第4章 MapReduce計算フレームワーク-1
本章に入る前に、まずはMapReduceの利用状況について少し触れておく。
Hadoopにおいては、MapReduceは非常に基本的かつ代表的な分散計算フレームワークであり、関連の知識が相当多いです。しかし、実際の運用では、MapReduceが直接使われるケースがそれほど多くない。理由は、より高性能で柔軟な処理基盤である Spark や Flink などのフレームワークに置き換えられつつある。また、MapReduceコーディングはやや複雑で、ビッグデータにおける要求を効率的に満たすことにならない。
この本章は、主にMapReduceコーディングを読み取れるようになること、そして運行仕組みを理解することを目的としてする。コードを一から書くことは求めない。
本章では、MapReduceのソースコードを共に仕組みや概念を説明していく。先にコードの解説を行い、基本的な理解を得た上で一定の概念があると、内部の運行仕組みと設計について理解しやすくなるでしょう。
第1節 MapReduceの紹介
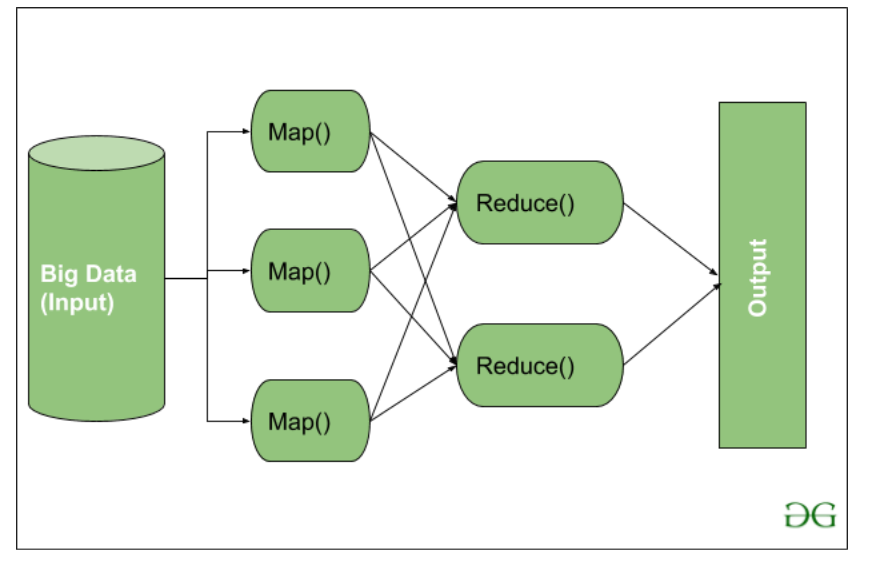
MapReduceは、Hadoopにおける分散計算フレームワークとして、日常的なデータ処理タスクを担う役割を果たす。その思想の核心は「分割(Map)」と「統合(Reduce)」という2つ策略がある。それを活用するんで、並行処理の特性を生かし、大規模データの効率的な処理を実現している。
MapReduceの処理流れは、以下の2段階に分けている:
- Map段階:入力データを複数の部分に「分割」し、個別の処理単位に分解する。これにより、複雑なタスクを複数の独立したタスクとして並列実行できるようになる。
- Reduce段階:Mapの結果を受け取り、分散されたデータを「統合」する。必要な処理を行った後、最終的な結果を出力する。
第2節 WordCount公式案例にいて
MapReduceの基本的な処理モデルを理解するために、文字列中の単語の出現回数を数えて統計するWordCount案例を紹介する。
この機能は公式のサンプルはパッケージhadoop-mapreduce-examples-2.9.2.jarに含まれる。通常/opt/bigdata/servers/hadoop-2.9.2/share/hadoop/mapreduceディレクトリにいる。

このJarファイルをHadoopサービスからダウンロードし、Ideaに導入して利用することができる。WordCountクラスはその実行ロジックである。

WordCountコードは、以下の3つの主要部分で構成されている。
Map階段
- Mapper親クラスを継承して親クラスのmapメソッドを書き直して分割ロジックを記述する。

- 入力値keyが1行文字のオフセット(offset)で、行数と理解していい、特に使われてない。
- 入力値valueがその行の文字列内容です。
- ロジックとしては、1行の文字列を空白で分割し。複数の単語を含める結果値
itrがループ処理をする。単語ごとに<key:単語, value:出現回数=1>形式でcontextに書き込む。
Reduce階段
- Reducer親クラスを継承して親クラスのreduceメソッドを書き直す統合処理のロジックを記述する。

-
入力値keyがMap階段から出力のkey値で、valuesがその単語に対応する出現回数の反復子(Iterable)です。例えば、
[1,1,1]と理解していい。
何で反復子には1で、それはMapメソッドに<key:単語, value:出現回数=1>を出力するため、<key,1>を収集してvalues集合をなして反復子に入れる。 -
単語keyに対応する総数
<key:単語, sum:総数>形でcontextに入れる。最後に出力結果をファイルに書き込む。
Driver
- 主プロセス。配置の実装、Job対象の設定、入力と出力ファイルのアドレスの添加と、最後のJobタスクの実行などをまとめて定義する。
- 最後に
job.waitForCompletion(true)を呼び出すんで、MapReduceジョブの実行が開始される。

MapReduce開発では、開発者が主にMapメソッドとReduceメソッドのロジック実装に集中すればよく、データの分割や統合処理の詳細な過程はフレームワーク側が自動的に処理し、触れることは必要ない。
第3節 手動的にWordCount機能を実現
MapReduceコーディング基本規範に従い、自分でWordCount機能を実現する。
IntelliJ IDEA などの開発ツールを使ってMavenプロジェクトを新規作成し、Mapper,Reducer,Driverの各クラスをコーディングする。
実現目標
コンテストに単語の出現回数を統計し、結果を出力する。
環境準備
- HADOOP_HOME環境変数の設定
hadoop-2.9.2インストールパッケージがダウンロードし、任意のディレクトリに置いて解凍する。
hadoop-2.9.2URL:Apache Hadoop

winOSの場合、Environment variables(環境変数)を検索して設定画面を開く。下のSystem variablesにHADOOP_HOMEとE:\Program Files\hadoop-2.9.2引数を追加する。

次は、System variablesにPath選択肢に入って%HADOOP_HOME%\bin値を追加する。

D:\InstallPackage\hadoop-2.9.2\etc\hadoop\hadoop-env.cmdファイルにJAVA_HOMEアドレスを追記する。

Hadoopサービスをwinにインストールするかどうか確認する。
hadoop version

HADOOP_HOMEとhadoop-env.cmdファイルのJAVA_HOMEパスはスペースが許さない。そのため新たにJDK をインストールする。JAVA_HOME指定先JDKに実際に存在する限り、環境変数にのJAVA_HOMEと不一致にしても構わない。
コーディング
- Hadoopプログラムの構築に入って、Maven依頼を導入
<dependency>
<groupId>org.apache.hadoop</groupId>
<artifactId>hadoop-common</artifactId>
<version>2.9.2</version>
</dependency>
<dependency>
<groupId>org.apache.hadoop</groupId>
<artifactId>hadoop-client</artifactId>
<version>2.9.2</version>
</dependency>
<dependency>
<groupId>org.apache.hadoop</groupId>
<artifactId>hadoop-hdfs</artifactId>
<version>2.9.2</version>
</dependency>
- Mapper部分
import org.apache.hadoop.io.IntWritable;
import org.apache.hadoop.io.LongWritable;
import org.apache.hadoop.io.Text;
import org.apache.hadoop.mapreduce.Mapper;
import java.io.IOException;
public class WordCountMapper extends Mapper<LongWritable, Text, Text, IntWritable> {
Text text = new Text();
IntWritable intWritable = new IntWritable(1);
@Override
protected void map(LongWritable key, Text value, Mapper<LongWritable, Text, Text, IntWritable>.Context context)
throws IOException, InterruptedException {
//一行文字を取得
String str = value.toString();
//文字を区切って単語数組になる
String[] strs = str.split(" ");
//出力
for (String s : strs) {
text.set(s);
context.write(text, intWritable);
}
}
}
- Reducer部分
import org.apache.hadoop.io.IntWritable;
import org.apache.hadoop.io.Text;
import org.apache.hadoop.mapreduce.Reducer;
public class WordCountReducer extends Reducer<Text, IntWritable, Text, IntWritable> {
Integer sum;
IntWritable intWritable = new IntWritable();
@Override
protected void reduce(Text key, Iterable<IntWritable> values, Reducer<Text, IntWritable, Text, IntWritable>.Context context)
throws IOException, InterruptedException {
sum = 0;
//累積加算
for (IntWritable value : values) {
sum += value.get();
}
//出力
intWritable.set(sum);
context.write(key,intWritable);
}
}
- Driver部分
import java.io.IOException;
import org.apache.hadoop.conf.Configuration;
import org.apache.hadoop.fs.Path;
import org.apache.hadoop.io.IntWritable;
import org.apache.hadoop.io.Text;
import org.apache.hadoop.mapreduce.Job;
import org.apache.hadoop.mapreduce.lib.input.FileInputFormat;
import org.apache.hadoop.mapreduce.lib.output.FileOutputFormat;
public class WordcountDriver {
public static void main(String[] args) throws IOException,
ClassNotFoundException, InterruptedException {
//配置ファイルを設定とJobを作成
Configuration configuration = new Configuration();
Job job = Job.getInstance(configuration);
//Mapper、Reducer、Driverクラスを添加
job.setJarByClass(WordcountDriver.class);
job.setMapperClass(WordCountMapper.class);
job.setReducerClass(WordCountReducer.class);
//Mapの出力値のタイプ
job.setMapOutputKeyClass(Text.class);
job.setMapOutputValueClass(IntWritable.class);
//最終出力値のタイプ
job.setOutputKeyClass(Text.class);
job.setOutputValueClass(IntWritable.class);
//入力と出力ファイルのアドレス
FileInputFormat.setInputPaths(job, new Path(args[0]));
FileOutputFormat.setOutputPath(job, new Path(args[1]));
//タスクをコミット
boolean result = job.waitForCompletion(true);
System.exit(result ? 0 : 1);
}
}
クラス上部の導入を注意し、ほとんどHadoop下の依頼で、正しく運行するため一致にしてください。
プログラムの実行(ローカル環境)
- プログラムの配置
今回の実行はローカルモードで行い、分散サービスを依頼しない。入力D:\wc.txtと出力ファイルのパスD:\outputを引数としてmainメソッド入力値に添加する。


下記はwc.txt内容です。
hadoop Zookeeper Hive mapreduce yarn HBase
hdfs Spark Zookeeper hadoop mapreduce
mapreduce Fink yarn nodemanager Hive
NameNode nodemanager Spark
Fink Bigdata ResourceManager Bigdata Zookeeper
HBase Zookeeper Spark Fink
- 環境の配置
Windows環境でD:\InstallPackage\hadoop-2.9.2\binにwinutils.exe、hadoop.dll2つのファイルが必要です。お勧め方法はGitHubから正しいbinフォルダをダウンロードしてローカルを上書きする。
ダウンロードURL:GitHub - cdarlint/winutils: winutils.exe hadoop.dll and hdfs.dll binaries for hadoop windows

git clone --no-checkout https://github.com/cdarlint/winutils.git
#或いは
git clone --no-checkout https://github.com/cdarlint/winutils.git <ローカルディレクトリ>
#最上層のディレクトリに入って
cd winutils
#指定ディレクトリダをウンロード
git config core.sparsecheckout true
echo "hadoop-2.9.2/bin" >> .git/info/sparse-checkout
git checkout master

取得したhadoop-2.9.2\bin フォルダ内のファイルをD:\InstallPackage\hadoop-2.9.2にコピーして上書きする。

- WordcountDriverの実行

すべての設定が正しく完了していれば、上図のように正常終了するはずです。
下図はwinutils.exe、hadoop.dll欠いてのエラーメッセージです。


-
D:\output結果の確認

二度と実行すれば、このフォルダを空きにする必要です。
- part-r-00000結果ファイルを開くと下図のように単語とその出現回数が1行ずつ表示されている。

二度と実行すれば、このD:\outputフォルダを削除する必要です。

プログラム運行(Hadoop分散式サービス)
- 分散式サービスの準備
Hadoopサービスを実行する。出力先のディレクトリ/wcoutputにファイルが既に存在している場合は、事前に削除しておく必要がある。

ウェブ上で削除することはでき、対象ディレクトリへの権限を付与しておく。
#そのディレクトリに権限を与える
hdfs dfs -chmod -R 777 /

エラーメッセージまだあるけど、実は消除した。

- プログラムをパッケージ化にする
IntelliJ IDEAツールを使い、右側のMavenを開けてpackage選択肢をダブルクリックすると、プロジェクトがビルドされ、JAR ファイルが生成される。

もし全てのコードをパッケージ化にしたくない、プラグイン配置に下の内容を添加して指定のクラスのみをパッケージ化できる。
<plugins>
<plugin>
<groupId>org.apache.maven.plugins</groupId>
<artifactId>maven-compiler-plugin</artifactId>
<configuration>
<includes>
<include>com/javapractice/hadoop/**</include>
</includes>
</configuration>
</plugin>
</plugins>

rzコマンドを入力してパッケージをアップロードする。


- パッケージを運行
hadoop jar JavaPractice-1.0.0-SNAPSHOT.jar com.javapractice.hadoop.WordCountDriver /wcinput /wcoutput

ウェブに出力結果を見える。

#出力内容を検査
hdfs dfs -cat /wcoutput/part-r-00000

ここまで手動的にWordCount機能を実現するのが終わりです。
第4節 Hadoopの直列化
4.1 Hadoopの直列化とは
直列化は、ネットワーク通信でデータを送信したり、対象をファイルに永続化したりする際に、送信効率や保存容量などを考慮して、対象をバイナリ形式に変換する処理です。
Hadoopでは、Java標準のSerializableを使用せず、独自の直列化クラスを採用している。例えば、Wordcount案例にIntWritable、longWritableクラスが使用される。
この理由は、クラスター内の節点の間通信がRPC(Remote Procedure Call)を通じて行う。RPCでは、メッセージを直列化にしてバイナリストリームに変換し、リモート節点に送転送する。リモート節点は受信してバイナリデータを逆直列化にして元の対象に復元する。その過程は、以下の特性が特に重要です:
- コンパクト性: 直列化されたデータがコンパクトであるほど、ネットワーク帯域を効率よく活用できる。
-
高速性: 直列化/逆直列化処理にかかる計算コストが低い。
一方、JavaのSerializableを使用した場合、検証情報、ヘッダー、継承構造など不要な情報が付加されて不利となる。
次に、Hadoopにの基本データ型とJavaの基本型の対応表。
| Java類型 | Hadoop Writable類型 |
|---|---|
| boolean | BooleanWritable |
| byte | ByteWritable |
| int | IntWritable |
| float | FloatWritable |
| long | LongWritable |
| double | DoubleWritable |
| String | Text |
| map | MapWritable |
| array | ArrayWritable |
4.2 直列化インターフェース実装
Hadoopでは、独自のデータ型を使用して処理を行う。そのため、JavaのBeanオブジェクトをHadoop内で利用するには、Writableインターフェースの実装が必須となる。
以下は、実装案例です。
public class Student implements Writable {
private Long id;
private String name;
private Integer age;
//直列化
@Override
public void write(DataOutput dataOutput) throws IOException {
dataOutput.writeLong(id);
dataOutput.writeUTF(name);
dataOutput.writeInt(age);
}
//逆直列化
@Override
public void readFields(DataInput dataInput) throws IOException {
this.id = dataInput.readLong();
this.name = dataInput.readUTF();
this.age = dataInput.readInt();
}
}
Writableインターフェースを実装する時は、直列化write()と逆直列化readFields()メソッドを上書きしなければならない。あと、直列化と逆直列化メソッドにデータ型も一致にする必要です。String型の直列化がwriteUTF()メソッドで、writeString()のようなメソッドがない。その2点を注意が必要です。
MapReduceについての基本的な理解は、ここまででおおよそ得られたかと思います。
次の章では、MapReduceの内部的な実行の仕組みについて解説していきます。
Discussion