

こんにちは D2CエンジニアのYuki Suzukiです。
2023/11/27~2023/12/1に開催されたAWS re:Invent 2023では今年も様々な新サービスが発表されました。
中でもAmazon Qについては生成系AIサービスとして一番注目を浴びたのではないでしょうか。
Amazon Qとは
AWS re:Invent 2023で発表されたAWSの新サービスで、エンタープライズ向けに設計されたAIチャットアシスタントです。
(AWS版のChatGPTと考えるとイメージしやすいです)
今回はAmazon Qのビジネスユーザー向け機能を使い、独自のデータを読み込ませチャットQ&Aアプリケーションを作り実際の動作を確認してみました。
※開発者向け機能もありますが本稿では触れません。
Amazon Qの特徴
- AWS管理コンソールからクリックするだけでAIチャットアシスタントのアプリケーションが作れてしまう
- 企業が持つクライアントデータにAmazon Qからアクセスさせることで独自にカスタマイズすることが可能
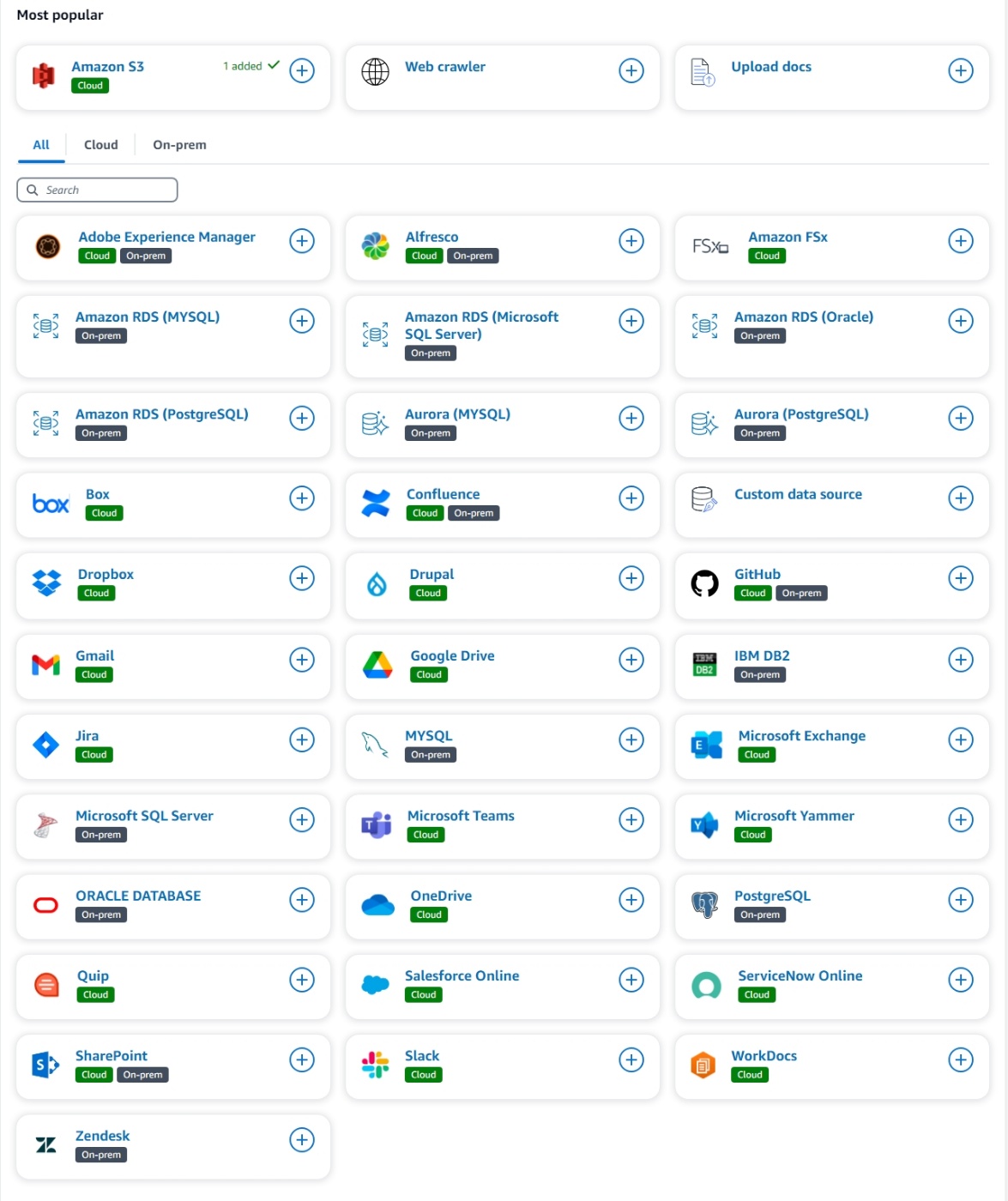
- さらにAmazon Qには最初からクライアントデータと連携できるように40以上のコネクタが用意されており連携が簡単に実現できる
※S3、RDSなどのAWSサービスはもちろんのこと、JIRA/Confluence、Github、Gmail、GoogleDrive、Slack、Teamsなどもデータソース元として設定できます - エンタープライズ用として最初からセキュリティとプライバシーに配慮された設計になっており、Amazon Qでは内部のモデルのトレーニングためにクライアントデータを一切使用しないことを当初から名言している[1]
※データ連携できるサービスは多岐に渡る
Amazon Qを利用するにあたっての留意事項
- プレビュー版であり、今後機能に変更がある可能性がある
- 現状は英語のみサポート
- 日本語はサポートされていない
- Amazon Qにインプットさせるクライアントデータも日本語は未対応
Amazon Qのアプリケーションを作る
実際にAmazon Qでアプリケーションを作っていきます。
0.事前準備
S3にyukisuzuki-sample-datasourceというバケットを作成し、中に独自データを入れておきます。
今回はe-govデータポータルより、国土交通白書_2013年度版 / 第Ⅱ部_第2章_時代の要請にこたえた国土交通行政の展開というデータをお借りしました。

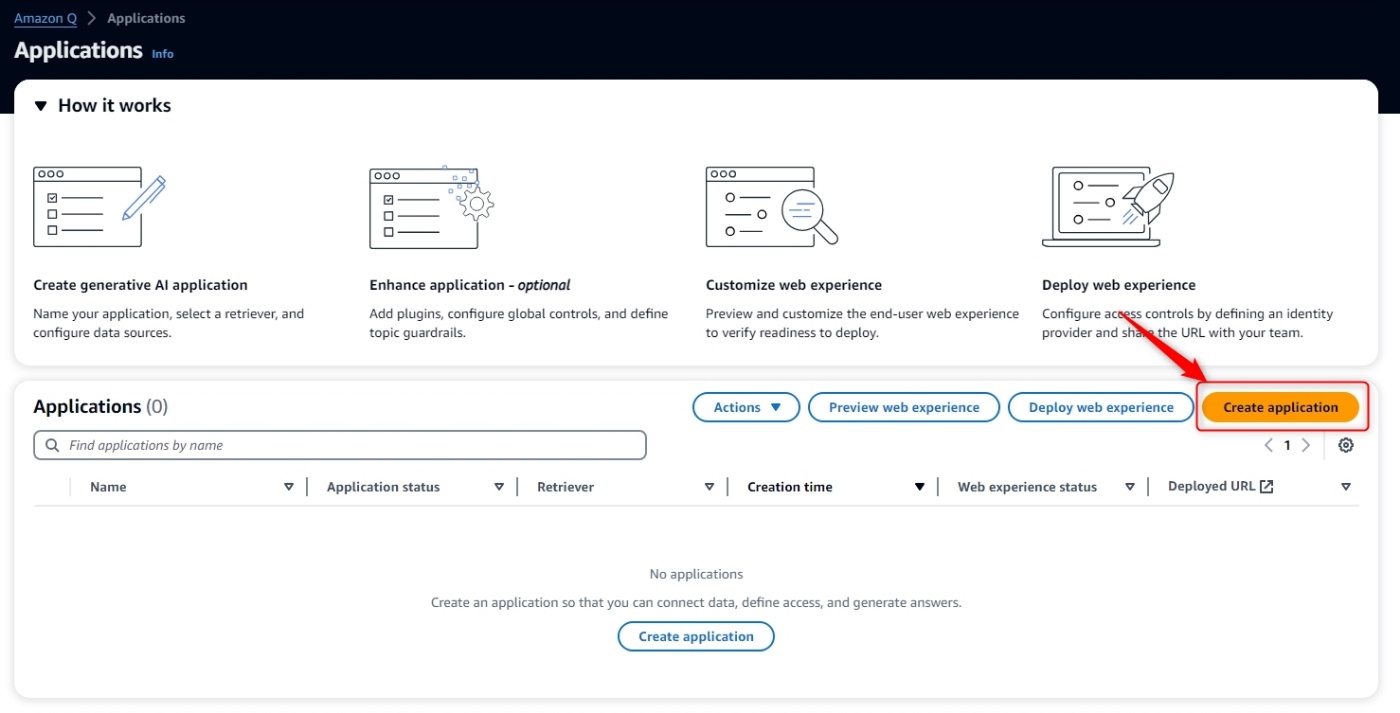
1.アプリケーションの作成
[手順]
- [Amazon Q > Applications]より
Create Applicationをクリック
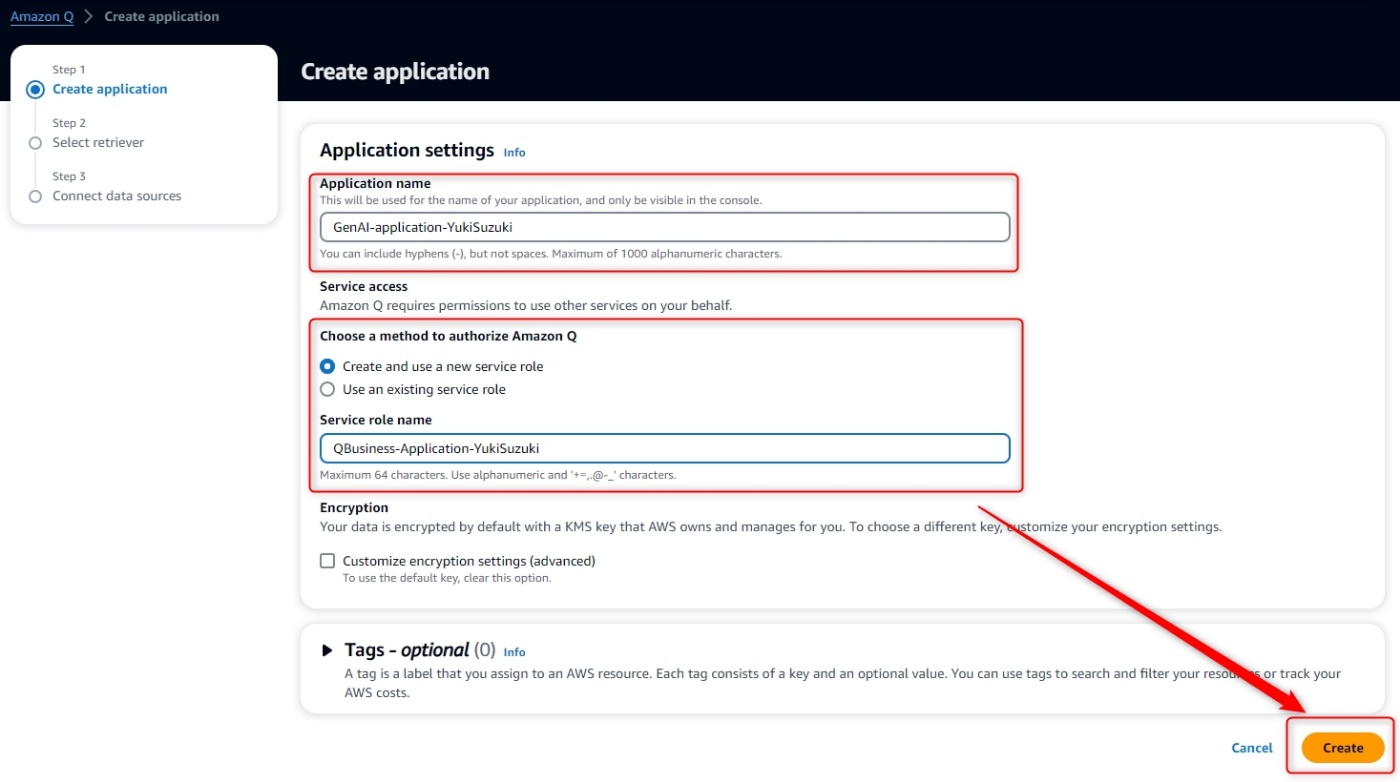
[手順]
アプリケーションの作成画面に移動するので、
-
Application nameを入力 -
Choose a method to authorize Amazon QにてCreate and use a new service roleを選択 -
Service role nameを入力 -
Createをクリック
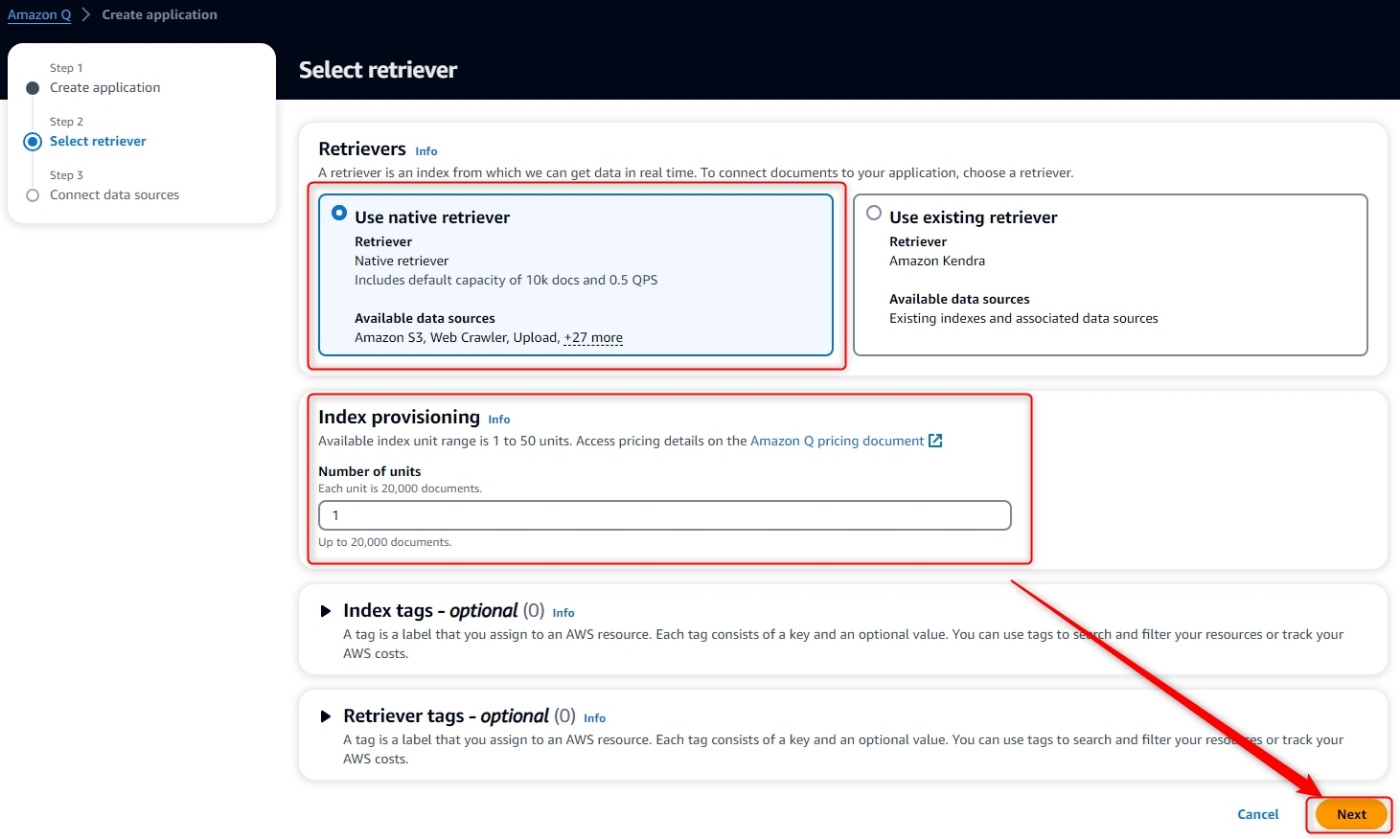
2. レトリバーの設定
会話中に独自データをAmazon Qに検索してもらうためのレトリバー(retriever)を設定します。
レトリバーには以下の2つが用意されており、Native Retrieverを選択することでAmazon Qがサポートする様々なデータソースに簡単に接続できるようになります。
- Native Retriever
- Amazon Kendra
Index provisioningは独自データのインデックスを作るためのunit数を選択します。
1unitで20,000ドキュメントを保存できるので、目的に応じて1~50までの間で設定します。
[手順]
-
RetrieverにてUse Native Retrieverを選択 -
Index provisioningにてunit数を入力 -
Nextをクリック
3.データソースの接続設定
データソースをAmazon Qに接続するための設定を行います。
0.事前準備で設定しておいたS3への接続設定を行います。
※データソースは同時に5つまで設定できます
[手順]
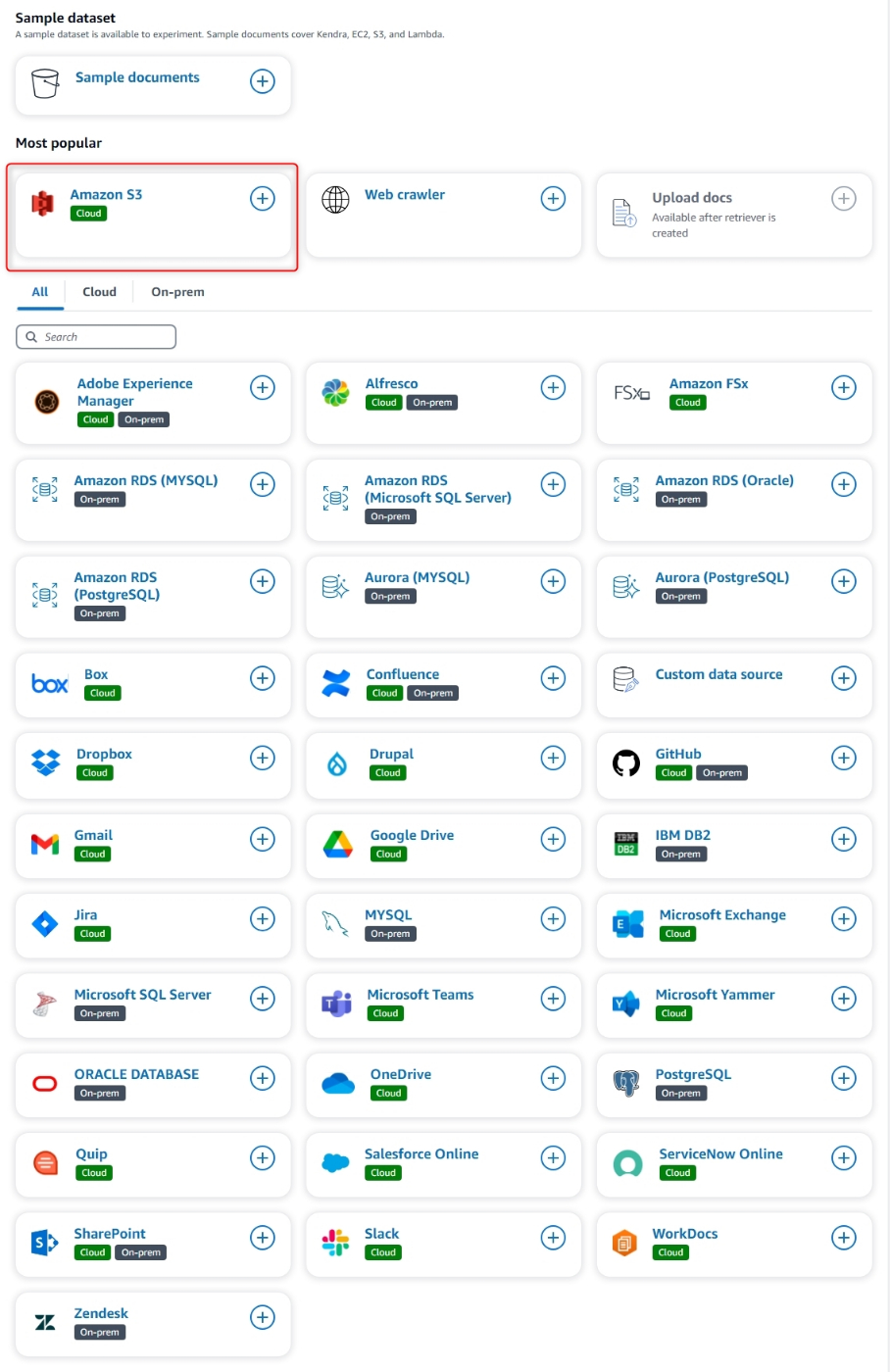
- 一覧から
Amazon S3を選択する
[手順]
-
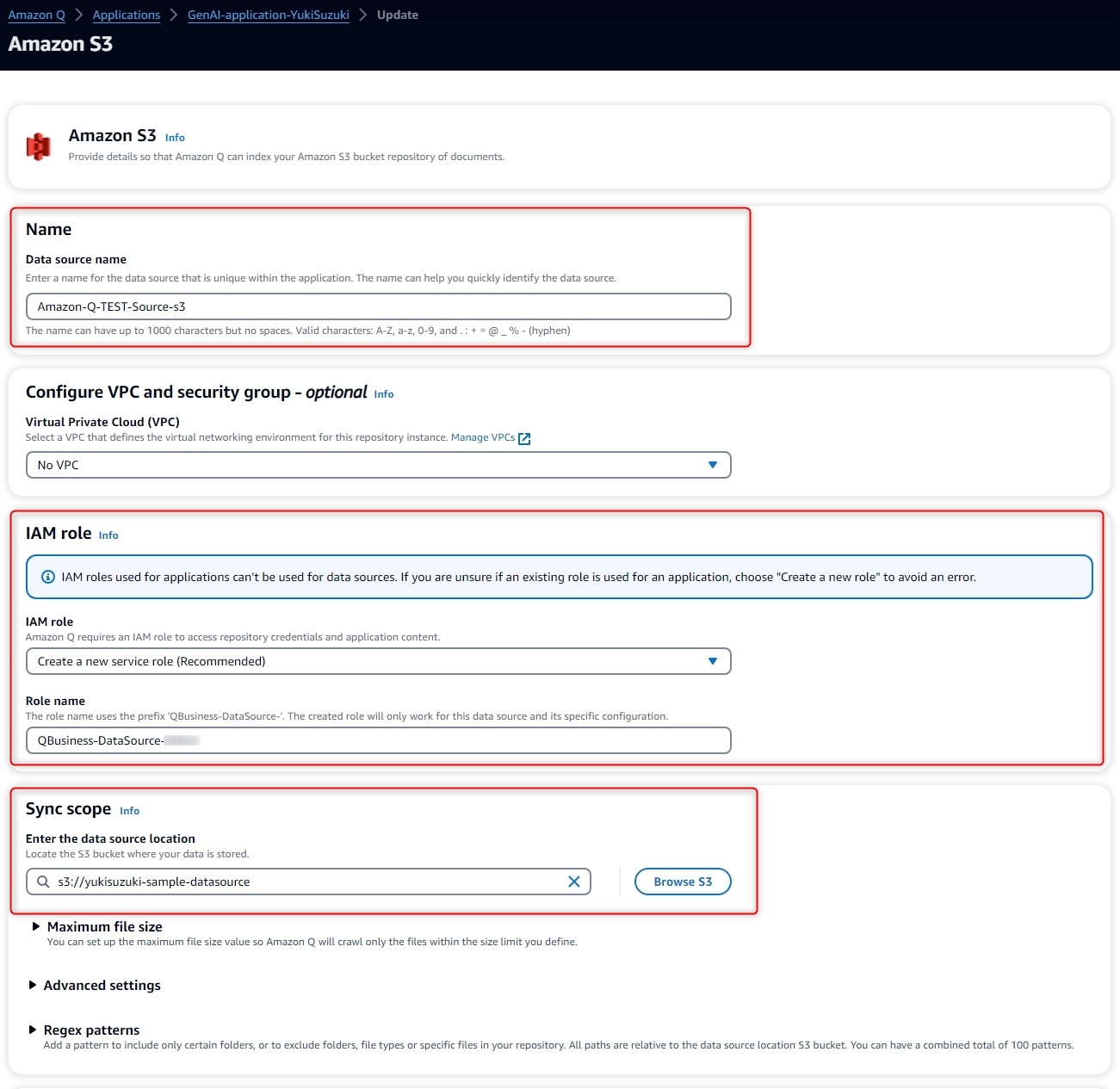
Nameにてデータソース設定名を入力 -
IAM RoleにてCreate a new service role(Recommended)'を選択& 作成するRole name`を入力 -
Sync ScopeにてS3のバケットパスを入力 -
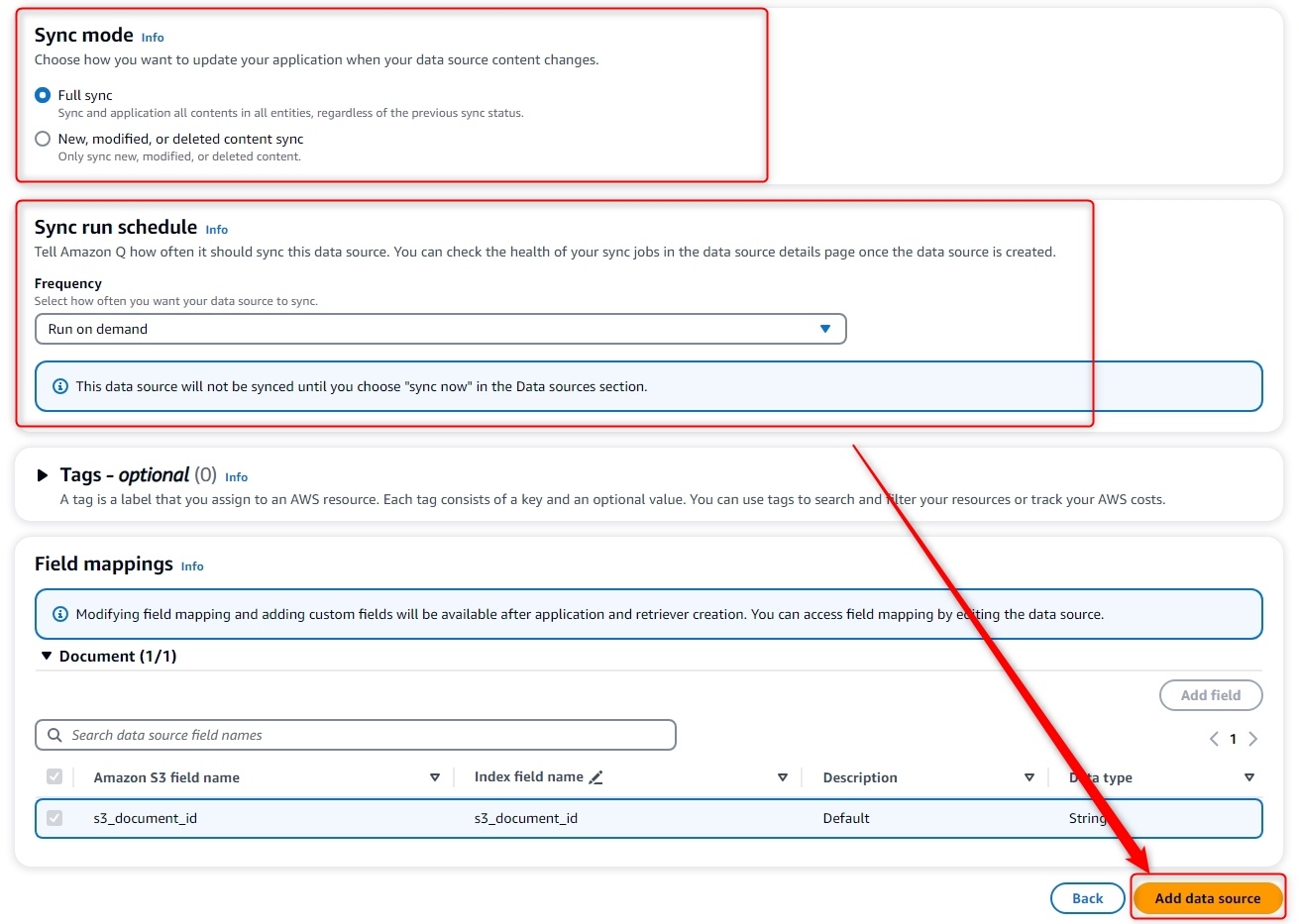
Sync Modeにてデータ同期方法を選択 -
Sync run scheduleにてデータ同期頻度を選択 -
Add data sourceをクリック
4.データの同期
データソースをAmazon Qにデータ同期させます。
[手順]
- [Amazon Q > Applications]より作成したアプリケーションをクリック
-
Data Sourceから作成したデータソースを選択 -
Sync Nowボタンをクリック - Syncが完了するまで数分~十数分待つ。
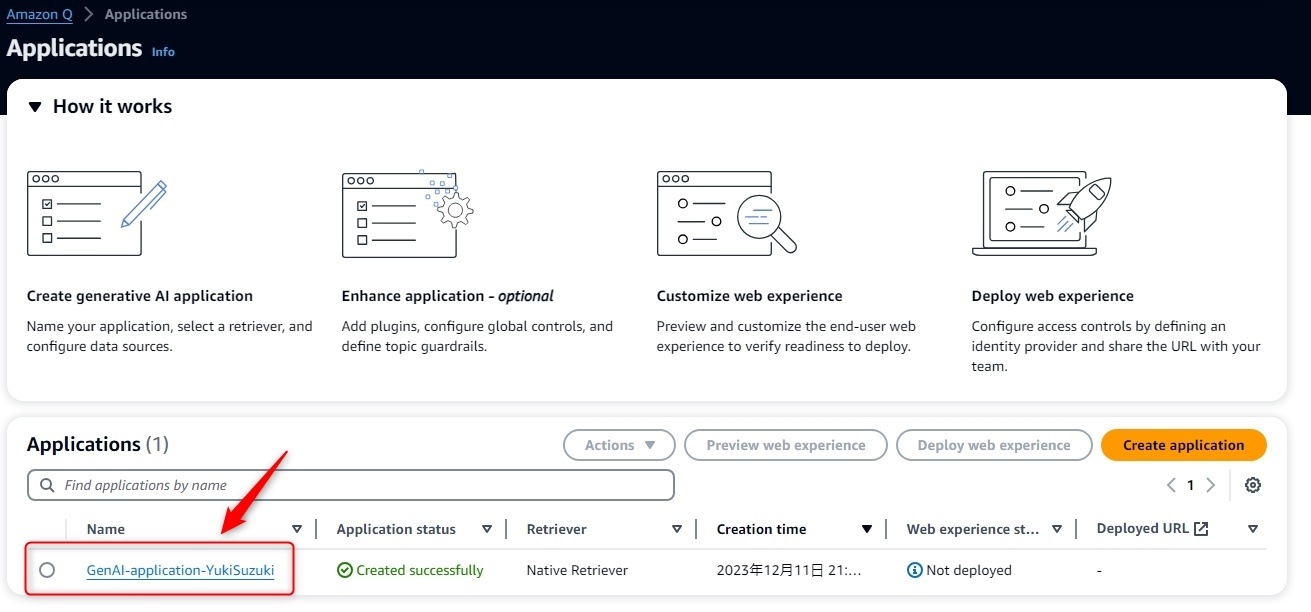
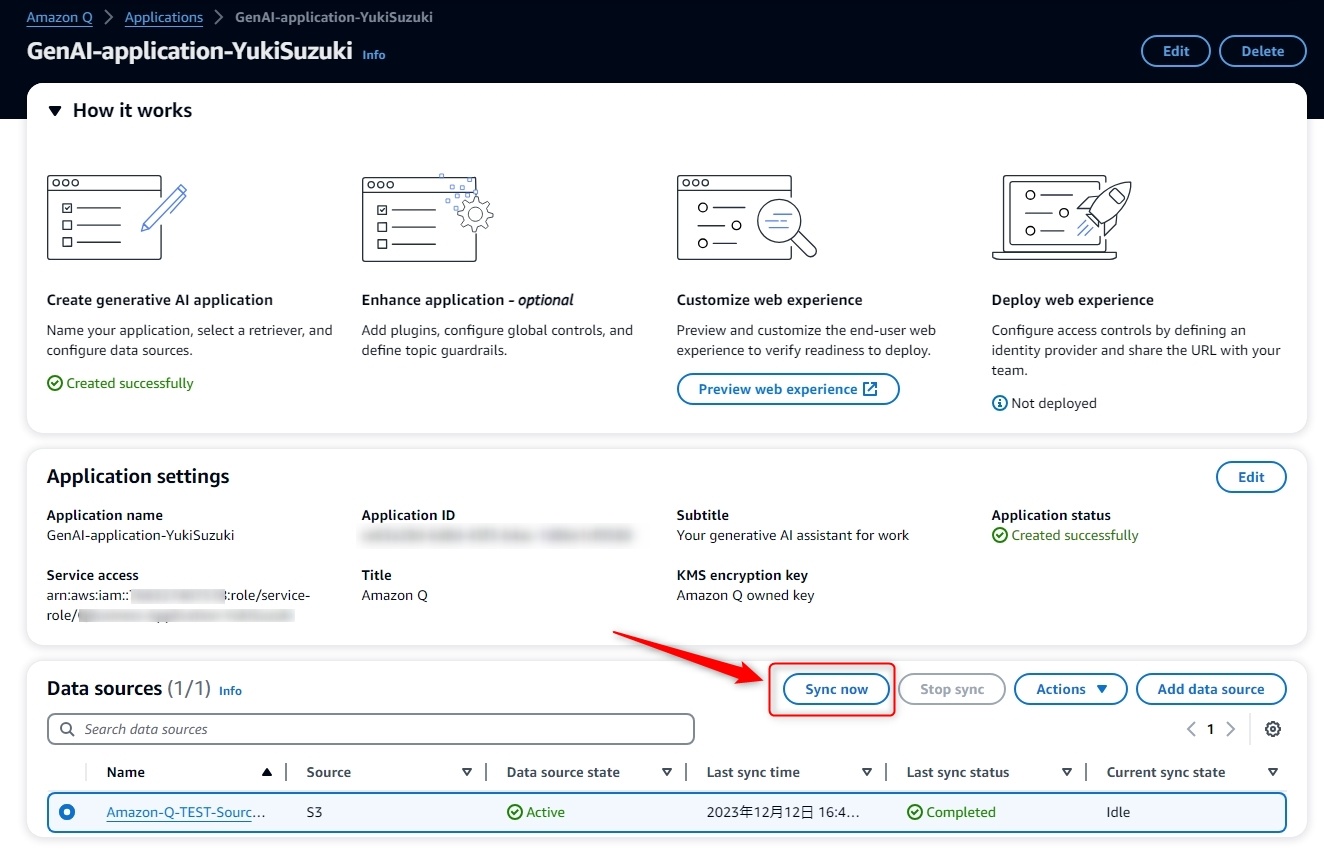
これでAmazon QでQ&Aチャットする準備が整いました。
5. アプリケーションの動作を確認する
Customize web experienceで、Preview web experienceをクリックするとプレビュー画面にいき、会話を開始できます。
[手順]
- [Amazon Q > Applications]より作成したアプリケーションをクリック
-
Customize web experienceからPreview web experienceをクリック - Amazon Qの会話画面が表示されるので質問事項を入力する
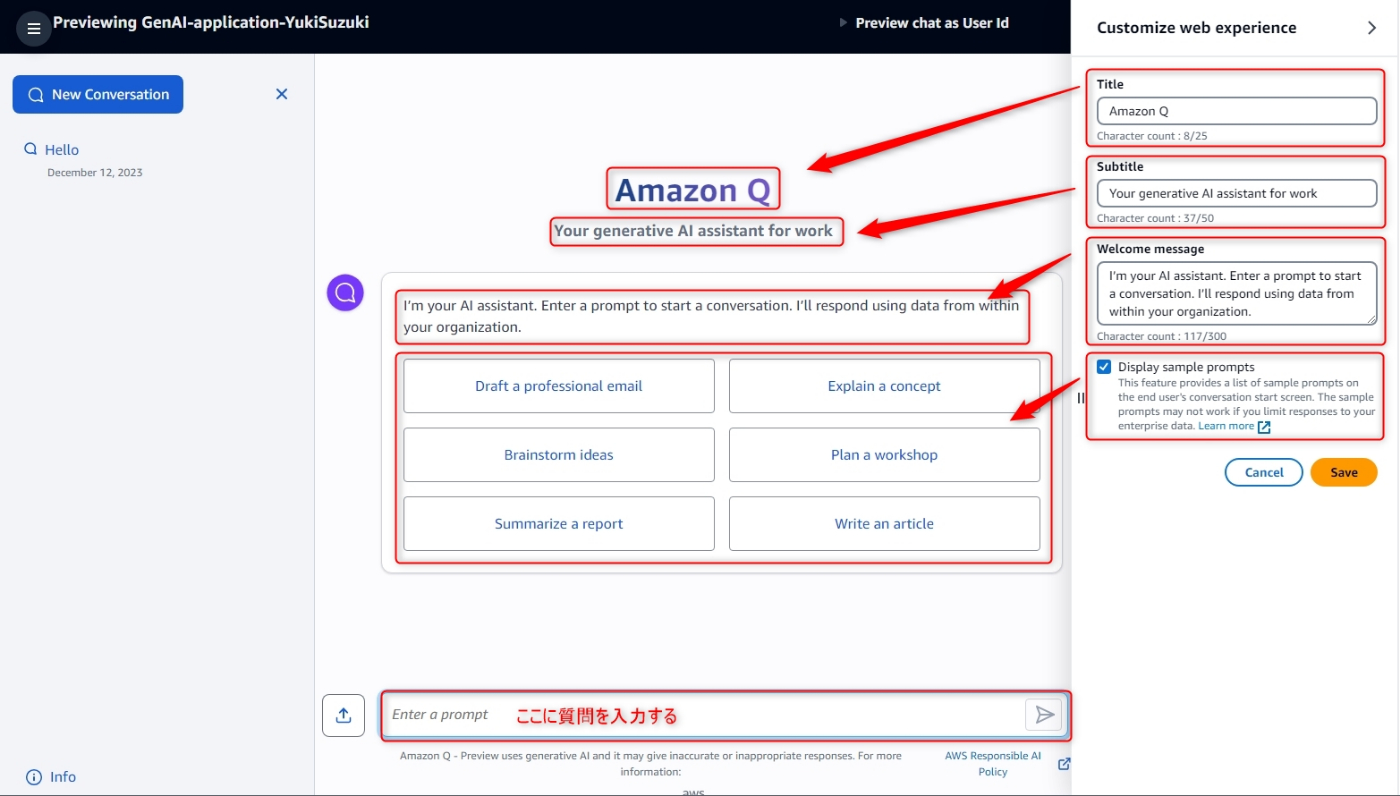
- 会話画面はタイトルやウェルカムメッセージがカスタマイズできるようになっています。
-
Display sample promptsにチェック入れておくとサンプル質問が表示され、クリックするとその内容で質問してくれます。
6. 会話を楽しむ
- 相手がAIとはいえ、まず最初は挨拶からですよね。
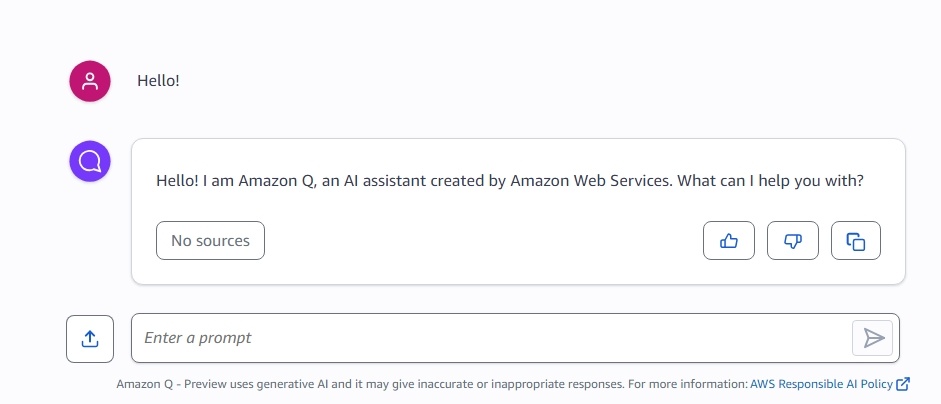
ちゃんと自己紹介してくれました。
※会話はすべて英語でないといけないので、以降の質問は全てgoogle翻訳で英訳して会話プロンプトに入れました。
- 挨拶が済んだところでS3に入れたドキュメントについて質問をしてみます。
「ドキュメントの中身についてサマライズしてほしい!」
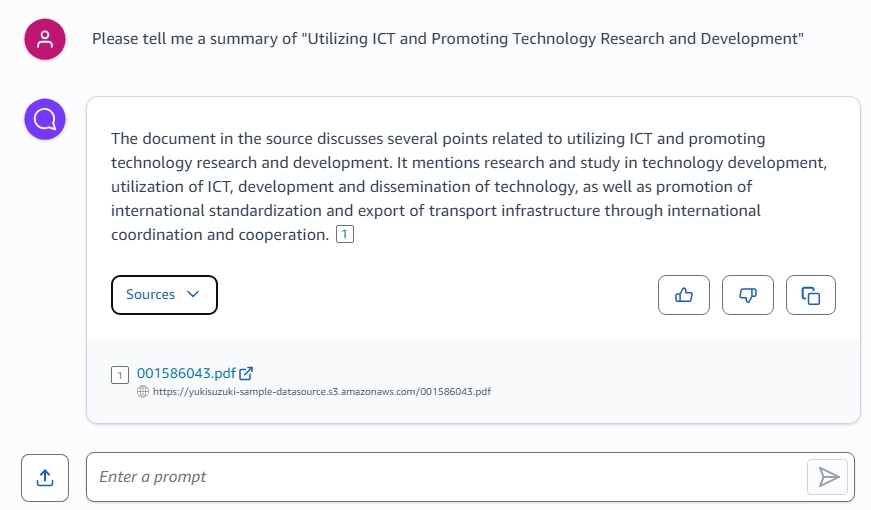
ちゃんと情報源の提示とともにサマライズしてくれました。
- もう少し質問してみます。
「ICTの活用と技術研究開発の推進」で最も大切なことは何ですか?

情報源が一つしかないからか少し薄い回答。でもちゃんとドキュメントを読んで答えてくれているように見えます
まとめ
- とにかく構築が楽ちんで簡単。エンジニアでない、プログラムを知らない人でもノーコードで管理画面ポチポチするだけでプロジェクトや自分のための生成AIアプリケーションを作れてしまう。
- 対応言語が英語だけというのはつらい。早く日本語に対応してほしい!
こんな使い方したいなを考えてみた
- 会社のシステムを誰よりもわかっているスーパーエンジニアAI君
- データソース:JIRA / Confluence / Google Drive / AWSサービス
- システムに関する仕様や設計、ビジネス要求やスケジュールまで質問すれば的確に返してくれる。もしかしたら最適なアーキテクチャの提案もしてくれるかもしれない。
- 頼れる社内ヘルプデスクAI君
- データソース:WEBクローラー / Google Drive
- 社内情報やドキュメントを総なめ。知りたい手続きやルールを情報ソース源の提示とともに手順付きで提示してくれる。
- 情報システム部門では問い合わせにリソースを割く必要がなくなり、回答の精度を上げるためにドキュメントやポータルサイトのブラッシュアップに注力できます。
- 事務系作業の効率化は任せて!業務アシスタントAI君
- データソース:Gmail / Slack / Google Drive
- リモートワークが主体だとどうしてもコミュニケーションのコストがオフラインより高くなりがち。返信で文字打つのだけでも結構大変。業務アシスタントAI君はあなたに変わり返信内容を考えて提案・下書き保存してくれます。送られてきたファイルがあれば解析して要点をまとめて伝えてもくれます。
さいごに
ちょっと考えただけでも色々アイデアが出てきました。
今回はビジネスユーザー向けにフォーカスして書きましたが、開発者向けの機能も数多く提供されています。弄り倒して自分だけの使い方を模索していきたいですね。

株式会社D2C d2c.co.jp のテックブログです。 D2Cは、NTTドコモと電通などの共同出資により設立されたデジタルマーケティング企業です。 ドコモの膨大なデータを活用した最適化を行える広告配信システムの開発をしています。
Discussion