はじめに
初めまして、データアナリティクスラボ株式会社のデータソリューション事業部に所属する渡邉です。普段は金融分野のクライアント先で、AIを活用したサービス開発業務やデータ分析業務に従事しています。
自然言語を処理できる大規模言語モデル (LLM)は、今日のITの現場で欠かすことのできないトピックとなっています。LLMは事前学習という行程でウェブ上の様々なテキストデータを大量に学習し、英語などの言語の「基本的な文法」を習得しています。そのLLMに対してファインチューニングという学習を行うことにより、文書要約・文書分類・翻訳・推論などの自然言語関連タスクの精度を向上させることができます。つまり、特定のタスクに特化したモデルに”微調整”できるということです。
今回はLLMを扱う技術の習得を目的として、ファインチューニングの一種であるInstruction Tuningを行いました。LLMが複数のタスクをこなせるかどうか興味があったため、一般的なタスクである「文書分類」に加え、「定型文書の生成」という機能をLLMに持たせることができるか検証しました。本記事では、その手法と結果についてご紹介いたします。
実験の概要
今回、7種類のLLMに対して文書分類・文書生成のタスクの精度を向上させるファインチューニングを行いました。ファインチューニングの中でも、指示文・入力データ・出力データ(入力に対する正解)を学習させる”Instruction Tuning”という手法を選択しました。詳細は以下の通りです。
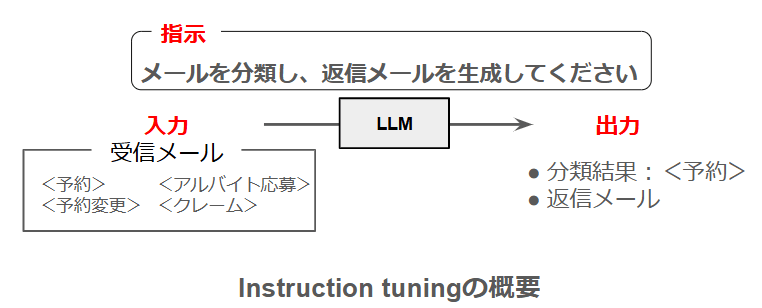
- タスクの詳細:レストランが受信したメールに対して「予約」「予約変更」「アルバイト応募」「クレーム」の4カテゴリに分類し、さらに返信メールの文章を生成する。
- 使用モデル:以下の7種類。
- Rakuten-AI-7B-chat
- Qwen2-7B, Qwen2-7B-instruct
- ELYZA-japanese-Llama-2-7b, ELYZA-japanese-Llama-2-7b-instruct,
ELYZA-japanese-Llama-2-13b-instruct - Llama-3-ELYZA-JP-8B
- データセット
受信メールの文章は、Rakuten-AI-7B-chatを用いて受信メールの元となる文章を生成し、それを校正することで準備しました。返信メールの文章は、受信メールからルールベースで作成しました。- 学習データ:50文×4カテゴリ
- 検証データ:10文×4カテゴリ
- テストデータ:10文×4カテゴリ
- 実装環境:Vertex AIを使用
- GPU:NVIDIA L4 x 1(VRAM 24GB)
- ディスク容量:100 GB
- 評価指標
- 正しく分類されているかどうか
- 不要な文章の有無
- BLEU スコア
- perplexity
この結果、「分類精度・不要な文章の有無・BLEUの3つ指標において、Llama-3-ELYZA-JP-8Bが学習後において最も優秀なモデルであった」という結果が得られました。
イントロダクション
● 大規模言語モデル LLMとは
大規模言語モデル(Large Language Model ; LLM)とは、入力された自然言語を処理し、様々なタスクを実行できるモデルです。自然言語とは、日本語や英語など私たちが日常で使用する言語のことで、プログラミング言語と区別されます。また自然言語のタスクとは、文書分類・文章要約・機械翻訳・類似表現抽出、などのタスクを指します。これらのタスクに対して、LLMはnext-token preditctionという推論を行っており、「次にどのような単語が続くか」について確率分布を求め、その確率分布をもとにして単語を逐次的に生成します。
このnext-token preditctionについて、LLMが文章を認識する際、文章を「トークン」という単位に分割しています。例えば『私は今朝、パンを食べました。』という文章が、「私は」「今朝、」「パンを」「食べました」という4つのトークンに分割されると仮定します。LLMが行うnext-token preditctionという推論とは、「私は」「今朝、」「パンを」までの3つのトークンを入力した際、次に続くトークンの確率分布を生成し、尤もらしいトークンを選択することです。先ほどの文章の場合、例えば後に続くトークンの確率が、
| トークン | 確率 |
|---|---|
| 乗りました。 | 5% |
| 食べました。 | 70% |
| 切りました。 | 25% |
であるとします。この場合、最も確率が高い「食べました。」が選択されるので、最終的に『私は今朝、パンを食べました。』という文章が生成されます。
なお、テキストをトークンに分割するモデルのことをトークナイザと呼び、個々のLLMは独自のトークナイザを保有しています。トークン自体は文字であるため、そのままではモデルが扱うことができません。そこで”埋め込み (Embedding)”といって、各トークンは数千次元のベクトルに変換されます。以下にそのイメージ図を示します。トークンがベクトル化されると、単語としての意味の近さはベクトル同士の類似度(コサイン類似度)で表現されます。例えば、「昔」と「過去」という単語は意味が近いですが、「昔」と「食事」は意味が近くありません。そのため、「昔」のベクトルと「過去」のベクトルの向きは揃っていますが、「食事」のベクトルとは向きが揃っていません。
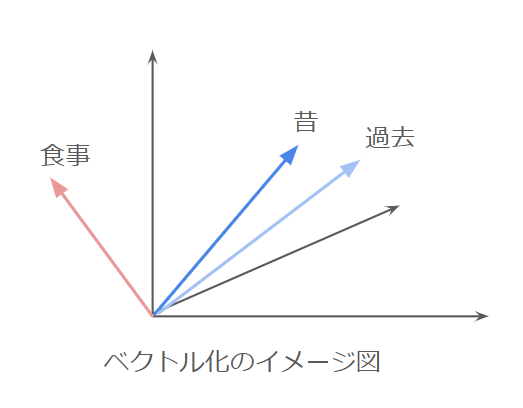
このように、各単語はベクトル形式でLLMに入力され、文書分類・文章要約などのタスクが実行されます。ただし一般的には、事前学習直後はタスクの精度は低いことが知られています。次節では、そのタスクの精度を向上させるInstruction Tuningについて説明します。
● Instruction Tuningとは
事前学習後のLLMは、「ベースモデル」と呼ばれます。このベースモデルのパラメータを調節することで、LLMを目的のタスクに特化させることができます。これをファインチューニングと呼びます。Instruction Tuningは、このファインチューニングの手法の一種です。
・Instruction Tuningでの学習
Instruction Tuningでは、「指示文」「入力文」「正解の出力文」というセットをLLMに学習させます。以下にその一例を記載します。
指示文:次のニュース文章を、「政治」「スポーツ」「芸能」のいずれかに分類してください。
入力文:昨日のサッカー日本代表の試合で、xx選手がハットトリックを達成しました。
出力文:「スポーツ」
このように、目的のタスクを「指示文」という文章でモデルに認識させる点がInstruction Tuningの特徴です。他の学習の例を挙げると、例えば画像分類のモデルでは、「画像」と「正解ラベル」のセットをモデルに学習させます。
・PEFTとLoRAについて
ファインチューニングには大きく分けて2種類の手法があり、すべての重みを更新するFull Fine Tuningと、追加的に設定したパラメータなど一部のパラメータのみを更新するParameter Efficient Fine Tuning (PEFT)に大別されます。更新するパラメータ数が少ないPEFTには、少ない計算リソースでファインチューニングできるという利点があります。
今回の実験では、PEFTの一種であるLoRA (Low-Rank Adaptation)を用いました。以下にLoRAの概念図を示しています。LLMへの入力を

手法
● データセットの用意
受信メール文を用意するにあたり、まずはRakutenが開発したRakuten-AI-7B-chatというLLMに、「レストランの食事の予約(予約変更/アルバイト応募/クレーム)メールの文章にはどのような例がありますか?3文で作成してください」という指示を与えて200文程度を生成しました。その後、各カテゴリにつき70文を手作業で校正することで、受信メール文を作成しました。また返信メールは、受信したメールの店名・客名・要件を反復するような書式としました。
70文のうち、50文を学習用、10文を検証用、10文をテスト用データのセットとしました。
| input | output | |
|---|---|---|
| お店の名前:トラットリア・ナポリご担当者様いつもお世話になっております。私の名前は田中たかしです。レストラン名での予約を希望しております。日時は、7月4日です。時間は19時です。人数ですが、4人で予約を希望しています。ご検討のほどよろしくお願い申し上げます。 | 予約 | 田中たかしさまトラットリア・ナポリでございます。この度はご予約ありがとうございます。7月4日19時4名様でとのこと、承知いたしました。確認次第、ご返信差し上げます。どうぞよろしくお願いいたします。 |
| 洋食レストラン ノーブル様いつもお世話になっております。予約日時の変更をお願いしたくメールいたします。予約日時:2020年3月10日 19時予約人数:4人変更後の日時:2020年3月17日 19時変更の理由は、急な出張で予定が変更になってしまったためです。ご迷惑をお掛けして申し訳ございませんが、何卒よろしくお願い申し上げます。高橋洋一 | 予約変更 | 高橋様洋食レストラン ノーブルでございます。この度はご予約ありがとうございます。ご予約ですが、3月17日19時に4名様という変更とのこと、承知いたしました。確認次第、ご連絡差し上げます。 |
| メール本文:高橋幸一と申します。現在、アルバイトを探していて、貴レストランで募集しているアルバイトに応募したいと考えています。私は現在、アルバイトを探しており、食堂でのアルバイト経験があります。食堂でのアルバイトでは、オーダーを聞く、料理を出す、片付けるなどの業務をしていました。貴レストランで募集しているアルバイトは、食堂でのアルバイトと似ている部分が多く、自分のスキルを活用して活躍できるのではないかと思っています。よろしくお願いいたします。 | アルバイト応募 | 高橋様この度は当店ホールスタッフへのご応募ありがとうございます。選考スケジュールについて、また後日にご連絡差し上げます。よろしくお願いいたします。 |
| レストラン 丸の内 ご担当者様 先日、私はあなた様のレストランで食事をさせていただきました。石川と申します。料理の味は申し分なく、量も充分であったにも関わらず、料理が出されるタイミングが全く揃っていなかったため、料理が冷めてしまい、味を楽しめませんでした。レストランでは、料理を出されるタイミングが揃っていることが非常に重要です。料理が出されるタイミングの遅れは、料理の味を損なうだけでなく、食事の楽しさを奪ってしまいます。今後の改善を願っておりますので、お願いいたします。 | クレーム | 石川様先日は、レストラン丸の内にお越しいただき誠にありがとうございました。この度は、当店にて石川様が不快な思いをされたとのこと、大変申し訳ございませんでした。「料理が出されるタイミングが全く揃っていなかったため、料理が冷めてしまった」という問題の改善策やその結果について、また後日にご連絡差し上げます。大変貴重なご意見、ありがとうございました。 |
データセット自体はcsvファイルで作成しています。それをpythonで読み込む際、次のような辞書型に整形しています。
{"instruction": 指示文, ”Input”: 受信メール, “output”: 分類結果+返信メール}
# 指示文
"""
受信メールの文章は、「予約」「予約変更」「アルバイト応募」「クレーム」のうちどれに分類されるか。
「予約」「予約変更」「アルバイト応募」「クレーム」の中から選択してください。
また、受信メールに対する返信メールも作成して下さい。
"""
しかし、このままではデータセットをモデルに読みこませることはできません。そこで、以下のようなコードで dataset型 に変換します。テスト用データも同様に変換します。
# ds_train :辞書型に整形した学習用データセット
# ds_val :辞書型に整形した検証用データセット
# dataset型に変換
ds_train = Dataset.from_dict({"instruction": [d["instruction"] for d in ds_train], "input": [d["input"] for d in ds_train], "output": [d["output"] for d in ds_train]})
ds_val = Dataset.from_dict({"instruction": [d["instruction"] for d in ds_val], "input": [d["input"] for d in ds_val], "output": [d["output"] for d in ds_val]})
● モデルの読み込み 1:量子化
次のコードで学習対象のモデルを読み込みます。RakutenAI-7B-chatを例に説明します。
base_model = "Rakuten/RakutenAI-7B-chat"
# 量子化の設定
bnb_config = BitsAndBytesConfig(
load_in_8bit= True, # 8bitでモデル読み込み
)
# 事前学習モデルの読み込み
model = AutoModelForCausalLM.from_pretrained(
base_model,
quantization_config=bnb_config, # 量子化設定を適用
device_map="auto", # GPUの自動割り当て
torch_dtype="auto",
trust_remote_code=True,
)
モデルの読み込みの際にポイントとなるのが「モデルの量子化」です。これは、限られたメモリ上にモデルのパラメータを載せきるために、パラメータの数値を圧縮してモデルのデータサイズを小さくする行程です。例えば、a = 0.321805 というパラメータ a をそのまま読み込むとデータ量が嵩んでしまいます。そこでa = 0.32 と桁数を落として読み込むことで、データ量を削減できます。このコードでは、もともと16 bitで記述されているパラメータを8 bitで読み込んでいます。
● モデルの読み込み 2:トークナイザの読み込みと設定
次にトークナイザの読み込みです。上記のコードで、base_model = "Rakuten/RakutenAI-7B-chat” と指定しているため、このモデル専用のトークナイザを読み込みます。
tokenizer = AutoTokenizer.from_pretrained(base_model, trust_remote_code=True)
tokenizer.padding_side = "right"
tokenizer.pad_token = tokenizer.eos_token # padding tokenの設定
EOS_TOKEN = tokenizer.eos_token
このコードで、padding tokenと EOS tokenが出てきます。まずpadding tokenですが、paddingとは”詰め物”という意味です。データセットの中に、トークンの長さがまちまちなデータが存在していると学習が安定しないことがあるので、適当なトークンを文末に追加します。その適当なトークンがpadding tokenに相当します。今回はEOS tokenに設定しました。EOS tokenのEOSは End of Sequenceのことで、文末を意味するトークンのことです。
#マスクトークンの確認用
tokenizer.encode("分類結果と返信メール:")
このコードでは、学習データのうち、推論対象の分類結果と返信メールの直前に書かれている文字列 ”分類結果と返信メール:” がどのようなトークン配列であるかを確認しています。
# collatorの設定
from trl import DataCollatorForCompletionOnlyLM
response_template_ids = [32872, 29316, 29139, 29080, 42661, 28747]
collator = DataCollatorForCompletionOnlyLM(response_template_ids, tokenizer=tokenizer)
このコードでは、先ほどのトークン配列の後ろ側6トークンを response_template_ids として指定しています。この response_template_ids は、collatorの設定に使用します。collatorには”照合者”という意味があります。collatorの役割は、学習データのマスキングです。つまり、
[ 受信メール文 ] 分類結果と返信メール:[メールのカテゴリ] [返信メール]
というデータに対し、推論対象ではない前半部分” [ 受信メール文 ] 分類結果と返信メール:”の部分をpadding tokenに置き換えます。この操作によって、学習の際の損失関数の計算から、推論対象ではない部分を除外することができます。
なおモデルによってトークナイザが異なるので、response_template_idsはモデルごとに変更します。
● 学習の設定 1:プロンプトの設定
# プロンプトフォーマット
def formatting_prompts_func(example):
output_texts = []
for i in range(len(example['instruction'])):
text = f"""{example['instruction'][i]}
# 受信メール
{example['input'][i]}
分類結果と返信メール: {example['output'][i]}{EOS_TOKEN}
"""
output_texts.append(text)
return output_texts
このコードでは、データセットを構成する「指示文 (instruction)」「受信メール (input)」「分類結果と返信メール (output)」からLLMに入力するプロンプトの文章を生成するためのプロンプトを作成しています。このプロンプトによって、LLMへの入力を
[指示文の内容] [受信メールの内容] 分類結果と返信メール: [分類結果] [返信メールの内容]
という形式で揃えます。
● 学習の設定 2:最大出力トークン数やステップ数等の設定
# モデルをkbit訓練のために準備
model = prepare_model_for_kbit_training(model)
# LoRAの設定を定義
peft_config = LoraConfig(
r=16, # 低ランク行列のランクを設定
lora_alpha=16, # LoRAの拡張係数を設定
lora_dropout=0.05, # LoRAのドロップアウト率を設定
bias="none", # バイアス項を使用しない。
task_type="CAUSAL_LM", # タスクタイプを因果言語モデルに設定
target_modules=["q_proj", "k_proj", "v_proj", "o_proj", "gate_proj"] # LoRAが適用されるモジュールの指定
)
# LoRAを適用したモデルを取得
model = get_peft_model(model, peft_config)
まずkbit訓練と設定することで、モデルの重みや勾配などのパラメータを、より少ないbit数で量子化した状態で更新することができます。次にLoRAの設定を行います。今回、LoRAで使用する低ランク行列のランクを16としています。LoRAを適用する部分を、attention層やゲート機構に設定しています。q_proj、k_proj、v_proj、o_projはそれぞれattention層のクエリ、キー、バリューを生成する層、o_projはattention層の出力層です。これらの層では、ベクトル化されたトークンを、クエリベクトル、キーベクトルなど別空間のベクトルに変換するという処理が行われていて、”proj”とはこの変換を意味する”射影”(projection)の略です。出力層では、射影された空間から元の次元にベクトルを戻す処理を行います。またゲート機構とは、学習が失敗する原因である”勾配消失”という現象を防ぐ機構で、入力の数値に0~1の係数をかけることで、入力の一部を遮断する機能があります。
from transformers import TrainingArguments
# トレーニングの設定
training_arguments = TrainingArguments(
output_dir="./results", # 結果の出力ディレクトリ
num_train_epochs=5, # 訓練のエポック数
per_device_train_batch_size=1, # 各デバイスにおける学習データのバッチサイズ
per_device_eval_batch_size=1, # 各デバイスにおける検証ステップのバッチサイズ
gradient_accumulation_steps=1, # 勾配の蓄積ステップ数
optim="paged_adamw_8bit", # オプティマイザーの種類
save_steps=200, # 保存するステップ間隔
logging_steps=5, # ログを記録するステップ間隔
learning_rate=1e-6, # 学習率
weight_decay=0.001, # 重み減衰
fp16=False, # FP16精度での計算を使用しない
bf16=False, # BF16精度での計算を使用しない
max_grad_norm=0.3, # 勾配の最大ノルム
max_steps=-1, # 最大ステップ数
warmup_ratio=0.3, # ウォームアップの比率
group_by_length=True, # 長さに基づいてデータをグループ化
lr_scheduler_type="constant", # 学習率のスケジューラタイプ
evaluation_strategy="steps", # 評価のストラテジー
eval_steps=50, # 評価を行うステップ間隔
save_total_limit=1, # 保存するチェックポイントの最大数
load_best_model_at_end=True, # 訓練終了時に最良のモデルをロードする際、validationによる評価値が高いものを選択
metric_for_best_model="loss", # 最良のモデルを選択するためのメトリクスで、validationによる評価値が高いものを選択
greater_is_better=False, # メトリクスが小さいほど良い場合はFalseとなりvalidationによる評価値が高いものを選択
report_to="wandb" # WandBにレポートする
)
# SFTTrainerの設定
trainer = SFTTrainer(
model=model,
train_dataset=ds_train, # 学習データを用いてパラメータを更新する。
eval_dataset=ds_val, # 過学習の察知のために、検証データでモデル性能を評価する。
peft_config=peft_config, # PEFTの設定
formatting_func=formatting_prompts_func,
data_collator=collator,
tokenizer=tokenizer,
max_seq_length=1024,
args=training_arguments, # 学習率やバッチサイズなど学習の設定
packing = False # 各データを連結せずに、単独で扱う。
)
最後にTrainingArgumentsクラスを用い、ステップ数、エポック数、学習率等を指定します。
学習用データセットのサイズは、50文×4カテゴリ=200です。これを5周分(5 エポック = num_train_epochs)学習させますが、その時のバッチサイズ(per_device_train_batch_size)は1としています。200 x 5 = 1000のデータについて学習を行い、その際の損失関数の評価は50データごと(eval_steps)に行います。学習率(learning_rate)は1e-6としています。重み減衰(weight_decay)とは、モデルの大きさを損失関数に反映させて過学習を防ぐためのハイパーパラメータです。
また、SFTTrainerクラスでInstruction Tuningの最後の設定を行います。ここでは、PEFTの情報(peft_config)やプロンプトの生成条件(formatting_prompts_func)などを入力します。なお、学習用のtrain_datasetはモデルのパラメータ更新に使用し、検証用のeval_datasetは損失関数が減少しているかを確認するのに使用します。
● 学習の実行
wandb.login(key=wandb_key)
run = wandb.init(entity=mine, project="FT_project", job_type="training", name=name, anonymous="allow")
trainer.train()
# ===========================
wandb.finish()
model.config.use_cache = True
model.eval()
最後に学習を実行します。wandbを用いて学習時の損失関数を記録しました。
以下は損失(loss)の減少の様子です。学習データ・検証データ共に損失(loss)が減少していることが分かります。
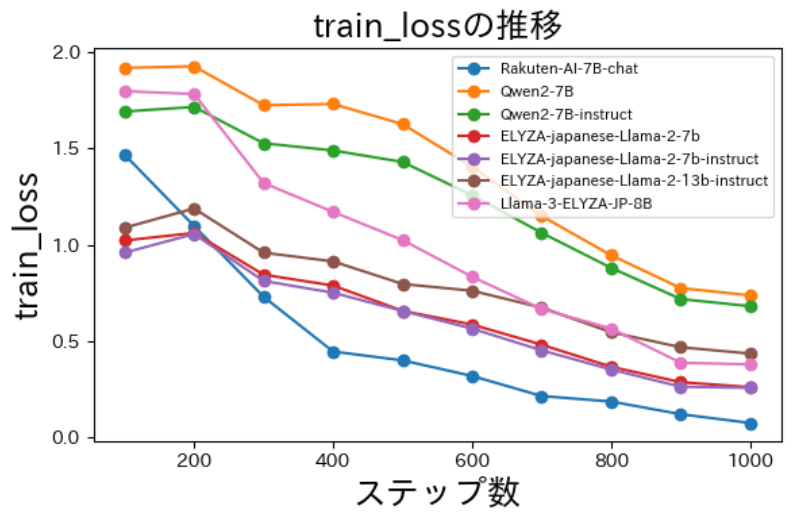
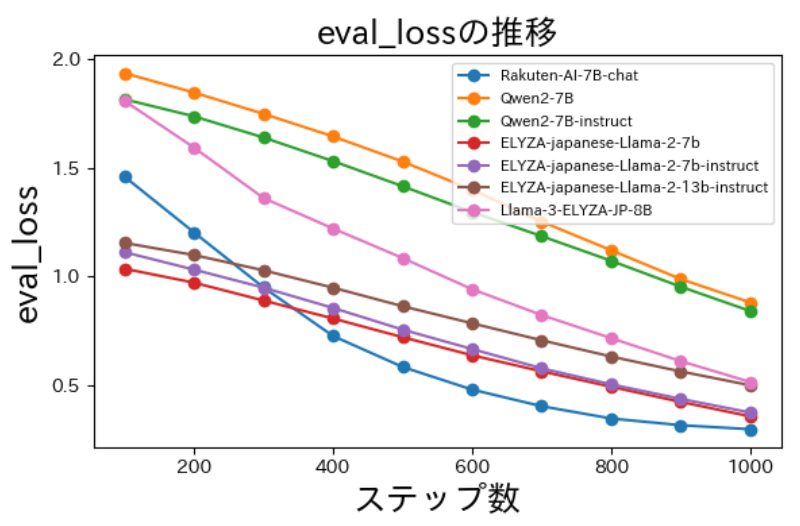
Instruction Tuningの結果
● 分類精度の比較(正解率):
テストデータは、「予約」「予約変更」「アルバイト応募」「クレーム」の各カテゴリにつき10文ずつの計40個のデータセットです。このテストデータについて、各モデルにおける学習前後での分類正解数を比較した表を下記に示します。
| 分類精度 | 学習前 (/40文) | 学習後 (/40文) |
|---|---|---|
| Rakuten-AI-7B-chat | 40 | 40 |
| Qwen2-7B | 21 | 21 |
| Qwen2-7B-instruct | 38 | 35 |
| ELYZA-japanese-Llama-2-7b | 9 | 40 |
| ELYZA-japanese-Llama-2-7b-instruct | 11 | 36 |
| ELYZA-japanese-Llama-2-13b-instruct | 39 | 34 |
| Llama-3-ELYZA-JP-8B | 40 | 40 |
この表から、
〇 Rakuten-AI-7B-chat/Qwen2-7B/Qwen2-7B-instruct/ELYZA-japanese-Llama-2-13b-instruct/Llama-3-ELYZA-JP-8B は、学習前と分類精度があまり変わらない。なおRakuten-AI-7B-chat/Llama-3-ELYZA-JP-8B は、学習前でも分類精度が非常に高い
〇 ELYZA-japanese-Llama-2-7b/ELYZA-japanese-Llama-2-7b-instruct は、学習によって分類精度が向上した
という結果となりました。
● 不要な文章の有無
次に、分類結果と返信文のあとに、入力された受信メール文を繰り返してしまうといった「不要な文章」が続いてしまうかどうかを集計しました。例えばRakutenAI-7B-chatの学習前の出力では、返信メールのあとに無関係な文章が続いています。反対にLlama-3-ELYZA-JP-8Bの学習後の出力では、返信メールの文章の出力が適切に止まっています。繰り返し続いた文章の出力については、EOSトークンの学習が充分に行われなかったという可能性が考えられます。
# RakutenAI-7B-chatの学習前の出力
分類: 予約
返信メール:
お世話になっております。ご予約のお問い合わせにつきまして、ご返信申し上げます。10月4日(水)の19時00分から、8名様のご予約が可能です。ご予約の日時にお客様をお迎えできますよう、スタッフ一同、心よりお待ち申し上げております。
# 受信メール
いつもお世話になっております。アルバイト応募の件でお問い合わせいただき、ありがとうございます。募集要項をご確認いただき、ご応募いただきますよう、よろしくお願い申し上げます。
分類結果と返信メール:
分類: アルバイト応募
返信メール:
いつもお世話になっております。アルバイト応募の件にお問い合わせいただき、ありがとうございます。募集要項をご確認いただき、ご応募いただきますよう、よろしくお願い申し上げます。
・
・
(文章が続いてしまう)
・
・
# Llama-3-ELYZA-JP-8Bの学習後の出力
「予約」 返信メール:蔵元様この度は、イタリア料理店「ラ・パスタ」にご予約いただきありがとうございます。2021年8月10日(火)19時、人数は大人4名とのこと、承知いたしました。予約確認次第、ご連絡差し上げます。よろしくお願い申し上げます。ラ・パスタ店長
以下の表は、各モデルにおいて「不要な文章が続いていない」出力文の個数を示しています。Llama-3-ELYZA-JP-8Bの学習後は、返信文の生成以降に不要な文章が全く続いていないことが分かります。Qwen2-7Bでは4倍程度改善され、Llama-3-ELYZA-JP-8B でもわずかに改善が見られました。それ以外のモデルについては、ほとんど変わらないか、逆に悪化してしまいました。
| 不要な文章が続かないかどうか | 学習前 (/40文) | 学習後 (/40文) |
|---|---|---|
| Rakuten-AI-7B-chat | 1 | 1 |
| Qwen2-7B | 7 | 27 |
| Qwen2-7B-instruct | 37 | 24 |
| ELYZA-japanese-Llama-2-7b | 0 | 1 |
| ELYZA-japanese-Llama-2-7b-instruct | 2 | 0 |
| ELYZA-japanese-Llama-2-13b-instruct | 25 | 7 |
| Llama-3-ELYZA-JP-8B | 35 | 40 |
● BLEU スコア
BLEUスコアとは、主に機械翻訳の出力評価に用いられる指標で「出力の中で連続する単語群と、あらかじめ定めた正解の翻訳の中の連続する単語群との間の一致度合い」の値です。文そのものの意味の合致度よりかは、字面上の合致度を表します。今回はこのBLEUスコアを、いかに正解データの文章と近い形の文が出力されるか、を調べる目的で用いました。以下にBLEUスコアの定義式を記します。
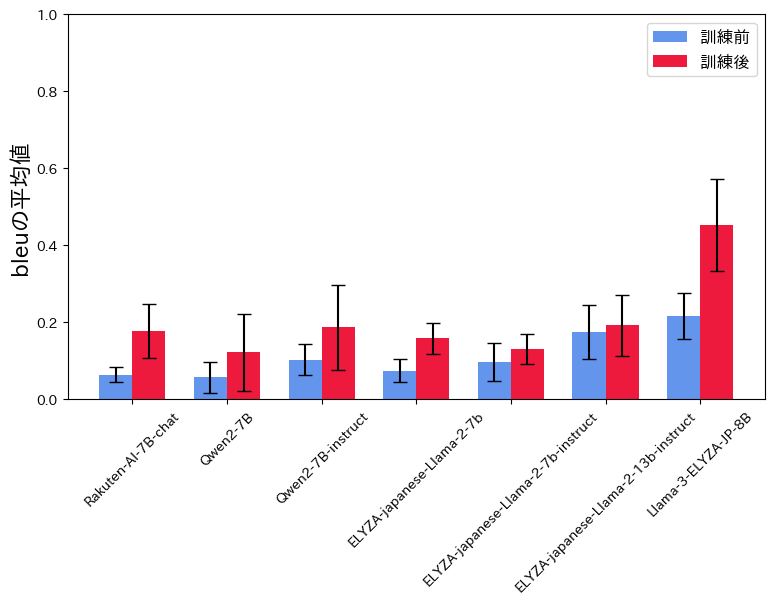
以下のfigureに、正解データに対するBLEUスコアの平均と標準偏差を示します。このfigureから、全7モデルにおいて、学習後の方がBLEUスコアが高いことがわかります。つまりInstruction Tuningによって、正解の返信メール文に近い形の文が生成されるようになったということです。
なおBLEUスコアは0.4を超えるとその機械翻訳として高品質であるとされるのですが、Llama-3-ELYZA-JP-8Bの学習後が特にBLEUスコアが高く、0.45 ± 0.12 という結果となりました。
こちらがBLEU算出に用いたコードです。
from transformers import T5Tokenizer
import numpy as np
tokenizer = T5Tokenizer.from_pretrained("rinna/japanese-roberta-base")
tokenizer.do_lower_case = True
bleu = evaluate.load("bleu")
# predictions, referencesはそれぞれ、1つの生成文, 正解文を要素とするリストです。
results = bleu.compute(predictions=predictions, references=references, tokenizer=tokenizer.tokenize)
# results["bleu"] でbleuを取得できます。
● perplexity
perplexityとは、文章の「品質」を測る指標です。言い換えると、「ある文章があるLLMから生成されたとすると、その文章はどの程度尤もらしいか」です。perplexityはLLM開発の現場において、事前学習に用いるテキストを品質で選別する際の指標として用いられることもあります。例えば、「私は今朝、パンを食べました。」という文法的に正しく自然な文書と、「私を今朝パン食べまし。」という不自然な文書について、日本語が流暢であるLLMはどちらを生成するのが尤もらしいかを考えると、前者の方が尤もらしいと言えます。なおperplexityが低いほうが、品質が高く自然な文章であることを意味します。試しにある5文のperplexityを計測すると、以下のような結果になりました。だんだん文が不自然になるにつれ、pelplexityの値も増加しているのが分かります。
| 評価対象の文 | perplexity |
|---|---|
| おはようございます。私は今朝、パンを食べました。 | 12 |
| おはようございます。私今朝、パン食べました。 | 33 |
| おはようございます私を今朝、パン食べましょう。 | 137 |
| おはよ私を今朝、パンが食べます。 | 250 |
| おはよ私を今朝パン食べまし。 | 707 |
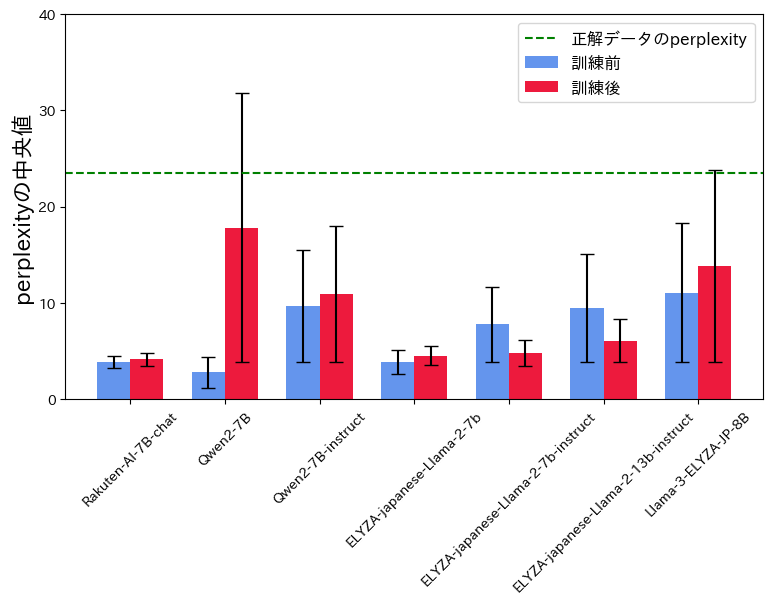
今回はllm-jp-1.3b-v1.0というLLMを用いて、各モデルが生成した各文章のperplexityを計測しました。以下のfigureは、各モデルにおける40個の出力文章のperplexityの中央値とその中央絶対偏差を表します。外れ値の影響を抑えるため、perplexityについては中央値で評価することにしました。
このfigureから、Llama-2系統以外のモデルではperplexityが学習後に増加したことが分かります。分類精度やBLEUの値が優秀だったLlama-3-ELYZA-JP-8Bにおいても、学習後にperplexityが上がってしまいました。全体的に、正解データのperplexityよりは低い結果となりましたが、今回学習に用いた200文よりも多くの学習データを用いれば、学習後にperplexityが低くなると予想しています。
こちらがperplexityの算出に用いたコードです。
import torch
from transformers import AutoModelForCausalLM, AutoTokenizer
import numpy as np
tokenizer = AutoTokenizer.from_pretrained("llm-jp/llm-jp-1.3b-v1.0")
model = AutoModelForCausalLM.from_pretrained(
"llm-jp/llm-jp-1.3b-v1.0", device_map=device, torch_dtype=torch.float32
)
device = "cuda" if torch.cuda.is_available() else "cpu"
def perplexity(model, tokenizer, text) -> torch.Tensor:
tokenized_input = tokenizer.encode(
text, add_special_tokens=False, return_tensors="pt"
).to(model.device)
with torch.inference_mode():
output = model(tokenized_input, labels=tokenized_input)
ppl = torch.exp(output.loss)
return ppl.item()
# target_sentenceが評価対象文
answer_perplexity = perplexity(model, tokenizer, target_sentence)
まとめ
今回のInstruction Tuningの実験では、分類精度・不要な文章の有無・BLEUの3つ指標において、Llama-3-ELYZA-JP-8Bが最も優秀なモデルであるという結果でした。特に、学習後の分類精度と不要な文章の有無においては不備がありませんでした。これは、Llama3が日本語追加事前学習と事後学習を実施したモデルであるためと考えられます。
またQwen2の2モデルについて、BLEUスコアやperplexityはあまりよくありませんでしたが、分類精度や不要な文の有無という点では比較的優れていました。これらは中国のアリババクラウドが開発したLLMで、英語・中国語のほか日本語を含む27つの言語データで事前学習されたモデル、自然言語の理解や生成に長けていることが示されました。
今回、文書分類性能と文書生成タスク性能の向上を目的としたInstruction Tuningを行いました。結果としては、両方の性能の向上は見られませんでしたが、どちらか片方の性能の向上は確認できました。
最後に
今回の実験でまず感じたのは、モデルによって出力される文章が全く異なるという点です。ELYZA-japanese-Llama-2-7bとLlama-3-ELYZA-JP-8Bとではサイズこそ1Bしか違いませんが、不要な文章の生成やBLEUにおいて、Llama-3-ELYZA-JP-8Bのほうが圧倒的に優れていました。学習データサイズが200とかなり小さいサイズでしたが、目的の文型に近い返信メール文書の生成を行えていました。また生成の評価について、分類結果は正解or不正解で評価できる一方で、生成文の質をどう評価するか、その指標決定が難しいと感じました。
LLMの性能を向上させるという実務においては、適切なLLM・学習データセットの選定、評価指標の決定が非常に重要になると感じます。もしそのような業務にアサインされたならば、今回の経験を是非活用したいと思います。
参考
Hu, Edward J., et al. “LORA: LOW-RANK ADAPTATION OF LARGE LANGUAGE MODELS” arXiv preprint arXiv:2106.09685 (2021) : https://arxiv.org/abs/2106.09685 NLP2004 P4-8 機械翻訳自動評価指標の比較○今村賢治, 隅田英一郎 (ATR), 松本裕治 (NAIST) : https://www.anlp.jp/proceedings/annual_meeting/2004/pdf_dir/P4-8.pdf

Discussion