Kindle に入っているビジネス書をオーディオブック化したい
TL; DR
- ゴールデンウィークの自由研究として、 Kindle 書籍を音声化するアプリケーションを作って公開したよ
- 手元の PC で書籍部分を抜き出して画像化するよ。 macOS では Automator を使って Kindle.app を自動でページめくりさせてスクショをとるよ
- できた PDF を GCP の Cloud Storage にアップロードすると、 Cloud Functions が起動して Vision API + Text-to-Speech に突っ込んで MP3 ができあがるよ
- 著作権の問題から Web サービスとして公開はしないけど、自分用に環境構築して使えるよ。慣れてない人でも30分〜1時間くらいでできると思うよ
- 一度環境構築すれば、あとは1冊10分以内、費用もほぼ無料〜1冊最大200円程度で好きな Kindle 書籍を音声化できて、積ん読消化が捗るよ
はじめに
書籍を音声で聞きたいというニーズは一定あると想定されます。日本で利用できる書籍を聞くサービスにはいくつかあり、代表的なものに Audible や audiobook.jp があります。
しかしこれらにはいくつか問題点があると考えています。
- 品揃えが不十分:最大の問題です。これらのサービスは書籍をもとに人が音読して録音しているため、どうしてもコストがかかるうえ出版されてから音声化されるまでの時間もかかります。結果、聞きたい本が音声化されていない、ということが頻発します。
- DRMによる制限:著作権保護の観点から仕方のないことですが、例えば音声の吹き込まれたMP3ファイルを抽出して編集したり好きなソフトウェアで再生したりということができません。
- 価格が高い:Audible はざっくり1冊あたり1,500円以上します。個人的にテキストの書籍を買わずにオーディオブックだけ買うというケースはほぼないため、普通の Kindle 版 + Audible で二重で金額がかさみます。一方 audiobook.jp は月750円の聴き放題サービスがあるため、こちらは十分安価だと言えるでしょう。
「Kindle 読み上げ」といったキーワードで検索すると、 Kindle アプリで閲覧している書籍を PC やスマートフォンに読み上げさせるという手法が見つかります。 iPhone の VoiceOver や Android の Talkback といった OS の機能を使って Kindle の書籍を読み上げさせるというものです。当然この方法も試しましたが、音声の流暢さは書籍を聞くという用途において耐えられるものではなく、また読み上げ中に OS レベルで操作性が著しく落ちるという問題もありとても常用できるものではありませんでした。
ないならば、ということで書籍画像から音声を生成するアプリケーションを作ってみました。 Kindle アプリを使っているところのスクリーンショットを使って Kindle の書籍を画像化し、それを PDF にまとめ、 Google Cloud の Vision API に突っ込んで OCR によりテキストを抽出します。それを Text-to-Speech に再び突っ込んで、音声化するという手法です。
音声のクオリティは Text-to-Speech に依存します。もちろん人間が読み上げたものほど流暢とはいきませんが、十分聞けるクオリティの音声になります。使ったことがない場合は軽く触ってチェックしてみてください。
アイディアについては以下の記事を参考にさせていただきました。といか二番煎じという方が適切かもです。 こちらの手法はヘッダー・フッターや図など本文と関係ない部分を AutoML を使って検出し、その部分を読み上げ時に省略しています。ただし教師データのアノテーションなど準備が少し大がかりで手間もかかるため、より簡単に使えることを目指しました。
作ったもの
GitHub 上で公開しています。
前提・コンセプト
- 主な対象はテキスト中心のビジネス書や新書、小説
-
現状の想定は Kindle で閲覧した際に縦書きで左に進むもの- 横書き右に進むものも対応できました
- 現状では挿絵や図の読み取りに対しては特別な扱いをしておらず、その箇所に差し掛かるとやや意味の汲みづらい読み上げとなってしまう
-
- 音声のクオリティ(流暢さ、抑揚など)はそこまでこだわらない
- Text-to-Speech で生成された音声は棒読み気味だが、それでも音声の95%程度は難なく意味が伝わり、残りの5%もそれほど苦労せず意味が推測できるという程度の出来
- できるだけ安価・メンテナンスフリーにすること
クライアント側
クライアント側 (手元の PC) では音声化する書籍の PDF データを作ります。
ここでは macOS 上の Kindle.app のスクリーンショットを1ページずつ撮って内容部分を切り抜くというアプローチをとることにしました。そのための Automator アプリをリポジトリ内に含めています。
ちょっと早送りですが以下のように動きます。
バックエンド側
GCP 上に構築する想定で作っています。 GCP のアカウントを持っていれば、以下のステップで準備が完了します。
- 新規プロジェクト / Cloud Storage bucket を作成し、各種 API を有効化
- 環境に合うように設定ファイルを編集
- Cloud Functions をデプロイ
この後は Cloud Storage に PDF をアップロードして数分待てば音声化された書籍がダウンロードできるようになります。
Web サービスとして多くの人がブラウザからPDFファイルをアップロードするだけで使えるようにすることも考えましたが、アップロードされたファイルに含まれる書籍の著作権の扱いが不明のため、サービス運営者以外がアップロードできる形での公開はしません。ただし、自分で環境を整えて、自分で書籍をキャプチャしたものを自分のために処理するだけならば、私的利用の範囲に入るため問題ないと考えます。また、著作物の複製をクラウドストレージに保存することについてはクラウドサービス等と著作権についてという文化庁の報告書が詳しく、プライベートなクラウドサービスに利用者のみがアクセスできる形での利用は権利者の許諾は不要であるという見解が示されています。
詳細
以下では作ったものの詳細とステップを説明していきます。
書籍の内容を含んだ PDF ファイルを生成
OCR と Text-to-Speech を使って PDF ファイルを音声化するというアプローチですが、まず手元の PC ではその入力となる書籍の内容を含んだ PDF ファイルを作ります。
しかし Kindle 書籍の内容を抽出したり、 PDF にするのは Kindle の書籍データに DRM がかかっているため簡単にはできません。ここではアナログな解決策ですが、「PC 上の Kindle アプリを自動でページめくりさせてスクリーンショットを取る」という方法をとることにしました。
macOS の Automator を使ってこれを実現しており、この Automator アプリもリポジトリに入っています。やっていることはシンプルで、 Kindle.app をアクティブ化してスクリーンショットを撮り、ページをめくる、という動作を動作を繰り返します。
Kindle.app で表示されるページは紙の書籍と違い、 Location という単位で管理されています。また表示する Location は Kindle.app を表示するウィンドウサイズによって変わります。そのため何ページめくればよいのかが自明でないという問題があります。最後のページ辿り着いたか (および同じページのスクショをとっていないか) を検出するために、 ImageMagick の compare コマンドで画像の差分が一定値を超えていないかをチェックすることにしました。
「ページめくりしてスクリーンショットを撮る」というアプローチの問題は、この作業中に他の作業ができなくなる点です。ただ、数分ほど待てばいいだけなのでそこまで大きな問題ではありません。別の方法として仮想マシンを立てて仮想マシン内でスクリーンショットを撮るとかも考えたのですが、ホストマシンと別にアカウント認証が必要だったり、ちょっと大掛かりでやりたくないです。いい方法があったら教えてほしい。
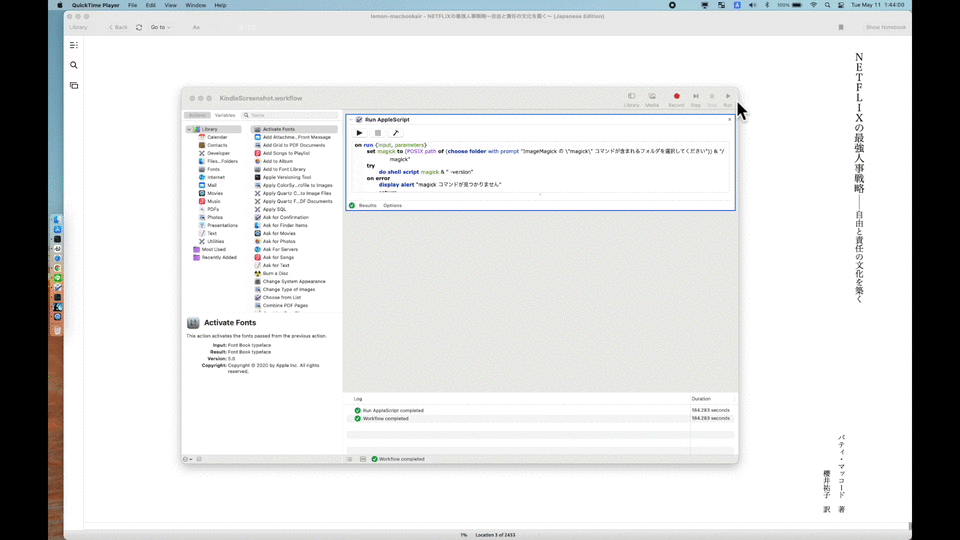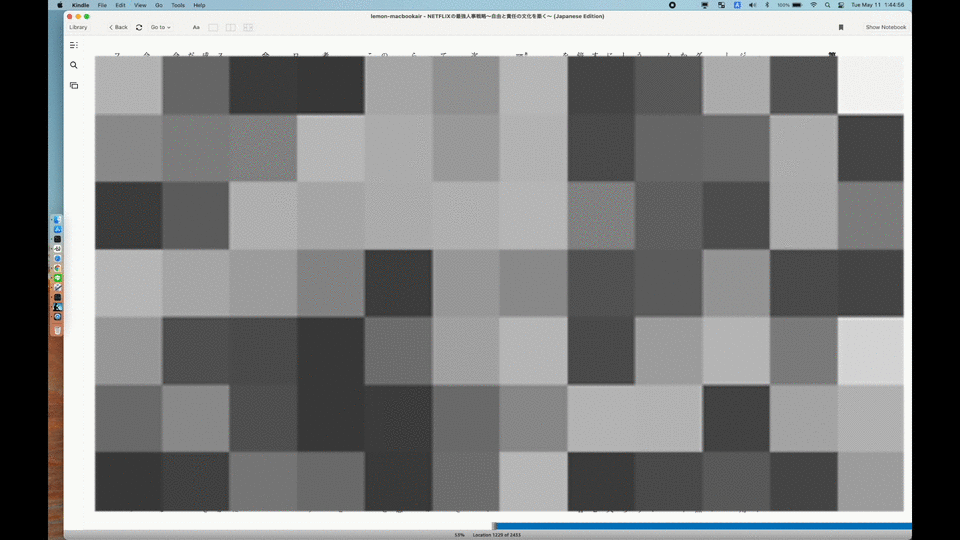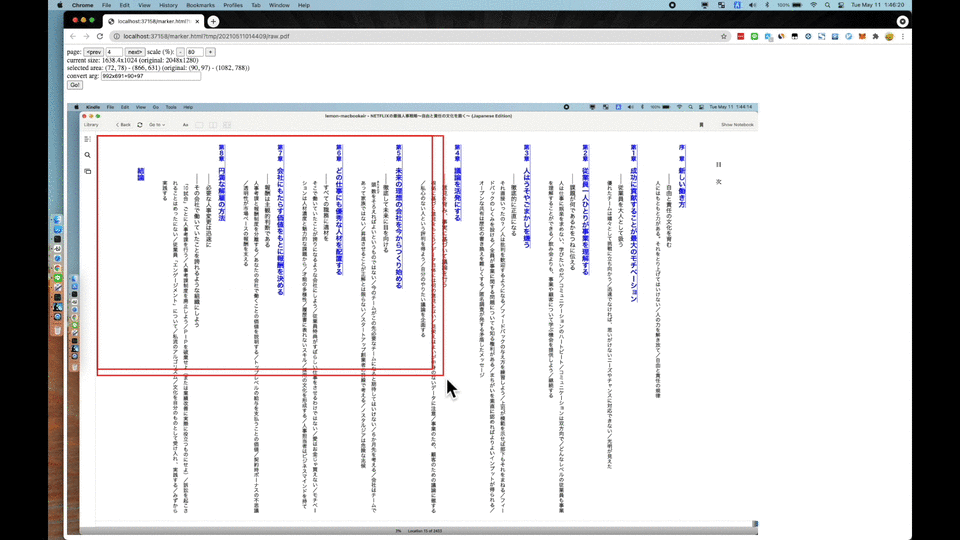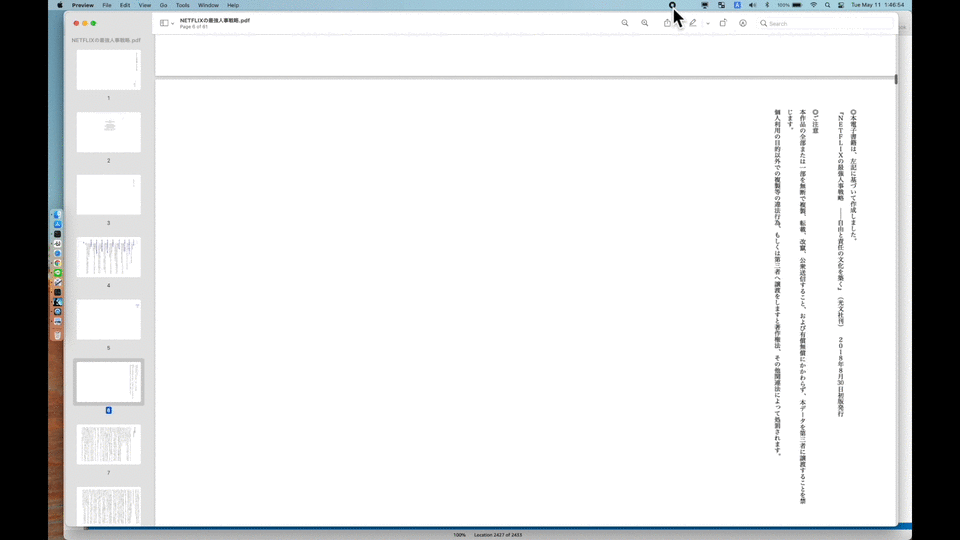
この後、ここで作った PDF ファイルから本文が表示されている箇所をトリミングします。後に OCR にかけるタイミングで、入力する PDF ファイルは、各ページに含まれる文章が音声化してほしい箇所のみである必要があります。つまり音声化してほしくないヘッダー・フッターやページ番号を含まないような箇所を抽出します。
ここではブラウザ上で撮影したスクリーンショットを表示し、その上でトリミングする範囲をユーザーが指定すると、 ImageMagick の convert -crop の引数を出力する、という簡単な HTML + JavaScript アプリケーションを作っています。 Automator の中身を見てみるとわかるのですが、画像のトリミング範囲を指定するために、ローカルに http サーバを立てたりポーリングで clipboard の変更を検知したりと涙ぐましいことをやってます。 AppleScript 難しい。
このように Kindle アプリ上の書籍を PDF にする方法はかなりアナログなのですが、ここは DRM を突破する本質的な方法がない以上ある程度は仕方がないかなと思っています。ただ、本文抽出とかはもうちょい賢くやれる気もします。シンプルさと使い勝手の両立がなかなか難しい。
Windows ユーザーは別の方法を探してください (Pull Request Welcome)
バックエンドアーキテクチャ
次に、作った PDF ファイルを OCR にかけて喋らせるところです。このバックエンドはすべて GCP で作っています。
アーキテクチャ図を見ればわかるかと思いますが、処理のフローは以下のようになっています。
- ユーザーが Cloud Storage に PDF ファイルをアップロード
- Storage Event をトリガーとして Cloud Functions が起動
- アップロードされた PDF ファイルに Cloud Vision API の OCR 処理をかけ、結果を Cloud Storage に保存
- 複数の JSON ファイルが生成される
- OCR 結果の JSON ファイルからテキストを抽出
- 抽出したテキストを Text-to-Speech API にかけ、結果を Cloud Storage に保存
- 1回あたり5,000文字までの制限があるため、5,000文字以内の文章単位で複数回API呼び出し
- 結果として複数の MP3 ファイルが生成される
- Text-to-Speech 結果の MP3 ファイルを結合して Cloud Storage に保存
少し苦労したところ、および今後も改善の余地があるところとしては OCR の結果からテキストを抽出するところです。
OCR では改行を単語の区切りとみなしてしまうため、 Text-to-Speech にかけるときに単語を続けて読むような処理をいれなければなりません。しかし単に続けて読むと、今度は見出しなどの続けて読んでほしくないものまで続けて読むようになってしまいます。これを回避するために、そのページ内での最大の Y 座標より小さな位置で改行されているものは文章の区切りであるとみなすような処理を入れています。
また、前述したとおり図に含まれるテキストは OCR で検出したものをそのまま読み上げているため、図の箇所に差し掛かると聞き取りづらくなってしまいます。これをいい感じに読み飛ばすためには、先行事例にあるような図を検出するような機械学習モデルを使う必要が出てきそうです。
さて、このような趣味プロジェクトにはメンテナンスコストはかけたくないためできるだけメンテナンスフリーになるようにしています。
- 常時起動のサーバを持たない:ストレージとして Cloud Storage を使い、またアプリケーション自体もバッチ処理を中心として Cloud Functions にスケジューラを任せることにしました。
- UIを実装しない:ユーザーは書籍化したい PDF ファイルを Cloud Storage にアップロードするだけでバッチ処理が走ります。また、生成された MP3 ファイルも Cloud Storage の UI からダウンロードできます。実際、私はスマートフォンの Cloud Console アプリからダウンロードしています。
変換結果について
PDF を Cloud Storage にアップロードしてから最後の MP3 ファイルができあがるまで、ほとんどのケースで5分もあれば完了します。すごい。
実行エラーが起きる場合は Cloud Functions のページから PdfAudify ジョブの実行ログを見ると原因がわかるかもしれません。
Google Cloud の Text-to-Speech には、音声合成のオプションとして Standard と WaveNet があります。料金ページにある通り、 Standard のほうが月間無料枠が4倍あり、無料枠を超えた有料課金分も1/4の価格です。個人的には日本語においては Standard と WaveNet でそこまで違いが感じられなかったため、 Standard で十分なのではないかと思います。
生成されたオーディオブックは、紙の書籍でA5版500ページ程度のビジネス書の場合、音声にして12時間程度、容量は200MB程度が目安です。 Text-to-Speech のデフォルトの音声は読み上げがゆっくりなので、 1.5倍速〜2倍速くらいで聞くとちょうど良いです。
また、この500ページ程度の書籍でも試したところでも5分程度で処理が終わり、十分高速なため1度の Cloud Functions の起動ですべての処理を行っています。これがもう少し時間がかかる場合は、 Cloud Functions の処理を分割することも考えられます。
また、一部の書籍 (10%ほど?) において OCR 処理でうまくテキストを抽出できないケースがあることがわかっています。 画像切り抜きの方法などを調整したり Vision API のパラメータを調整するなどで修正できる可能性がありますが、現状ではできていません。
コスト
GCP は各サービスごとに毎月の無料枠と使用量あたりの従量課金額が決められており、若干計算が複雑になります。これに加えて登録時の無料クレジット $300 も加味するとさらに計算が複雑です。
結論からいうと超ざっくりの見積もりで、
- 新規登録時の無料クレジットを全部突っ込むとすると150冊分までは無料
- 無料クレジットを使い切った後は、月3冊まではほぼ無料、月3冊を超えると1冊50円、月10冊を超えると1冊230円
という感じです (2021年5月10日現在) 。ただこれは1冊あたり紙でA5版500ページという多めの分量での見積もりなので、実際はもう少し安くなると思います。
詳しい計算を知りたい場合は以下。
今回のアーキテクチャのうちもっともコストがかかるのは Text-to-Speech API, ついで Vision API の利用料です。ざっくり試した感じで従量課金分だけを考慮すると、紙でA5版500ページ程度のビジネス書の場合、1冊あたりの従量課金分は計230円程度、内訳としては以下のような金額感です。
価格表 (紙の書籍でA5版500ページ程度のビジネス書の場合、2021年5月10時点)
| 区分 | 毎月無料枠 | 単価 (USD) | 単位 | 1冊あたり使用量 | 1冊あたり従量課金 (USD) | 1冊あたり従量課金 (JPY) |
|---|---|---|---|---|---|---|
| Text-to-Speech API (Standard) | 4,000,000 chars | 4.00 | 1,000,000 chars | 400,000 chars | 1.6 | 175 |
| Cloud Vision API | 1,000 units | 1.50 | 1,000 units | 300 units | 0.45 | 50 |
| Download APAC | - | 0.12 | 1 GB | 0.2 GB | 0.024 | 3 |
| その他 | - | - | - | - | < 0.01 | < 1 |
ちなみに Text-to-Speech API の音声合成を WaveNet にした場合は1冊800円程度になります。これだけ金額が違うと、多少音声のクオリティが低くても Standard にしたくなりますね。
上記料金表をベースに、毎月無料枠を考慮した1ヶ月の冊数あたりの料金 (円) のグラフを書くこんな感じになります。3冊まではほぼタダで使え、10冊までは Text-to-Speech が無料で使えるため10冊の場合で計400円。それ以降は1冊あたりが高くなり30冊の場合で計5,000円という感じです。それでも十分安いですが。
また登録時の $300 = 32,000円の無料クレジットを使うとするとこの5倍程度で150冊までいけます。これだけあれば聞きたい本を全部音声化できそうですね。
まとめ
Kindle アプリを自動でページめくりしながらスクリーンショットを撮りつつ、まとめた PDF を OCR にかけて結果を Text-to-Speech で喋らせてオーディオブック化する、というアプリを実装しました。システム全体としては Kindle の書籍を想定していますが、オーディオブック化の部分自体は PDF であれば何でも動くはずです。
実際作ってみて、めちゃくちゃ便利です。通勤中や外を散歩しているとき、ジムでのトレーニング時、入浴中などあらゆる時間を読書時間に変えられます。積極的に目で文字を追えない・追う気分になれないときもとりあえずBGM的に流しておくということができるようになったのは大きいです。誇張でなく読書量10倍になったと感じます。今のオーディオブックの品揃えに不満を持っている方は試してみてください。
Discussion
kindle本ということであれば、Alexaアプリでわりといい感じに(バックグラウンドでも)読み上げてくれるとつい数か月間に知りました。
ありがとうございます!知りませんでした。確かにこっちのが手軽で読み上げもいい感じですね…
Alexa のほうは再生速度が変えられなかったりプレイヤーの使い勝手がイマイチなところもありそうなので、必要に応じて使い分けられると良さそうですね!
pyautoguiを使って、Windows版でKindleのスクリーンショットを撮る事ができました。
Windows版のKindleはフルスクリーン表示すると、外枠などもなくなるので、切り出す手間が不要で、スクリプト書くのもかなり楽でした。
その後は、daimatzさんのプログラムを使って、PDFを音声に変換できました!ありがとうございます。