内容は上記の図をイメージした状態でお読みいただければ幸いです。
環境
今回は、Google CloudのVertex AI Workbenchでインスタンスを作成しました。Vertex AI Workbenchで作成するインスタンスはDeep Learning VMであり、Python, GPUドライバ, CUDA Toolkitなどが予めインストールされています。数クリックで簡単にGPU付きのVMを立てることができるため、非常に便利です。
インスタンスの詳細は以下の通りです。
- OS: Debian 11
- GPU Driver: 550.90.07
- CUDA Version: 12.4
- CUDA Toolkit: 11.8
Pythonのパッケージは uv でインストール・管理します。
実験概要
利用するデータセット
今回サンプルとして利用するのは以下のデータセットです。植物ごとの葉の画像があり、病変有無などのラベルがあります。今回は簡単のためにフォルダ名をクラス名にした分類モデルの学習をしたいと思います。
ディレクトリ構成
実験管理の詳細に入る前にディレクトリの全体像を説明します。ここではプロジェクト名はworkspaceとしています(テンプレートリポジトリではml-exp-templateになっています)。
以下のlogsやdatasetsには例となるファイル名を記載しています。また、今回は学習部分のみ実装してあり、推論のみは実装していないため、サンプルファイルだけを配置しています。
workspace/
├── README.md
├── pyproject.toml
├── uv.lock
├── .python-version
├── .gitignore
├── .venv
├── logs/
│ └── exp_001/
│ └── 20251204_060842.log
├── outputs
│ └── exp_001/
│ └── sample_output.csv
├── models/
│ └── exp001/
│ └── fold_0/
│ └── best_model.pth
├── datasets/
│ └── Plant_leave_diseases_dataset_without_augmentation/
│ └── Apple___Apple_scab/
│ └── image (1).JPG
├── notebooks/
│ └── eda_sample.ipynb/
├── src/
│ ├── config.py
│ ├── data/
│ │ ├── __init__.py
│ │ ├── dataset.py
│ │ └── splits.py
│ ├── model/
│ │ ├── __init__.py
│ │ └── create_model.py
│ ├── training/
│ │ ├── __init__.py
│ │ ├── optimizer.py
│ │ └── train_loop.py
│ ├── inference/
│ │ └── infer_sample.py
│ └── utils/
│ ├── logger.py
│ ├── seed.py
│ └── wandb_utils.py
├── scripts/
├── setup_directories.py
├── prepare_dataset.py
├── train.py
└── infer.py
以下でそれぞれの機能を簡単に説明します。
uv関連
pyproject.tomlやuv.lockはuvの環境が記載されたファイルです。uvをインストールしてuv sync --frozenとコマンドを打てば同じ環境(Pythonパッケージ)を再現することができます。
logs
こちらはログファイル(.log)を格納するためのディレクトリです。後述しますが、実験IDごとにディレクトリを分けて、("%Y%m%d_%H%M%S")の名称でファイルを作成して保存するようにしています。
outputs
こちらは推論結果などアウトプットを格納するためのディレクトリです。テンプレートでは特に何か出力する実装はしていませんが、例えばテストデータへの推論結果(.csvなど)を保存するといった形で利用することを想定しています。
models
こちらはモデルの重みを格納するためのディレクトリです。事前学習済みのモデルや学習したモデルの重みを保存します。テンプレートの実装では実験IDごとかつfoldごとにモデルのvaidation評価が最も高いepochの重みを保存するようにしています。
datasets
こちらはデータを格納するためのディレクトリです。生データや加工したデータを保存することを想定しています。
src
こちらは実装コードを格納するためのディレクトリです。各種設定を記載したconfig.pyをはじめ、機能ごとにディレクトリを分けてPythonファイルを格納しています。
scripts
こちらはsrc/のモジュールを呼び出して学習を回したり推論を回したりするスクリプトを格納するためのディレクトリです。テンプレートでは推論部分については特に実装していません。
実験管理
ここからは実験管理に用いるツールや使い方を紹介します。
1. 実験設定の管理
実験設定はsrc/config.pyに全て記載するようにしています。Python標準ライブラリであるdataclassesを用いて型ヒントを与えています。dataclassを使う理由としては、後に説明するtyroとの相性がよいからです。(詳細は後述します。)
2. ログの記録
ログはPythonの標準ライブラリである logging を用いています。
loggingは、特定のイベントが発生したことを示すコードを記載することで、簡単にログを記録できるライブラリです。ログのレベルを指定することができ、どのレベル以上の時にログを記録するかを設定することができます。テンプレートの実装ではsrc/utils/logger.pyにコードを書いています。
まずログファイルを作成するコードを書いています。どの実験かわかるように該当の実験IDをディレクトリ名にして、さらにいつ実行したかがわかるように日付と時間をファイルの名称として作成するようにしています。
def make_log_file(cfg: CFG) -> Path:
run_id = datetime.datetime.now().strftime("%Y%m%d_%H%M%S")
log_dir = cfg.paths.log_dir / cfg.common.exp_name
log_dir.mkdir(parents=True, exist_ok=True)
log_file = log_dir / f"{run_id}.log"
return log_file
次に、loggerを作成するコードを実装しています。ログレベルはlogger.setLevel(logging.INFO)でINFOに設定しています。StreamHandlerはコンソールに出力するためのハンドラで、FileHandlerは.logに書き込むためのハンドラです。
def init_logger(log_file: Path, logger_name: str = LOGGER_NAME) -> logging.Logger:
logger = logging.getLogger(logger_name)
if logger.hasHandlers():
return logger # Logger already initialized
logger.setLevel(logging.INFO)
fmt = logging.Formatter("%(message)s")
sh = logging.StreamHandler()
sh.setFormatter(fmt)
fh = logging.FileHandler(str(log_file), encoding="utf-8")
fh.setFormatter(fmt)
logger.addHandler(sh)
logger.addHandler(fh)
return logger
この他に、GPUを用いた処理の時間計測のためにtorch.cuda.Eventを用いた計測用デコレータや、CUDA memoryの占有状態を取得するための関数を記載しています。テンプレートをご参照ください。
このようにloggerを設定することで、実験を回すたびに以下のようなログファイルを取得することができます。
========== Start fold=0 ==========
----- Seed info -----
Set seed: 42
----- Task info -----
Number of classes: 39
Model: resnet18d
Starting training: fold=0, epochs=3, optimizer=adamw, scheduler=warmup_cosine
[Before training] Used: 256.2MB / total: 22478.3MB (1.14% used)
----- Epoch 1/3 (fold 0) -----
[Train] Epoch 1: Loss=0.2530, Accuracy=0.9242
[train_one_epoch] 82.480602 sec (CUDA)
[Valid] Epoch 1: Loss=0.2996, Accuracy=0.9216
[valid_one_epoch] 10.179159 sec (CUDA)
[epoch=1] train_loss=0.2530 train_acc=0.9242 val_loss=0.2996 val_acc=0.9216
Saved best model (updated): /workspace/models/exp001/fold_0/best_model.pth (epoch=1, val_loss=0.2996)
3. パラメータ・学習推移の管理
モデルのパラメータや学習の推移の確認には Wandb というツールを使います。Wandbはサインアップすればすぐに使うことができます。
まず、Wandbの初期化はsrc/utils/wandb_utils.pyに実装しています。引数について、projectはプロジェクトグループのまとまりで実験記録を管理することができるので、例えばatmaCup#18のようにプロジェクトを作っておいてそれを指定するのがよいでしょう。entityにはユーザーIDを指定します。run_nameには任意の実験IDを指定します。
modeは"online"や"offline"を指定できます。(後述します。)
def init_wandb(cfg: CFG, fold: int | None = None) -> Optional[Run]:
if not cfg.wandb.use_wandb:
return None
run_name = cfg.common.exp_name
if fold is not None:
run_name = f"{run_name}_fold{fold}"
run = wandb.init(
project=cfg.wandb.project,
entity=cfg.wandb.entity,
mode=cfg.wandb.mode,
name=run_name,
config=cfg.to_dict(),
)
return run
実際に記録したい項目は以下のように書きます。
run.log(
{
"Train/Loss": train_loss,
"Train/Accuracy": train_acc,
"Valid/Loss": val_loss,
"Valid/Accuracy": val_acc,
"lr": lr,
"epoch": epoch,
},
step=epoch,
)
Webブラウザ
modeを"online"にする場合、WandbのWeb UIで実験の記録を見ることができます。事前に環境変数WANDB_API_KEYに自身のAPIキーを設定しておく必要があります。
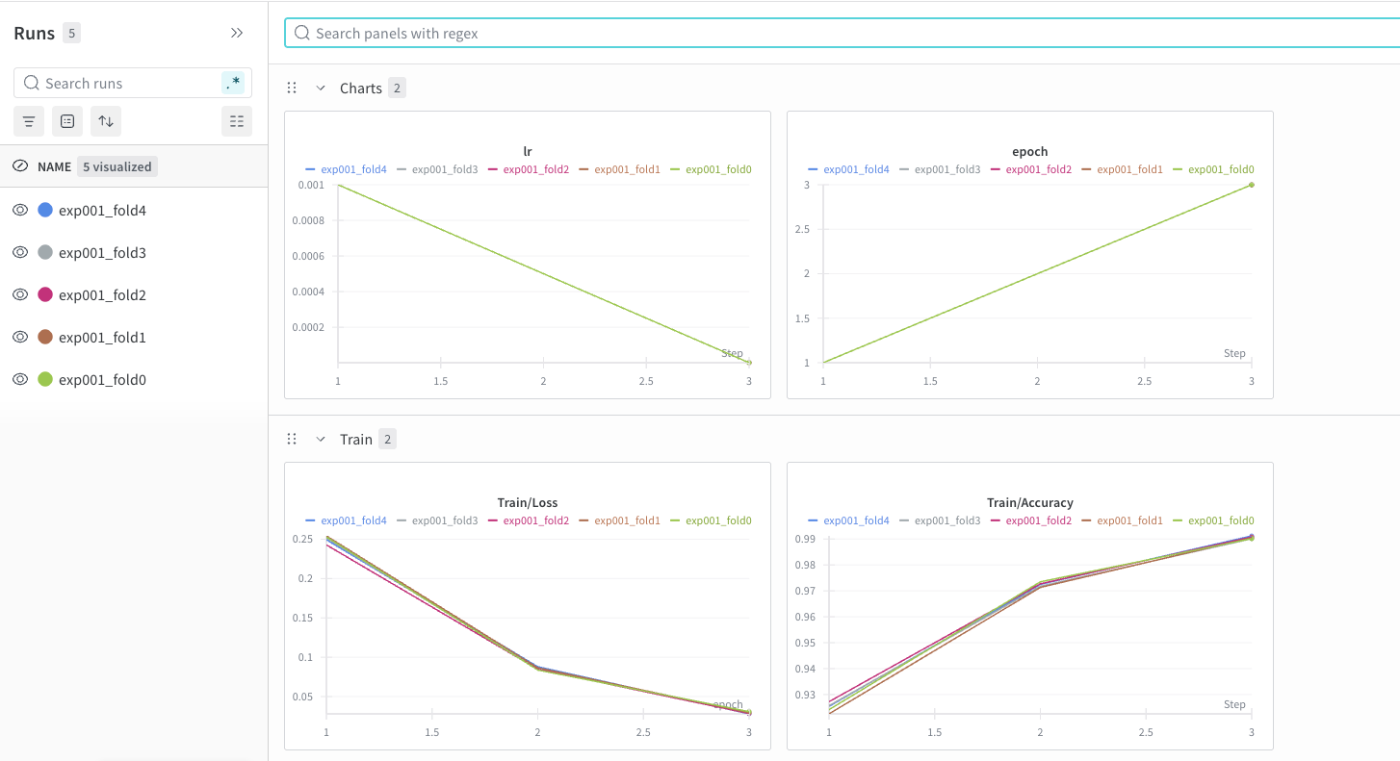
また、先ほどの初期化wandb.initでconfig=cfg.to_dict()と渡しているため、Runを開いて詳細を確認すると、以下のようにconfigで設定した項目を確認することができます。
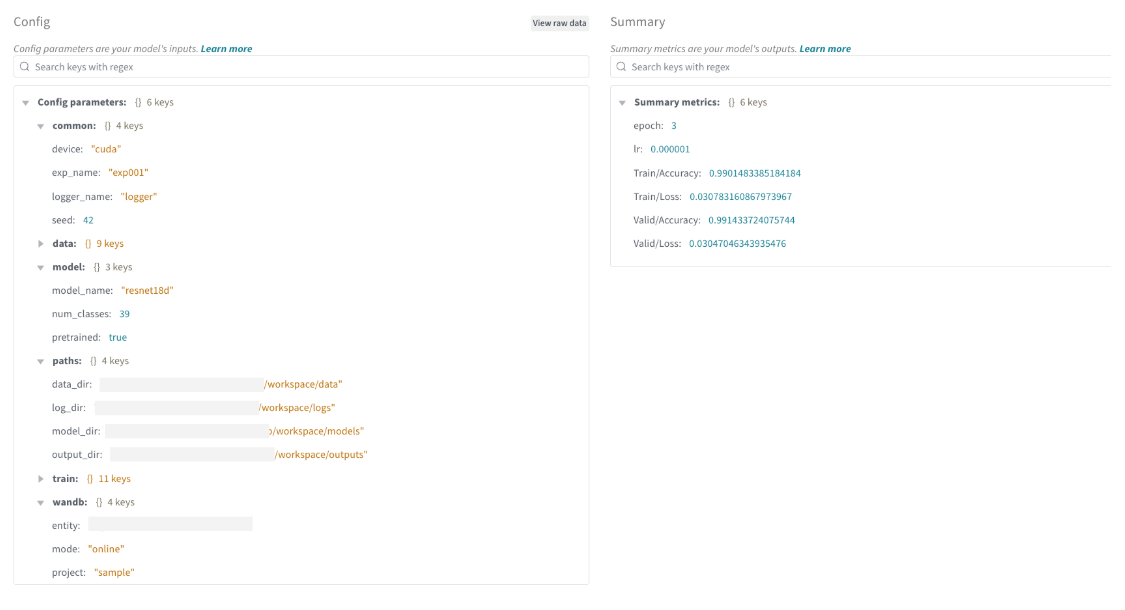
このように、Wandbは学習推移や設定を記録してわかりやすいUIで可視化・閲覧することができる便利なツールです。個人でも無料で始めることができるため、機械学習コンペでも役立ちます。
W&B LEET
上記のようなWandbのUIは非常に見やすく使い勝手がよいですが、ネックとなるのはWandbのサーバーと通信が必要であるという点です。Wandbのサーバーにデータを送信する必要があるため、企業や組織によっては内部の承認を通すといった手続きが必要であったり場合によっては利用できないこともあると考えられます。
そこで、このような実験記録をオフラインで閲覧したいというユーザーの要望に応えて11月にリリースされたのがW&B LEETです。これは、ターミナルインターフェース(オフライン)で学習の記録を追跡できる機能です。
LEETの使用方法はドキュメントに記載されています。SDKバージョンは0.23.0以上である必要があります。また、wandbを使って処理を実行するとwandbというディレクトリが作成され、そこに実験ログが保存されていきますが、これはmodeが"online"でも"offline"でも同じです。LEETはそれらのログファイルをオフラインで読み込むことでターミナルで実験結果を閲覧できるようにしているようです。
LEETの利用コマンドは以下の通りです。そのまま実行すると最新の実験ログが渡されます。
wandb beta leet
特定の実験記録を閲覧したい場合はパスを指定をします。
wandb beta leet [PATH]
コマンドを実行すると以下のような画面がターミナルに表示されます。
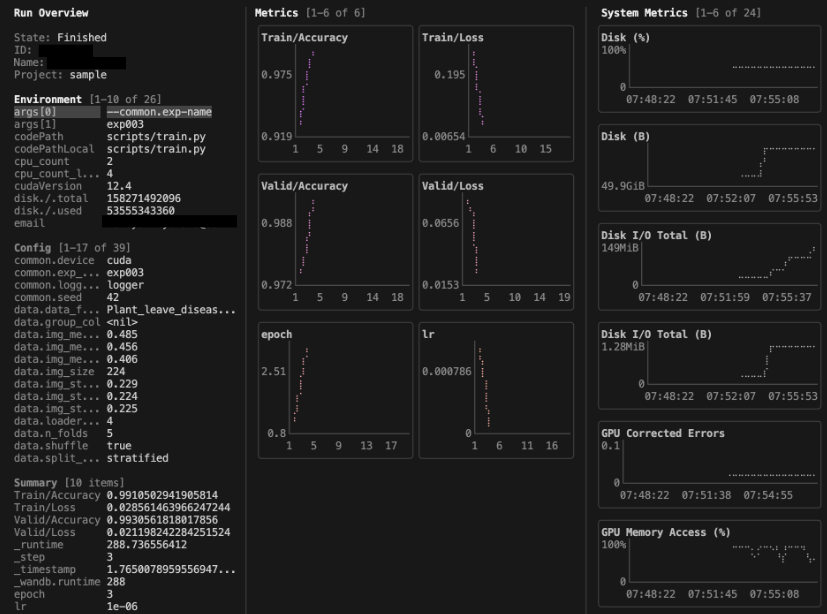
ここからドキュメントをもとに操作してみたいと思います。
実はドキュメントを直接見に行かなくても、上のターミナル画面を開いたままhを押すことでhelp画面を表示することができます。操作がわからなくなったらこれを参照しましょう。

次に、全体のパネル操作についてです。左右のウィンドウは[や]のコマンドで閉じることができるため、見やすいように操作しましょう・

次に、左の Run Overview についてです。
こちらではログに含めたconfigの設定値を一覧で確認することができます。キーボードの上下で選択されている項目を動かすことができます。ページを移動したい場合はキーボードの左右で操作できます。ブロックを移動したいときはtabを使います。また、文字列が長くて途切れてしまっている項目もありますが、選択されている項目はターミナルの最下部に表示されているため、どのような文字列かを確認することができます。

また、oを押してから任意の文字列を入力することで、表示項目にフィルタをかけることができます。ここではtrainと指定することでtrainに関連する項目を表示することができました。(ctrl + kでフィルタを解除できます。)

次に、中央の Metrics についてです。
こちらはログに含めたlossやlearining rateの推移を確認することができます。このままでは少しみづらいと思う場合は先ほど述べたように[, ]で左右のウィンドウを閉じるか、もしくはMetricsの表示列数を減らすこともできます。cを押すとPress 1-9 to set metrics grid columnsと表示されるので、1を押します。そうすると2カラムだった表示が1カラムになります。(行数も別コマンドで調整できます。)

さらに、カーソルでグラフを選択してスクロールをするとズームをすることができます。使用していて気がついた注意点として、スクロールをする位置によってズームのされる位置が異なります。ここでは0~3epochにログが集まっているため、0~1あたりの軸にカーソルを持ってきてスクロールすることで、見たい部分をズームすることができました。Web UIと比べると座標位置がずれているように見えるのが少し気になりますが、概ねの傾向を掴むことはできそうです。

こちらもRun Overviewと同じくフィルタをかけることができます。/を押して任意の文字列でフィルタをかけることができます。ここではlossに絞ってみました。(`ctrl + l'でフィルタを解除できます。)

最後に、右の System Metrics についてです。
こちらはディスクのI/OやGPU Memory Allocatedなどを確認することができます。こちらもMetrics同様にカラム数や行数を指定することができます。Metricsではc, rが調整コマンドでしたが、System Metricsの場合は大文字のC, Rになります。カラム数を1に、行数を3まで絞るとみやすくなりました。

Wandb LEETへの所感
使ってみた所感としては、まずWebブラウザを介さずにターミナル上でサッと実験結果を確認できるのは便利だと感じました。正直、グラフの見やすさであれば圧倒的にWeb UIではあるため、個人利用する場合にはWeb UIを見ることが多そうです。一方で、LEETの可視化でWeb UIより良いと感じた点としては、MetricsとConfigを同じ画面で見ることができる点です。おそらくWeb UIではチャートとconfig詳細は画面を切り替えないと見られないため、この2つを並べて見ることでどんな設定をしたかとその学習推移がどうであるかを簡単に確認できるという点ではLEETに軍配があがると感じました。Web UIを問題なく使える人は併用して、使えない人はLEETを使うという運用になるかと思います。
4. CLI構築
最後にCLI(コマンドラインインターフェース)の構築ツールである tyro を紹介します。
tyroとは、型注釈付きのPythonからCLIを生成することができるツールです。Pythonで記述した関数やdataclass, pydanticなどを用いて定義した構成をインスタンス化してCLI生成することができます。
tyroの概要
tyroの特長について説明する前に、まずどのようなことができるのかを簡単にイメージするために、ドキュメントの例をそのまま用いて基本的な利用方法を紹介します。
まず関数からCLIを生成する場合、以下のように記述します。引数に型ヒントを与えて、関数内には説明と処理を記載しています。
"""Sum two numbers by calling a function with tyro."""
import tyro
def add(a: int, b: int = 3) -> int:
"""Add two numbers together.
Args:
a: First number to add.
b: Second number to add. Defaults to 3.
"""
return a + b
# Populate the inputs of add(), call it, then return the output.
total = tyro.cli(add)
print(total)
実装した関数はコマンドラインから以下のように使用することができます。
$ python script.py --a 5
8
$ python script.py --a 5 --b 7
12
このように、tyroではPythonで記述した関数からCLIを生成することができます。以降では、tyroをさらに深掘りして、どのような特長があるかを説明していきます。
tyroの特長
ここではtyroの代表的な特長をいくつか紹介します。
シンプルな記述でCLI生成
まずはシンプルであるということがtyroの特長の一つであると言えるかと思います。例えば、先ほどの関数を argparse を使って書くと以下のようになります。tyroと比べるとコードが少し長く読みづらいと感じます。tyroでは先ほどのようによりシンプルな形で実装が可能です。
"""Sum two numbers by calling a function with argparse."""
import argparse
def add(a: int, b: int = 3) -> int:
"""Add two numbers together.
Args:
a: First number to add.
b: Second number to add. Defaults to 3.
"""
return a + b
# ---- argparse version ----
def main():
parser = argparse.ArgumentParser(description="Sum two numbers.")
parser.add_argument("--a", type=int, help="First number to add.")
parser.add_argument(
"--b", type=int, default=3, help="Second number to add. Defaults to 3."
)
args = parser.parse_args()
total = add(args.a, args.b)
print(total)
if __name__ == "__main__":
main()
可視性の高いhelpメッセージ
tyroでは、--helpで呼び出すことで、設定した引数や説明を確認することができます。先ほどの関数の例では以下のように出力されます。
$ python script.py --help
usage: script.py [-h] --a INT [--b INT]
Add two numbers together.
╭─ options ───────────────────────────────────────────────────────────╮
│ -h, --help show this help message and exit │
│ --a INT First number to add. (required) │
│ --b INT Second number to add. Defaults to 3. (default: 3) │
╰─────────────────────────────────────────────────────────────────────╯
クラスのインスタンス化とネスト構造への対応
ここまでは関数からCLIを生成する方法について説明しましたが、tyroではクラスをインスタンス化することも可能です。dataclassやpydanticで定義したクラスをインスタンス化する機能を持っています。具体的には以下のような形で記述できます。以下は今回の実験管理で設定しているconfig.pyです。
# src/config.py
from dataclasses import asdict, dataclass, field
from pathlib import Path
from typing import Literal
import torch
# PROJECT_ROOT = Path(__file__).resolve().parents[1]
PROJECT_ROOT = Path("sample_project/workspace")
@dataclass
class PathsCfg:
"""Paths configuration for the project directories."""
data_dir: Path = PROJECT_ROOT / "datasets"
"""Directory containing the dataset."""
model_dir: Path = PROJECT_ROOT / "models"
"""Directory for pretrained and trained models."""
log_dir: Path = PROJECT_ROOT / "logs"
"""Directory for storing logs."""
output_dir: Path = PROJECT_ROOT / "outputs"
"""Directory for storing output results."""
@dataclass
class CommonCfg:
"""Common configuration settings for the experiment."""
exp_name: str = "exp001"
"""Name of the experiment."""
seed: int = 42
"""Random seed for reproducibility."""
device: str = "cuda" if torch.cuda.is_available() else "cpu"
"""Device to use for training (cuda or cpu)."""
logger_name: str = "logger"
"""Name of the logger."""
@dataclass
class DataCfg:
"""Data loading and preprocessing configuration."""
data_folder: str = "Plant_leave_diseases_dataset_without_augmentation"
"""Name of the dataset folder."""
# cv
split_type: Literal["stratified", "random", "group"] = "stratified"
"""Type of cross-validation split: 'stratified', 'random', or 'group'."""
group_col: str | None = None
"""Column name for group split (used when split_type='group')."""
n_folds: int = 5
"""Number of folds for cross-validation."""
shuffle: bool = True
"""Whether to shuffle the data before splitting."""
# image
img_size: int = 224
"""Input image size (height and width)."""
img_mean: tuple = (0.485, 0.456, 0.406)
"""Mean values for image normalization (RGB channels)."""
img_std: tuple = (0.229, 0.224, 0.225)
"""Standard deviation values for image normalization (RGB channels)."""
loader_num_workers: int = 4
"""Number of worker processes for data loading."""
@dataclass
class ModelCfg:
"""Model architecture configuration."""
model_name: str = "resnet18d"
"""Name of the model architecture."""
pretrained: bool = True
"""Whether to use pretrained weights."""
num_classes: int = 39
"""Number of output classes for classification."""
@dataclass
class WandbCfg:
"""Weights & Biases logging configuration."""
use_wandb: bool = True
"""Whether to use Weights & Biases for logging."""
project: str = "sample"
"""W&B project name."""
entity: str | None = "sample_entity"
"""W&B entity (username or team name)."""
mode: Literal["online", "offline", "disabled", "shared"] = "online"
"""W&B logging mode: 'online', 'offline', 'disabled', or 'shared'."""
@dataclass
class TrainingCfg:
"""Training hyperparameters configuration."""
batch_size: int = 32
"""Batch size for training."""
shuffle: bool = True
"""Whether to shuffle the training data."""
num_epochs: int = 3
"""Number of training epochs."""
lr: float = 1e-3
"""Learning rate (alias for learning_rate)."""
# optimizer
optimizer: Literal["adam", "adamw", "sgd"] = "adamw"
"""Optimizer type: 'adam', 'adamw', or 'sgd'."""
weight_decay: float = 1e-4
"""Weight decay (L2 regularization) for the optimizer."""
momentum: float = 0.9
"""Momentum factor for SGD optimizer."""
# scheduler
scheduler: Literal["cosine", "warmup_cosine"] = "warmup_cosine"
"""Learning rate scheduler type: 'cosine' or 'warmup_cosine'."""
warmup_epochs: int = 1
"""Number of warmup epochs for the scheduler."""
eta_min: float = 1e-6
"""Minimum learning rate for cosine annealing."""
@dataclass
class CFG:
"""Main configuration class that aggregates all configuration settings."""
paths: PathsCfg = field(default_factory=PathsCfg)
"""Paths configuration."""
common: CommonCfg = field(default_factory=CommonCfg)
"""Common configuration."""
data: DataCfg = field(default_factory=DataCfg)
"""Data configuration."""
model: ModelCfg = field(default_factory=ModelCfg)
"""Model configuration."""
wandb: WandbCfg = field(default_factory=WandbCfg)
"""Weights & Biases configuration."""
train: TrainingCfg = field(default_factory=TrainingCfg)
"""Training configuration."""
def to_dict(self):
"""Convert the configuration to a dictionary."""
return asdict(self)
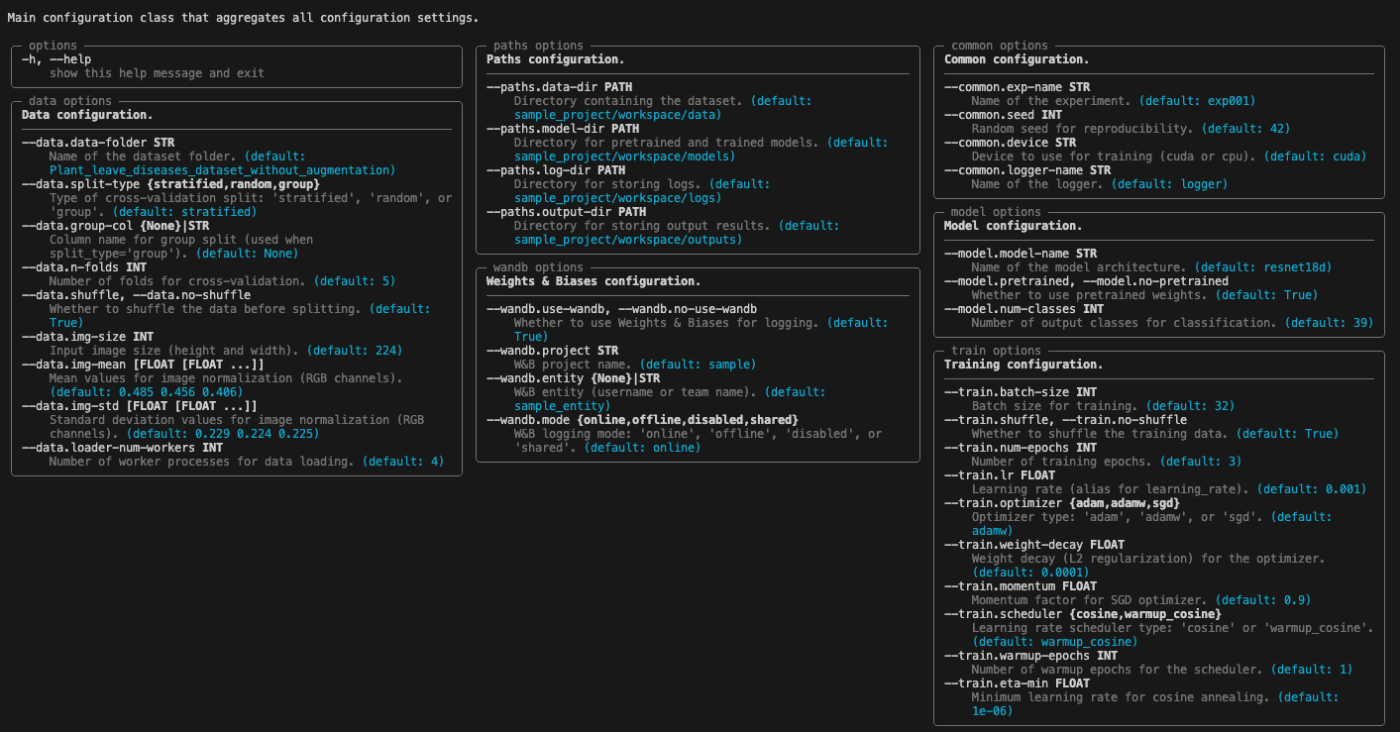
ここでは、型ヒントを使って引数を設定しているだけではなく、階層的に記述されていることがわかります。tyroはこうしたネスト化された構造にも対応しているため、--helpで確認すると、以下のように設定したクラスごとの項目を一覧で確認することができます。どんな設定をしたか、どのような型であったか、一覧でサッとみることができるのは便利です。
コマンドを実行する際は、以下のようにドットで区切って引数を与えて(デフォルトが設定されている場合は上書きして)実行することができます。
uv run scripts/train.py --wanbd.mode offline --train.lr 1e-5
型安全なCLI生成
次に、tyroが重視している「型安全」についてです。tyroは上の例で記述しているようにtypingの型をそのままCLIに反映します。
例えば、先ほどの足し算の関数で引数に指定されているintではない文字列を渡してみると、以下のようにエラー出力がされます。(script.py --a text)
╭─ Value error ───────────────────────────────────────────────────────╮
│ Error parsing --a: invalid literal for int() with base 10: 'text' │
│─────────────────────────────────────────────────────────────────────│
│ Argument helptext: │
│ --a INT │
│ First number to add. (required) │
│─────────────────────────────────────────────────────────────────────│
│ For full helptext, see script.py --help │
╰─────────────────────────────────────────────────────────────────────╯
これ自体は他のCLI生成ツールでも同じような挙動かと思いますが、tyroでは以下のようにstr, int, floatもあまり気にすることなくCLIで与えることができます。これはtyroが型ヒントに基づきCLIからの入力を正しくパースし、正しい型の値だけを関数に渡すように設計されているためです。
uv run scripts/train.py \
--wandb.project sample_project \
--train.lr 1e-5 \
--train.num-epochs 2
さらに、以下のように型ヒントを単にstrとするのではなく、Literalで選択肢を限定することによって、それ以外の値が指定されたときに即時エラーを吐くように定義することも有効です。
optimizer: Literal["adam", "adamw", "sgd"]
これは、いろいろな処理が進んだ後にこの引数のタイプミスでエラーになってそこまでの処理が無駄になってしまうような事象を防止し、処理を実行する最初の時点で引数のタイプミスに気が付くことができるということです。
また、他にもTupleやDictをそのまま渡すことができますが、これもtyroの型安全な設計がもたらす利点と言えます。
tyroの便利機能
シェル補完
tyroでは以下の設定をすることで、コマンドラインの自動補完を有効にすることができます。個人的にはこれがかなり有難い機能だと感じました。ドキュメントを見ながら試して上手くいったりいかなかったりだったのですが、私の場合は以下の流れで有効化することができました。
前提として、私の環境ではbashを使っています。
手順として、まずはじめにcompletionファイル用のディレクトリを決めます。
completion_dir=${BASH_COMPLETION_USER_DIR:-${XDG_DATA_HOME:-$HOME/.local/share}/bash-completion}/completions/
mkdir -p "$completion_dir"
自動補完を適用したいscripts/train.pyに対して、--tyro-write-completionでcompletionファイルを生成します。私の環境では、/home/User/.local/share/bash-completion/completions/train.pyが作られました。
次に以下のコマンドを実行します。
python scripts/train.py --tyro-write-completion bash "${completion_dir}/train.py"
これで補完の有効化はできているのですが、注意点としてuv runでは補完が機能しませんでした。uvの仮想環境をactiveにはするのですが、以下のようにスクリプトの実行権限を与えて、直接コマンド実行する形でないと補完が機能しませんでした。
権限付与
chmod +x scripts/train.py
シェル補完の使い方
./scripts/train.py --t [TAB] -> --train.
./scripts/train.py --w [TAB] -> --wandb.
./scripts/train.py --train.wa [TAB] -> --train.warmup-epochs
./scripts/train.py --wandb.u [TAB] -> --wandb.use-wandb
設定した引数は意外に名称を忘れてしまうことがあるため、このように引数を全てコマンドに打たなくても補完することができるのは非常に便利だと感じました。
Annotatedの活用
tyro.confのargとtypingのAnnotatedを使って指定することもできます。これを使うとCLIのエイリアスを指定することもできるため、コード内の引数としてわかりやすく名前にしたいけどCLIではできるだけ省略したいといったことが可能になります。
"""Sum two numbers by calling a function with tyro."""
from dataclasses import dataclass
from typing import Annotated
from tyro.conf import arg
import tyro
@dataclass
class AddArgs:
first_number: Annotated[int, arg(help="First number to add.", aliases=["-a"])]
second_number: Annotated[
int, arg(help="Second number to add. Defaults to 3.", aliases=["-b"])
] = 3
def add_with_args(args: AddArgs) -> int:
return args.first_number + args.second_number
total = tyro.cli(AddArgs)
total = add_with_args(total)
print(total)
サブコマンド
また、サブコマンドと呼ばれる機能によって、同じスクリプトでも異なる引数設定で実行することが可能とのことです。(こちらは未検証です。)
from typing import Union, Annotated
from dataclasses import dataclass
import tyro, tyro.conf
@dataclass
class TrainCfg(CFG):
mode: str = "train"
@dataclass
class EvalCfg(CFG):
mode: str = "eval"
checkpoint: Path = Path("best.pth")
CliCfg = Union[
Annotated[TrainCfg, tyro.conf.subcommand("train")],
Annotated[EvalCfg, tyro.conf.subcommand("eval")],
]
if __name__ == "__main__":
cfg = tyro.cli(CliCfg)
コマンドは以下のように実行します。
python main.py train --train.batch-size 64
python main.py eval --checkpoint outputs/exp_001/best.pth
本記事のまとめ
最後に、本記事で紹介した要点を整理します。
1. tyroを用いてCLIを生成する
dataclassを用いてconfigを定義することで型安全なCLIを作ります。
@dataclass
class TrainingCfg:
"""Training hyperparameters configuration."""
batch_size: int = 32
"""Batch size for training."""
shuffle: bool = True
"""Whether to shuffle the training data."""
num_epochs: int = 3
"""Number of training epochs."""
lr: float = 1e-3
"""Learning rate (alias for learning_rate)."""

2. 実行中のログはloggingで記録する
コマンドラインから実行した処理はloggingを用いて.logファイルに記録します。
========== Start fold=0 ==========
----- Seed info -----
Set seed: 42
----- Task info -----
Number of classes: 39
Model: resnet18d
Starting training: fold=0, epochs=3, optimizer=adamw, scheduler=warmup_cosine
[Before training] Used: 256.2MB / total: 22478.3MB (1.14% used)
----- Epoch 1/3 (fold 0) -----
[Train] Epoch 1: Loss=0.2538, Accuracy=0.9243
[train_one_epoch] 78.591992 sec (CUDA)
[Valid] Epoch 1: Loss=0.1352, Accuracy=0.9560
[valid_one_epoch] 10.125912 sec (CUDA)
[epoch=1] train_loss=0.2538 train_acc=0.9243 val_loss=0.1352 val_acc=0.9560
Saved best model (updated): /sample_project/workspace/models/exp003/fold_0/best_model.pth (epoch=1, val_loss=0.1352)
3. モデルの学習推移をWandbで監視する
オンラインではWandbのWebブラウザ、オフラインではLEETを使って学習推移を監視・確認します。
個人レベルの小規模な実験であれば、この3つのツールを駆使するだけでしっかりと実験の記録を残したり、確認することができるかと思います。
終わりに
今回はAIエンジニアリング入門シリーズの2本目として、logging, wandb, tyroを用いた実験管理方法を紹介しました。よいモデルを作るにはたくさんの仮説検証を回す必要がありますが、それを丁寧に管理したり効率的に実行することで、実験効率を上げることができ、結果的に優れたモデル構築につながります。今回はかなり簡単な例でサンプルを作りましたが、こちらをベースにカスタムしていただければすぐに実験を回すことができるかと思いますので、ぜひご活用いただければ幸いです。

Discussion