fastai, WandB によるDANN (Domain Adversarial Neural Networks) の学習とメトリック監視
TL;DR
ラベル付きソースドメイン、resnet34ベースモデル、DANNによるドメイン適応でターゲットドメインの高精度な推論を目指します。fastaiの資源を有効活用し、さらにWandBで各ロスやメトリックの監視を行います。
はじめに
典型的な例として、識別・あるいは回帰タスクを行いたいがアノテーション(ラベル付け作業)が困難なデータAがあり、しかしそれを模擬した合成画像データBを生成できる場合を考えます。データAをターゲットドメイン、データBをソースドメインを呼びます。ラベルを用意できるデータBによる教師あり学習では、データBへの推論は機能しますがデータAへは機能しません。これは、データAとBの間にドメインギャップが存在するからです。ドメインギャップは例えば以下です。
- ノイズの有無
- シミュレーションモデルと現実との相違
このドメインギャップを軽減し、ソースドメインを用いて学習したモデルをターゲットドメインへ適用可能にすることが目的です。この技術をドメイン適応といい、その代表的な手法のひとつとしてDANN (Domain Adversarial Neural Networks)[1] があります。
画像認識モデルでは、畳込み層やTransfomerのエンコーダなどの特徴抽出器で画像データを少ない次元数の表現(特徴マップ)に変換し、それに対して全結合層で回帰や識別を行います。DANNによるドメイン適応では、特徴抽出器を通ったデータの分布がソースドメインでもターゲットドメインでも大きく異ならないようにすることでタスクが可能になります。そのために、おおよそ以下のように敵対的学習を行います。
- 特徴抽出器によって画像から特徴マップを得る。
- ソースドメインの特徴マップに対してラベルを予測し真値とのロスを取る。この識別器をラベル予測器と呼び、そのロスをラベルロスと呼ぶ。
- 特徴マップがソースドメインかターゲットドメインか予測し、正解とのロスを取る。この識別器をドメイン識別器と呼び、そのロスをドメインロスと呼ぶ。
- これらのロスの和によってモデルの各パラメータを更新するが、ドメインロスは特徴抽出器のパラメータ更新時だけその符号を反転する。
つまり、ソースドメインの教師あり学習と並行して、特徴抽出器がソースドメインとターゲットドメインを区別可能にするような特徴を出力しないよう学習します。ドメイン識別器自体は通常通り学習されるため、ドメインギャップを0にする特徴抽出器 vs ドメインギャップを検出するドメイン識別器の敵対的学習になっています。詳細は原著論文や日本語の解説記事[2] を参照してください。
教師なしドメイン適応において、敵対的学習ベースのDANNは確かに代表的手法ですが、Diffusion modelの登場以降これによるスタイル変換をベースとした手法も有効なようです。たとえばZoDi[3] があります。DANNやCycleGAN等の敵対的学習手法は安定的な学習が難しいようです。
この記事では、画像を入力とする回帰モデルをDANNで教師なしドメイン適応します。回帰問題はドメイン適応では難しい問題であることに注意が必要です[4]。
resnet34ベースモデルによるDANNの実装
前節4のロスの反転を行うのがGradient reversal layer (GRL)です。特徴抽出器では、resnet34のGlobal average pooling以降を除外して[bs, 512, 2, 2]次元に圧縮する層を追加しています。このプーリング層は[bs, 512, 8, 8]を[bs, 512, 1, 1]にしますが512次元の特徴マップだと筆者のケースでは次元数が小さいためです。ソースドメイン、ターゲットドメインともに2048次元の特徴マップが十分であることはオートエンコーダで確認しています。LabelPredictorの出力次元が3なのは筆者がこの手法を画像から3つの値への回帰問題に用いたいからです。原著論文は識別問題への応用を考えています。DANNを回帰問題に用いているコードの例が少ないので、この記事ではこれ以降この問題設定を前提とします。識別タスクを解く場合も少ない変更で可能です。
import torch
import torch.nn as nn
from torch.utils.data import IterableDataset, DataLoader, Dataset
from torchvision.models import resnet34
from fastai.vision.all import *
import wandb
from fastai.callback.wandb import WandbCallback
from fastai.callback.tracker import SaveModelCallback
import numpy as np
from PIL import Image
from pathlib import Path
from torchvision import transforms
import random
import math
# ソースドメイン生成用に自前で定義した関数
import gen as g
class GradientReversalLayer(nn.Module):
def __init__(self, alpha=1.0):
super().__init__()
self.alpha = alpha
def forward(self, x):
return GradientReversalFunction.apply(x, self.alpha)
class GradientReversalFunction(torch.autograd.Function):
@staticmethod
def forward(ctx, x, alpha):
ctx.alpha = alpha
return x.view_as(x)
@staticmethod
def backward(ctx, grad_output):
return -ctx.alpha * grad_output, None
class FeatureExtractor(nn.Module):
def __init__(self):
super().__init__()
resnet = resnet34(pretrained=True)
self.resnet_layers = nn.Sequential(*list(resnet.children())[:-2])
self.additional_layers = nn.Sequential(
nn.AvgPool2d(2),
nn.Conv2d(512, 512, 4, stride=2, padding=1),
nn.BatchNorm2d(512),
nn.ReLU()
)
def forward(self, x):
x = self.resnet_layers(x)
x = self.additional_layers(x)
return x
class LabelPredictor(nn.Module):
def __init__(self):
super().__init__()
self.regressor = nn.Sequential(
nn.Flatten(),
nn.Linear(512 * 2 * 2, 256),
nn.ReLU(),
nn.Dropout(0.3),
nn.Linear(256, 64),
nn.ReLU(),
nn.Linear(64, 3)
)
def forward(self, x):
return self.regressor(x)
class DomainClassifier(nn.Module):
def __init__(self):
super().__init__()
self.classifier = nn.Sequential(
nn.Flatten(),
nn.Linear(512 * 2 * 2, 256),
nn.ReLU(),
nn.Dropout(0.3),
nn.Linear(256, 1)
)
def forward(self, x):
return self.classifier(x)
class DANN(nn.Module):
def __init__(self):
super().__init__()
self.feature_extractor = FeatureExtractor()
self.label_predictor = LabelPredictor()
self.domain_classifier = DomainClassifier()
self.grl = GradientReversalLayer()
def forward(self, x):
features = self.feature_extractor(x)
regression_output = self.label_predictor(features)
reverse_features = self.grl(features)
domain_output = self.domain_classifier(reverse_features)
return regression_output, domain_output
ロスを定義します。lambda_domainはラベルロスに対するドメインロスの重要度のようなパラメータですが、GRLの定義で登場したalphaもそうです。このコードではalphaは原著論文通りスケジューリングし、lambda_domainはハイパーパラメータとして調整します。regression_loss_valueはWandBで監視するために保存します。このモデルにはソースドメインとターゲットドメインをまとめてバッチで渡しますが、回帰ロスはソースドメインだけに対して計算するのでregression_output_sourceを定義しています。
class DANNLoss(nn.Module):
def __init__(self, lambda_domain=0.1):
super().__init__()
self.lambda_domain = lambda_domain
self.regression_criterion = nn.MSELoss()
self.domain_criterion = nn.BCEWithLogitsLoss()
self.regression_loss_value = None
self.domain_loss_value = None
self.total_loss_value = None
def forward(self, pred, y_source, domain_labels):
regression_output, domain_output = pred
source_size = y_source.size(0)
regression_output_source = regression_output[:source_size]
regression_target = y_source
regression_loss = self.regression_criterion(regression_output_source, regression_target)
domain_loss = self.domain_criterion(domain_output.squeeze(), domain_labels.float())
total_loss = regression_loss + self.lambda_domain * domain_loss
# 個別の損失を保存しておく
self.regression_loss_value = regression_loss.item()
self.domain_loss_value = domain_loss.item()
self.total_loss_value = total_loss.item()
return total_loss
データローダを定義します。これ以降はfastaiのチュートリアルです。g.gen()関数はCuPyを使ってGPUでデータを生成する関数です。ターゲットデータはディスクから読み込みます。
class SourceDataset(IterableDataset):
def __init__(self, data_size=1000):
super().__init__()
self.data_size = data_size
def __iter__(self):
for _ in range(self.data_size):
img, target = g.gen(numpx=256)
yield img.unsqueeze(0).repeat(3, 1, 1), target
def __len__(self):
return self.data_size
class TargetDataset(Dataset):
def __init__(self, img_dir, img_size=256, img_num=1000):
super().__init__()
self.img_dir = Path(img_dir)
self.img_paths = random.sample(list(self.img_dir.glob('*.png')), k=len(list(self.img_dir.glob('*.png'))))
self.img_num = img_num
self.transform = transforms.Compose([
transforms.Resize((img_size, img_size)),
transforms.ToTensor(),
])
def __getitem__(self, idx):
img_path = self.img_paths[idx]
img = Image.open(img_path).convert('RGB')
return self.transform(img)
def __len__(self):
return self.img_num
DANN用のLearnerを定義します。かなり実装が冗長ですが、ChatGPTと壁打ちしながら書いたのとリファクタリングが面倒なのでとりあえず動く以下でOKとしています。Learnerに渡すコールバックでソースドメインとターゲットドメインのデータをコンバインしモデルに渡します。alphaのスケジューリングもここで行います。WandbCallbackだけでは監視できない量はこのコールバックの実装[5] を真似て追加しています。
def train_dann(
target_path,
validation_target_path,
source_data_size=1000,
source_buffer_size=1000,
validation_data_size=1000,
batch_size=32,
n_epoch=100,
lambda_domain=0.1,
run_name=None,
project_name='your_project_name'
):
"""DANNの学習実行"""
# ソースデータセットとデータローダー(学習用)
source_dataset = SourceDataset(
data_size=source_data_size,
)
source_dl = DataLoader(
source_dataset,
batch_size=batch_size,
num_workers=0 # GPUを使用するg.gen()のため
)
# ソースデータセットとデータローダー(検証用)
source_val_dataset = SourceDataset(
data_size=validation_data_size,
)
source_val_dl = DataLoader(
source_val_dataset,
batch_size=batch_size,
num_workers=0
)
# ターゲットデータセットとデータローダー(学習用)
target_dataset = TargetDataset(
img_dir=target_path,
img_size=256,
img_num=source_data_size # 学習用のデータ数を指定
)
target_dl = DataLoader(
target_dataset,
batch_size=batch_size,
shuffle=True,
num_workers=4,
pin_memory=True
)
# ターゲットデータセットとデータローダー(検証用)
target_val_dataset = TargetDataset(
img_dir=validation_target_path,
img_size=256,
img_num=validation_data_size # 検証用のデータ数を指定
)
target_val_dl = DataLoader(
target_val_dataset,
batch_size=batch_size,
shuffle=False,
num_workers=4,
pin_memory=True
)
# DataLoadersの作成(検証データはソースとターゲットの両方を使用)
dls = DataLoaders(source_dl, source_val_dl) # FastAIのLearnerにはソースデータを渡す
# モデルとLearnerの作成
model = DANN()
loss_func = DANNLoss(lambda_domain=lambda_domain)
learn = Learner(dls, model, loss_func=loss_func, splitter=dann_splitter)
# WandBの初期化
if run_name is not None:
wandb.init(project=project_name, name=run_name)
else:
wandb.init(project=project_name)
# DANN用のコールバック
class DANNCallback(Callback):
def __init__(self, total_epochs, target_dl):
self.total_epochs = total_epochs
self.epoch = 0
self.target_dl = target_dl # データローダーをインスタンス変数として保持
def before_fit(self):
self.target_iter = iter(self.target_dl)
if wandb.run is None:
raise ValueError('You must call wandb.inig() before DANNCallback')
self._wandb_step = wandb.run.step -1
self._wandb_epoch = 0 if not(wandb.run.step) else math.ceil(wandb.run.summary['epoch'])
self.learn._wandb_step = self._wandb_step # 追加
def before_batch(self):
if self.learn.training:
# ターゲットドメインのバッチを取得
try:
x_target = next(self.target_iter)
except StopIteration:
self.target_iter = iter(self.target_dl)
x_target = next(self.target_iter)
x_source, y_source = self.xb[0], self.yb[0]
x_target = x_target.to(x_source.device)
x_combined = torch.cat([x_source, x_target], dim=0)
domain_labels = torch.cat([
torch.zeros(x_source.size(0)),
torch.ones(x_target.size(0))
]).to(x_source.device)
# 学習率のスケーリング係数αの計算
p = self._wandb_epoch / self.total_epochs
# p = self.epoch / self.total_epochs
alpha = 2. / (1. + np.exp(-10 * p)) - 1
self.learn.model.grl.alpha = alpha # self.modelをself.learn.modelに変更
# 学習に使用するデータとラベルの設定
self.learn.xb = (x_combined,)
self.learn.yb = (y_source, domain_labels)
def after_batch(self):
if self.training:
self._wandb_step += 1
self._wandb_epoch += 1/self.n_iter
self.learn._wandb_step = self._wandb_step # 追加
wandb.log({'regression_loss': self.learn.loss_func.regression_loss_value, 'domain_loss': self.learn.loss_func.domain_loss_value}, step=self._wandb_step)
def after_epoch(self):
self.epoch += 1
self._wandb_epoch = round(self._wandb_epoch)
wandb.log({'epoch': self._wandb_epoch}, step=self._wandb_step)
class DANNValidationCallback(Callback):
def __init__(self, source_val_dl, target_val_dl):
self.source_val_dl = source_val_dl # データローダーをインスタンス変数として保持
self.target_val_dl = target_val_dl
self.source_preds = []
self.source_targets = []
self.domain_preds = []
self.domain_targets = []
def before_validate(self):
self.source_val_iter = iter(self.source_val_dl)
self.target_val_iter = iter(self.target_val_dl)
self.source_preds = []
self.source_targets = []
self.domain_preds = []
self.domain_targets = []
def before_batch(self):
if not self.learn.training:
if not hasattr(self, 'source_val_iter'):
self.source_val_iter = iter(self.source_val_dl)
if not hasattr(self, 'target_val_iter'):
self.target_val_iter = iter(self.target_val_dl)
# 検証時のバッチ処理
try:
x_source_val, y_source_val = next(self.source_val_iter)
except StopIteration:
self.source_val_iter = iter(self.source_val_dl)
x_source_val, y_source_val = next(self.source_val_iter)
try:
x_target_val = next(self.target_val_iter)
except StopIteration:
self.target_val_iter = iter(self.target_val_dl)
x_target_val = next(self.target_val_iter)
x_source_val = x_source_val.to(self.dls.device)
y_source_val = y_source_val.to(self.dls.device)
x_target_val = x_target_val.to(self.dls.device)
x_combined_val = torch.cat([x_source_val, x_target_val], dim=0)
domain_labels_val = torch.cat([
torch.zeros(x_source_val.size(0)),
torch.ones(x_target_val.size(0))
]).to(self.dls.device)
self.learn.xb = (x_combined_val,)
self.learn.yb = (y_source_val, domain_labels_val)
def after_batch(self):
if not self.learn.training:
regression_output, domain_output = self.pred
y_source, domain_labels = self.learn.yb
source_size = y_source.size(0)
# ソースデータの処理
regression_output_source = regression_output[:source_size]
y_source = y_source.cpu()
regression_output_source = regression_output_source.cpu()
self.source_targets.append(y_source)
self.source_preds.append(regression_output_source)
# ドメイン分類器の処理
domain_output = domain_output.squeeze().cpu()
domain_labels = domain_labels.cpu()
self.domain_preds.append(domain_output)
self.domain_targets.append(domain_labels)
def after_validate(self):
# 収集したデータを結合
source_targets = torch.cat(self.source_targets)
source_preds = torch.cat(self.source_preds)
domain_targets = torch.cat(self.domain_targets)
domain_preds = torch.cat(self.domain_preds)
# 各出力ごとのRMSEを計算
rmse = torch.sqrt(torch.mean((source_preds - source_targets) ** 2, dim=0))
rmse_dict = {
'rmse_num_particles': rmse[0].item(),
'rmse_planer_dist': rmse[1].item(),
'rmse_depth_dist': rmse[2].item()
}
# ドメイン分類器の精度を計算
domain_preds_labels = (torch.sigmoid(domain_preds) > 0.5).float()
domain_accuracy = (domain_preds_labels == domain_targets).float().mean().item()
# WandBにログ
if hasattr(self.learn, '_wandb_step'):
wandb.log({**rmse_dict, 'domain_accuracy': domain_accuracy}, step=self.learn._wandb_step)
else:
wandb.log({**rmse_dict, 'domain_accuracy': domain_accuracy})
# コールバックの追加
learn.add_cb(DANNCallback(total_epochs=n_epoch, target_dl=target_dl))
learn.add_cb(DANNValidationCallback(source_val_dl=source_val_dl, target_val_dl=target_val_dl))
learn.add_cb(WandbCallback(log='all', log_preds=False))
learn.add_cb(SaveModelCallback())
# GPUが利用可能な場合は使用
if torch.cuda.is_available():
learn.model = learn.model.cuda()
learn.dls.cuda()
return learn
事前学習したresnet34バックボーンだけをfreezeできるようにsplitterを定義します。また、fine_tuneを少し変更してfine_tune_dannを定義します。
def dann_splitter(model):
return [
params(model.feature_extractor.resnet_layers),
params(model.feature_extractor.additional_layers),
params(model.label_predictor),
params(model.domain_classifier),
params(model.grl)
]
@patch
@delegates(Learner.fit_one_cycle)
def fine_tune_dann(self:Learner, epochs, base_lr=2e-3, freeze_epochs=1, lr_mult=100,
pct_start=0.3, div=5.0, **kwargs):
"Fine tune with `Learner.freeze` for `freeze_epochs`, then with `Learner.unfreeze` for `epochs`, using discriminative LR."
self.freeze_to(1)
self.fit_one_cycle(freeze_epochs, slice(base_lr), pct_start=0.99, **kwargs)
base_lr /= 2
self.unfreeze()
self.fit_one_cycle(epochs, slice(base_lr/lr_mult, base_lr), pct_start=pct_start, div=div, **kwargs)
# 使用例
"""
# モデルの学習
n_epoch = 2
learn = train_dann(
target_path="../data/train/",
validation_target_path="../data/test/",
source_data_size=1000,
source_buffer_size=1000,
batch_size=64,
n_epoch=n_epoch,
run_name="your_run_name"
)
lr = learn.lr_find()
learn.fine_tune_dann(n_epoch, lr)
wandb.finish()
結果
WandBにアクセスして、回帰するそれぞれの量のRMSEや、DANN特有のそれぞれのロスを可視化できます。回帰ロスが低下しながらドメイン識別精度を0.5になっていることを確認できます。ソースとターゲットを区別できないよう特徴抽出器を学習できます。
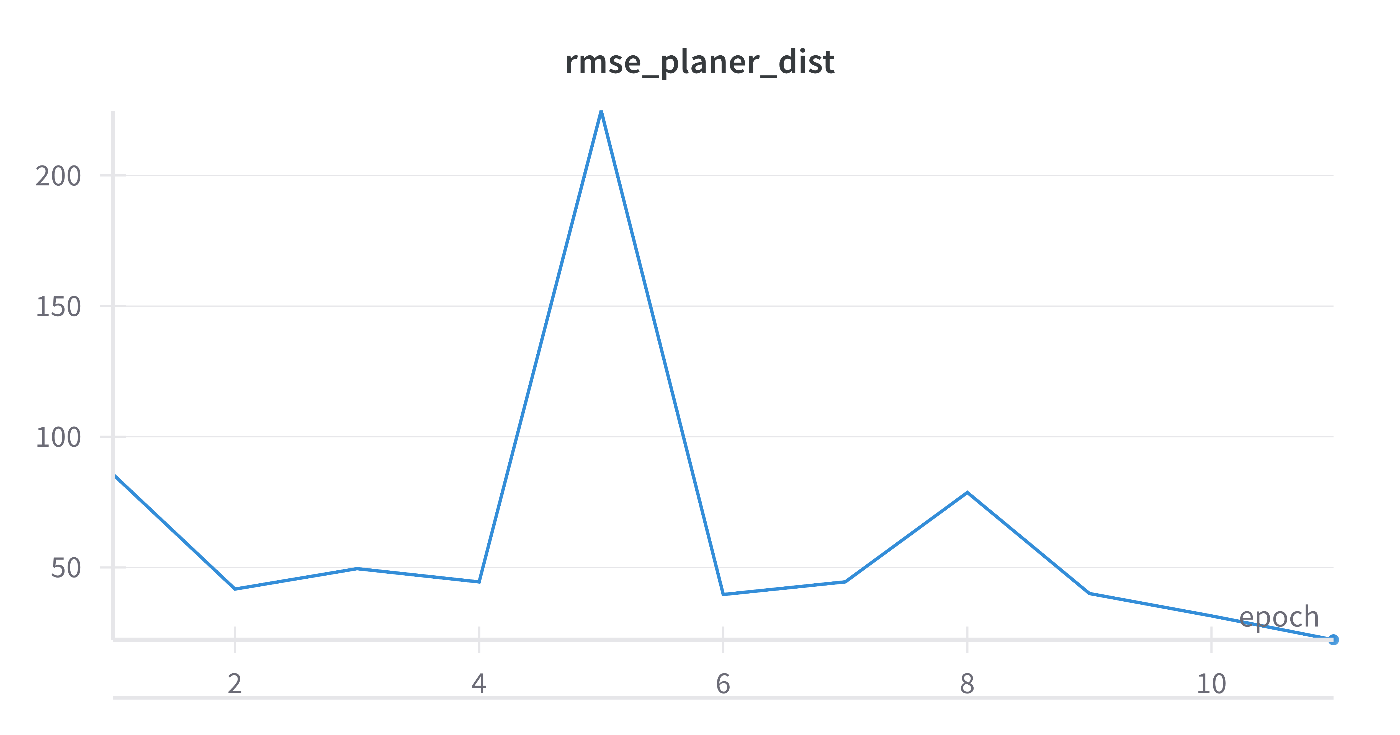
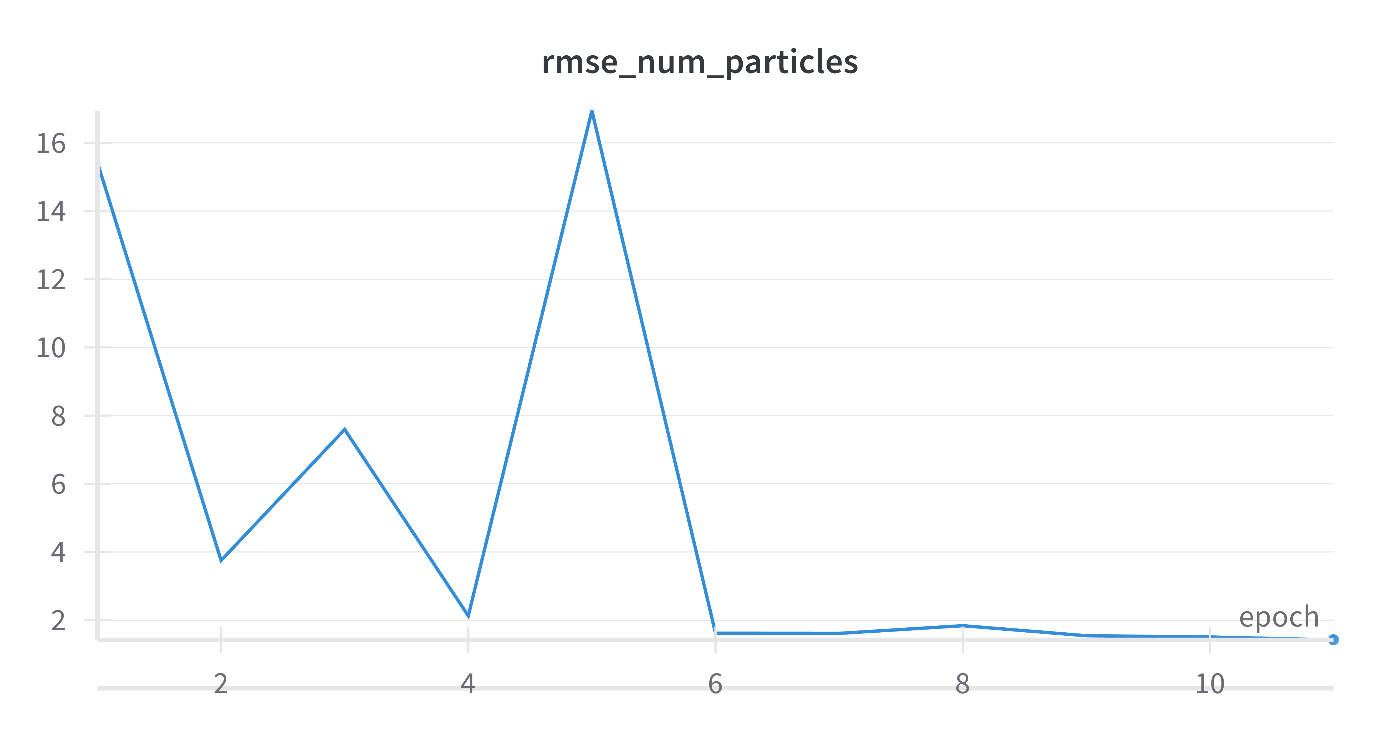
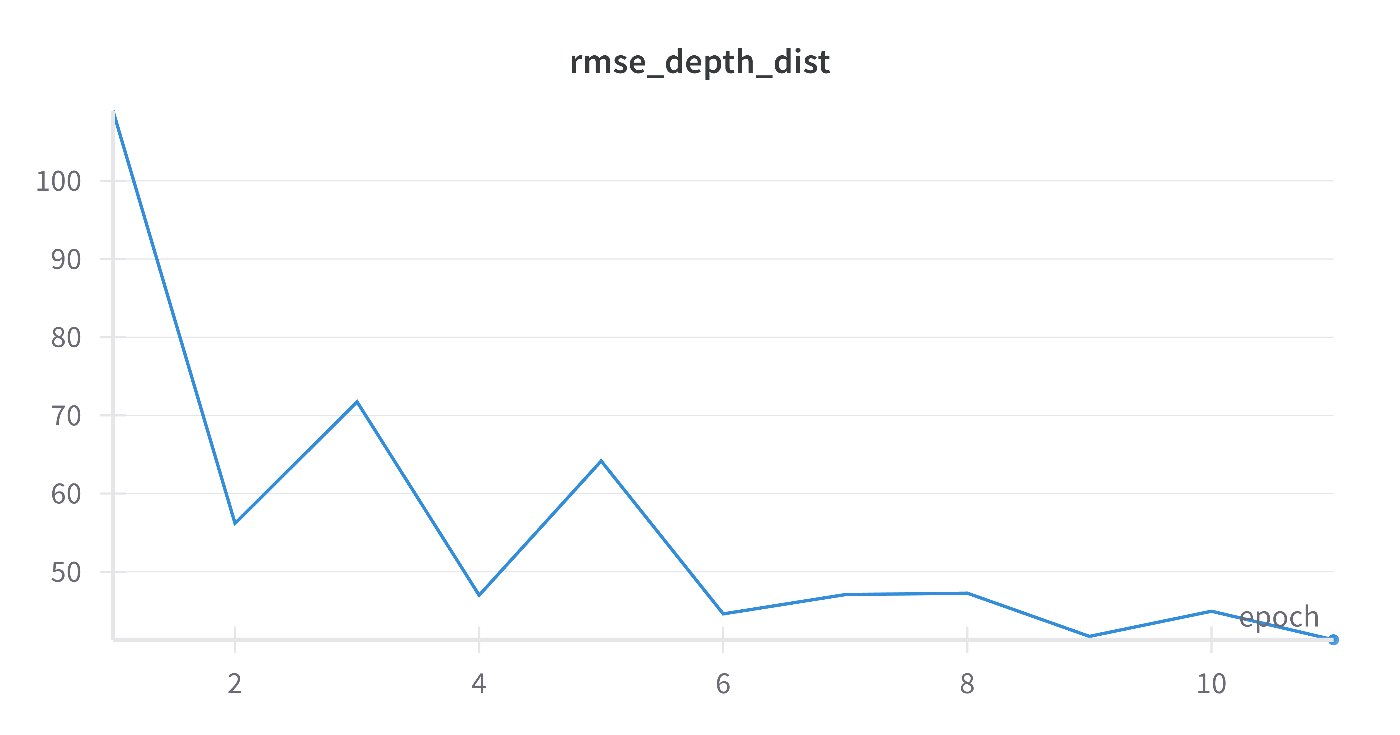
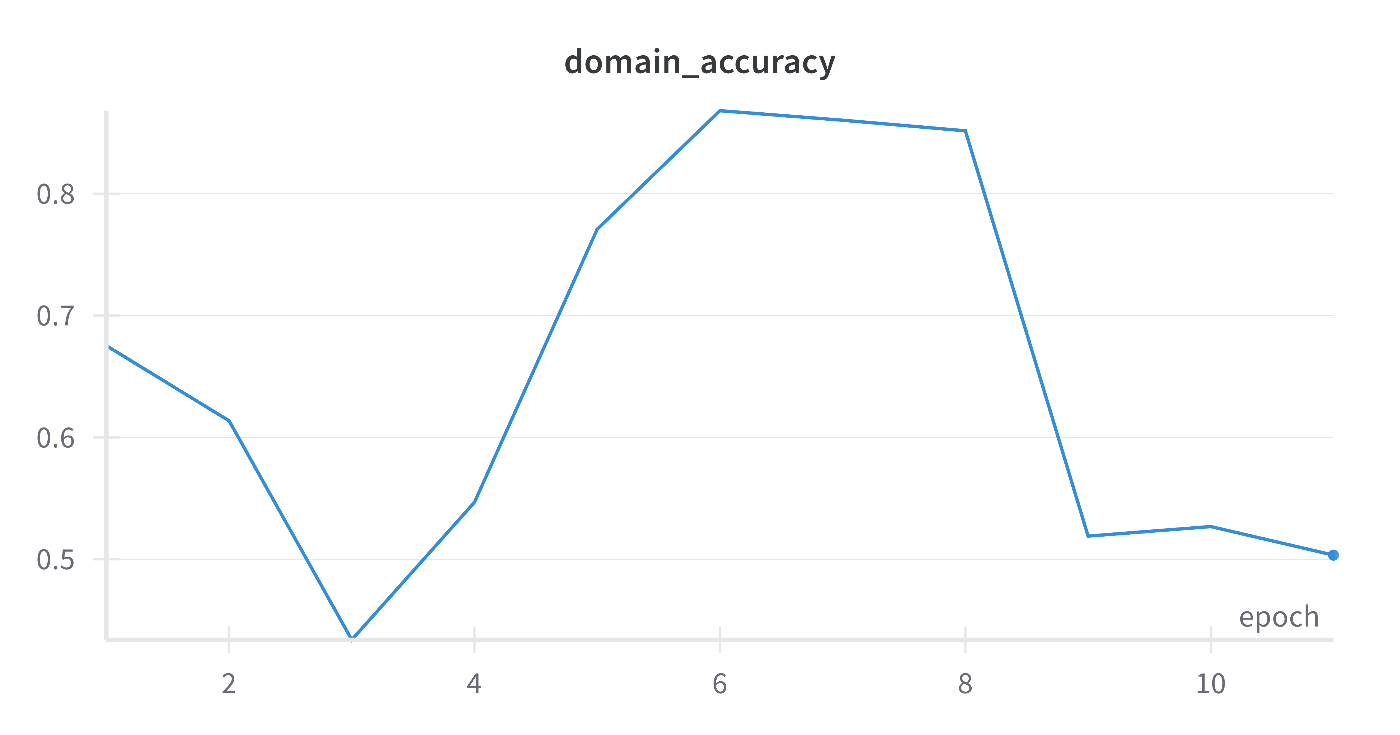
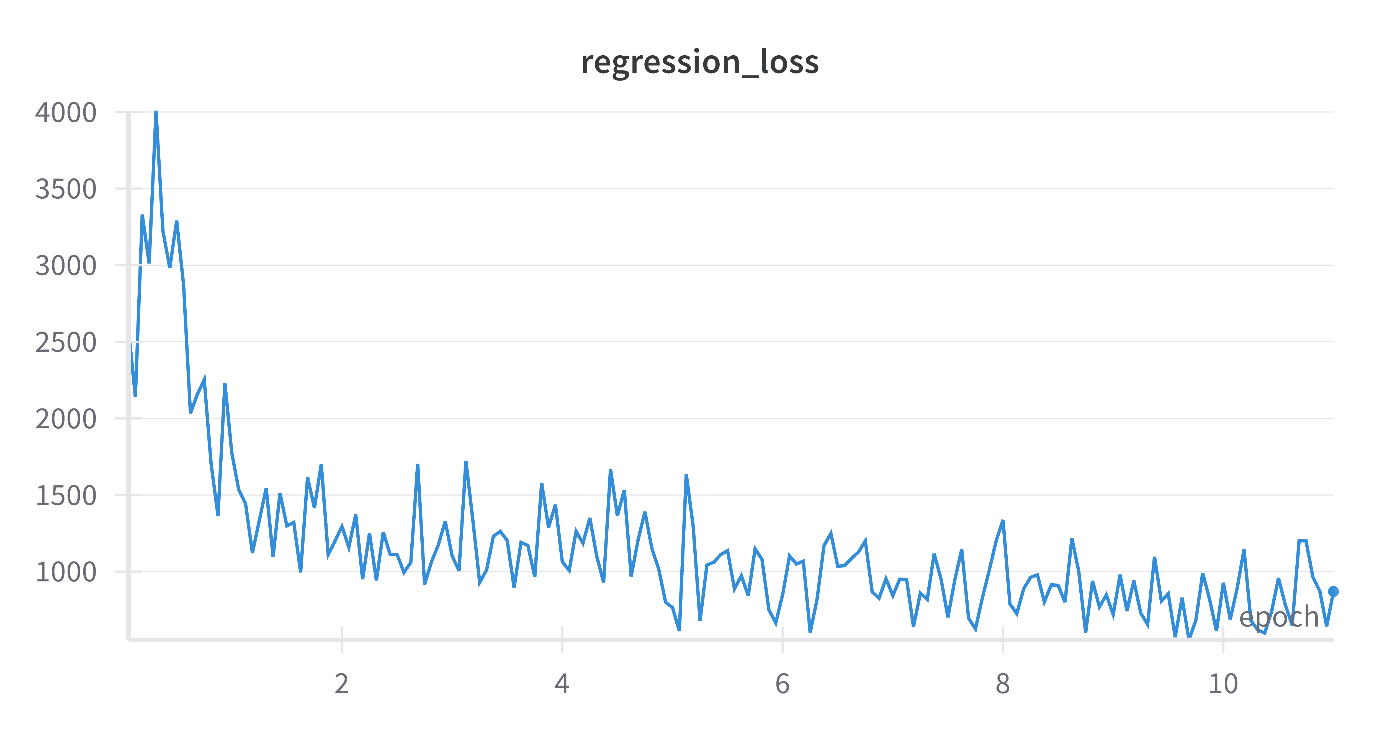
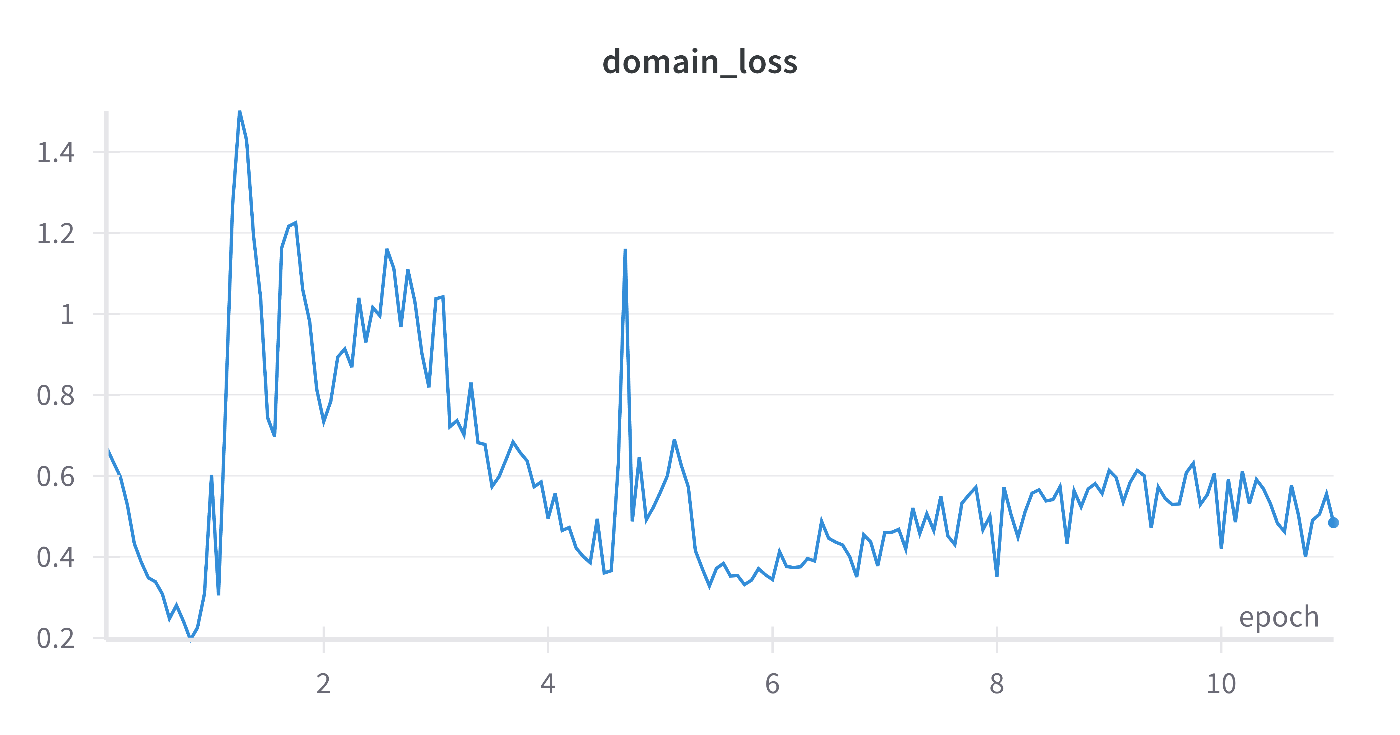
次はZoDiを試してみたい。
Discussion