🧸
第3章 HDFSの分散ファイルシステム-1/2
第1節 HDFSの紹介
HDFS(正式名称:Hadoop Distributed File System、Hadoop 分散ファイルシステム)はHadoopの中心的なコンポーネントであり、分散ストレージサービスを提供します。分散ファイルシステムは複数のコンピュータに跨り、超大規模データの保存と処理に必要な拡張性を実現します。
重要な概念
- Master/Slave構造
HDFSは典型的なMaster/Slave構造を持っています。HDFSクラスタは通常、1つのNameNodeと複数のDataNodeで構成されます。NameNodeはクラスタの主節点(Master Node)であり、DataNodeは従節点(Slave Node)です。 - ブロックストレージ(block storage)
HDFS内のファイルは物理的にブロック(block)で分割されて保存されます、ブロックのサイズは設定引数で規定できます。Hadoop 2.xでは既定のブロック大小は128Mです。 - 命名空間(NameSpace)
HDFSは従来の階層型ファイル構造を支持しています。ユーザーやプログラムなどはディレクトリを作成し、その目録にファイルを保存できます。HDFSの命名空間の階層構造は、ほとんど一般人的なファイルシステムに似ています:ファイルの作成、削除、移動、名前変更が可能です。
HDFSはクライアントに対して、抽象的な木構造のディレクトリを提供します。アクセス形式はhdfs://Namenode_Hostname:port/test/inputです。 例:hdfs://centos1:9000/test/input
NameNodeはファイルシステムの名前空間を管理しており、ファイルシステム名前空間や属性の変更は全てNameNodeによって記録されます。 - NameNodeのメタデータ管理
ディレクトリ構造とファイルのブロック位置情報をメタデータと呼びます。NameNodeのメタデータは、各ファイルのブロック情報が記録します。 - DataNodeのデータストレージ
ファイルの各ブロックの具体的なストレージ管理はDataNodeによって行われます。一つのブロックは複数のDataNodeで保存され、DataNodeは定期的に自分が保持しているブロック情報をNameNodeに報告します。 - 副本仕組み
耐障害性を確保するために、ファイルのすべてのブロックには副本が存在します。各ファイルのブロック大小と副本数は設定可能です。HDFSは特定のファイルの副本数を指定でき、後から変更することも可能です。副本数の既定値は3です。 - HDFSの利用に適した場合
HDFSは一度の書き込みと複数回の読み出しに適した場面を想定して設計されています。ファイルのランダムな変更は支持していません(追記は支持されているが、ランダムな更新は支持されていません)。そのため、HDFSは大規模データ分析の基盤ストレージサービスに適していますが、オンラインストレージ(online storage)などのアプリケーションには適していません。
HDFSの構造

- NameNode(nn):Hdfsクラスタの管理者、Master
- Hdfsの名前空間(NameSpace)を管理
- 副本情報を管理
- ファイルブロックのマッピング情報を記録
- クライアントの読み書き請求を処理
- DataNode:任務の実行者、Slave
- NameNodeからの命令を受け、DataNodeが実際の操作を実行
- データブロックを保存
- データブロックの読み書きを担当
- Client:クライアント
- ファイルをHDFSにアップロードする際、ClientはファイルをBlockに分割してアップロードを行う
- NameNodeと情報をやり取りし、ファイルの位置情報を取得
- DataNodeと情報をやり取り、ファイルの読み書きを行う
- Clientを通じてコマンドを使用し、HDFSの管理やアクセスを実現する
第2節 クライアント操作
2.1 Shellコマンド方式
- 二つの書き方、後ろの部分が同じで
hadoop fs コマンド
hdfs dfs コマンド
#同じな効果
hadoop fs -cat /wcoutput/part-r-00000
hdfs dfs -cat /wcoutput/part-r-00000
- 全てのコマンドを検査
hadoop fs

- 常用のコマンド
#具体のコマンドに関連の引数を表す
hadoop fs -help mkdir
#ディレクトリの顕示
hadoop fs -ls /
#ディレクトリを作成
hadoop fs -mkdir -p /bigdata/test
#ディレクトリを消除し、空でないディレクトリが消除られない
hadoop fs -rmdir -p /bigdata/test

- 本地のファイルをHDFSにアップロードし、元のファイルを消除られてある
vim hadoopTest.txt
hadoop fs -moveFromLocal hadoopTest.txt /bigdata/test

- 目標ファイルをhadoopTestの中に追加し、元のファイルが保留される
vim hdfsTest.txt
hadoop fs -appendToFile hdfsTest.txt /bigdata/test/hadoopTest.txt
#全てのファイルを表し
hadoop fs -cat /bigdata/test/hadoopTest.txt
#ファイルの末尾内容を表し
hadoop fs -tail /bigdata/test/hadoopTest.txt

- ファイルをコピーして本地又はHDFSに発送し、二つの書き方が一様です
hadoop fs -copyFromLocal hdfsTest.txt /bigdata/test/
hadoop fs -put hdfsTest.txt /bigdata/test/
hadoop fs -copyToLocal /bigdata/test/hadoopTest.txt /root
hadoop fs -get /bigdata/test/hadoopTest.txt /root

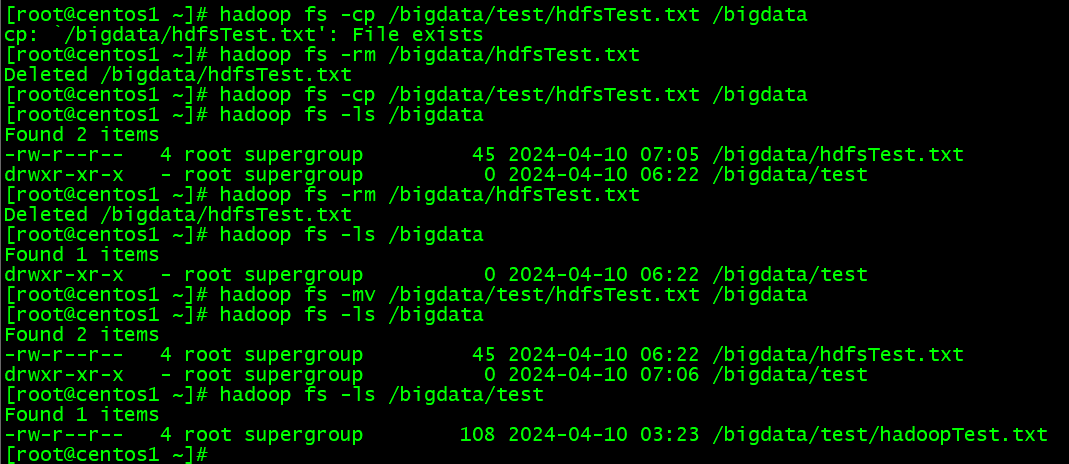
#HDFSファイルをコピーすると別のアドレスに移動し
hadoop fs -cp /bigdata/test/hdfsTest.txt /bigdata
#HDFSファイルを消除
hadoop fs -rm /bigdata/hdfsTest.txt
#HDFSファイルの移動
hadoop fs -mv /bigdata/test/hdfsTest.txt /bigdata
#直接にHDFS上にファイルを作成
hadoop fs -touchz /bigdata/test/touchTest.txt

ファイルの作成のコマンドあるけれど、HDFS上に書き込みのコマンドがありません。この点から見えてファイルの変更におけての支持が上手くない、ただ整体の大小の変わりで、データ内容の変更に係わらず場合が適用です。
#HDFSの権限管理コマンドがlinuxと同じで
hadoop fs -chmod 666 /bigdata/test/hadoopTest.txt
hadoop fs -chown root:root /bigdata/test/hadoopTest.txt
hadoop fs -chgrp root /bigdata/test/hadoopTest.txt

#ファイルの大小を表し
hadoop fs -du /bigdata/test/hadoopTest.txt

#ファイルの副本数を設定
hadoop fs -setrep 10 /bigdata/test/hadoopTest.txt



ここで設定された副本数は、NameNodeのメタデータに記録されるだけ、実際に副本の数量が本当に存在するかどうかは節点数に依存します。現在はサーバが4台しかないため、最大数が4つしか保留でません。節点数が10台に増えた限り、10に設定することが可能になります。
2.2 JAVAクライアント
Javaを使って外部からHadoopを利用する方法には多くの内容が含まれますので、ここで一つの入門用の例を挙げて、Javaを通じてHadoopクラスタを使用する方法を説明します。
- Maveプロジェクトに下の依頼を追加
<dependencies>
<dependency>
<groupId>junit</groupId>
<artifactId>junit</artifactId>
<version>RELEASE</version>
</dependency>
<dependency>
<groupId>org.apache.logging.log4j</groupId>
<artifactId>log4j-core</artifactId>
<version>2.8.2</version>
</dependency>
<dependency>
<groupId>org.apache.hadoop</groupId>
<artifactId>hadoop-common</artifactId>
<version>2.9.2</version>
</dependency>
<!-- https://mvnrepository.com/artifact/org.apache.hadoop/hadoop-client-->
<dependency>
<groupId>org.apache.hadoop</groupId>
<artifactId>hadoop-client</artifactId>
<version>2.9.2</version>
</dependency>
<!-- https://mvnrepository.com/artifact/org.apache.hadoop/hadoop-hdfs -->
<dependency>
<groupId>org.apache.hadoop</groupId>
<artifactId>hadoop-hdfs</artifactId>
<version>2.9.2</version>
</dependency>
</dependencies>
デバッグしやすいようにsrc/main/resources目録にlog4j.propertiesファイルを作成して完全の運行ログを出せます。
log4j.rootLogger=INFO, stdout
log4j.appender.stdout=org.apache.log4j.ConsoleAppender
log4j.appender.stdout.layout=org.apache.log4j.PatternLayout
log4j.appender.stdout.layout.ConversionPattern=%d %p [%c] - %m%n
log4j.appender.logfile=org.apache.log4j.FileAppender
log4j.appender.logfile.File=target/spring.log
log4j.appender.logfile.layout=org.apache.log4j.PatternLayout
log4j.appender.logfile.layout.ConversionPattern=%d %p [%c] - %m%n

- 具体コードの表示
public class HdfsClient {
private FileSystem fs = null;
@Before
public void start() throws URISyntaxException, IOException, InterruptedException{
Configuration configuration = new Configuration();
configuration.set("fs.defaultFS", "hdfs://192.168.31.135:9000");
fs = FileSystem.get(new URI("hdfs://192.168.31.135:9000"), configuration, "root");
}
@Test
public void testMkdirs() throws IOException {
fs.copyFromLocalFile(new Path("D:/log_info.log"), new Path("/bigdata/test"));
}
@After
public void end() throws IOException {
fs.close();
}
}
これはファイルのアップロードを実現する例です。すべての流れを理解するのは難しくないと思いますので、大まかな概念をつかめれば、入門としては十分です。
Discussion