はじめに
データソリューション事業部の宮澤です。
昨日Xにてポストされていた以下の記事を理解しようと思い、読んでみました。
概要
GPUメモリ節約のためによく使われる gradient_accumulation_steps の挙動にバグがあったとのこと。unslothおよびtransformersのライブラリでは修正されたと報告されています。
バグについて
事象
unslothの記事を見ると、gradient accumulationを使用すると、フルバッチトレーニングを使用する場合よりも損失が大きくなったことが示されたとのことです。実際に以下の図を見ると、バッチサイズ*勾配累積=16で固定したときに、勾配累積が大きいほうが損失が大きくなっています。
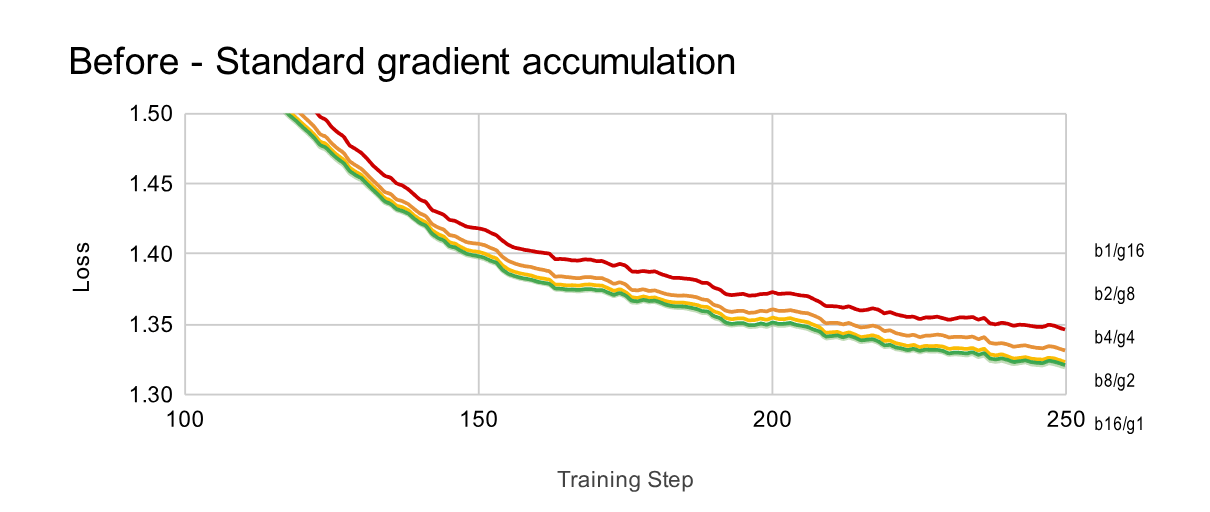
https://unsloth.ai/blog/gradient より引用
原因
原因として、①累積ステップで数値エラーが発生している ②損失計算にバグがある という2つの仮説が挙げられたとのことです。①についてはfloat32で累積した際にも同様の結果となることがわかり、僅かな累積エラーでした。②は実際にバグがあり、こちらに大きな原因であったようです。
実は、勾配を単純に足し合わせるだけでは、フルバッチでの計算と数学的に同義ではありませんでした。
まず交差エントロピーは以下の式で表されます。
この時、分母はマスクされていないトークンの数をカウントしています。
分かりやすさのために分母を平均長
gradient accumulationを使った場合の損失は、フルバッチの時と比べて
これを補正するには累積される各項に
この「分母に問題がある」という点を確かめるために、分母を削除して実験してみると、全ての設定で損失が一致することが確認されたとのことです。

https://unsloth.ai/blog/gradient より引用
したがって、問題はミニバッチの損失の正規化部分にあるということがわかりました。
解決策
最終的な修正後の式はこの記事で直接書かれてはいませんでしたが、有効なシーケンス長が異なることを踏まえて累積計算する必要があることから、おそらくミニバッチ内で累積された損失をすべての有効なトークン数を分母として正規化する形に修正されたと考えられます。(有効なトークン数tはマスクされていないトークン数の意です。)
また、このバグはtransoformersライブラリでも修正されたことが報告されていますので、そちらも見ていきたいと思います。
修正は以下のようにされたとのことです。
def ForCausalLMLoss(logits, labels, vocab_size, **kwargs):
# Upcast to float if we need to compute the loss to avoid potential precision issues
logits = logits.float()
# Shift so that tokens < n predict n
shift_logits = logits[..., :-1, :].contiguous()
shift_labels = labels[..., 1:].contiguous()
# Flatten the tokens
shift_logits = shift_logits.view(-1, vocab_size)
shift_labels = shift_labels.view(-1)
# Enable model parallelism
shift_labels = shift_labels.to(shift_logits.device)
num_items = kwargs.pop("num_items", None)
+ loss = nn.functional.cross_entropy(shift_logits, shift_labels, ignore_index=-100, reduction="sum")
+ loss = loss / num_items
- loss = nn.functional.cross_entropy(shift_logits, shift_labels, ignore_index=-100)
return loss
具体的には、交差エントロピーの計算部分であるnn.functional.cross_entropyで、デフォルトは平均値を取るようにreduction="mean"となっていますが、これが削除され、まずreduction="sum"で損失を累積してから有効なトークン数num_itemsで正規化するように修正されています。`
おわりに
今回は、gradietion accumulationのバグについてまとめました。急いでキャッチアップしたため誤りが含まれるかもしれませんがご容赦ください。原因は紐解いてみれば意外とシンプルなものでしたが、自分がよく使っていた設定であっただけに、これまで発見されていなかったことに少し驚きました。それと同時に、便利なライブラリでも違和感のある挙動があった際には実験をしてみたりソースコードを見てみることが重要であると感じました。

Discussion