第2章 Hadoopの分散システム組み立て


バージョン情報
- HadoopはJava言語で書かれるため、Java環境(JVM)が必要で、 JDKバージョンはJDK8です。
- 統一的にVMwareの仮想マシンを使用して、Linuxの4つの節点を準備し、LinuxOSはCentos7です。
- Hadoopの構築モードの選べ
- 単一節点モード:単一節点モードはクラスタを使用しないため、本番環境ではこの方法は使用されない。
- 単一節点模擬分布モード:単一節点、マルチスレッド(multi-thread)でクラスタの効果を模擬するが、本番環境ではこの方法は使用されない。
- 完全分散モード:複数節点を持ち、実際の生産環境のモードと一致しています。本番環境ではこのモードが推奨される。
第1節 環境準備
Hadoopの分散システムを構築する前に、クラスタの環境設定が必要です。ここでは主要なポイントを紹介し、詳しい設定手続きが以下の文章で確認できます。
- クラスタは全て4つのサービスが含まれ、hostファイルにIPアドレスのマッピングが図のように示す。

- firewall/selinuxを停止
systemctl status firewalld

- 4つのサーバの間にパスワード不要で登録
- 4つのサーバの時刻が一致にし
Hadoop節点の配置
| 対象 | centos1 | centos2 | centos2 | centos2 |
|---|---|---|---|---|
| HDFS | NameNode,DataNode | SecondaryNameNode,DataNode | DataNode | DataNode |
| YARN | NodeManager | NodeManager、ResourceManager | NodeManager | NodeManager |
第2節 Hadoopの組み立て
2.1 Hadoopインストール
- ソフトを格納のディレクトリを作成
mkdir -p /opt/bigdata/servers
- rzコマンドでHadoopパッケージをそのディレクトリにアップロード

- パッケージ解凍
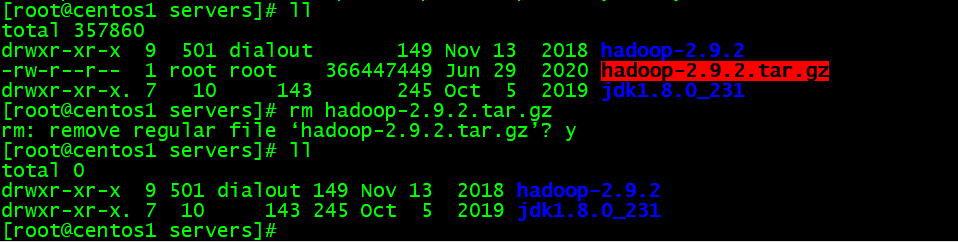
tar -zxvf hadoop-2.9.2.tar.gz
#元パッケージを消除
rm hadoop-2.9.2.tar.gz
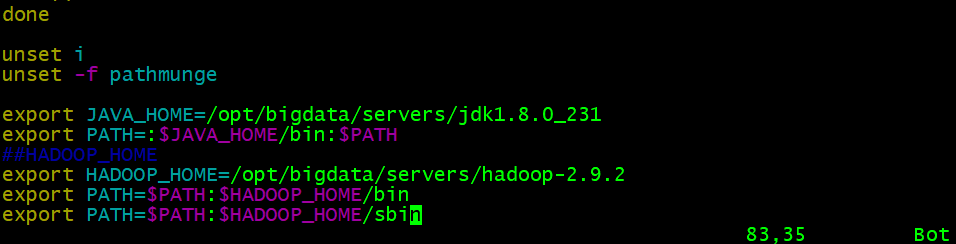
- Hadoopの環境引数を設定
vim /etc/profile
##HADOOP_HOME
export HADOOP_HOME=/opt/bigdata/servers/hadoop-2.9.2
export PATH=$PATH:$HADOOP_HOME/bin
export PATH=$PATH:$HADOOP_HOME/sbin
#環境引数を有効にし
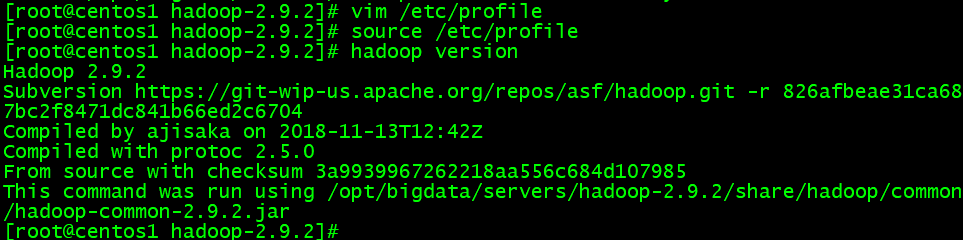
source /etc/profile
- Hadoop検証
hadoop version
Hadoopディレクトリ説明
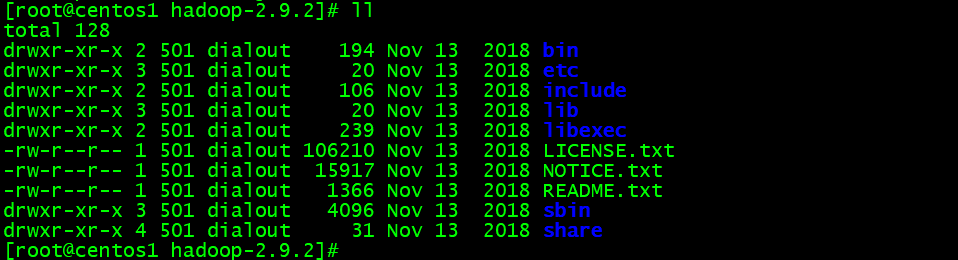
drwxr-xr-x 2 501 dialout 194 Nov 13 2018 bin
drwxr-xr-x 3 501 dialout 20 Nov 13 2018 etc
drwxr-xr-x 2 501 dialout 106 Nov 13 2018 include
drwxr-xr-x 3 501 dialout 20 Nov 13 2018 lib
drwxr-xr-x 2 501 dialout 239 Nov 13 2018 libexec
drwxr-xr-x 3 501 dialout 4096 Nov 13 2018 sbin
drwxr-xr-x 4 501 dialout 31 Nov 13 2018 share
- bin:Hadoop操作関連のコマンドがあるディレクトリ。例えばhadoop、hdfsなど
- etc:Hadoopの設定ファイルのディレクトリ。例えばhdfs-site.xml、core-site.xmlなど
- lib:Hadoopの本地依頼
- sbin:Hadoopクラスタの起動・停止関連のスクリプトやコマンドを保存
- share:Hadoopのjar、公式の案例jar、ドキュメントなどを含み
2.2 Hadoopクラスタの設定
Hadoopクラスタの設定 = HDFSクラスタの設定 + MapReduceクラスタの設定 + Yarnクラスタの設定
- HDFSクラスタの設定
- JDKのパスをHDFSに設定する(hadoop-env.shを変更)
- NameNodeの節点及びデータの格納ディレクトリを指定する(core-site.xmlを変更)
- SecondaryNameNodeの節点を指定する(hdfs-site.xmlを変更)
- DataNodeの従節点を指定する(etc/hadoop/slavesファイルを変更し、各節点の設定情報を1行に配置)
- MapReduceクラスタの設定
- JDKのパスをMapReduceに設定する(mapred-env.shを変更)
- MapReduce計算フレームワークがYarnフレームワークを使用するように指定する(mapred-site.xmlを変更)
- Yarnクラスタの設定
- JDKのパスをYarnに設定する(yarn-env.shを変更)
- ResourceManagerの主節点が配置されている節点アドレスを指定する(yarn-site.xmlを変更)
- NodeManagerの節点を指定する(slavesファイルの内容により決定される)
HDFSクラスタの設定
cd /opt/bigdata/servers/hadoop-2.9.2/etc/hadoop/
- slaves設定
vim slaves
#従節点アドレスを書き込み
centos1
centos2
centos3
centos4

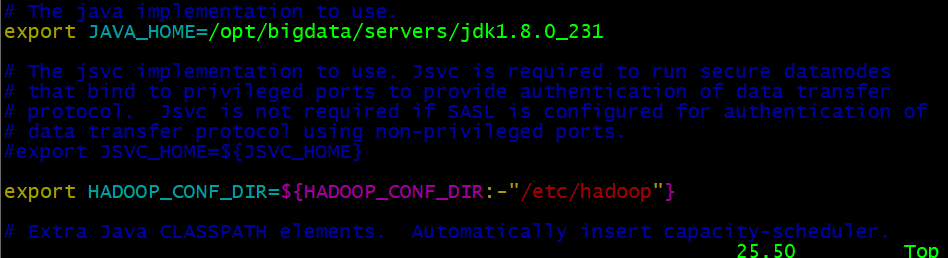
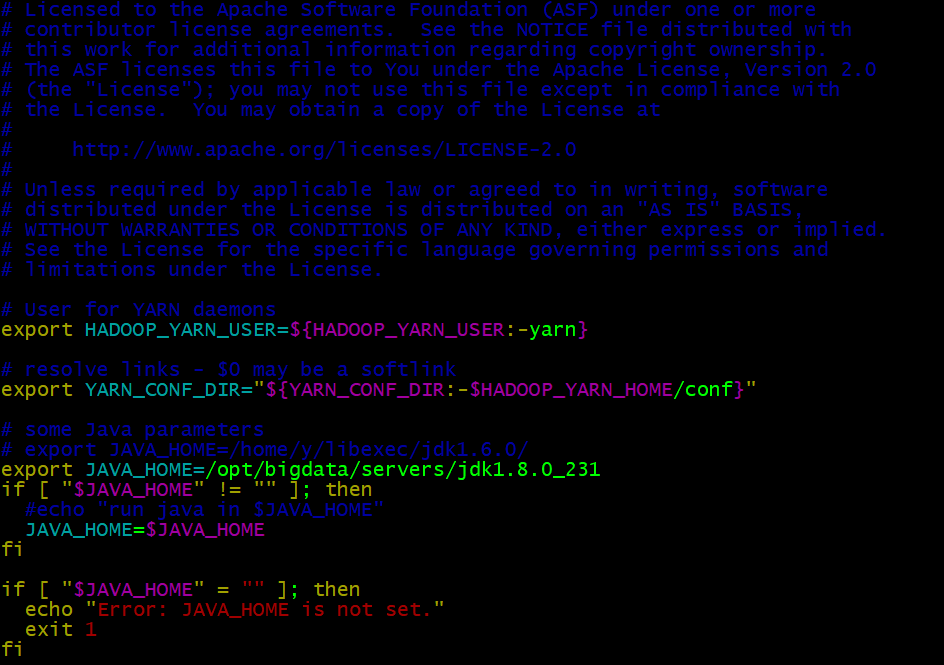
- hadoop-env.sh設定
vim hadoop-env.sh
#Javaアドレスを添加
export JAVA_HOME=/opt/bigdata/servers/jdk1.8.0_231
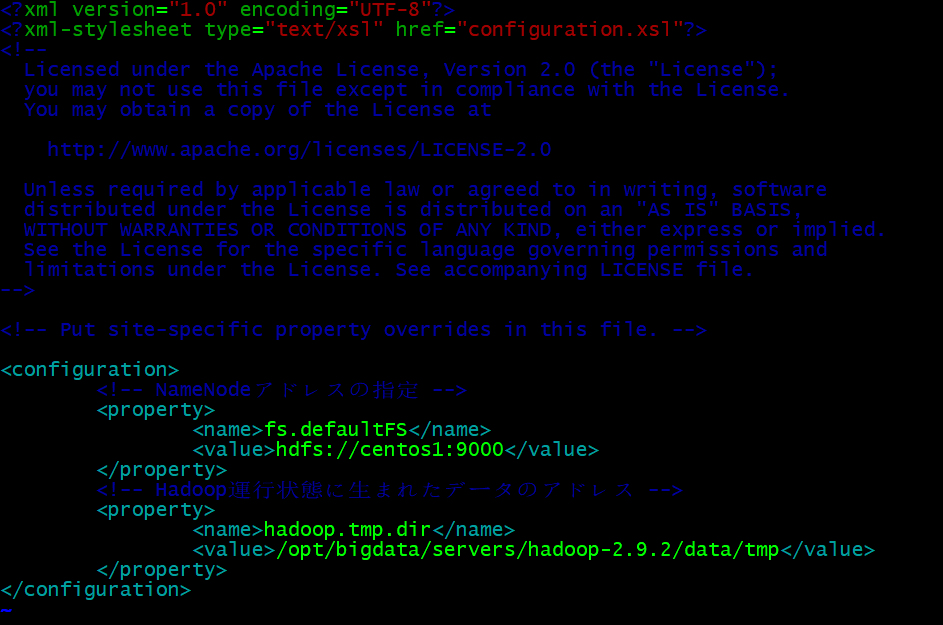
- core-site.xml設定
vim core-site.xml
#NameNode節点やデータ格納のアドレスを指定
<!-- NameNodeアドレスの指定 -->
<property>
<name>fs.defaultFS</name>
<value>hdfs://centos1:9000</value>
</property>
<!-- Hadoop運行状態に生まれたデータのアドレス -->
<property>
<name>hadoop.tmp.dir</name>
<value>/opt/bigdata/servers/hadoop-2.9.2/data/tmp</value>
</property>
core-site.xml資料:https://hadoop.apache.org/docs/r2.9.2/hadoop-project-dist/hadoop-common/core-default.xml
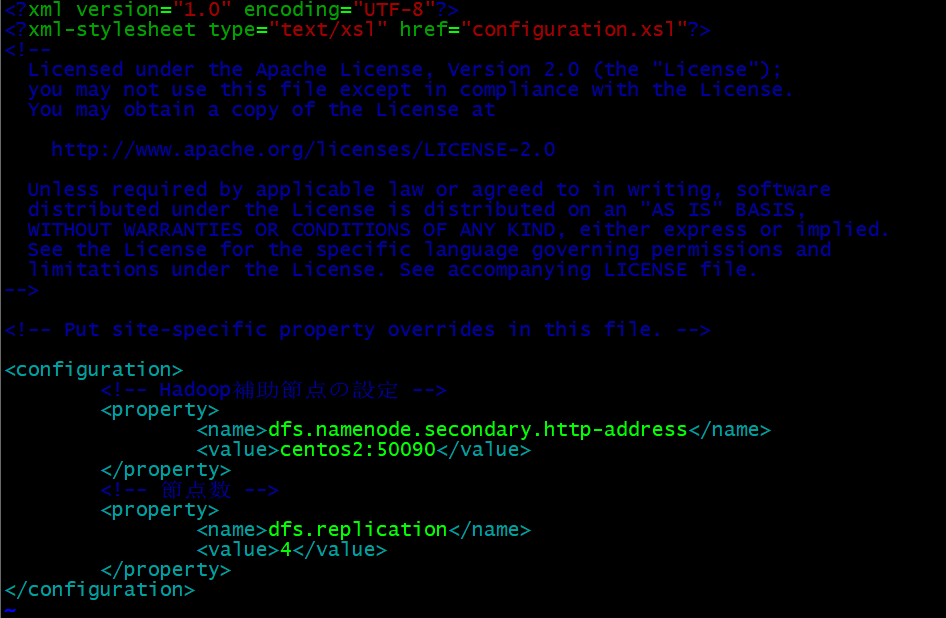
- hdfs-site.xml設定
vim hdfs-site.xml
#secondarynamenodeの指定
<!-- Hadoop補助節点の設定 -->
<property>
<name>dfs.namenode.secondary.http-address</name>
<value>centos2:50090</value>
</property>
<!-- 節点数 -->
<property>
<name>dfs.replication</name>
<value>4</value>
</property>
hdfs-site.xml資料:https://hadoop.apache.org/docs/r2.9.2/hadoop-project-dist/hadoop-hdfs/hdfs-default.xml
MapReduceクラスタの設定
vim mapred-env.sh
#Javaアドレスを添加
export JAVA_HOME=/opt/bigdata/servers/jdk1.8.0_231

- mapred-site.xml設定
#ファイル名を変更
mv mapred-site.xml.template mapred-site.xml
vim mapred-site.xml
#MapReduce計算フレームワークがYarn上に運行を指定
<!-- MRがYarn上に運行の指定 -->
<property>
<name>mapreduce.framework.name</name>
<value>yarn</value>
</property>

mapred-site.xml資料:https://hadoop.apache.org/docs/r2.9.2/hadoop-mapreduce-client/hadoop-mapreduce-client-core/mapred-default.xml
Yarnクラスタの設定
- yarn-env.sh設定
vim yarn-env.sh
#Javaアドレスを添加
export JAVA_HOME=/opt/bigdata/servers/jdk1.8.0_231
- yarn-site.xml設定
vim yarn-site.xml
#ResourceMnagerの節点を指定
<!-- YARNのResourceManager節点の指定 -->
<property>
<name>yarn.resourcemanager.hostname</name>
<value>centos2</value>
</property>
<!-- Reducerデータを取得の方式 -->
<property>
<name>yarn.nodemanager.aux-services</name>
<value>mapreduce_shuffle</value>
</property>
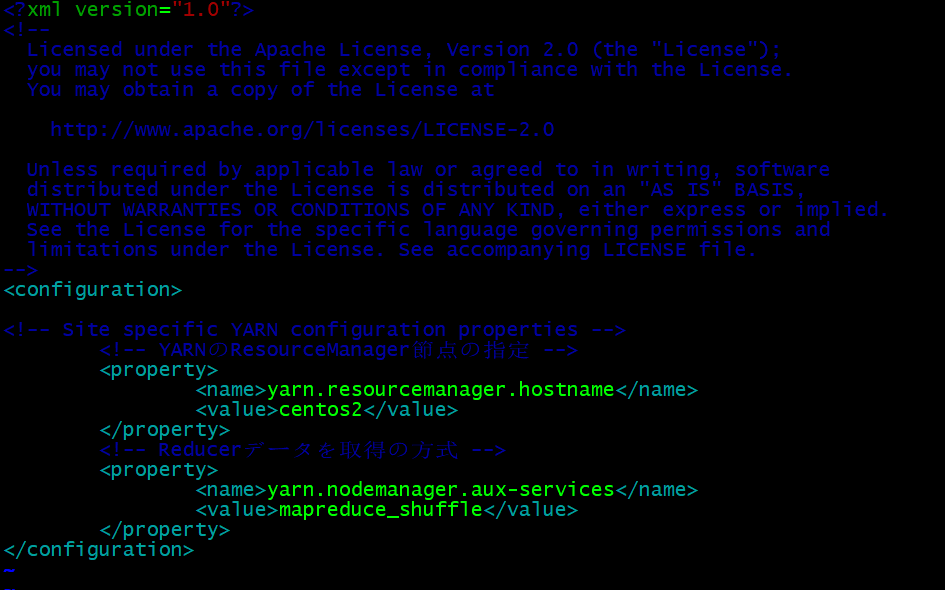
yarn-site.xml資料:https://hadoop.apache.org/docs/r2.9.2/hadoop-project-dist/hadoop-hdfs/hdfs-default.xml
Hadoopのインストールディレクトリの所有者と所有者グループの情報はデフォルトで501 dialoutです。Hadoopクラスタを操作するユーザーは仮想マシンのrootユーザーを使用しています。そのため、情報が混乱するのを避けるために、Hadoopのインストールディレクトリの所有者と所有者グループを一致させるように変更します。

chown -R root:root /opt/bigdata/servers/hadoop-2.9.2

Hadoopの分配
Hadoop全体のファイルを他の3つのサーバに発送します。
cd /opt/bigdata/servers/
scp -r hadoop-2.9.2/ centos2:$PWD
scp -r hadoop-2.9.2/ centos3:$PWD
scp -r hadoop-2.9.2/ centos4:$PWD


第3節 Hadoopクラスタの起動
クラスタの起動方式は、単一節点起動やクラスタ起動の2種類に分けます。単一節点起動とは、サーバごとにHadoopサービスを一つ一つ起動する方法で、節点の回復や追加など使用されます。クラスタ起動は、全ての節点が一斉に起動、停止する場合に使用されます。
3.1 単節点起動
HDFS単節点起動
- NameNodeの初期化
特別注意:クラスタを初めて起動する場合は、NameNode節点で初期化する必要があります。初めてではない、又はNameNode以外では、NameNodeの初期化を実行してはいけません!!!
hadoop namenode -format
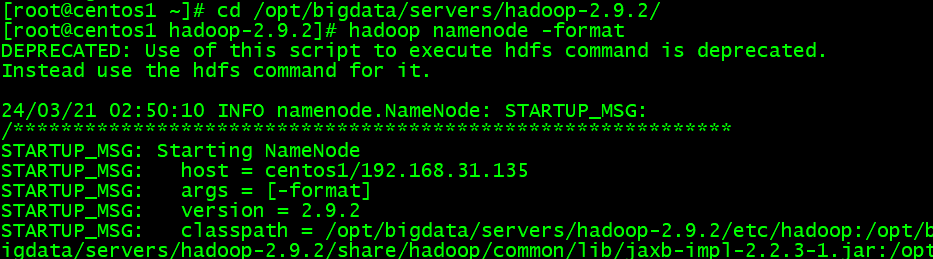
Storage directory ~/name has been successfully formatted.その様なメッセージが表れたら、Hadoopの初期化が成功になると言えます。二度と初期化操作が行けません。
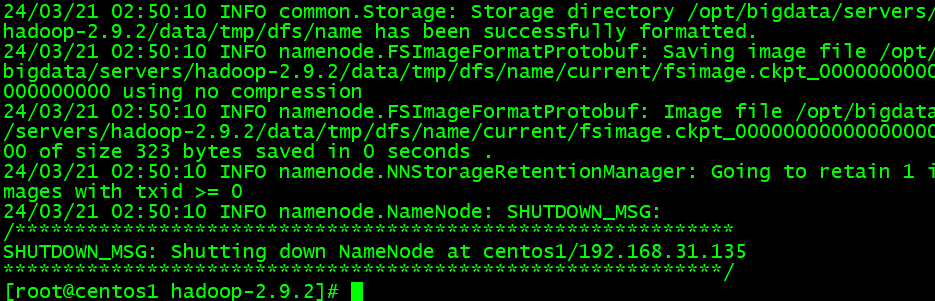
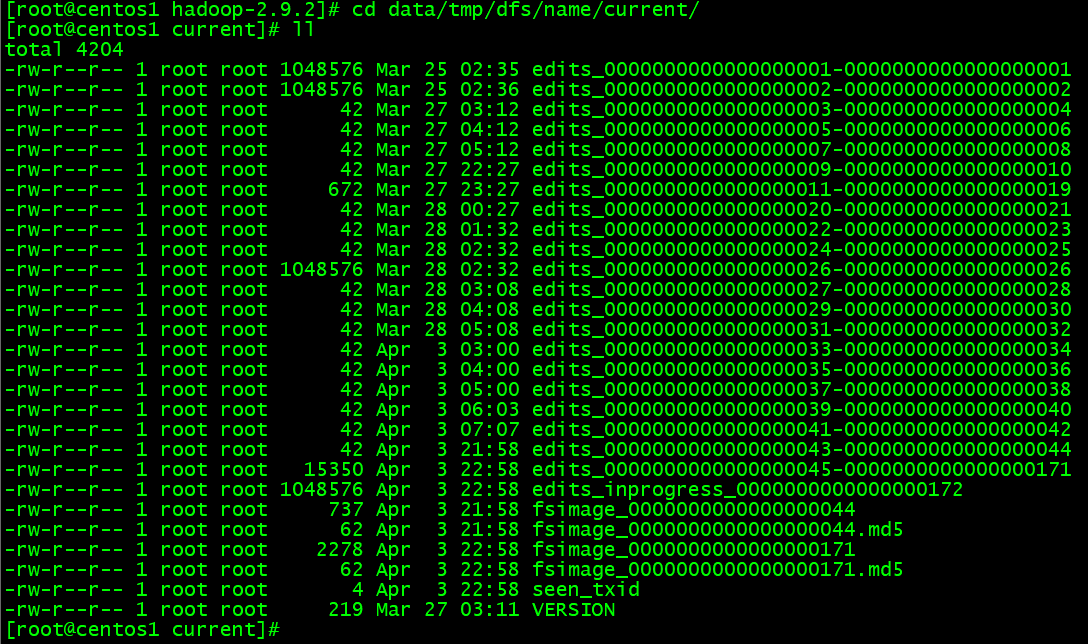
Hadoopの初期化につれて/opt/bigdata/servers/hadoop-2.9.2/data/tmp/dfs/name/current下のファイルが生成されます。データにの改修記録が全てここに格納されます。もし二度と初期化されたら、メタデータが損壊された、Hadoopサービスが起動できません。

- HDFSのNameNode起動
cd /opt/bigdata/servers/hadoop-2.9.2/sbin/
hadoop-daemon.sh start namenode
#HDFSのプロセスを検査
jps

- 全ての節点がDateNode起動
hadoop-daemon.sh start datanode


プロセスを検査してHDFSの起動を確認でき、又はWebにHDFS画面に登録すると詳しい情報を見えます。
http://192.168.31.135:50070/dfshealth.html#tab-overview
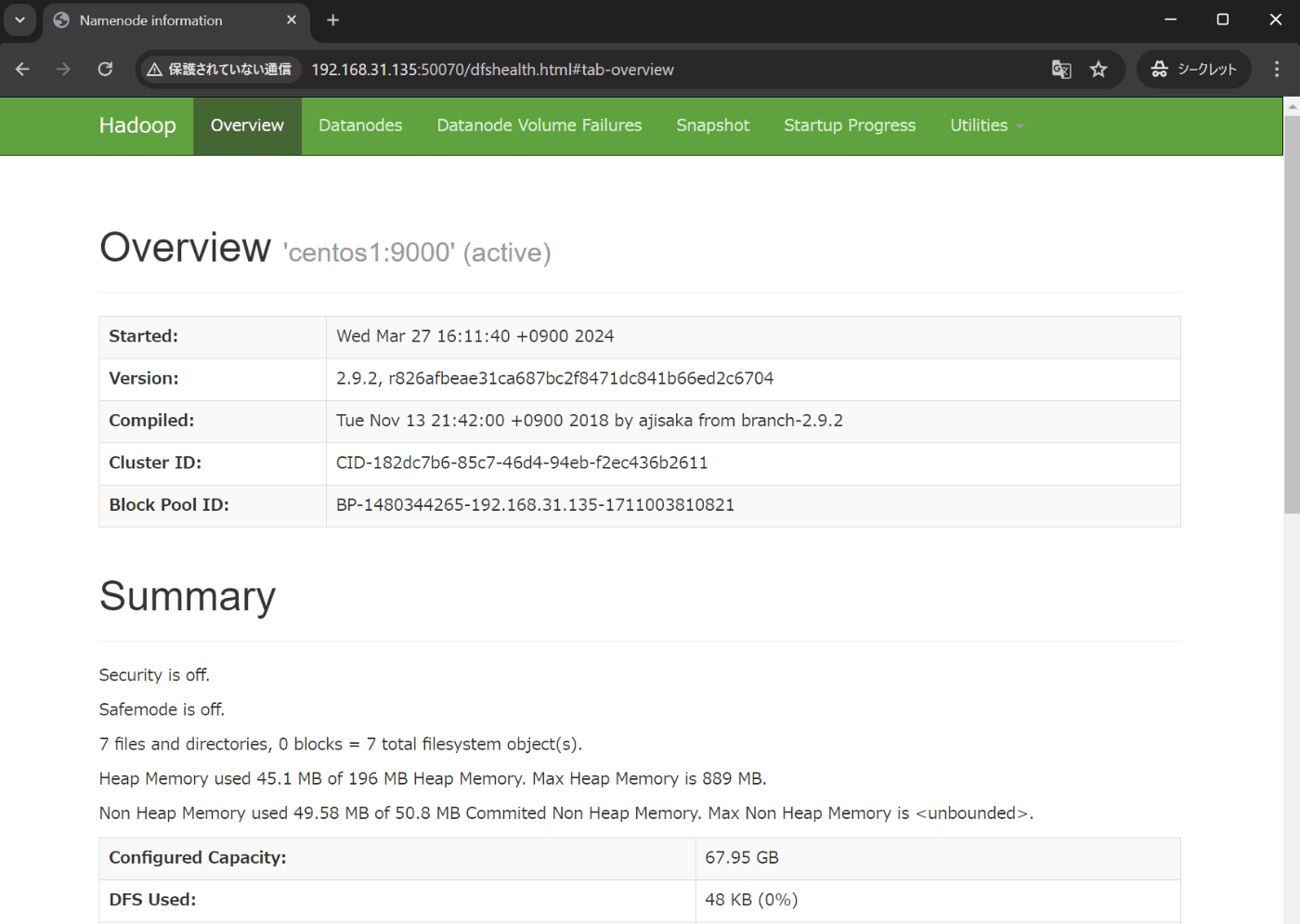
live Nodesをリンクして各節点の状態を表せます。全ての節点が順調に運行しているなら、ここまでHadoopのHDFS部分の設定や起動が完了しました。
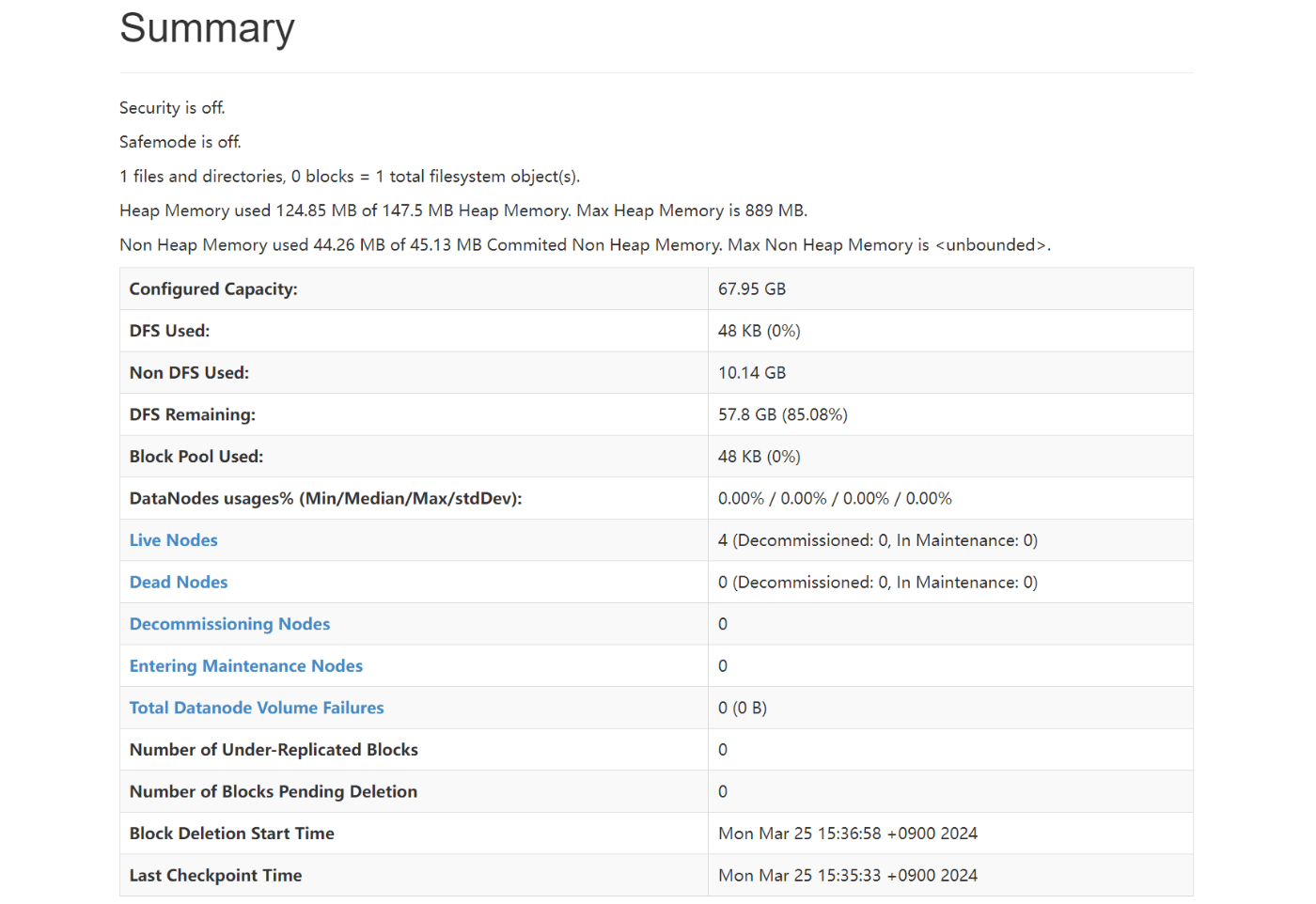
http://192.168.31.135:50070/dfshealth.html#tab-datanode
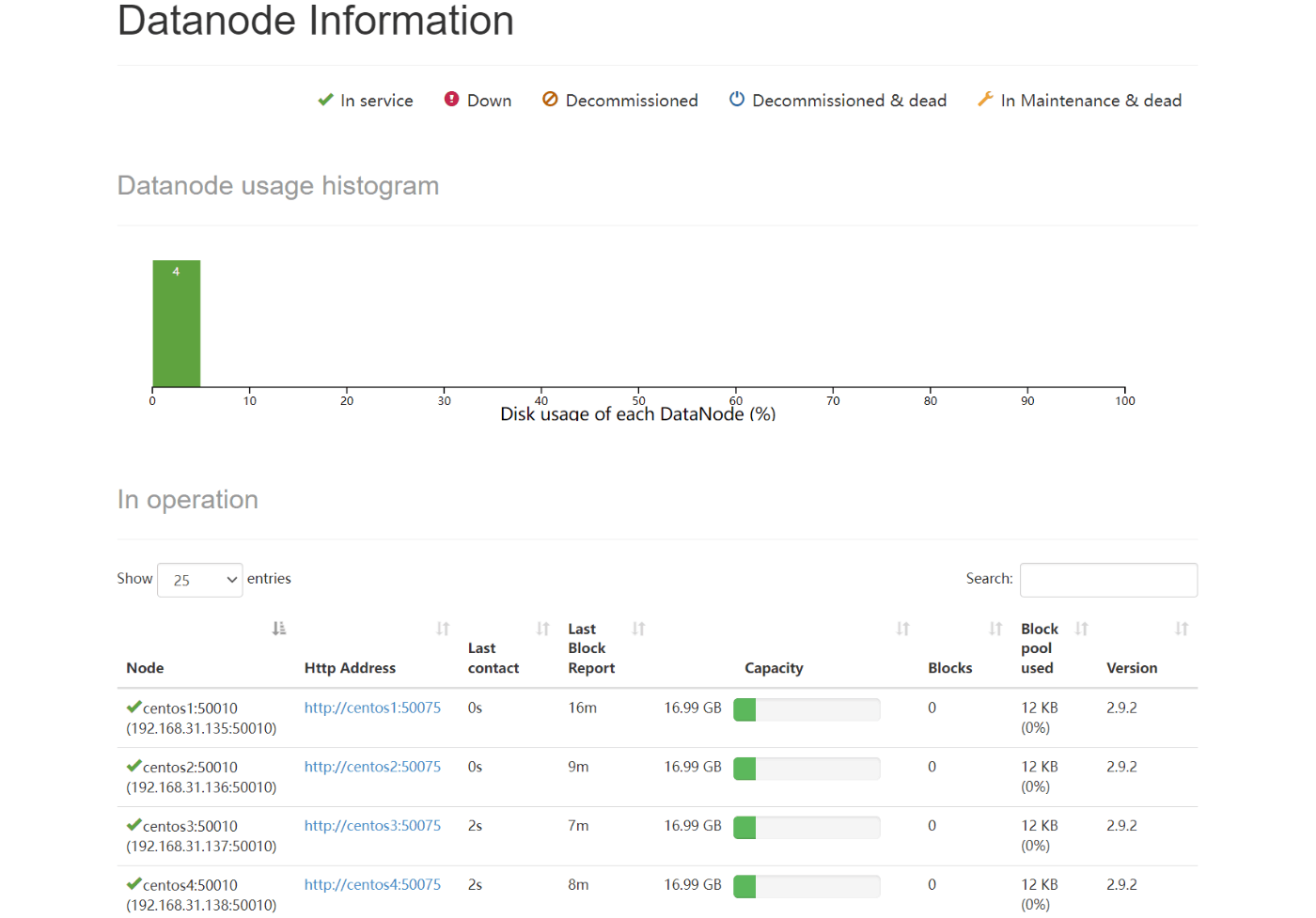
YARN単節点起動
- centos2でresourcemanagerを起動

- 全ての節点が以下のコマンドを実行
yarn-daemon.sh start nodemanager


- 節点の停止
hadoop-daemon.sh stop namenode
hadoop-daemon.sh stop datanode
yarn-daemon.sh stop resourcemanager
yarn-daemon.sh stop nodemanager
3.2 クラスタ起動
HDFSクラスタ起動
若し単節点起動の流れに初期化の操作を行わないなら、ここHDFSを初期化させるのが必要です。二度と初期化を実行が行けない、この点が注意します。
hadoop namenode -format
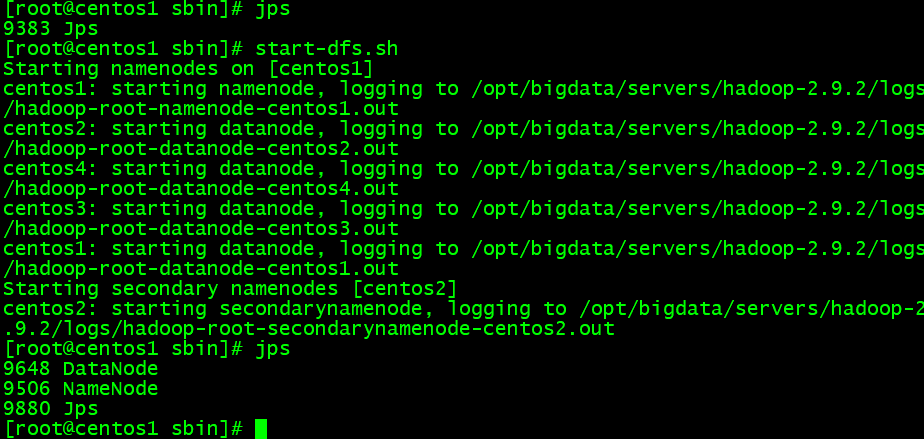
- Hdfs起動
cd /opt/bigdata/servers/hadoop-2.9.2/sbin
start-dfs.sh
#Hdfs停止
stop-dfs.sh
YARNクラスタ起動
- centos2節点にYarn起動
start-yarn.sh
#Yarn停止
stop-yarn.sh
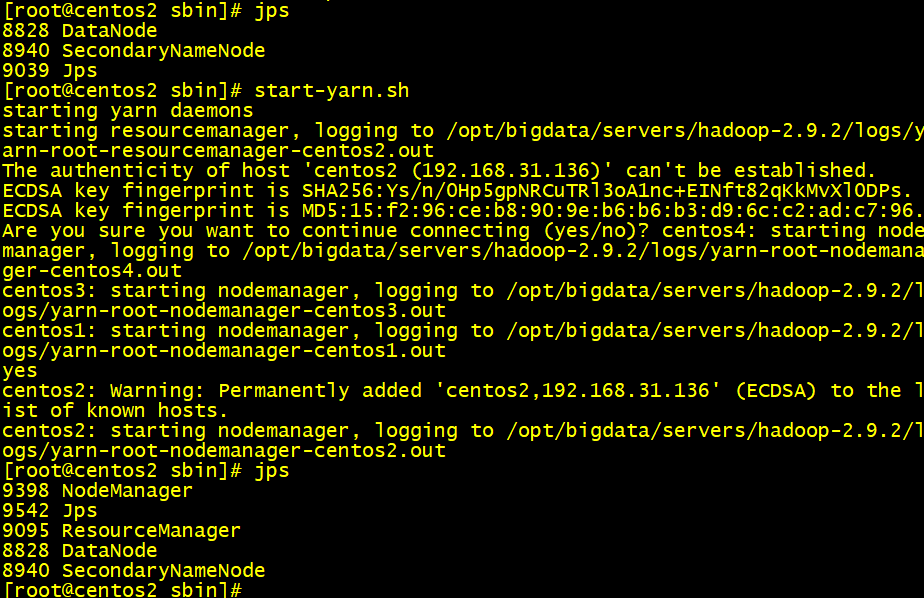
コマンド纏め
- 別々にHDFS起動/停止
hadoop-daemon.sh start / stop namenode / datanode / secondarynamenode
- YARN起動/停止
yarn-daemon.sh start / stop resourcemanager / nodemanager
- クラスタHDFS起動/停止
start-dfs.sh / stop-dfs.sh
- クラスタYARN起動/停止
start-yarn.sh / stop-yarn.sh
第4節 歴史サーバを配置
計算任務のログを検査できません。本節は歴史ログサーバを設定すると歴史ログを検査できるを紹介します。
4.1 歴史記録サーバの設定
- mapred-site.xml設定
cd /opt/bigdata/servers/hadoop-2.9.2/etc/hadoop/
vim mapred-site.xml
#以下の内容を追加
<!-- 歴史サーバのアドレス -->
<property>
<name>mapreduce.jobhistory.address</name>
<value>centos1:10020</value>
</property>
<!-- 歴史サーバのwebアドレス -->
<property>
<name>mapreduce.jobhistory.webapp.address</name>
<value>centos1:19888</value>
</property>
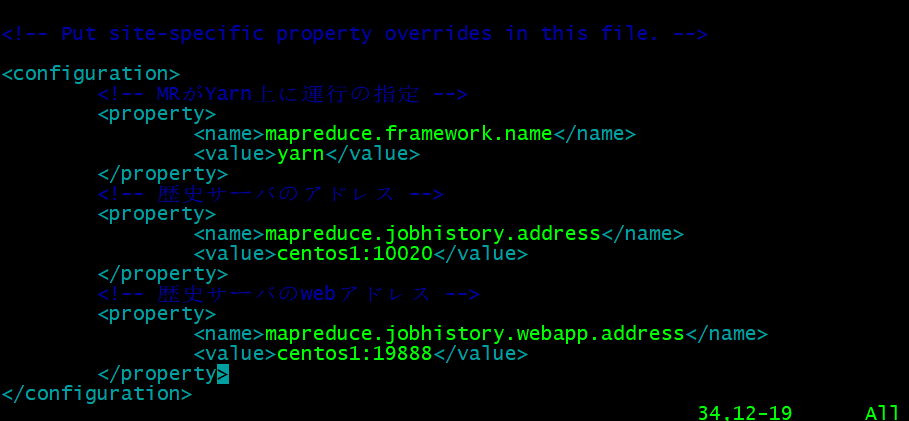
- 他の節点に分配し、自動的に上書き
scp mapred-site.xml centos2:$PWD

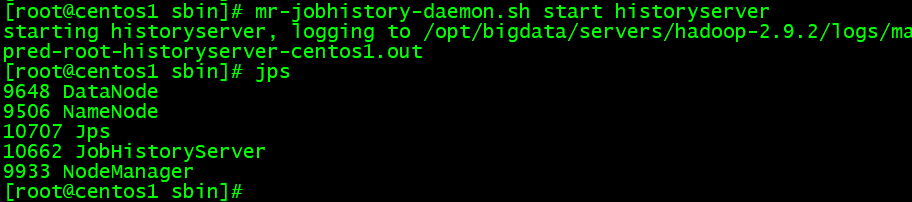
- 歴史ログサーバの起動
cd /opt/bigdata/servers/hadoop-2.9.2/sbin
mr-jobhistory-daemon.sh start historyserver
- JobHistoryのWebアドレス
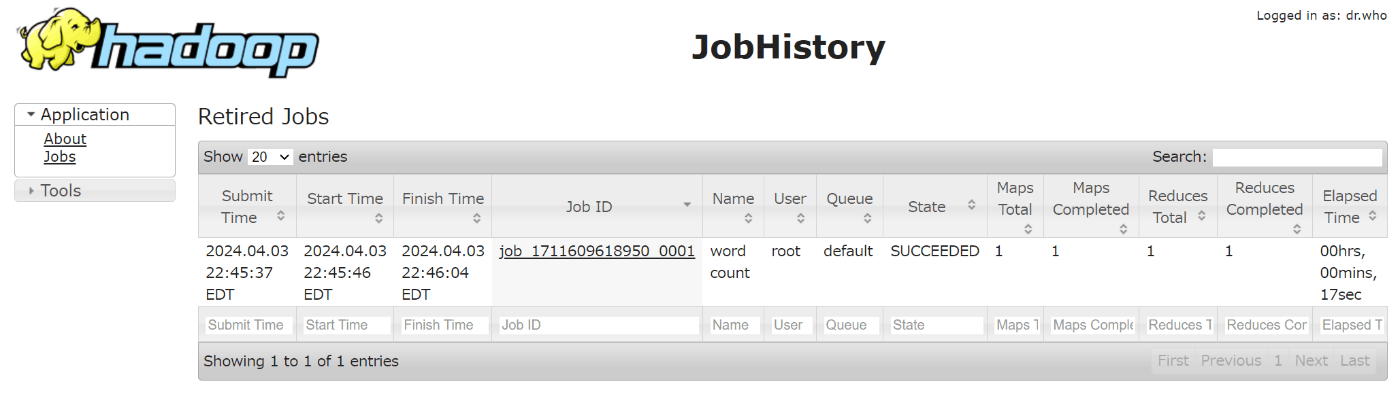
http://192.168.31.135:19888/jobhistory
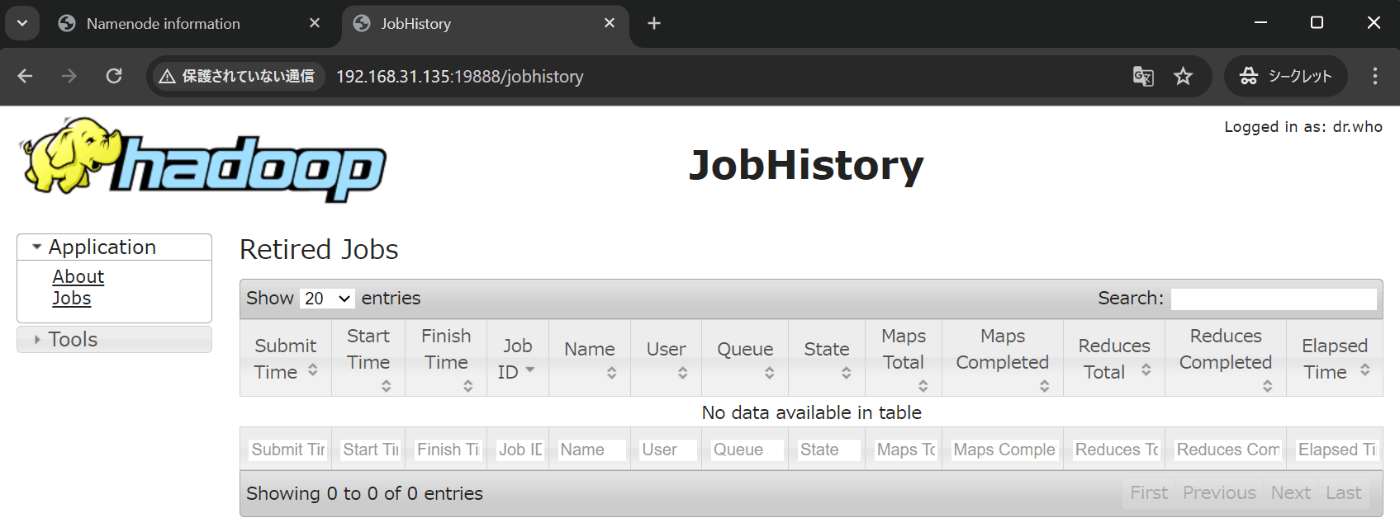
今まで何も計算を実行しないので、歴史記録がありません。
4.2 ログの合併
MapReduceには一つ完全の任務を複数の小任務に分割される方式で実行します。そのために処理記録が各節点に散らばります。ログ合併の設定は一つの入口を通じて完全のログ記録が検査できます。
- yarn-site.xml設定
cd /opt/bigdata/servers/hadoop-2.9.2/etc/hadoop/
vim yarn-site.xml
#以下の内容を追加
<!-- ログの重合機能 -->
<property>
<name>yarn.log-aggregation-enable</name>
<value>true</value>
</property>
<!-- 7日間の保留 -->
<property>
<name>yarn.log-aggregation.retain-seconds</name>
<value>604800</value>
</property>
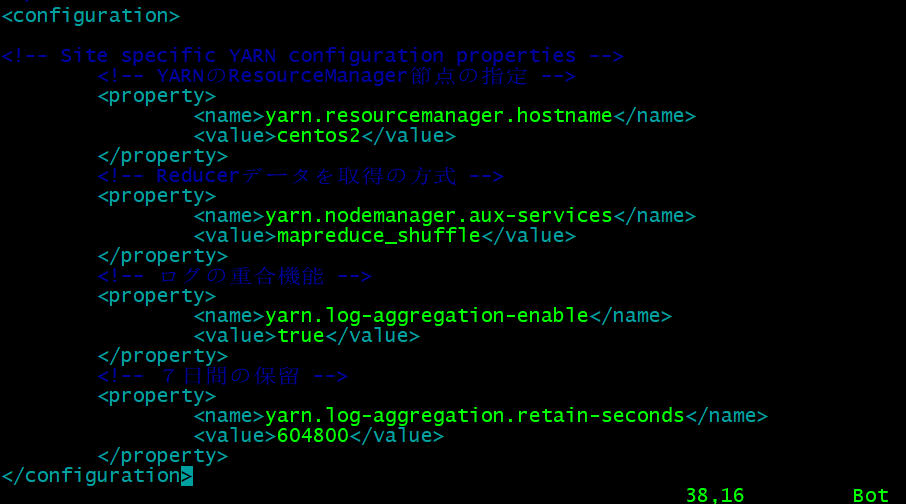
- 各節点に分配
scp yarn-site.xml centos2:$PWD

- 全てのサービスを再起動
stop-dfs.sh
stop-yarn.sh
mr-jobhistory-daemon.sh stop historyserver
start-dfs.sh
start-yarn.sh
mr-jobhistory-daemon.sh start historyserver
第5節 クラスタのテスト
公式が提供した案例を実行してHadoopの運動状況を確認します。
- 臨時のテストファイルを作成
cd /root/
vim wordCountTest.txt
#以下の内容を書き込み
hadoop mapreduce yarn
hdfs hadoop mapreduce
mapreduce yarn nodemanager
NameNode nodemanager
ResourceManager
ResourceManager
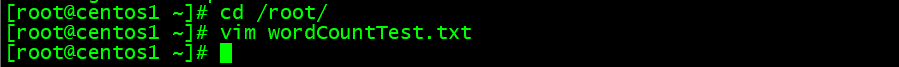
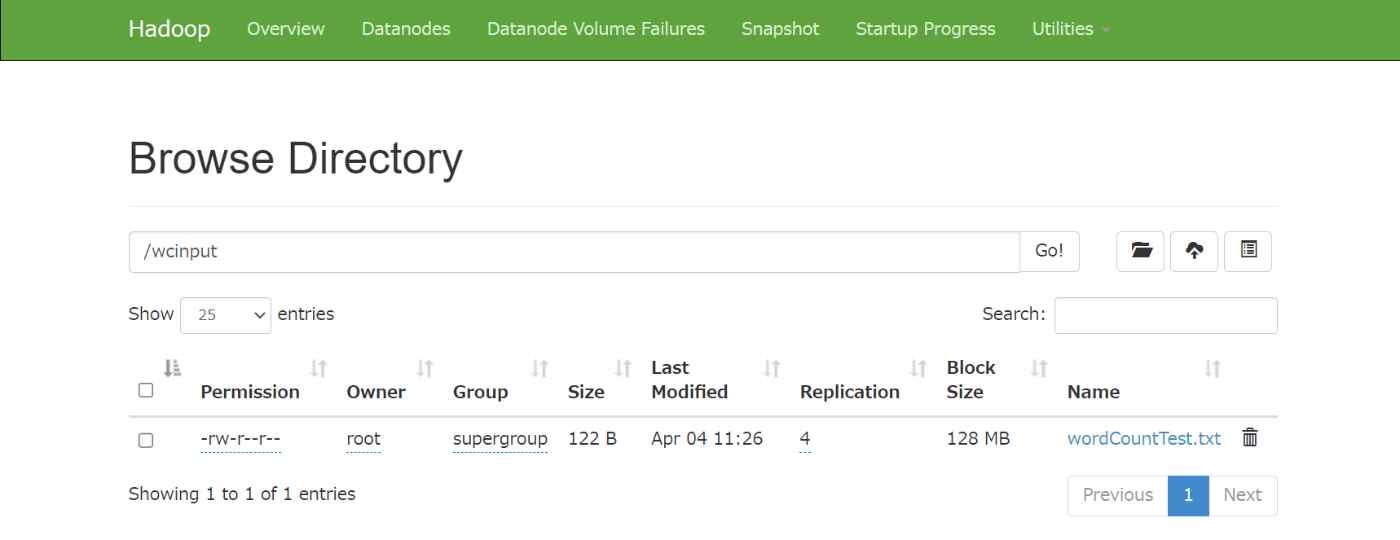
- HDFS上にwcinputディレクトリを作成
hdfs dfs -mkdir /wcinput
- wordCountTestファイルをwcinputにアップロード
hdfs dfs -put wordCountTest.txt /wcinput

ブラウザでHDFS全てのディレクトリ結構を検査できます。

- プログラムを実行
cd /opt/bigdata/servers/hadoop-2.9.2/
hadoop jar share/hadoop/mapreduce/hadoop-mapreduce-examples-2.9.2.jar wordcount /wcinput /wcoutput

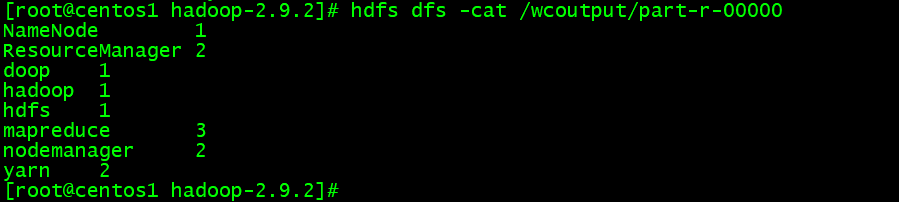
- 出力結果を検査
hdfs dfs -cat /wcoutput/part-r-00000

- ログの検査
http://192.168.31.135:19888/jobhistory
- メタデータの変更情報を記録された
cd data/tmp/dfs/name/current/
纏め
本章は、Hadoopの分散システムを組み立て流れや基本の操作を紹介しました。
- Hadoopの分散システムの配置内容
- Hadoopの起動方式、一度の初期化限りを要する
- ログ検査やログの合併を実現する
- wordCount案例の展示
次の章では、Hadoopの三大構成要素の一つ、最も核心であるHDFS(Hadoop Distributed File System)を紹介します。
Discussion