ベイズ推定を使って、連続殺人犯の居場所を解明しよう! (Numb3rsより)
概要
今から20年くらい前に「Numb3rs~天才数学者の事件ファイル~」という、天才数学者とFBI捜査官のコンビが難事件を解決していくアメリカドラマが放送されていた。その中で出てきたエピソードの1つに、連続殺人の居場所をこれまでの殺害現場から推測する、所謂、地理的プロファイリングが使われるエピソードがあった。
今回は、この問題を地理的プロファイリングで使われている主流の方法とは別のベイズ推定方法を用いてアプローチしてみようと思う。
注意事項
ベイズ推定について
事前知識として、一応、ベイズ推定について記載する。
だが、本記事はベイズ推定の解説がメインではないので、詳細は別の解説記事を見てほしい。
- 真の分布
q(x) x^n = (x_1, x_2, x_3, ..., x_n) 補足説明
- ベイズ推定では、データがある分布
q(x) - 私たち(推測者)は、この分布
q(x) x^n - こういった制約の中で、データの背後にある真の分布
q(x)
- ベイズ推定では、データがある分布
- 確率モデル
p(x|w) \psi (w) 補足説明
- 私たち(推測者)は、データ
x^n q(x) p(x|w) - つまり、私たち(推測者)は、確率モデル
p(x|w) w q(x) - 同様に確率モデル
p(x|w) w \psi (w)
- 私たち(推測者)は、データ
- 観測したデータ
x^n p(x|w) \psi (w)
確率モデルp(x|w)
今回、連続殺人犯の事件現場と住居の関係性を表す式を真の分布と確率モデルに設定したい。
ざっくり、以下の2つの性質を持っていれば良さそうである。
- 住居から近すぎる場所では、犯罪を起こさない(なぜなら、すぐバレちゃうから)
- 住居からあまりにも遠く離れた場所でも、犯罪を起こさない(なぜなら、犯行は習慣化しており、遠くまで行くのが面倒だから)
- 殺人犯は住居と職場の2カ所を拠点にしている
補足説明
- 1つ目と2つ目の条件は、私が勝手に考え、3つ目の条件は、ドラマの設定から持ってきた。
- 実際に使われている地理的プロファイリングの要素はこれよりはるかに複雑だが、今回は、一種の遊びでやるので、上記のような適当な設定にした。
そこで、テキトーに、この3つの性質をもつ、座標
ただし、
また、慣例的に
定数についての補足説明
- 上記の10や0.05などの定数は後々、グラフの見やすさのため、決めた適当な値であり、重要ではない
-
V V := \int_{\bf x} p({\bf x} \mid w ) d{\bf x}
パラメータに関する補足説明
-
(b_1, c_1) (b_2, c_2) -
a_1 a_2 -
d
事前分布\psi (w)
事前分布は今回すべて、一様分布とする。
しかし、ある程度区間を決める必要はあり、今回、座標については
a1についての補足説明
-
a_1 0\sim 1 0\sim 0.45 - モデルが対称性を持つ場合、シミュレーションが不安定になることがある。理由はその数学的構造にあるのだが、今回は立ち入らない。
真の分布q(x) x^n
さて、本来の手順と逆になるが、今回は真の分布を、確率モデルのパラメータが
この分布をプログラムにプロットしたのが以下だ。
パラメータに関する補足説明
- これらの値は、私がグラフなどがきれいに見えるように決めた値であり、意味のある数値ではない。

グラフに関する補足説明
- このグラフはヒートマップで、明るい部分の確率が高く、暗い部分の確率が低い。
- 右上のドーナッツの穴の中心部分が住居であり、左下のドーナッツの穴の中心部分が職場である。
数値計算について
- この記事の数値計算はすべて区分求積法で計算しているが、次元の呪いで計算量が爆発的に増えていくためお勧めできない。
この真の分布

これだけだとわかりにくいので、先ほどの真の分布と重ねてみる。

こうしてみると、確かに真の分布から生成されていることがわかる。
このように、人の目で犯人の犯罪行為の規則性を見つけることは簡単ではない。
事後分布p(w|X^n)
まず、事後分布を計算する準備として、事前分布
この式を見てわかる通り、尤度関数は事前分布
尤度関数の意味
- 尤度関数の意味というのを語弊を恐れず、ざっくり言ってしまうと、パラメータ
w - この性質から、尤度関数が高いパラメータがよく出るような確率分布を作れば、それが真のパラメータを予測する分布になっていることが期待できる。そして、それこそが次に紹介する事後分布
p(w|x^n)
事後分布
ここでUは正規化定数で、積分の結果が1になるように設定する。
補足説明
強いてUを数式で書くと以下のような形になるが、合計を1にするためだけの定数であり、本質的ではないのであまり気にする必要はない。
上記の数式に従い、数値計算をすると、
例:職場
この方法を使って、職場
職場(b_1, c_1)
職場の事後分布を真の分布と重ねて描画した(カクカクしていて荒い部分が事後分布)。

白→黄→赤→黒の順で確率が低くなっていく。
グラフから、大体、職場の少し上あたりの確率が高くなっていることが確認できる。
住居(b_2, c_2)
同様に住居の事後分布を真の分布と重ねて描画した

こちらも、住居の少し上あたりの確率が高くなっていることが確認できる。
比率a_1

真の分布の
犯人が犯罪を起こしやすいと考えている距離d
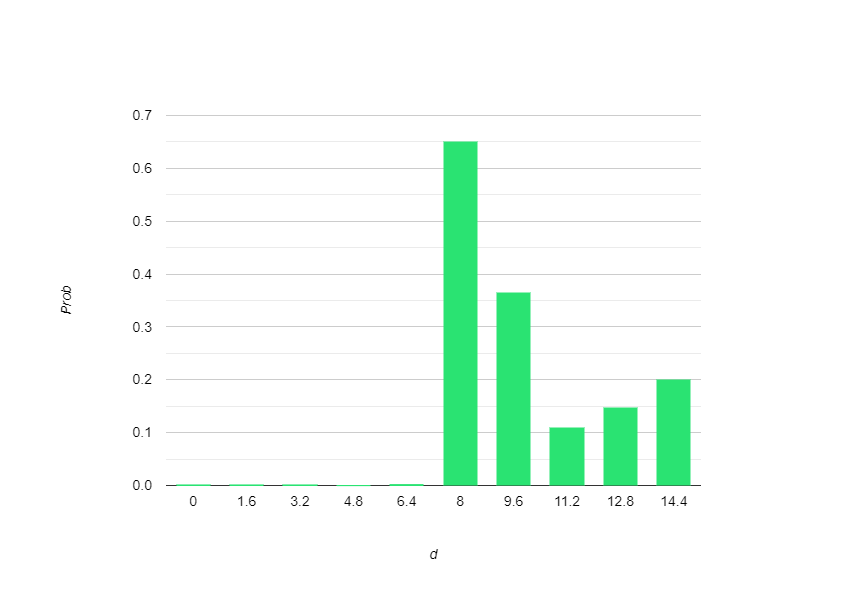
真の分布の
予測分布・モデル選択
犯人の居場所を特定できたのでほとんど目的を達成することができたが、せっかくなので、さらに分析を進めたいと思う。
予測分布
事後分布
これを数値計算して求めたのが以下の図である。左の図が真の分布で、右の図が予測分布である。
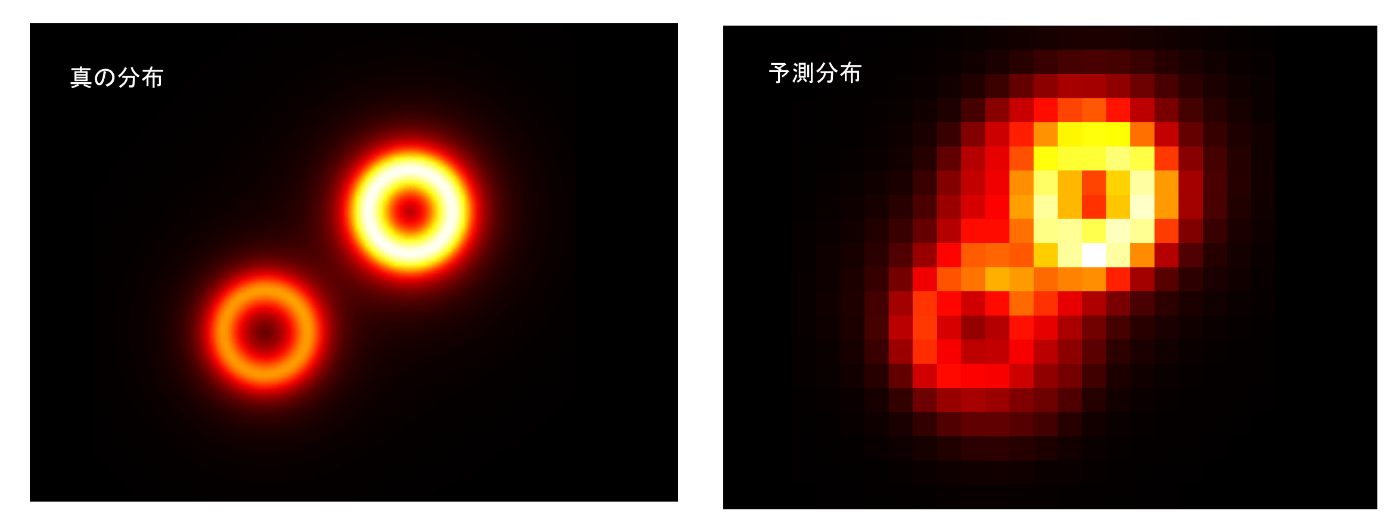
こうして見比べてと、少し予測分布のほうが幅が広く、上に位置していることがわかる。
この予測分布を使って、犯人の次の犯行現場を予想することができるだろう。
もっとも、予測については深層学習を使ったほうが良い結果が出る(たぶん?)ので、今はあまり使われないと思う。
モデル選択
ドラマにおいて、天才数学者は最初、犯人が2つの拠点(住居と職場)を利用していることに気が付かず、「犯人は1つの拠点から犯行を行っている」という誤った仮説のもとで、数式を立てた。その結果、正しい事後分布にならず、犯人を逮捕することができなかった。
しかし、その挫折を、兄のFBI捜査官や父と協力して、乗り越え、再度挑戦するというのが、ドラマのクライマックスだ(唐突なネタバレ)。
ドラマの中では、犯人の拠点が2つある可能性に気が付いた瞬間、これまでの「犯人の拠点が1つである」という仮定のモデルを棄却して、すぐに「犯人の拠点が2つある」というモデルを採択した。
これを直感ではなく、もう少し統計的に判断するならば、統計モデルのモデル選択をすることになる。
つまり、真の分布と計算したモデルの誤差を推測する量である情報量基準という値を計算し、比べて、情報量基準が小さいほうが良いモデルだ、ということになる。
情報量基準のすごさ
- 情報量基準の説明で、「真の分布と計算したモデルの誤差を推測する量」といったが、この情報量基準のすごい点は、なんと、計算には真の分布が必要ない、という点だ。
- 例えば、「ボールペンと鉛筆の長さを比較したとき、鉛筆はどれくらい長いか、予想してください。しかし、あなたに考える材料として鉛筆は渡せるけど、ボールペンは渡せません。」と言われたら途方に暮れてしまうだろう。しかし、情報量基準は”ボールペン”がなくてもどれくらい長いか回答できてしまう、という驚異的な式だ。
- もちろん、しっかりカラクリがある。真の分布を使わない代わりに、そこから出たデータを使って推測するのだ。前の例だと、ボールペンの部品だけは渡してくれるようなものである。
情報量基準はいろいろあるけど、現在のところ最強の基準はWAIC(またはWBIC)であるので、今回はこれを利用する。
事後分布で平均をとっているので、かなり計算コストが高い式なのだが、頑張って計算すると、以下のような値になった。
(ついでに、「1つの拠点から犯行を行っている」という誤った仮説の下でモデルを作り、事後分布をつくり、それのWAICも計算した)
| モデル | WAIC |
|---|---|
| 2つの拠点から犯行を行うモデル(これまで計算してきたモデル) | 5.32 |
| 1つの拠点から犯行を行うモデル | 5.55 |
1つの拠点から犯行を行うモデル
-
このモデルの記述は難しくない。具体的には以下の形になる
p(x, y \mid b_1, c_1, d ) := \frac {1} {V} \frac { \exp(-0.05 D(x, y))} { 10 + \left | D(x, y) - d \right | } ただし、
D(x, y) := \sqrt{ \left ( x - b_1 \right )^2 + \left ( y - c_1 \right )^2 } -
b_1, c_1, d
この結果から、「2つの拠点から犯行を行うモデル(これまで計算してきたモデル)」のほうが妥当である、といえる。
結論
- ベイズ推定と仮想的な確率モデルを使って、犯人の居場所を特定する、という遊びをやってみた
- 計算してみると、サンプル数30で、ようやく、「2つの拠点から犯行を行うモデル(これまで計算してきたモデル)」のほうが妥当である、という結論に到達しているのに、ドラマの中ではより少ないサンプル数で、拠点が1つでないことに気が付いており、天才数学者とFBI捜査官の最強コンビは、尋常じゃないことがよくわかった。
- 今回、区分求積法ですべて数値計算をしたが、次元の呪いで半分死にかけたので、次回はPyMC(マルコフ連鎖モンテカルロ法)を使いたい(反省)
最後に
- 「Numb3rs 天才数学者の事件ファイル」は20年前の古いドラマですけど、面白いので、ぜひ皆さんにもおすすめです、それではまた!
Discussion