DeepSeek-V3.2-Exp 完全分析:2025年AIモデルの突破とスパース注意機構技術の詳細解析
🎯 核心要点 (TL;DR)
- 技術的突破:細粒度スパース注意機構(DSA)の初実装により、長文処理効率を大幅向上
- コスト優位性:API価格を50%以上削減、入力コストは最低$0.07/百万トークン(キャッシュヒット時)
- 性能維持:計算効率を大幅向上させながら、V3.1-Terminusと同等の性能を維持
- オープンソース支援:完全な推論コード、CUDAカーネル、マルチプラットフォーム展開ソリューションを提供
- アーキテクチャ革新:次世代アーキテクチャへの中間ステップとして、V4版の技術基盤を構築
目次
- DeepSeek-V3.2-Expとは
- スパース注意技術の詳細解析
- 性能ベンチマーク比較
- API価格とコスト分析
- 展開ソリューションと技術実装
- オープンソースエコシステムとコミュニティ支援
- 将来の開発ロードマップ
- よくある質問
DeepSeek-V3.2-Expとは {#deepseek-v32-expとは}
DeepSeek-V3.2-Expは、DeepSeek AIが2025年9月29日にリリースした実験的大規模言語モデルで、同社のAIアーキテクチャ革新における重要なマイルストーンを示しています。V3.1-Terminusのアップグレード版として、V3.2-Expの核心的革新は**DeepSeekスパース注意(DSA)**機構の導入にあります。
核心技術特性
- 基礎アーキテクチャ:V3.1-Terminusをベースに構築、671Bパラメータ規模を維持
- 革新機構:細粒度スパース注意の初実装により、従来のTransformerアーキテクチャの限界を突破
- 効率向上:長文処理シナリオにおいて計算コストとメモリ使用量を大幅削減
- 品質保証:V3.1-Terminusとほぼ同一の出力品質を実現
💡 技術的洞察
スパース注意機構の導入は、大規模モデルアーキテクチャ発展の重要な進化方向を表しています。選択的注意重み計算により、モデルは性能を維持しながら計算複雑度を大幅に削減でき、特に長文シーケンス処理において重要です。
スパース注意技術の詳細解析 {#スパース注意技術}
DeepSeekスパース注意(DSA)の動作原理
従来の注意機構では、シーケンス内の各トークンと他の全トークンとの関係を計算する必要があり、計算複雑度はO(n²)でした。DSAは以下の方法で最適化を行います:
効率向上データ
公式性能データによると:
| 指標 | DeepSeek-V3.1-Terminus | DeepSeek-V3.2-Exp | 改善幅 |
|---|---|---|---|
| 長文推論速度 | ベースライン | 大幅向上 | ~2-3倍 |
| メモリ使用量 | ベースライン | 削減 | ~30-40% |
| 訓練効率 | ベースライン | 向上 | ~50% |
| APIコスト | ベースライン | 削減 | 50%+ |
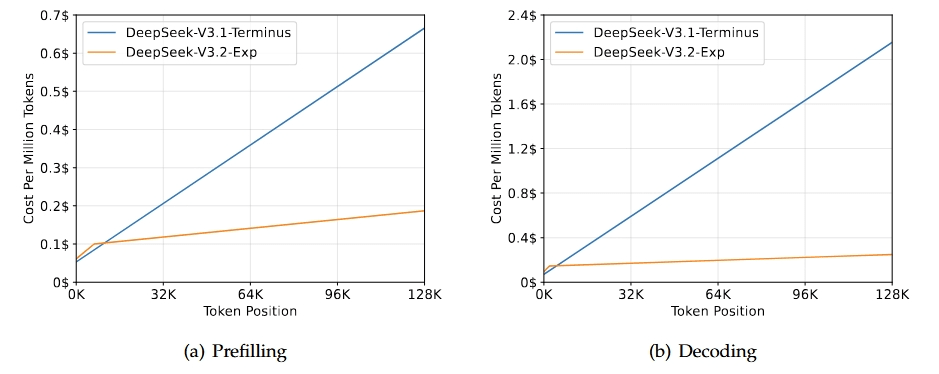
図:異なるトークン位置でのDeepSeek-V3.2-ExpとV3.1-Terminusのコスト比較
性能ベンチマーク比較 {#性能ベンチマーク}
推論モード性能(ツール使用なし)
| ベンチマークテスト | DeepSeek-V3.1-Terminus | DeepSeek-V3.2-Exp | 変化 |
|---|---|---|---|
| MMLU-Pro | 85.0 | 85.0 | 同等 ✅ |
| GPQA-Diamond | 80.7 | 79.9 | -0.8 |
| Humanity's Last Exam | 21.7 | 19.8 | -1.9 |
| LiveCodeBench | 74.9 | 74.1 | -0.8 |
| AIME 2025 | 88.4 | 89.3 | +0.9 ✅ |
| HMMT 2025 | 86.1 | 83.6 | -2.5 |
| Codeforces | 2046 | 2121 | +75 ✅ |
| Aider-Polyglot | 76.1 | 74.5 | -1.6 |
Agentツール使用性能
| ベンチマークテスト | DeepSeek-V3.1-Terminus | DeepSeek-V3.2-Exp | 変化 |
|---|---|---|---|
| BrowseComp | 38.5 | 40.1 | +1.6 ✅ |
| BrowseComp-zh | 45.0 | 47.9 | +2.9 ✅ |
| SimpleQA | 96.8 | 97.1 | +0.3 ✅ |
| SWE Verified | 68.4 | 67.8 | -0.6 |
| SWE-bench Multilingual | 57.8 | 57.9 | +0.1 ✅ |
| Terminal-bench | 36.7 | 37.7 | +1.0 ✅ |
✅ 重要な発見
V3.2-Expは全体的な性能レベルを維持しながら、特定のタスク(数学推論、プログラミング競技、ブラウザ操作など)で向上を示しており、スパース注意機構が効率を向上させるだけでなく、特定のシナリオでモデル能力を強化する可能性があることを示しています。
API価格とコスト分析 {#api価格分析}
最新価格構造
DeepSeek-V3.2-Exp APIはキャッシュベースの差別化価格戦略を採用:
| サービスタイプ | キャッシュヒット | キャッシュミス |
|---|---|---|
| 入力コスト | $0.07/百万トークン | $0.56/百万トークン |
| 出力コスト | $0.16/百万トークン | $0.42/百万トークン |
💰 コスト優位性分析
- 高キャッシュヒット率シナリオ:コスト削減は70-80%に達する可能性
- 新規ユーザーフレンドリー:キャッシュミスでも、ほとんどの競合他社より50%以上安い
- バッチ処理優位性:大規模アプリケーション展開の経済性が大幅向上
競合他社とのコスト比較
展開ソリューションと技術実装 {#展開ソリューション}
ローカル展開オプション
1. HuggingFaceネイティブ展開
# モデル重み変換
cd inference
export EXPERTS=256
python convert.py --hf-ckpt-path ${HF_CKPT_PATH} \
--save-path ${SAVE_PATH} \
--n-experts ${EXPERTS} \
--model-parallel ${MP}
# インタラクティブインターフェース起動
export CONFIG=config_671B_v3.2.json
torchrun --nproc-per-node ${MP} generate.py \
--ckpt-path ${SAVE_PATH} \
--config ${CONFIG} \
--interactive
2. SGLang高性能展開
| ハードウェアプラットフォーム | Dockerイメージ | 特徴 |
|---|---|---|
| H200 | lmsysorg/sglang:dsv32 |
最高性能 |
| MI350 | lmsysorg/sglang:dsv32-rocm |
AMD GPUサポート |
| NPU A2/A3 | lmsysorg/sglang:dsv32-a2/a3 |
国産チップ対応 |
起動コマンド:
python -m sglang.launch_server \
--model deepseek-ai/DeepSeek-V3.2-Exp \
--tp 8 --dp 8 --page-size 64
3. vLLM統合
vLLMはday-0サポートを提供。詳細設定は公式recipesを参照。
ハードウェア要件推奨
| 展開規模 | GPU構成 | メモリ要件 | 適用シナリオ |
|---|---|---|---|
| 小規模テスト | 1x H100 | 80GB | 研究開発 |
| 中規模 | 4x H100 | 320GB | 企業アプリケーション |
| 大規模本番 | 8x H100 | 640GB+ | 商用サービス |
オープンソースエコシステムとコミュニティ支援 {#オープンソースエコシステム}
核心オープンソースコンポーネント
1. TileLangカーネル
- 特徴:高い可読性、研究用途に適している
- リポジトリ:TileLang Examples
- 用途:アルゴリズム研究、教育デモンストレーション
2. 高性能CUDAカーネル
- DeepGEMM:インデクサーlogitカーネル(ページング版含む)
- FlashMLA:スパース注意専用カーネル
- 性能:本番環境最適化、大規模展開対応
ライセンスとコンプライアンス
- オープンソースライセンス:MITライセンス
- 商用フレンドリー:商用利用と修正を許可
- コミュニティ貢献:コミュニティの開発・最適化参加を歓迎
⚠️ 展開時の注意事項
- ハードウェア互換性:GPUドライバーがCUDA 11.8+をサポートしていることを確認
- メモリ管理:大規模モデル推論には十分なGPUメモリが必要
- ネットワーク設定:API呼び出しには安定したネットワーク接続が必要
- 監視・アラート:リソース使用量監視の設定を推奨
将来の開発ロードマップ {#将来のロードマップ}
短期計画(2025年10月-12月)
コミュニティディスカッションと公式情報に基づく:
技術発展方向
-
アーキテクチャ革新:
- より効率的なスパース注意パターン
- Mixture of Expertsシステム最適化
- マルチモーダル能力統合
-
Agent能力:
- R2 agentバージョン開発
- MCP(Model Context Protocol)サポート
- ツール使用能力強化
-
エコシステム構築:
- より多くの展開プラットフォーム対応
- 開発者ツール改善
- コミュニティ貢献メカニズム
🤔 よくある質問 {#よくある質問}
Q: DeepSeek-V3.2-ExpとV3.1-Terminusの根本的違いは何ですか?
A: 主な違いは注意機構の実装にあります。V3.2-ExpはDeepSeekスパース注意(DSA)を導入し、選択的に注意重みを計算することで、長文処理の計算複雑度を大幅に削減します。モデルパラメータ規模は同じ(671B)ですが、V3.2-Expは訓練と推論効率において質的向上を実現しています。
Q: スパース注意はモデル出力品質に影響しますか?
A: 公式ベンチマークテストによると、V3.2-ExpはほとんどのタスクでV3.1-Terminusと同等の性能を示し、一部のタスクでは向上も見られます。スパース注意機構は慎重に設計され、最も重要な注意接続を保持するため、出力品質への影響は微小です。
Q: 50%のAPI価格削減はどのように実現されましたか?
A: 価格削減は主に2つの要因によります:1)スパース注意機構による計算コストの大幅削減;2)キャッシュ機構導入による重複計算の削減。キャッシュヒットリクエストでは、コストを70-80%削減できます。
Q: 適切な展開ソリューションの選択方法は?
A: 推奨事項:
- 研究用途:HuggingFaceネイティブ展開、デバッグと修正が容易
- 本番環境:SGLangまたはvLLM、より優れた性能
- リソース制約:API呼び出しを検討、より低コスト
- 特別要件:ハードウェアプラットフォームに応じて対応するDockerイメージを選択
Q: V3.2-ExpはV3.1-Terminusを置き換えますか?
A: 公式計画によると、V3.1-Terminusは2025年10月15日までサービスを維持し、その後コミュニティフィードバックに基づいてV3.2正式版のリリースを決定します。V3.2-Expは現在実験版で、主に技術検証とコミュニティテスト用です。
Q: オープンソースコミュニティはV3.2-Expの発展にどう参加できますか?
A: コミュニティは以下の方法で参加できます:
- GitHubでのIssueとPull Request提出
- 高性能カーネル最適化への貢献
- ベンチマークテストと性能評価への参加
- 展開経験とベストプラクティスの共有
- Discordコミュニティディスカッションへの参加
まとめと提言
DeepSeek-V3.2-Expのリリースは、大規模言語モデルアーキテクチャ革新の重要な進歩を示しています。スパース注意技術の成功的応用は、モデル効率を向上させるだけでなく、業界全体に新しい技術パスを提供しています。
重点行動提言
-
開発者:
- V3.2-Exp API性能を早急にテスト
- 特定アプリケーションシナリオでのスパース注意の影響を評価
- オープンソースコミュニティに参加し、コードとフィードバックを貢献
-
企業ユーザー:
- 既存アプリケーションの移行を検討してコスト削減
- 長文処理シナリオでの性能向上を評価
- 新価格構造に基づくコスト最適化戦略を策定
-
研究機関:
- スパース注意機構の理論基盤を深く研究
- 他のモデルアーキテクチャでの応用可能性を探索
- ベンチマークテストと性能評価作業に参加
DeepSeek-V3.2-Expは単なる技術製品ではなく、オープンソースAIエコシステム発展の重要なマイルストーンです。より多くの革新技術の導入とコミュニティの積極的参加により、より効率的で経済的なAIソリューションが近い将来に現実となることが期待されます。
📚 関連リソース
最終更新:2025年9月29日
Discussion