日経先物分析その3...SQ別の値動きに特徴はあるか(1)




その2では何をしたのか
"その2"では日経先物のタイムバーにSQごとのidを割り当て、残存時間を計算しました
今回も使用しますので、まだ見ていない方は参照してください
その3では何をするのか
SQごとのidを使用し値動きの特徴などを見ていきます
・マイナーSQとメジャーSQで値動きに違いがあるのか
・上昇しやすい月、下落しやすい月はあるのか
などを見ていきます。少し長くなりそうなので適当に記事を分割して書いていく事にします。
概要
- SQごとにidを割り当てる
- SQカレンダーの作成
- SQ idでサンプリングしたOHLCデータの作成
- 時系列データとしてロウソク足をPlotしてみる
- SQ別に終値の変化率を箱ひげ図でPlotしてみる
- SQ別に高安終値の変化率を箱ひげ図でPlotしてみる
- メジャーSQでサンプリングするとどうなるのか
- 次は何をするのか
という感じで...
準備
使用するデータ
使用するデータは2013/01~2023/09までの日経先物miniのohlcvを使用します
DataFrame
shape: (2_960_691, 6)
┌─────────────────────┬───────┬───────┬───────┬───────┬──────────┐
│ datetime ┆ op ┆ hi ┆ lw ┆ cl ┆ volume │
│ --- ┆ --- ┆ --- ┆ --- ┆ --- ┆ --- │
│ datetime[μs] ┆ i64 ┆ i64 ┆ i64 ┆ i64 ┆ f64 │
╞═════════════════════╪═══════╪═══════╪═══════╪═══════╪══════════╡
│ 2013-01-04 09:00:00 ┆ 10750 ┆ 10765 ┆ 10745 ┆ 10750 ┆ 101269.0 │
│ 2013-01-04 09:01:00 ┆ 10750 ┆ 10765 ┆ 10735 ┆ 10745 ┆ 17336.0 │
│ 2013-01-04 09:02:00 ┆ 10740 ┆ 10750 ┆ 10740 ┆ 10745 ┆ 5341.0 │
│ 2013-01-04 09:03:00 ┆ 10745 ┆ 10750 ┆ 10740 ┆ 10745 ┆ 7193.0 │
│ … ┆ … ┆ … ┆ … ┆ … ┆ … │
│ 2023-09-26 15:12:00 ┆ 32105 ┆ 32105 ┆ 32105 ┆ 32105 ┆ 0.0 │
│ 2023-09-26 15:13:00 ┆ 32105 ┆ 32105 ┆ 32105 ┆ 32105 ┆ 0.0 │
│ 2023-09-26 15:14:00 ┆ 32105 ┆ 32105 ┆ 32105 ┆ 32105 ┆ 0.0 │
│ 2023-09-26 15:15:00 ┆ 32080 ┆ 32080 ┆ 32080 ┆ 32080 ┆ 19432.3 │
└─────────────────────┴───────┴───────┴───────┴───────┴──────────┘
使用するライブラリ
install
!pip install jpholiday
!pip install polars
!pip install plotly
!pip install statsmodels
実行
Import
import datetime
from typing import List
import plotly.graph_objects as go
from plotly.subplots import make_subplots
import polars
from statsmodels.tsa import stattools
# 前回作成した関数
from hogehoge import to_sq_timedelta
データの読み込み
データはparquetファイルで保存しています。csvと比べて容量も小さく、読み書きも高速なのでオススメです
fp = r'../datasets/NK225F.parquet'
data = pl.read_parquet(fp)
SQごとにidを割り当てる
前回作成した関数を使用するだけですが、その前にSession名を割り当てます。"その1"でコードを書いたのですがpolarsの仕様変更があったらしく警告が出てくる様になりました。ここで一応書き直しておきます
polarsで仕様変更があった部分
data = data\
.with_columns([
pl.col('datetime').dt.time().alias('time') ])\
.with_columns([
pl.when((pl.col('time') < datetime.time(7, 0, 0))
| (datetime.time(16, 0, 0) < pl.col('time')))
-旧 .then('NightSession')
-旧 .otherwise('DaySession')
+新 .then(pl.lit('NightSession'))
+新 .otherwise(pl.lit('DaySession'))
.alias('session'), ])\
.drop('time')
"""ついでにgroupbyも非推奨になりました。これからはgroup_byになります"""
-旧 data.groupby('session').agg(pl.col('cl').last())
+新 data.group_by('session').agg(pl.col('cl').last())
Execution
"""Session名の割り当て"""
data = data\
.with_columns([
pl.col('datetime').dt.time().alias('time') ])\
.with_columns([
pl.when((pl.col('time') < datetime.time(7, 0, 0))
| (datetime.time(16, 0, 0) < pl.col('time')))
.then(pl.lit('NightSession'))
.otherwise(pl.lit('DaySession'))
.alias('session'), ])\
.drop('time')
"""SQ idの取得"""
data = to_sq_timedelta(
df=data.drop_nulls('cl'),
datetime_col='datetime',
drop=False)\
.drop_nulls('sq_id')
Output
shape: (2_975_941, 11)
┌─────────────────────┬───────┬───────┬───────┬───┬───────┬───────┬───────────┬───────┐
│ datetime ┆ op ┆ hi ┆ lw ┆ … ┆ sq ┆ sq_id ┆ timedelta ┆ to_sq │
│ --- ┆ --- ┆ --- ┆ --- ┆ ┆ --- ┆ --- ┆ --- ┆ --- │
│ datetime[μs] ┆ i64 ┆ i64 ┆ i64 ┆ ┆ bool ┆ i16 ┆ i32 ┆ i32 │
╞═════════════════════╪═══════╪═══════╪═══════╪═══╪═══════╪═══════╪═══════════╪═══════╡
│ 2013-01-04 09:00:00 ┆ 10750 ┆ 10765 ┆ 10745 ┆ … ┆ false ┆ 0 ┆ 1 ┆ 5035 │
│ 2013-01-04 09:01:00 ┆ 10750 ┆ 10765 ┆ 10735 ┆ … ┆ false ┆ 0 ┆ 1 ┆ 5034 │
│ 2013-01-04 09:02:00 ┆ 10740 ┆ 10750 ┆ 10740 ┆ … ┆ false ┆ 0 ┆ 1 ┆ 5033 │
│ 2013-01-04 09:03:00 ┆ 10745 ┆ 10750 ┆ 10740 ┆ … ┆ false ┆ 0 ┆ 1 ┆ 5032 │
│ … ┆ … ┆ … ┆ … ┆ … ┆ … ┆ … ┆ … ┆ … │
│ 2023-10-13 08:56:00 ┆ null ┆ null ┆ null ┆ … ┆ false ┆ 129 ┆ 1 ┆ 4 │
│ 2023-10-13 08:57:00 ┆ null ┆ null ┆ null ┆ … ┆ false ┆ 129 ┆ 1 ┆ 3 │
│ 2023-10-13 08:58:00 ┆ null ┆ null ┆ null ┆ … ┆ false ┆ 129 ┆ 1 ┆ 2 │
│ 2023-10-13 08:59:00 ┆ null ┆ null ┆ null ┆ … ┆ false ┆ 129 ┆ 1 ┆ 1 │
└─────────────────────┴───────┴───────┴───────┴───┴───────┴───────┴───────────┴───────┘
SQカレンダーの作成
Plotする為にSQごとにカテゴリー値を作成します
1月SQなら"SQ_1"、2月SQなら"SQ_2"という感じで
Execution
sqs = data\
.group_by('sq_id')\
.agg([
pl.col('datetime').last()
])\
.with_columns([
(pl.lit('SQ_') + pl.col('datetime').dt.month().cast(str)).alias('sq_name')
])\
.sort('sq_id')\
.drop('sq_id')
Output
shape: (126, 2)
┌─────────────────────┬─────────┐
│ datetime ┆ sq_name │
│ --- ┆ --- │
│ datetime[μs] ┆ str │
╞═════════════════════╪═════════╡
│ 2013-01-11 03:00:00 ┆ SQ_1 │
│ 2013-02-08 03:00:00 ┆ SQ_2 │
│ 2013-03-08 03:00:00 ┆ SQ_3 │
│ 2013-04-12 03:00:00 ┆ SQ_4 │
│ … ┆ … │
│ 2023-03-10 08:59:00 ┆ SQ_3 │
│ 2023-04-14 08:59:00 ┆ SQ_4 │
│ 2023-05-12 08:59:00 ┆ SQ_5 │
│ 2023-06-09 08:59:00 ┆ SQ_6 │
└─────────────────────┴─────────┘
SQ idでサンプリングしたOHLCデータの作成
SQカレンダーのデータを結合、SQごとにresamplingしOHLCVのデータを作成します
Execution
'''2012/12のデータがないので2013/01にSQがあるデータを削除'''
sq_df = data\
.join(sqs, on='datetime', how='outer')\
.with_columns([
pl.col('sq_name').fill_null(strategy='backward')
])\
.group_by(['sq_id'])\
.agg([
pl.col('sq_name').first(),
pl.col('op').first(),
pl.col('hi').max(),
pl.col('lw').min(),
pl.col('cl').last(),
pl.col('volume').sum(),
])\
.drop_nulls('cl')\
.filter(pl.col('sq_id') != 0)\
.sort('sq_id')
Output
shape: (128, 7)
┌───────┬─────────┬───────┬───────┬───────┬───────┬─────────────┐
│ sq_id ┆ sq_name ┆ op ┆ hi ┆ lw ┆ cl ┆ volume │
│ --- ┆ --- ┆ --- ┆ --- ┆ --- ┆ --- ┆ --- │
│ i16 ┆ str ┆ i64 ┆ i64 ┆ i64 ┆ i64 ┆ f64 │
╞═══════╪═════════╪═══════╪═══════╪═══════╪═══════╪═════════════╡
│ 1 ┆ SQ_2 ┆ 10810 ┆ 11505 ┆ 10425 ┆ 11275 ┆ 3.6301367e7 │
│ 2 ┆ SQ_3 ┆ 11240 ┆ 12115 ┆ 11040 ┆ 12095 ┆ 3.3138749e7 │
│ 3 ┆ SQ_4 ┆ 12035 ┆ 13535 ┆ 11805 ┆ 13500 ┆ 4.9767771e7 │
│ 4 ┆ SQ_5 ┆ 13445 ┆ 14480 ┆ 12945 ┆ 14480 ┆ 3.3429393e7 │
│ … ┆ … ┆ … ┆ … ┆ … ┆ … ┆ … │
│ 125 ┆ SQ_6 ┆ 29120 ┆ 32720 ┆ 29095 ┆ 31905 ┆ 3.3391821e7 │
│ 126 ┆ SQ_7 ┆ 31910 ┆ 33960 ┆ 31765 ┆ 32820 ┆ 4.3111418e7 │
│ 127 ┆ SQ_8 ┆ 32820 ┆ 33470 ┆ 31660 ┆ 32045 ┆ 2.7357e7 │
│ 128 ┆ SQ_9 ┆ 32045 ┆ 33335 ┆ 31230 ┆ 32655 ┆ 2.3712e7 │
└───────┴─────────┴───────┴───────┴───────┴───────┴─────────────┘
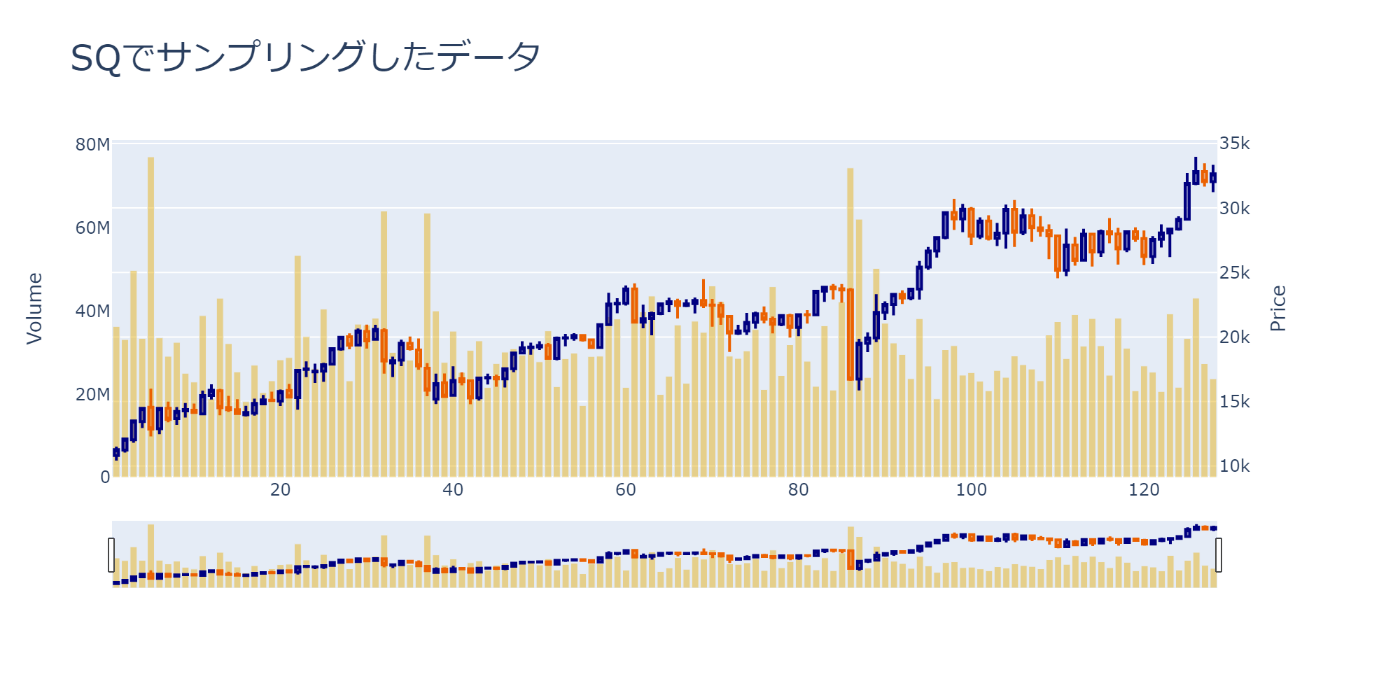
時系列データとしてロウソク足をPlotしてみる
今回は描画するデータが少ないので簡単なplotlyを使用していますが、データ量が多くなると重すぎて動かなくなります。ちょっと行数が増えますが、そんな時はbokehを使用してみてもいいかもしれません
Execution
def plot_candle(
idx: List[int],
op: List[float],
hi: List[float],
lw: List[float],
cl: List[float],
vol: List[float],
title: str,
width: int=1000,
height: int=500
):
candle = go\
.Candlestick(
x=idx,
open=op,
high=hi,
low=lw,
close=cl,
showlegend=False,
increasing_line_color='#000080',
decreasing_line_color='#eb6101'
)
bar = go\
.Bar(
x=idx,
y=vol,
showlegend=False,
marker={"color": "rgba(230,180,34,0.5)",}
)
fig = make_subplots(specs=[[{'secondary_y': True}]])
fig.add_trace(candle, secondary_y=True)
fig.add_trace(bar, secondary_y=False)
fig.update_layout(
title=title,
title_font_size=25,
height=height,
width=width)
fig.update_yaxes(title="Price", secondary_y=True, showgrid=True)
fig.update_yaxes(title="Volume", secondary_y=False, showgrid=False)
return fig
fig = plot_candle(
idx=sq_df['sq_id'],
op=sq_df['op'],
hi=sq_df['hi'],
lw=sq_df['lw'],
cl=sq_df['cl'],
vol=sq_df['volume'],
title="SQでサンプリングしたデータ"
)
fig.show()
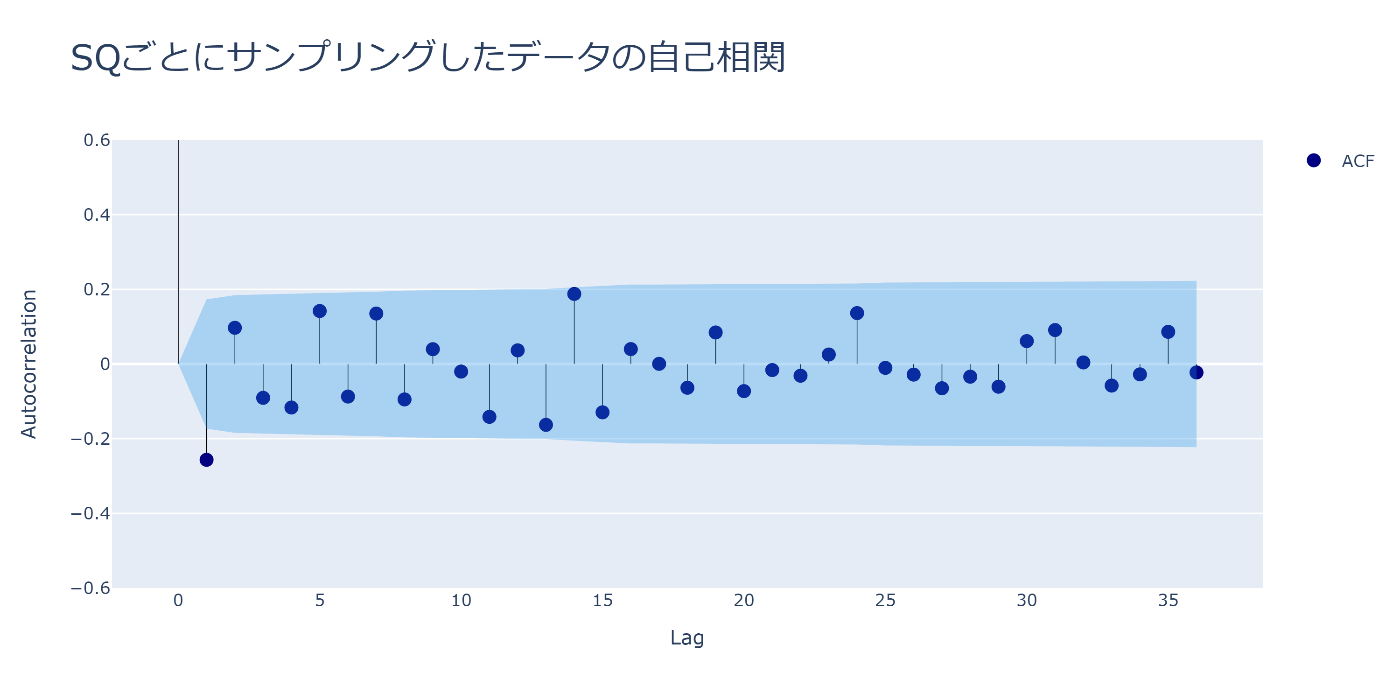
ついでに自己相関もPlotしてみます
翌月のSQとの逆相関がそれなりにありそうですね
Execution
def plot_auto_corr(x_lst: List[float], lags: int, title: str):
# 自己相関係数と信頼区間の計算
auto_corr, cinter = stattools.acf(x_lst, nlags=lags, alpha=0.05)
upper, lower = cinter[:, 0] - auto_corr, cinter[:, 1] - auto_corr
idx = list(range(len(auto_corr)))
# Plotlyを使用してPlotする
fig = go.Figure()
fig.add_trace(go.Scatter(
x=idx,
y= auto_corr,
mode='markers',
marker=dict(color='#000080', size=10),
name= 'ACF',
))
fig.add_trace(go.Bar(
x=idx,
y=auto_corr,
width=0.05,
marker=dict(color='black'),
showlegend=False
))
fig.add_scatter(
x=idx, y=upper, mode='lines',
line_color='rgba(255,255,255,0)',
showlegend=False)
fig.add_scatter(
x=idx, y=lower, mode='lines',
fillcolor='rgba(32, 146, 230,0.3)', fill='tonexty',
line_color='rgba(255,255,255,0)', showlegend=False)
fig.update_layout(
title=title,
title_font_size=25,
xaxis_title="Lag",
yaxis_title="Autocorrelation",
width=1000,
height=500,
yaxis=dict(range=[-0.6, 0.6])
)
return fig
# リターンの計算
rors = sq_df\
.with_columns([
(pl.col('cl') / pl.col('op')).log().alias('RoR')
])\
.drop_nulls()\
['RoR'].to_list()
fig = plot_auto_corr(rors, 36, "SQごとにサンプリングしたデータの自己相関")
fig.show()
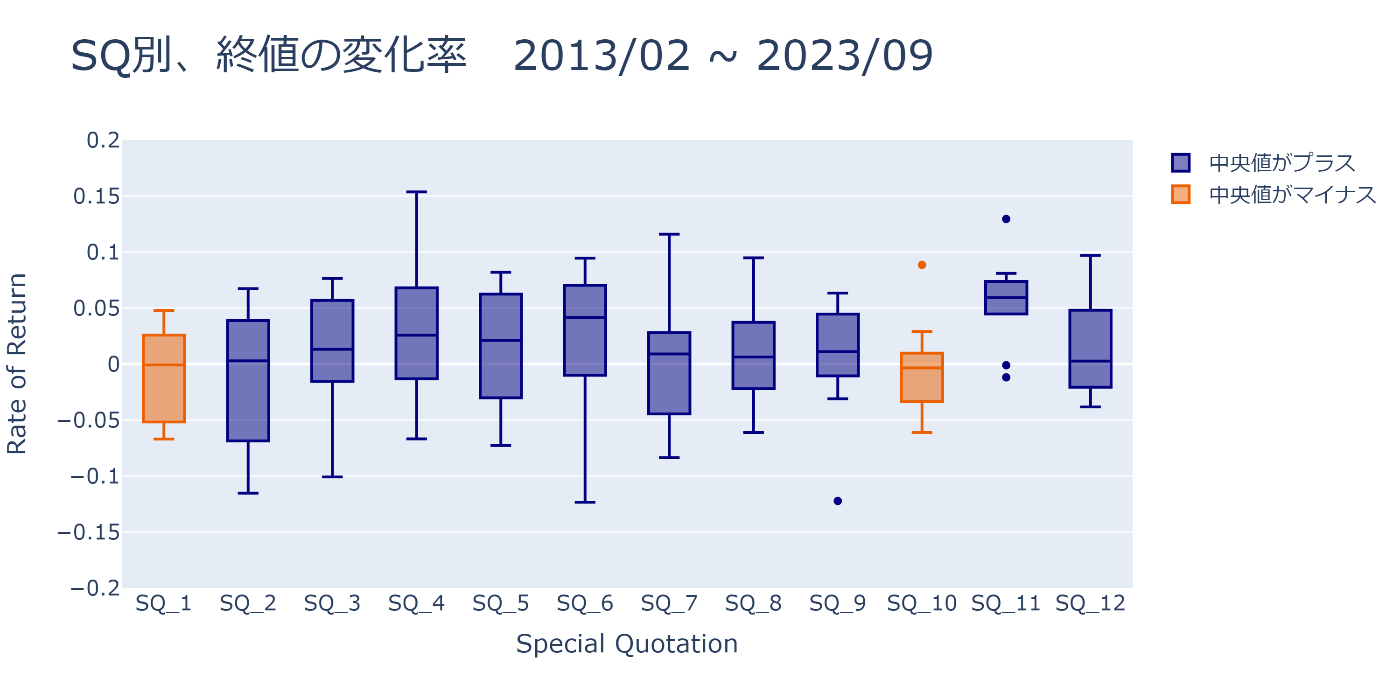
SQ別に終値の変化率を箱ひげ図でPlotしてみる
SQごとに箱ひげ図をPlotしてみると、11月のSQは上昇する傾向が強そうです
この記事を書いているのが2023/9なので、10/13~11/10の期間がどう動くのか気になりますね
Execution
def plot_sq_box(x: List[float], sq_names: List[str], title: str, width=1000, height=500):
df = pl.DataFrame({'x': x, 'sq_name': sq_names})
colors = df\
.group_by('sq_name')\
.agg([pl.col('x').median()])\
.with_columns([
pl.when(0 < pl.col('x'))
.then(pl.lit(True))
.otherwise(pl.lit(False))
.alias('color')
])\
.drop('x')
df = df.join(colors, on='sq_name', how='outer')
plus = df.filter(pl.col('color') == True)
minus = df.filter(pl.col('color') == False)
plus_box = go.Box(x=plus['sq_name'],
y=plus['x'],
marker_color='#000080',
name='中央値がプラス')
minus_box = go.Box(x=minus['sq_name'],
y=minus['x'],
marker_color='#eb6101',
name='中央値がマイナス')
fig = go.Figure()
fig.add_trace(plus_box)
fig.add_trace(minus_box)
fig.update_layout(
title=title,
title_font_size=30,
yaxis=dict(range=(-0.2, 0.2)),
yaxis_title='Rate of Return',
xaxis_title='Special Quotation',
font=dict(size=15),
width=width,
height=height
)
fig.update_xaxes(categoryorder='array', categoryarray=[f'SQ_{i}' for i in range(1, 13)])
return fig
fig = plot_sq_box(rors, sq_df['sq_name'].to_list(), 'SQ別、終値の変化率 2013/02 ~ 2023/09')
fig.show()
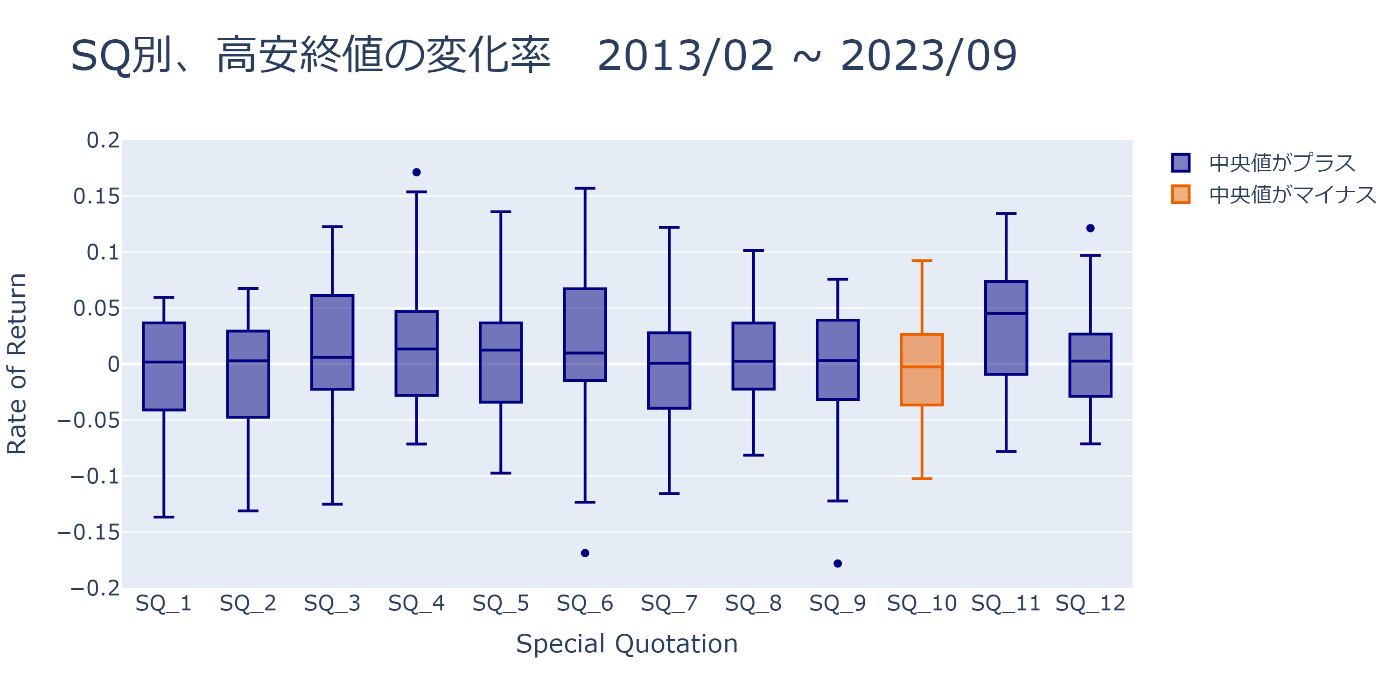
SQ別に高安終値の変化率を箱ひげ図でPlotしてみる
Execution
temp_rows = sq_df\
.with_columns([
(pl.col('hi') / pl.col('op')).log().alias('hi'),
(pl.col('lw') / pl.col('op')).log().alias('lw'),
(pl.col('cl') / pl.col('op')).log().alias('cl'),
])
hlc_rors = temp_rows['hi'].to_list() + temp_rows['lw'].to_list() + temp_rows['cl'].to_list()
sq_names = sq_df['sq_name'].to_list() * 3
fig = plot_sq_box(hlc_rors, sq_names, 'SQ別、高安終値の変化率 2013/02 ~ 2023/09')
fig.show()
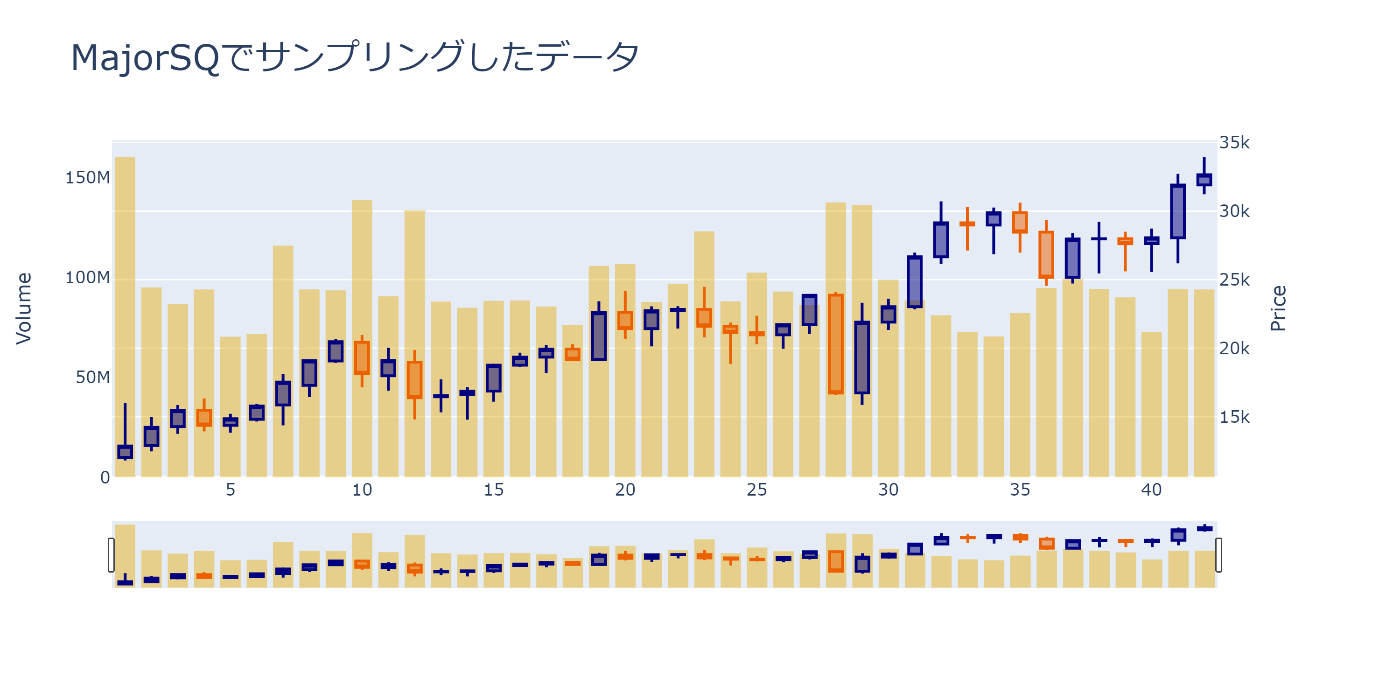
メジャーSQでサンプリングするとどうなるのか
メジャーSQと呼ばれる3,6,9,12月でサンプリングするとどうなるのでしょうか
前回の記事で作成したto_sq_timedelta関数を使用すれば簡単にメジャーSQでサンプリングする事ができます
'''majorにTrueを渡します'''
>>> data = to_sq_timedelta(
>>> df=data.drop_nulls('cl'),
>>> datetime_col='datetime',
>>> drop=False,
>>> major=True)\
>>> .drop_nulls('sq_id')



次は何をするのか
参考になりましたでしょうか
前回もそうですが、時々間違いに気づいて修正しているので、気になった方は自分で検証してみる事をオススメします
次回は同じくSQ別の違いをもう少し掘り下げていこうかと思っています
GISやTradingViewのPineScriptとか色々記事を書こうかと思うのですが、なかなか面倒で...
Discussion