1.はじめに
初めまして、データアナリティクスラボ株式会社のデータソリューション事業部に所属する渡邉です。普段は広告業界のクライアント先にて、メディア分析に従事しています。
私は社内でラボチーム1課CV(computer vision)チームに所属しており、画像関連のIT技術の研究を行っています。その研究活動のテーマとして、「画像関連タスクを実行するプロダクトの作製」を掲げています。今回、CLIPというテキストと画像の両方を処理することができるモデルを用いた画像検索システムを構築しました。本記事では、この実装活動についてご紹介いたします。
本記事はDAL Tech Blog Advent Calendar 2025として投稿しました。全ての記事は以下からご確認いただけます。
2.CLIPとは
2-1.CLIPの概要
CLIP(Contrastive Language-Image Pre-training)は、言語と画像のマルチモーダルな処理が可能なモデルで、OpenAIによって開発されました。CLIPの主な機能は、テキストデータ・画像データを入力として受け取り、ベクトルに変換するというものです。そのためCLIPのアーキテクチャは、テキストをベクトル変換するテキストエンコーダと、画像をベクトル変換する画像エンコーダの2つの部分に大別されます。テキストと画像をどのようなベクトルに変換するようにモデルが訓練されているか、次の節でご説明いたします。

https://arxiv.org/abs/2103.00020
2-2.CLIPの事前学習
CLIPをはじめとする機械学習モデルは、入力データを計算処理して何かしらの値を出力しますが、その計算過程のパラメータを保持しています。しかし、モデルの初期状態ではそのパラメータは最適化されておらず、適切な出力値を出すことができません。そのため、事前に学習データを与えて目的の出力を出すようにモデルのパラメータを調節します、これを、"事前学習"といいます。
CLIPの事前学習に必要なデータは、画像とそれに対応するテキストのセットです。そのセットをCLIPに与えると、テキストから生成されるベクトル
この事前学習によって、CLIPはテキスト・画像を適切なベクトルに変換することができるようになります。この事前学習の特筆すべき点は、学習後に特定のデータセットを使った追加トレーニングを行わなずに、OCRや画像分類といった多様な画像関連タスクを高い精度でこなせるようになったという点です。
なお実際のCLIPは、テキストエンコーダの部分はエンコードを実行する部分とテキストをトークン分割するトークナイザーで構成されています。そのため、CLIPのモデルを構成するファイルは、
- トークナイザーのファイル
- 画像の前処理を行うプロセッサーのファイル
- テキスト、画像をベクトルに変換するモデルのファイル
の3つです。
2-3.画像生成AIの一部に用いられるCLIP
CLIPのテキストエンコーダは、画像生成AI stable diffusionのアーキテクチャの一部として活用されています。詳細は割愛しますが、stable diffusionではノイズ画像からノイズを取り除く(デノイジング)ことで目的の画像を生成しますが、その際にプロンプトのテキストがCLIPのテキストエンコーダによってベクトル化され、デノイジングの条件として与えられます。

https://arxiv.org/abs/2112.10752
3.画像検索システムの概要
画像検索システムの概要は次の図の通りです。
- まず、検索システムは検索したい画像に関するテキストを入力として受け取ると、CLIPのテキストエンコーダがベクトル化します。
- 次に、検索対象画像群についても、CLIPの画像エンコーダがベクトル化します。
- 最後に、画像群から生成したベクトル群について、テキストから生成したベクトルと最も類似した画像を取得します。この時の類似度は、コサイン類似度を採用しています。

この処理を記述したpyファイルを、Streamlitを用いてウェブアプリ化しました。Streamlitとは、PythonでWebアプリを作成するフレームワークです。このフレームワークを用いると、テキストを入力するボックスや検索の実行ボタン等のUIも、簡単に記述できます。
4.画像検索システム実装の手順
それでは、実際の画像検索システム実装の具体的な手順をご説明いたします。
4-1.VMの準備
まず実行環境を用意すべく、VMの準備について、インスタンス生成、ネットワークタグの設定、Google Cloud Storage(GCS)の設定、の3ステップで行いました。
インスタンス生成
今回は、Google CloundのCompute EngineからVMインスタンスを生成しました。その際の設定ですが、
- ソースイメージ:pytorch-2-7-cu128-ubuntu-2204-nvidia-570
- GPU:T4 GPU (メモリ 30 GB)
- 静的外部IPアドレスを設定
としました。当初はL4 GPU・メモリ 16GB のVMを作成したのですが、それでは検索処理の実行にあたりメモリ不足でした。また、VMへのssh接続にはVSCodeを用いました。
各ライブラリのバージョンは次の通りです。
gcsfs==2025.10.0
numpy==2.2.6
pillow==11.0.0
streamlit==1.49.1
sentencepiece==0.2.1
transformers==4.55.0
torch==2.6.0+cu124
torchaudio==2.6.0+cu124
torchvision==0.21.0+cu124
ファイアウォールルールとネットワークタグの設定
次に、ファイアウォールルールとネットワークタグの設定を行いました。VM内のStreamlitサーバーはデフォルトで8501番ポートを介してユーザーの入力を受け取るのですが、外部からVMの8501番ポートへのアクセスは拒否されるように設定されています。そのため今回は、VM8501番へのアクセスを許容するファイアウォールルールを設定し、それに対応したターゲットタグをVMに付与しました。
この実装活動の当初は、Compute Engineのインスタンスではなく、Vertex AIのインスタンスを使用していました。しかしVertex AIの方では、個々のインスタンスにネットワークタグを付与することができなかったため、Compute Engineを選択したという経緯があります。
Google Cloud Storage(GCS)でのバケットの設定
そしてGCSにて、検索対象の画像ファイル群を格納するバケットのインスタンスを設定しました。
Compute Engineで作成したVMからは、以下のようなコードでバケット内の画像ファイルにアクセスできます。
import gcsfs
fs = gcsfs.GCSFileSystem()
bucket_path = <bucket_path>
image_paths = fs.glob(f"{bucket_path}/**")
4-2.処理ファイルの作製
モデルのダウンロード
まずは、CLIPのモデルの重みファイルを取得します。今回は、hugging faceから日本語対応CLIPモデル (line-corporation/clip-japanese-base) を選択し、トークナイザー(tokenizer)・画像プロセッサー(image_processor)、テキスト/画像をベクトル変換するモデル(model)の重みファイルを取得しました。
from transformers import AutoModel, AutoTokenizer, CLIPImageProcessor
import torch
from PIL import Image
import os
import glob
HF_MODEL_PATH = 'line-corporation/clip-japanese-base'
device = "cuda" if torch.cuda.is_available() else "cpu"
# 日本語 CLIP モデルをロード(AutoModel + trust_remote_code)
model = AutoModel.from_pretrained(HF_MODEL_PATH, trust_remote_code=True)
# 画像用 processor
image_processor = CLIPImageProcessor.from_pretrained(HF_MODEL_PATH)
# テキスト用 tokenizer
tokenizer = AutoTokenizer.from_pretrained(HF_MODEL_PATH, trust_remote_code=True)
# 保存
model.save_pretrained(save_path)
processor.save_pretrained(save_path)
tokenizer.save_pretrained(save_path)
上記の重みファイルを、VM上に配置します。
CLIPのロード
まずは、VMに配置したCLIPの重みファイルをロードします。こちらがそのコードです。
from transformers import AutoModel, AutoTokenizer, CLIPImageProcessor
import torch
from PIL import Image
import requests
import os
import glob
import streamlit as st
import gcsfs
@st.cache_resource
def load_model():
load_path = <load_path>
device = "cuda" if torch.cuda.is_available() else "cpu"
model = AutoModel.from_pretrained(load_path, trust_remote_code=True).to(device)
processor = CLIPImageProcessor.from_pretrained(load_path, trust_remote_code=True)
tokenizer = AutoTokenizer.from_pretrained(load_path, trust_remote_code=True)
return model, processor, tokenizer
テキスト/画像のベクトル化および類似度に基づいた検索
次に、ロードしたモデルを用いてテキストと画像を処理します。input_text_by_user がユーザーが任意に入力するテキストで、このテキストに意味が近い画像が検索されます。
処理の流れですが、以下の順で行っています。
- まず、画像を格納したGCSから画像ファイル群を取得します。
- 次に、テキストをトークナイザーで、画像をプロセッサーで処理します。
- そして、2. で処理したテキストと画像をモデルでベクトル化します。
- 最後に、テキストから生成したベクトルと、画像から生成したベクトルのコサイン類似度を計算し、最も類似度が高い画像のベクトルを判定します。その画像データやファイル名を、
resultに格納します。
この一連の処理を行うファイルを、clip.pyと名付けています。なお、6. 参考記事 を参考にさせていただきました。
def search_image(input_text_by_user: str):
device = "cuda" if torch.cuda.is_available() else "cpu"
model, processor, tokenizer = load_model()
# GCS 内の画像一覧取得
fs = gcsfs.GCSFileSystem()
bucket_path = <bucket_path>
image_paths = fs.glob(f"{bucket_path}/**")
# 画像読み込み
images = [Image.open(fs.open(path, 'rb')).convert("RGB") for path in image_paths]
image_inputs = processor(images=images, return_tensors="pt")
# GPUに移動
image_inputs = {k: v.to(device) for k, v in image_inputs.items()}
# テキスト
text_list = [input_text_by_user]
text_tokens = tokenizer(text_list, padding=True)
text_inputs = {k: v.to(device) if isinstance(v, torch.Tensor) else torch.tensor(v, device=device)
for k, v in text_tokens.items()}
# テキストと画像のベクトル化
with torch.no_grad():
text_vector = model.get_text_features(**text_inputs) # (1, D)
image_vectors = model.get_image_features(**image_inputs) # (N, D)
# 正規化
text_vector = text_vector / text_vector.norm(dim=-1, keepdim=True)
image_vectors = image_vectors / image_vectors.norm(dim=-1, keepdim=True)
# 類似度計算 (N, D) @ (D, 1) -> (N,)
image_similarity = (image_vectors @ text_vector.T).squeeze(1)
image_similarity_with_filename = [
{
"file": os.path.basename(p),
"similarity": float(s)
}
for p, s in zip(image_paths, image_similarity)
]
best_idx = torch.argmax(image_similarity).item()
# 結果出力
result = {
"image_similarity_with_filename": image_similarity_with_filename,
"best_image": os.path.basename(image_paths[best_idx]),
"best_path": image_paths[best_idx]
}
return result
4-3.Streamlitファイルの作製
こちらがStreamlitを用いてclip.pyをウェブアプリ化するコードです。このファイルをapp.pyと名付けています。
import streamlit as st
from clip import search_image
import gcsfs
from PIL import Image
st.title("画像検索アプリ")
input_text_by_user = st.text_input("テキストを入力してください")
fs = gcsfs.GCSFileSystem()
if st.button("実行"):
result = search_image(input_text_by_user)
# Streamlit で整形して表示
st.write("類似度:", result["image_similarity_with_filename"])
st.write("検索画像:", result["best_image"])
fs = gcsfs.GCSFileSystem()
with fs.open(result["best_path"], "rb") as f:
result_img = Image.open(f)
st.image(result_img, caption=f"検索結果: {result['best_path']}")
4-4.streamlitサーバーの起動
最後に、CLIPの重みファイル、上記の処理ファイル (clip.py)、streamlitファイル (app.py)をVM上に配置します。そして下記のコマンドを実行すると、app.pyが実行されてVM内でStreamlitサーバーが起動します。
streamlit run clip/app.py --server.port 8501 --server.address 0.0.0.0
そして
http://<VMの外部アドレス>:8501
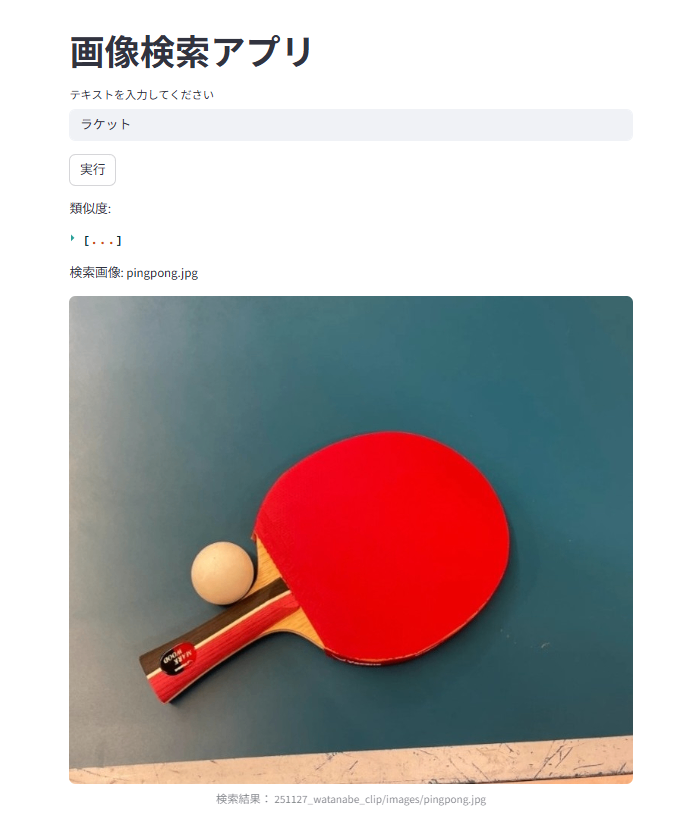
こちらのリンクを踏むと、Webアプリがブラウザ上で立ち上がります。下記が実際の画面になります。

こちらの画面では、”ラケット”という入力テキストに対して、卓球の画像(pingpong.jpg)ヒットしています。

検索対象の画像群は、こちらの15枚としています。
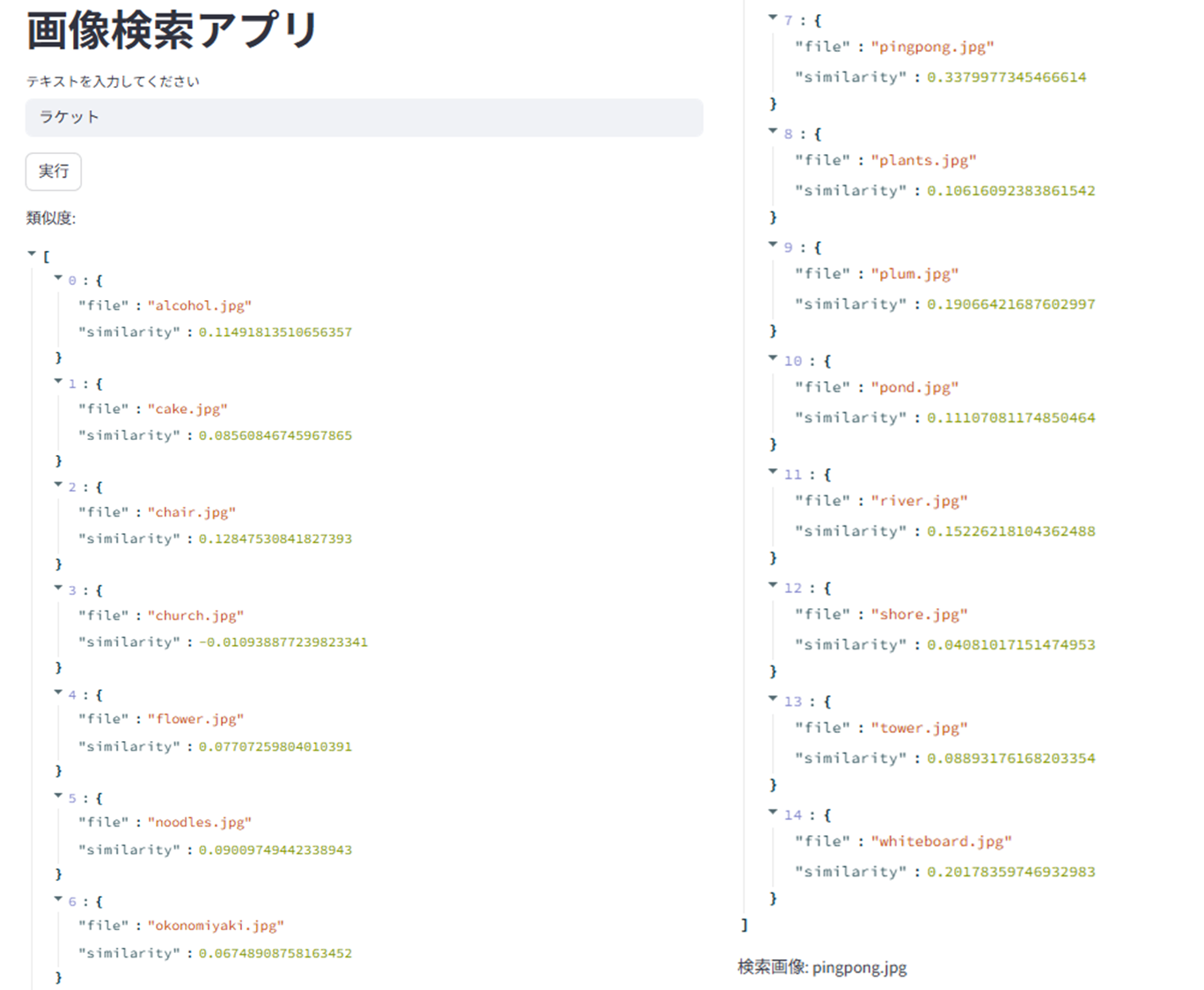
画像の検索に際し、入力テキストのベクトルと画像のベクトルのコサイン類似度を算出しています(下図)。こちらの結果からindex=7、つまり画像群の8番目(pinpong.jpg)で最も類似度が高いことが分かります。
なお、実装中に1度起動してから再起動しなおす場合は、
sudo lsof -i :8501
で表示されるPIDを用いて
sudo kill -9 <PID>
とすることで、占有されていたポート8501が解放されて再起動できるようになります。
5.実装してみての感想
私はこの活動を通じて、
- VLMを活用して画像関連タスクを処理させる手法
- プロダクト化にあたって、VMを活用する方法
の2点について、実践的に学ぶことができました。なお当プロダクトには、
- アプリの自動起動
- 画像の追加機能
- https通信など暗号化
- 検索対象の画像群を事前にベクトル化
などの点が不足しています。今後はFlutterを用いたUIの構築やCloud Runを活用し、こうした点を改善していきたいと考えています。
このように、弊社では社員の実践的な学びをサポートする体制が整っており、社員は自由に技術研究・実装活動を行って研鑽することができます。本記事を通じ、弊社に興味を持っていただけたなら幸いです。ここまでご一読いただきまして、ありがとうございました。
6.参考記事

Discussion