1. はじめに
こんにちは株式会社D2C(以下D2C)でデータサイエンティストをしている井上です。
本記事では、WSDM 2019で発表された論文「Neural Demographic Prediction using Search Query」を紹介します。
1.1 記事の要約
- 検索クエリからデモグラフィック(性別や年齢)予測を行うためのHURA(Hierarchical User Representation with Attention)モデルを提案した論文
- HURAモデルはWord Encorder, Query Encoder, User Classificationの3段階から構成される階層型ニューラルネットモデル
- 性別予測および年齢予測の両タスクにおいて、ベースラインを上回る予測精度を達成
2. 背景
2.1 背景と動機
-
デモグラフィック予測の重要性
インターネット上での年齢や性別といったユーザ属性は、パーソナライズされた広告(例:女性にドレスの広告、男性に髭剃りの広告)やレコメンデーションシステムなど、さまざまなアプリケーションで重要な役割を果たします。しかし、ユーザのデモグラフィック(以下、デモグラ)データを入手することは非常に困難です。 -
検索クエリの利用
多くのユーザは日常的に検索クエリを発行しており、クエリの内容や書き方にはユーザの属性に関連する特徴(例:「cool」など若者が多用する表現、または「presbyopic glasses」といった高齢者向けの用語)が含まれる可能性があります。ただし、検索クエリは短文でありノイズも多い(amazon.comやyoutubeなど)ため、効果的に有用な情報を抽出する手法が求められます。
2.2 HURAの概要
HURAは、ユーザ単位の複数の検索クエリから、階層的にデモグラを学習するモデルです。
 HURAモデルのアーキテクチャ(出典:https://www.atailab.cn/ir2019fall/pdf/zengqin.pdf )
HURAモデルのアーキテクチャ(出典:https://www.atailab.cn/ir2019fall/pdf/zengqin.pdf )
- 第一段階(Word Encoder):各検索クエリを単語ごとに分解し、単語間の関連性を捉えます
- 第二段階(Query Encoder):複数のクエリ表現から、クエリ同士の関連性を捉えます
- 最終段階(User Classification):得られたユーザ表現を基に、Softmax層で年齢や性別などのカテゴリに分類します
3. モデルの詳細構成
3.1 Word Encoder(単語エンコーダ)
検索クエリは一般的に複数のキーワード(例:peppa pig website)で構成されるため、各クエリの中で局所的な文脈や重要なキーワードを抽出することが非常に重要です。例えば、「pig」という単語は「peppa pig」という文脈では子ども向けキャラクターを指し、年齢予測に役立ちますが、「domestic pig」という文脈では家畜を指し、デモグラ予測にはほとんど役立たないです。Word Encoderは以下の3層から構成されます。
3.1.1 単語埋め込み(Word Embedding)
まず、検索クエリは単語の列として表されます。ある検索クエリ
ここで、
-
w_i i -
M
各単語
ここで、
-
E \in \mathbb{R}^{V \times D} V D -
w_i \in \mathbb{R}^{D} w_i
この処理によって、元々の単語
3.1.2 単語レベルCNN(Convolutional Neural Network)
上述のように検索クエリの単語列は単なる単語の羅列ではなく、語順やフレーズの構造が意味を持ちます。例えば、
- 「peppa pig website」 → 「peppa pig (キャラクター)」+「website (ウェブサイト)」
- 「domestic pig」 → 「domestic (家畜)」+「pig (ブタ)」
このように、単語の隣接関係を考慮することで、より適切な表現を学習できます。そのため、Convolutional Neural Network(CNN) を用いて局所的なコンテキスト情報を捉えます。
各単語
-
c_i \in \mathbb{R}^{F_w} w_i -
f_w -
K_w K_w=3 -
w_{\lfloor i - \frac{K_w - 1}{2} \rfloor : \lfloor i + \frac{K_w - 1}{2} \rfloor} i K_w -
b_w
3.1.3 単語レベルAttention
検索クエリ内のすべての単語が同じ重要度を持つわけではありません。例えば、
- 「birthday gift for wife」 の場合、wife は性別推定に有効
- 「the elder scrolls online」 の場合、elder は年齢推定には有効でない
そのため、各単語の重要度を考慮して重みをつける Attention機構 を導入します。
Attention weightの計算
まず、単語ベクトル
ここで、
-
v_w \in \mathbb{R}^{T_w} -
V_w \in \mathbb{R}^{F_w \times T_w} -
b_w \in \mathbb{R}^{T_w}
次に、単語ごとのAttention weigh
この式によって、重要な単語には高い重み
クエリの最終表現
最後に、各単語ベクトルをAttention weighで加重平均し、クエリの最終特徴ベクトル
この
3.2 Query Encoder(クエリエンコーダ)
Word Encoderで得られた各検索クエリの表現
クエリレベルのCNN
検索クエリ
-
q'_i \in \mathbb{R}^{F_q} q_i -
f_q -
K_q K_q = 3 -
q_{\lfloor i - \frac{K_q - 1}{2} \rfloor : \lfloor i + \frac{K_q - 1}{2} \rfloor} K_q -
b_q
この畳み込み層を複数のフィルターで適用し、それらの出力を統合することで、クエリの局所的な関係を捉えた特徴ベクトル
クエリレベルのAtention (Query-Level Attention Network)
異なる検索クエリは、人口統計予測に対して異なる影響を与えます。多くの検索クエリは、このタスクにとって無関係またはノイズとなる可能性があり、すべての検索クエリが同じ重要度を持つわけではありません。例えば:
- 「birthday gift for grandson」 → 年齢推定に有効
- 「google maps」 → 情報が少なく、分類に役立たない
そのため、各クエリの重要度を学習し、適切な重みを与えるためのAttention機構 (Attention Mechanism) を導入します。
-
v_q \in \mathbb{R}^{T_q} q_i -
V_q \in \mathbb{R}^{F_q \times T_q} -
b_q \in \mathbb{R}^{T_q}
この式によって、重要なクエリには高い重み
ユーザの最終特徴表現
最後に、Attention weighを考慮したクエリの加重和を計算し、ユーザの特徴ベクトル
ここで、
3.3 User Classification(ユーザ分類層)
ユーザ分類層は、ユーザの検索クエリから学習された隠れた表現に基づいて、ユーザを年齢予測における年齢グループや、性別予測における性別カテゴリに分類するために使用されます。この層では、Softmax層を使用して、ユーザ
-
W \in \mathbb{R}^{d \times C} d C -
b_u \in \mathbb{R}^{C}
モデルの訓練段階では、損失関数としてクロスエントロピーを使用し、全体の目的関数は次のように定式化されます。
-
y_u,c u c c -
U
予測段階では、
4. 実験設定と評価
4.1 データセット
ランダムサンプリングしてきた25,000人のユーザから、6か月間の検索クエリと年齢カテゴリが取得されています。なお、ユーザ1人あたり平均約171.6クエリ、各クエリの平均単語数は約3.42語。
-
Age Dataset
以下のように年齢カテゴリは6段階(例: 18歳未満、18-24歳など)としています。
-
Gender Dataset
25,000人のユーザのうち、男性が13,349人、女性が11,651人となっています。
4.2 実験設定
その他、細かな実験設定等は以下のようになります。
データ分割
• 訓練用データ: 20,000人(80%)
• テスト用データ: 5,000人(20%)
• 訓練データの10%を検証用に使用
精度指標
- Accuracy
- Macro-averaged Fscore
Word Embedding
- 各単語は事前学習済みの word2vecを使用
- 埋め込み次元:200
両タスクのCNN
- ウィンドウサイズ:3
- フィルター数:300
学習設定
- オプティマイザ:RMSProp
- バッチサイズ:100
- ドロップアウト:0.2
- Early Stopping:検証データの損失が 3エポック 連続で減少しない場合に学習を停止
ベースライン手法
- SVM, LR, LinReg, FastText, CNN, LSTM, HAN(文章分類のためのHierarchical
Attention Networks、本実験では、各ユーザをdocumentとし、検索クエリをsentenceとみ
なす) - 各実験は独立して10回繰り返し、平均結果を示す
5. 結果
表:Ageデータセットでの実験結果(出典:https://www.atailab.cn/ir2019fall/pdf/zengqin.pdf )
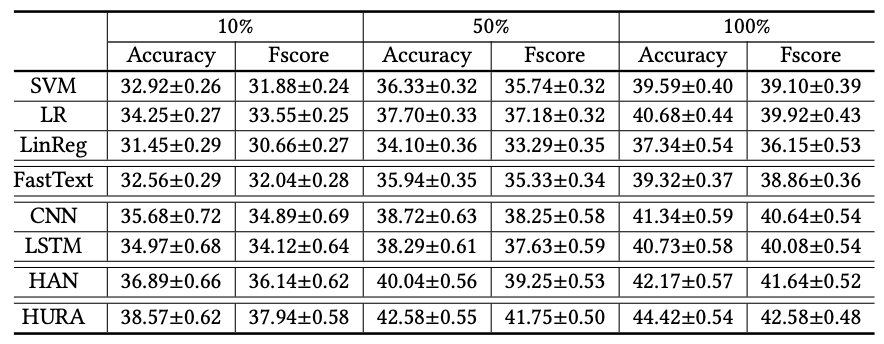
表:Genderデータセットでの実験結果(出典:https://www.atailab.cn/ir2019fall/pdf/zengqin.pdf )

提案手法であるHURAモデルが両タスクにおいてベースラインより精度が上回ることがわかります。
従来の機械学習手法に基づいたデモグラ予測方法との比較
SVM、LR、およびLinRegなどの従来の機械学習手法に基づいたデモグラ予測方法よりも優れた性能を発揮できます。これは、これらの手法で使用されるユーザを表現するための特徴が手作業で作成されており、検索クエリの複雑な意味や文脈を捉えることができないためです。
ニューラルネットワークベースモデルとの比較
FastText、CNN、およびLSTM など、ニューラルネットワークに基づく多くの既存の人口統計予測方法にも優れています。これらの手法では、同じユーザのすべての検索クエリが長いテキストとして連結され、ユーザ表現が構築されます。したがって、各個別の検索クエリの意味情報を効果的に捉えることができず、これらの手法では有益な検索クエリとあまり有益でない検索クエリを区別することができません。多くの検索クエリはデモグラ予測にとって有益でなくノイズとなるため、これらの手法は検索クエリに基づく年齢および性別予測には最適でない可能性があります。
HURAモデルでは、ユーザ表現のために階層的なニューラルモデルを使用しています。このモデルは、まずword encoderを使用して各検索クエリの単語から表現ベクトルを学習し、その後、query encoderを使用して検索クエリに基づいて各ユーザの表現ベクトルを学習します。HURAモデルは、予測タスクへの寄与度合いに基づいて異なる単語とクエリに異なる重みを与えるため、単語レベルおよびクエリレベルのAttention Networkを組み込んでいます。異なる単語や検索クエリはデモグラ予測に対して異なる有益性を持っているため、HURAモデルはこれらの既存のNNベースのデモグラ予測手法よりも検索クエリからユーザの年齢と性別を予測するのに適していることが言えるようです。
HANとの比較
HAN法ではLSTMネットワークを使用して、単語から文の表現を学習し、文から文書の表現を学習するためです。この手法は文書分類に適しており、単語と文の順序情報を捉えることができます。しかし、検索クエリはキーワードの組み合わせであるため、文とは大きく異なります。さらに、文書内の文が通常お互いに強い関連性を持っている(例えば、同じトピックに従っている)のに対し、同じユーザからの検索クエリにはより多くの多様性があります。例えば、ユーザは異なる検索セッションでさまざまな種類の情報を検索することがあります。隣接する時間帯の検索クエリは互いに関連性があるかもしれませんが、長期間にわたる検索クエリ間の関連性は通常非常に弱いです。したがって、CNNを使用して単語や検索クエリの局所的文脈を捉えることは、クエリ表現とユーザ表現においてより適切であると筆者は述べています。
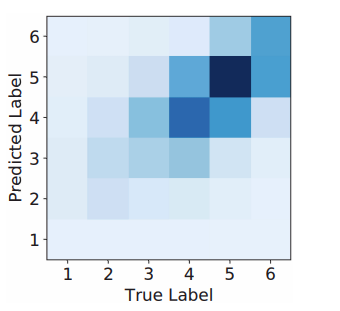 図:ageデータセットの混同行列(出典:https://www.atailab.cn/ir2019fall/pdf/zengqin.pdf )
図:ageデータセットの混同行列(出典:https://www.atailab.cn/ir2019fall/pdf/zengqin.pdf )
最も多くの誤分類は、隣接する年齢カテゴリにユーザを分類することによって生じていることがわかります。例えば、年齢カテゴリ4の多くのユーザが年齢カテゴリ5に誤分類されています。この結果は直感に一致しており、隣接する年齢カテゴリのユーザ間で検索内容や書き方に多くの重なりがあるためのようです。
6. 補足
6.1 CNNとAttentionの役割
-
CNN層
- 単語レベルでは、近傍単語間の依存関係(例:「peppa」と「pig」の関係)を捉えることで、意味的なつながりを抽出します。
- クエリレベルでは、時間的に近いクエリ間の関連性(同じ意図の異なる表現など)を補完的に取り込みます。
-
Attention機構
- 各単語や各クエリの重要度を動的に算出することで、ノイズの多いクエリや共通語(例:"login", "amazon.com")の影響を抑え、予測に有用な部分に重みを集中させます。
7. 感想
本記事では、WSDM 2019で発表された論文「Neural Demographic Prediction using Search Query」の紹介を行いました。
個人的に、検索クエリのみでデモグラ予測できるため大変興味深いと感じた一方で、検索クエリと性別等のデモグラをセットとしたデータセットを手に入らないのが一番の難点であると感じました。機会があれば、日本語の検索クエリで試してみたいと思いました。

株式会社D2C d2c.co.jp のテックブログです。 D2Cは、NTTドコモと電通などの共同出資により設立されたデジタルマーケティング企業です。 ドコモの膨大なデータを活用した最適化を行える広告配信システムの開発をしています。
Discussion