はじめに
こんにちは。D2C エンジニアの市村です。
最近、AWSでインシデント検出と対応に特化したIncident Managerというサービスを知り、本番環境で構築してみました。
この記事ではIncident Managerを実装してみた感想を書いていこうと思います。
Incident managerでできること
以下のことができます。
- インシデントの管理
- インシデント時の電話通知やSlack通知
- AWS Systems Manager Automationのrunbookを使った運用の自動化
詳細な説明はこちら参照
このように構築が少し大変だった電話通知機能も備わっているので、運用時に活躍できるサービスだと思います。
構築
内容
今回は、EC2のCPU使用率が高くなった場合にIncident Managerで通知対応をし、LambdaでEC2を再起動をさせるということをやってみます。
Incident Managerを構築するには以下を作成する必要があります。
- 連絡先の作成
- 個人の連絡先を登録します。
- 個人の連絡先は複数登録できます。
- エスカレーションプランの作成
- 連絡先に登録したメンバーの登録します。
- ここで連絡先への通知順番や通知間隔を決めます。
- 対応プランの作成
- インシデント毎に作成します。
- インシデントの対応内容を設定できます。
- インシデント状況の通知先の設定や運用自動化のrunbookの紐づけを行います。
- CloudWatch Alarmと対応プランの紐づけを行います。
- runbookの作成
- 今回はEC2を再起動させるLambdaを呼び出すレシピを記載します。
連絡先、エスカレーションプランの作成は画面通りに作成するだけなので、割愛させていただきます。
対応プランの作成
画面に沿って作成します。

チャットチャンネル設定を対応プラン作成時に行います。
今回はchatbotは作成済みなので、対応プランの作成画面から紐づけを行います。
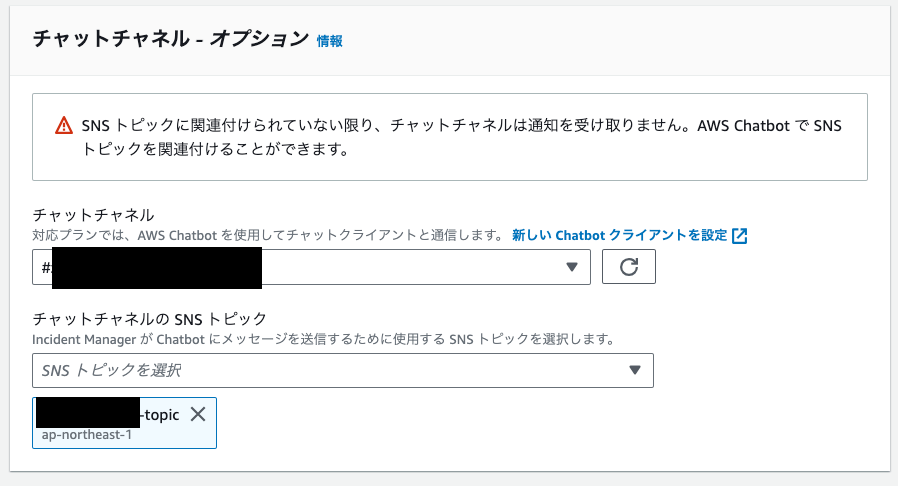
エスカレーションプランの紐付けを行います。

ここで対応プランの作成を完了します。
runbookの作成が完了したら対応プランの編集からrunbookの紐付けを行います。
EC2を再起動するLambdaの作成
import json
import boto3
from botocore.exceptions import ClientError
def lambda_handler(event, context):
print('recovery start!!')
print(event)
ec2 = boto3.client('ec2')
try:
response = ec2.reboot_instances(InstanceIds=[event['instanceid']], DryRun=False)
print('Success', response)
except ClientError as e:
print('Error', e)
print('recovery end')
return {
'statusCode': 200,
'body': json.dumps('recovery end')
}
event引数で渡されたinstanceidを使ってboto3で再起動させるコードを記載しました。
runbookの作成
AWS Systems Managerのドキュメントから作成します。

yamlだと以下のようになります。
description: call lambda
schemaVersion: '0.3'
mainSteps:
- name: GetInstanceId
action: 'aws:executeAwsApi'
outputs:
- Name: InstanceId
Selector: '$.MetricAlarms[0].Dimensions[0].Value'
- Name: AlarmName
Selector: '$.MetricAlarms[0].AlarmName'
inputs:
Service: cloudwatch
Api: describeAlarms
StateValue: ALARM
ActionPrefix: 'arn:aws:ssm-incidents::{アカウントID}:response-plan/{対応プランの名前}'
nextStep: CallRecoveryLambda
- name: CallRecoveryLambda
action: 'aws:invokeLambdaFunction'
inputs:
InvocationType: RequestResponse
FunctionName: {Lambdaファンクションの名前}
InputPayload:
instanceid: '{{GetInstanceId.InstanceId}}'
alarmname: '{{GetInstanceId.AlarmName}}'
最後に、対応プランの画面でrunbookの紐づけと、CloudWatch AlarmのアクションにIncident Managerを設定します。
これで構築は完了です。
使ってみた感想
実際に対象のEC2のCPU使用率を上げてアラームを発生させてみました。
Incident Manager
インシデント発生後のIncident Managerの画面は以下のようになりました。

また、タイムラインタブで詳細なタイムラインがみれます。
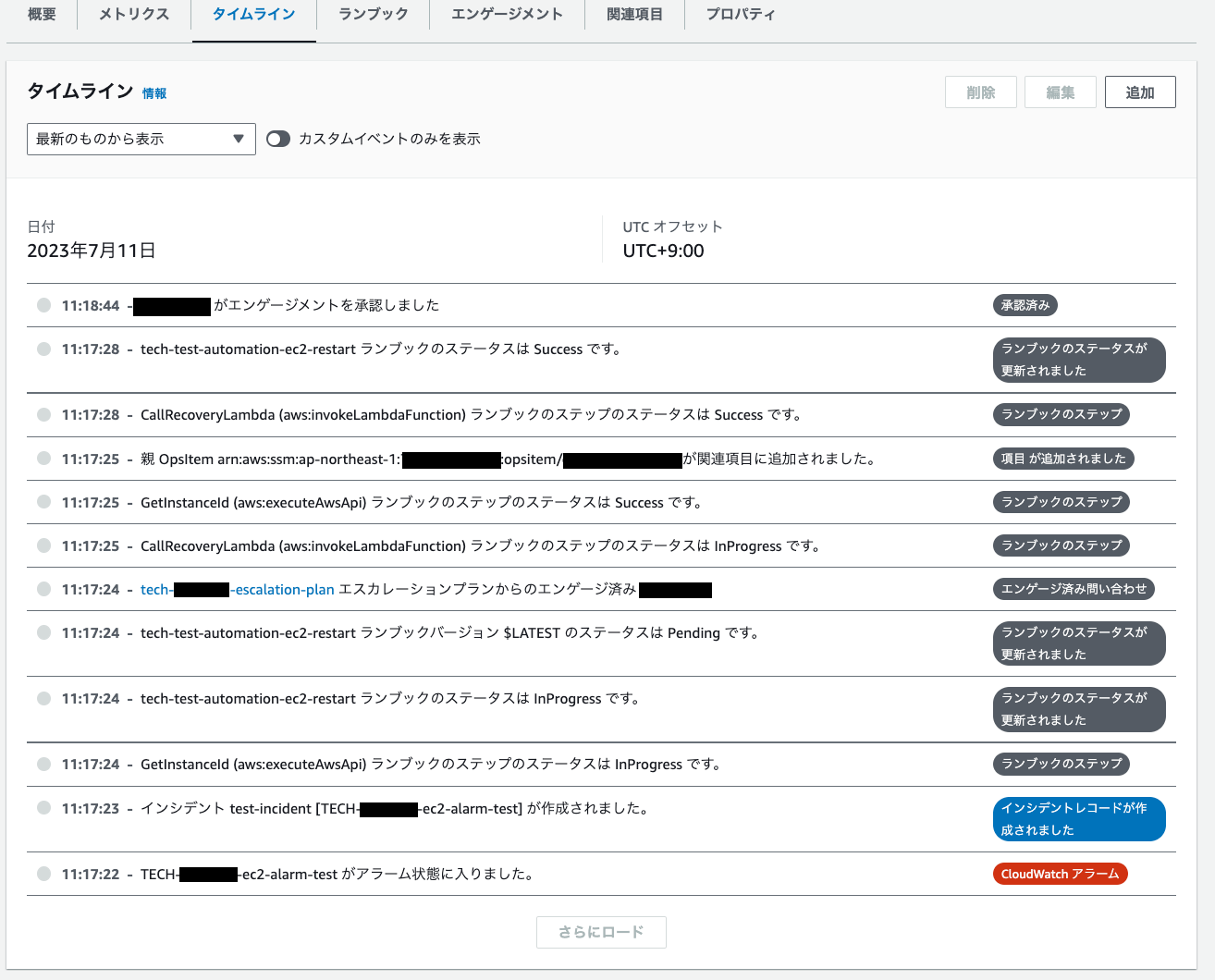
以下のようになっていることがわかります。
- CloudWatch Alarmがアラーム状態になる
- インシデントが作成された
- runbookが実行開始した
- エスカレーションプランを元に連絡先に通知が行われた
- runbookが成功した
- 連絡対象者がエンゲージメントを承認した
(電話に出て1を押すとエンゲージメントを承認状態になる)
連絡先に登録した携帯電話
画像は割愛しますが、インシデント発生後に海外から実際に電話がかかってきました。
Slack
インシデント発生後、以下のようにSlackに通知がきました。

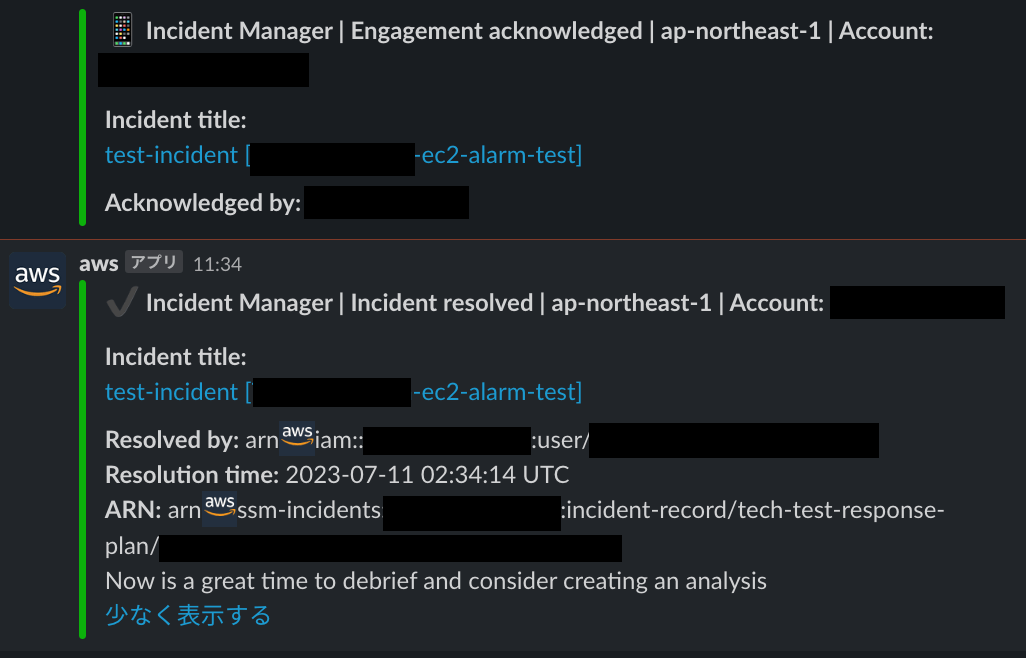
以下のタイミングでSlackに通知がくることがわかります。
- 関連アイテムの作成した
- 連絡先に通知が開始した
- インシデントが開始した
- runbookが成功した
- 連絡対象者がエンゲージメントを承認した(電話通知に応答した)
- インシデントが解決した
簡単に電話通知されるのも便利ですが、対応者の応答状況やrunbookの実行状況も時系列で通知してくれるのでインシデント発生時に状況が把握しやすく便利だと感じました。
おわりに
システムの運用をしていると、どうしてもインシデント対応が必要になってきます。
そういった状況の中でこのIncient Managerを使うとインシデントに早く気付き素早く対応できるようになります。
また、runbookで自動リカバリ等の運用自動化も導入できたら更に運用が楽になるので、私が運用しているサービスでも率先して導入していこうと思いました。
最後までお読みいただき、ありがとうございました。
参考

株式会社D2C d2c.co.jp のテックブログです。 D2Cは、NTTドコモと電通などの共同出資により設立されたデジタルマーケティング企業です。 ドコモの膨大なデータを活用した最適化を行える広告配信システムの開発をしています。
Discussion