はじめに
本記事の内容はGitHub Actions Meetup Tokyo #4で自分が発表した内容を元に、スライドには書ききれなかった内容などを追加したものです。
また、当日の勉強会のアーカイブ動画や、他の発表者の方のスライドなどは以下のリンクからご覧いただけます。今回のGitHub Actions Meetup Tokyo #4は発表者全員がGitHub Actionsセルフホストランナーの基盤運用を担当されている方であり、実質的にセルフホストランナー回と呼べる内容でした。この分野に興味がある方はぜひ他の方の発表も見て頂けると嬉しいです。
CybozuのGitHub Actionsセルフホストランナーの近況
基本機能の安定化と運用の課題
CybozuのGitHub Actionsセルフホストランナーは2021/08[1]頃からすでに運用が開始されており、過去にも何度かその運用状況について発表してきました。最後に外部発表したのは約1年前のCI/CD Test Night #6での @miyajan の発表でした。
この時点でセルフホストランナーのインフラ基盤として機能はほぼ完成されており、日常的な利用において大きな問題は発生していませんでした。しかし、運用面では主に規模の問題からなる課題がいくつか発生しており、この1年はそれらを対策していました。
この1年間に主に解決した課題は以下です。
- actions/setup-javaで使用するAmazon Correttoのキャッシュ
- Terraform作業の効率化
- AWSのAPIリミット対策
- AWSの費用対策
既に発表した内容についてはリンクを付けてあります。それ以外については今後機会があれば発表していきたいと思います。
今回の記事は、最後の AWSの費用対策 について紹介したいと思います。
AWS費用の移り変わり
費用の推移と内訳
この1年の間にセルフホストランナーの利用チームの増加、また既に導入しているチームのGitHub Actions利用拡大に伴いAWSの費用が増加してきました。特に、昨年11月から今年3月にかけてAWSの費用が急激に増加しました。
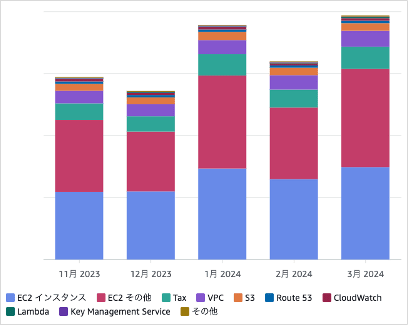
AWS費用の内訳を詳しく分析すると、EC2インスタンス と EC2その他 という項目が全体の約2/3を占めていることがわかります。EC2インスタンスはGitHub Actionsのジョブ数に応じてオートスケールするため、その利用が増えるにつれて費用も増加します。EC2その他については内訳を調べたところ、ほぼNAT Gatewayからインターネットに出る通信に対して発生する費用であることが分かりました。従って、こちらもGitHub Actionsの利用拡大に伴って増加していきます。
どちらも社内でセルフホストランナーの利用が拡大するにつれて増加するものですので、増加傾向自体はやむを得ません。しかし、増加のペースが思ったよりも急激だったためこのタイミングで費用対策についても考えることにしました。今回は2つの支配的な要因のうち、EC2インスタンスに関して費用削減の取り組みを行いました。
philips-labs/terraform-aws-github-runner によるセルフホストランナーの構築
CybozuではOSSのTerraform moduleであるphilips-labs/terraform-aws-github-runnerを利用してセルフホストランナーの基盤を構築しています。philips-labs/terraform-aws-github-runner はLambda関数とEC2インスタンスを組み合わせて、GitHub Actionsのジョブ数に応じてセルフホストランナーがオートスケールする仕組みを提供します。基本的には、GitHub Actionsでジョブがトリガーされたときのwebhookに応じてLambda関数からジョブの数と同数のEC2インスタンスを起動する仕組みです。
このアーキテクチャはとてもシンプルにランナーのオートスケールを実現しますが、いくつかの課題も存在します。特にジョブごとに新しいEC2インスタンスを起動するため、ランナーのすべての準備が整いジョブの処理を開始するまでの待ち時間が発生します。GitHub Actionsのユーザーからはジョブが開始されるまで毎回1-2分程度は待たされるように見えてしまいます。
ランナープールによる待機時間の削減
セルフホストランナーの基盤を提供する有名ないくつかのOSS[2]では昔からこの課題の解決方法を提供していました。philips-labs/terraform-aws-github-runner においてもランナープールと呼ばれる仕組みを提供しています。
ランナープールの仕組みとしては、webhookが来るよりも前に一定数のランナーをあらかじめ起動して常に待機状態としておくことで、ジョブがトリガーされた際、即座に処理を開始できるようにしておくものです。ユーザーからはジョブが即座に開始されるため、 github.com での通常のランナーのような待ち時間のストレスが無い体験を得られます。
待機状態のランナーの数が減ると、webhookやEventBridge SchedulerにトリガーされるLambda関数からEC2を起動して自動的に補充します。イメージとしてはk8sのreconcileでpod数を一定に保つ挙動と近いです。これにより常に一定数のランナーが待機している状態を維持できます。
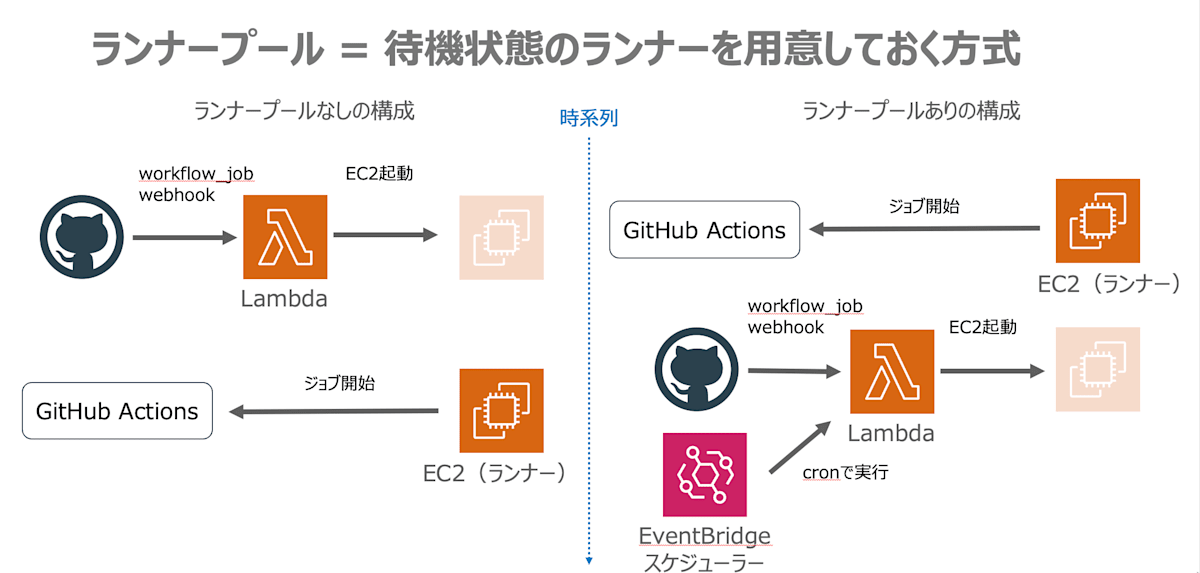
サイボウズでのランナープール運用
philips-labs/terraform-aws-github-runner 特有の事情として、Enterprise全体で共有できるランナーは作成できず、リポジトリもしくはOrganization(以後Orgと表記)単位のセルフホストランナーしか作れないという制約があります。
自分たちの運用では各Orgごとプールさせるランナーの数を調整しており、ほとんどのOrgでは基本スペックのランナーを3台プールしています。一方、開発がアクティブで大規模なOrgでは最大60台ものランナーをプールさせています。また、E2Eテストを頻繁に実行するOrgでは基本スペックのランナーとは別に、CPUとメモリが増強されている高スペックのランナーもプールに含めています。このように各Orgのニーズに応じた台数をプールすることで、ジョブの待ち時間をなるべく減らすようにしています。
無駄なプールサイズの削減
夜間・休日のスケールイン漏れの修正
先に説明したようにランナープールはジョブが開始されるよりも前にEC2インスタンスを稼働させているため、ジョブがトリガーされるかどうかに関わらずEC2の料金が発生し続けています。従って、GitHub Actions自体の利用率が下がる夜間や休日はプールサイズを縮小しておくことでEC2の料金を節約可能です。
philips-labs/terraform-aws-github-runner では pool_config と idle_config の設定を併用[3]することで特定の時間だけプール台数の調節が可能です。Cybozuではこれを利用して日中と夜間・休日の設定を切り替えることで、夜間・休日にはランナープールを1台だけとするようにスケールインの設定をしていました。
このスケールインの仕組みは今まで問題なく動いていたと思われていたのですが、実は主にE2Eテスト用で利用されている高スペックのランナーについては夜間・休日のスケールインが動いておらず、日中のプールサイズが維持されてしまっていました。とある開発チームから高スペックのランナーを10台にまで増やして欲しいと依頼があり、その設定後に日毎のEC2の費用を調べた際に休日の料金がやけに値上がりしていることから判明しました😇。
原因は高スペックランナー用のTerraformの設定ファイル上で pool_config と idle_config の時間帯指定のcron設定が足りていないことでした。Terraformのコード上では基本スペックのランナーと高スペックランナーは別々に管理されていたため、基本スペックのランナーには夜間・休日にプールを1台に減らすcron設定が追加されていた一方、高スペックランナーにはその設定が漏れていました。このミスを修正し、高スペックランナーも夜間・休日にスケールインが動くようになったことでEC2の費用が若干削減されました。
開発が非アクティブなOrgのプール数の削減
さらに、あまりランナーが利用されていない非アクティブなOrgに対してプールサイズの見直しを行いました。非アクティブなOrgについて調べてみたところ、個人用途と思われるOrgと、チーム開発で利用されているが開発人数の規模は小さいOrgの2種類が存在していました。どちらもAWSの料金事情を説明してプール台数を削減させてもらうことで、無駄に待機させてしまっていたランナー分の料金を節約しました。
これらの無駄なランナープールの削減は、その1つ1つの金額は大したものでないものの、セルフホストランナーを提供しているOrgの数が現段階で 40弱 ほど存在するため、全体としてはそれなりにまとまった金額の節約を実現できました。
スポットインスタンスの費用削減
Cybozuでのスポットインスタンスの利用
Cybozuのセルフホストランナーは運用初期からランナーとして起動するためのEC2はすべてスポットインスタンスを利用しています。スポットインスタンスは圧倒的に安い代わりに起動中のEC2は中断される可能性があり、もしもGitHub Acitonsのジョブを実行中にそのEC2が中断されてしまった場合、当然ジョブは失敗となってしまいます。社内のセルフホストランナーのユーザーからすると不便な挙動ですが、料金との兼ね合いから現状では許容してもらっています。
しかし、セルフホストランナーの利用が拡大するに従って、ジョブが謎に失敗する現象が増えたという声が多くなってきたため、2023/07頃にインスタンスタイプのバリエーションを増やす対策をしました。それまではスポットプールに m5, m6i のインスタンスタイプしか含めていませんでしたが、ここに m5d, m5n, m6in, m6id といったm5とm6iのバリエーションを追加しました。
同時に、スポットプールからどのインスタンスタイプを起動するかという戦略をAWS推奨の price-capacity-optimized に変更しました。philips-labs/terraform-aws-github-runner のデフォルトは lowest-price であるため、今までは料金的には安い代わりに中断される可能性も高いインスタンスが選ばれてしまうことが多かったと思われます。price-capacity-optimized はスポット価格が安く、かつ在庫が余っていて中断されにくいインスタンスタイプが選択されるので価格と中断率のバランスが取れているようです。それぞれの違いについて詳しくはAWSのドキュメントを参照してください。
スポットインスタンスの種類と価格の変動
スポットインスタンスの価格は需要と供給によって変動しており、価格の遷移はAWSのコンソール上でも確認できます。先述したように m5, m5n, m5d など様々なインスタンスタイプが起動されるように変更したため、料金にどのような影響をもたらしているのかを調べてみました。スポット価格の遷移はAWSコンソールから見ることが可能です。
その結果、 基本のm5に対して m5n, m5dといったバリエーションはオンデマンド価格同様にスポット価格も順当に高くなる傾向にありました。実はm5nやm5dといったバリエーションの付加価値はセルフホストランナーとしてはメリットがない[4]ため、m5の代わりにこれらが起動されると単純に割高となってしまいます。
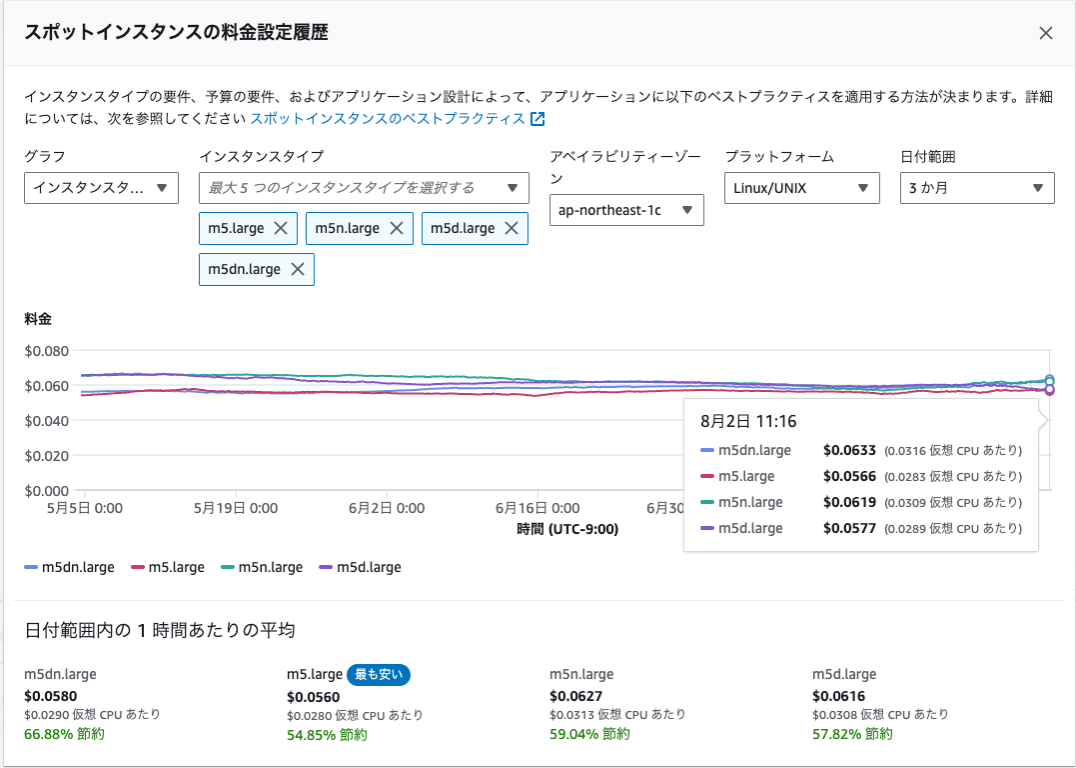
(8/2時点では m5 < m5d < m5n < m5dn 順で順当な価格となっていた)
割高であることは分かりつつも、スポット中断率を下げるためにm5nやm5dといったバリエーションを追加することはやむを得なかったため、2023/07 - 2024/03までの間はこのスポットプールの戦略で運用していました。
m7世代とAMD系CPUの追加
m5nやm5dといったバリエーションのコスパはあまりよくないことが分かったため、最新世代のm7iをm5nやm5dの代わりとしてスポットプールに追加してみることを検討しました。最新のm7iは価格が高いであろうと今まで予想していたのですが、スポット中断率は維持しつつ、基本スペックが向上すればGitHub Actionsのジョブも短時間で終わるためメリットがあるのではと考えました。また、自分がプライベートではAMDのRyzen CPUユーザーであるため、m7iのスポット価格を調べるついでに興味半分でAMD系CPUのインスタンスも調べてみることにしました。
価格を調べてみたところ、なんとスポット価格においては最新世代のバリエーションであるm7i-flexが一番安く、m5が最も高い価格という結果でした。オンデマンド価格では m5 = m6i < m7i-flex < m7 の順に高額ですので、スポット価格は必ずしもオンデマンド価格と同じ傾向になるわけではないようです。
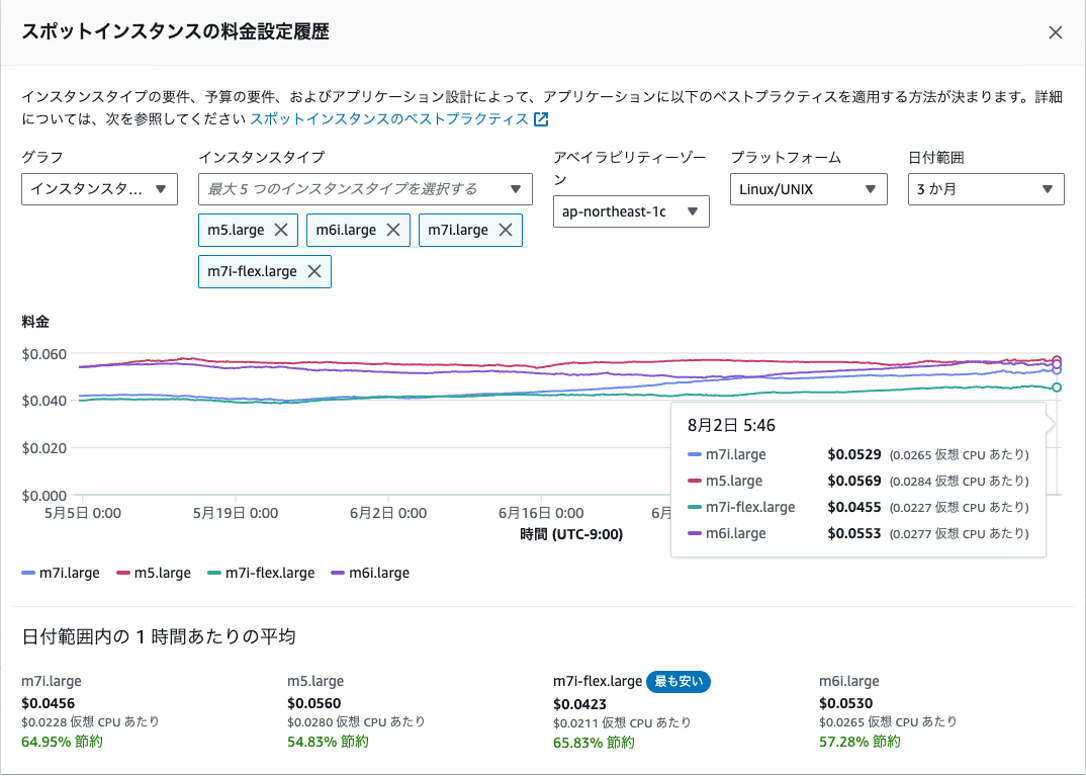
(8/2時点では最安がm7i-flex, 最高額がm5とオンデマンド価格とは逆転している)
さらにAMD系のCPU(m5a, m6a, m7a)も含めて価格を比較してみたところm6aが頭1つ飛び抜けてスポット価格が低く、コスト効率がとても良いと判明しました。
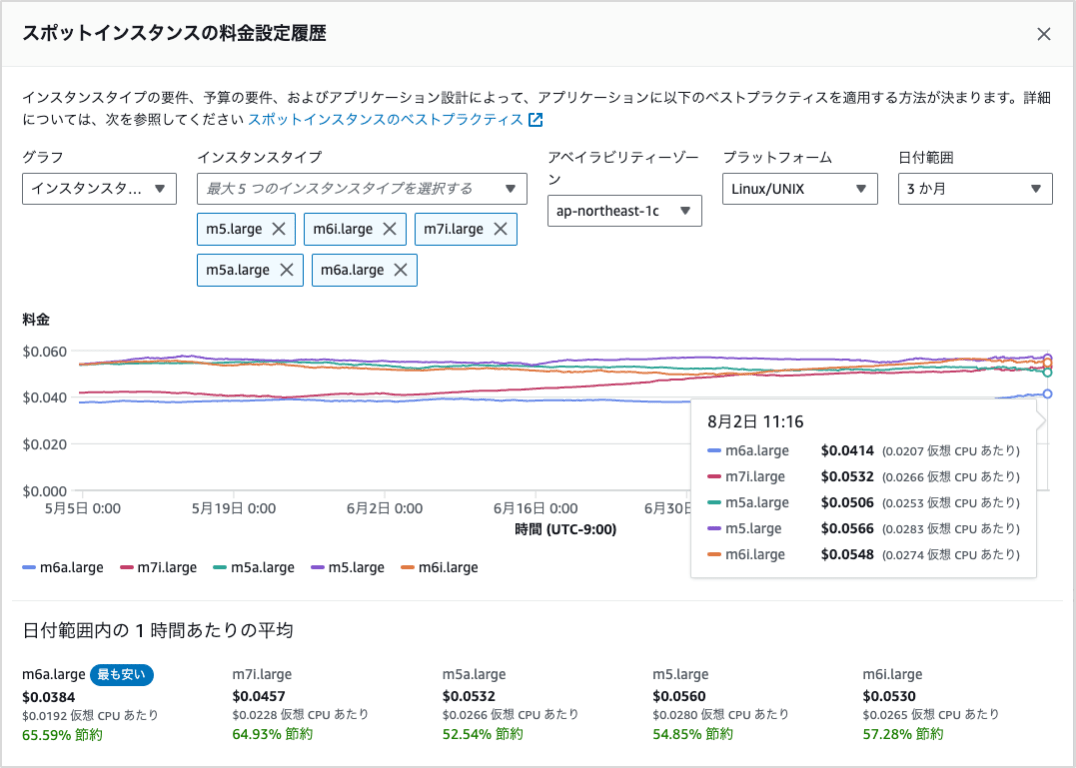
(8/2時点ではグラフの青の折れ線であるm6aが飛び抜けて安い)
この結果を受けて、まずスポットプールに最新世代のm7iを追加しました。インスタンスガチャのSSRです。Intel系ではm7i-flexが最安だったのですが、m7i-flexは性能特性が特殊でセルフホストランナーとの相性が不明だったため、今回は追加を見送りました。
続いてAMD系のCPU(m5a, m6a, m7a)も追加することにしました。AMD系のCPUはIntel系と同じx86系アーキテクチャであるためARMのGraviton系とは異なり互換性に問題はないはずですが、社内でGitHub Actionsはすでに様々な用途で利用されているため、何らかの問題が発生することを当時は懸念していました。導入してからこの記事の執筆時点でそろそろ半年になりますが、今のところ社内からはAMD系由来の問題についての報告はありません。結果的には互換性についてそれほど慎重にならなくても大丈夫そうです。
現在のスポットプール
最終的に現在のスポットプールは以下のTerraformのコードのようになっています。現在は3種類のスペックのランナーを提供しているため、EC2の large, xlarge, 2xlarge ごとにスポットプールを用意しています。
m5系とm6i系の割高なバリエーションについても引き続き含めています。これはスポットプールに存在していても price-capacity-optimized 戦略によって選ばれる可能性は低いはずであると予想しているのと、もしも選ばれたとしてもそれはスポット中断率を下げるために必要だと考えているためです。
instance_types = {
large = [
"m5.large",
"m5d.large",
"m5a.large",
"m5ad.large",
"m5n.large",
"m5dn.large",
"m5zn.large",
"m6i.large",
"m6a.large",
"m6id.large",
"m6in.large",
"m6idn.large",
"m7i.large",
"m7a.large",
]
xlarge = [
"m5.xlarge",
"m5d.xlarge",
"m5a.xlarge",
"m5ad.xlarge",
"m5n.xlarge",
"m5dn.xlarge",
"m5zn.xlarge",
"m6i.xlarge",
"m6a.xlarge",
"m6id.xlarge",
"m6in.xlarge",
"m6idn.xlarge",
"m7i.xlarge",
"m7a.xlarge",
]
"2xlarge" = [
"m5.2xlarge",
"m5d.2xlarge",
"m5a.2xlarge",
"m5ad.2xlarge",
"m5n.2xlarge",
"m5dn.2xlarge",
"m5zn.2xlarge",
"m6i.2xlarge",
"m6a.2xlarge",
"m6id.2xlarge",
"m6in.2xlarge",
"m6idn.2xlarge",
"m7i.2xlarge",
"m7a.2xlarge",
]
}
スポットプール最適化の結果
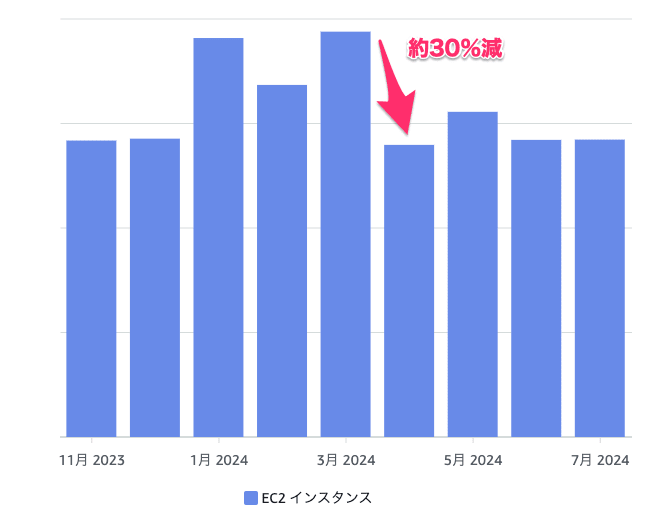
ここまで説明したスポットプールの最適化を2024/03末頃に実施したところ、翌月の4月にはEC2費用を約30%削減できました。3月 -> 4月でEC2費用が30%削減された以降、7月末現在までの費用はおおむね横ばいを維持できています。
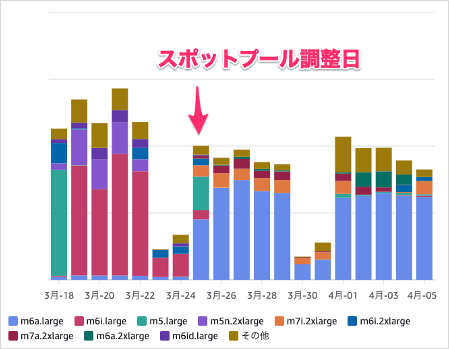
AWSのCost Explorerでインスタンスタイプごとの料金で見てみると、最適化を行った翌日から大半がm6aに切り替わりました。今まで利用されていたm5やm6iはほとんど利用されなくなった様子が分かります。
また、これは完全に予想していなかったのですがスポット中断率も劇的に改善されました。スポット中断された数を記録しているDatadogのグラフ上で見ると、最適化を行った翌日から中断数が劇的に減少している様子が分かるかと思います。
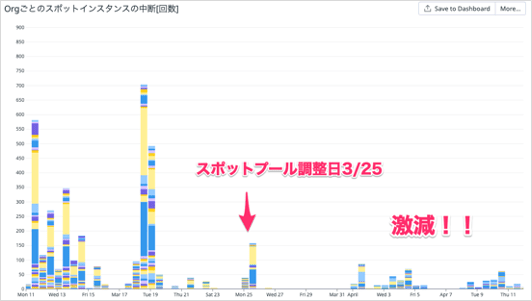
先述のスポット価格と中断されにくさのバランスを取る price-capacity-optimized 戦略とm6aが噛み合うことで運用コストの削減と安定性の向上を同時に実現できました。自分たちにとってはありがたいことですが、m6aが突出して安く中断されにくい理由は分からないです。東京リージョンでm6aの在庫が余ってるのかな・・・?
最終的な費用削減の効果測定
EC2費用
ここまで無駄なランナープールの削減とスポットプールの最適化による費用削減の取り組みを紹介してきました。最後に、これらの取り組みがどれだけの効果をもたらしたのかを詳しく見ていきます。
こちらがEC2の費用のグラフにそれぞれの取り組みを適用した時期を重ねたものです。まず、ランナープールの削減に関しては2/13の夜間・休日のスケールイン忘れの修正をした以降の土日は明らかに費用が下がっていることが分かります。もう1つのスポットプールの最適化はこれを適用した3/25を境に明らかにEC2の費用が下がっていることが分かるかと思います。
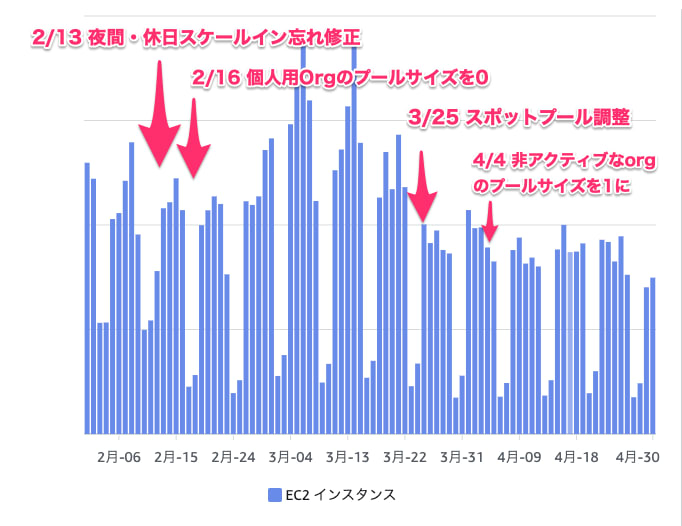
AWS全体の費用
EC2費用の削減は達成できたものの、AWSの費用全体の内訳ではEC2と並んで支配的であったEC2その他(主にNAT Gateway)がまだ手つかずであり、4月以降も依然として内訳としては高額なままです。
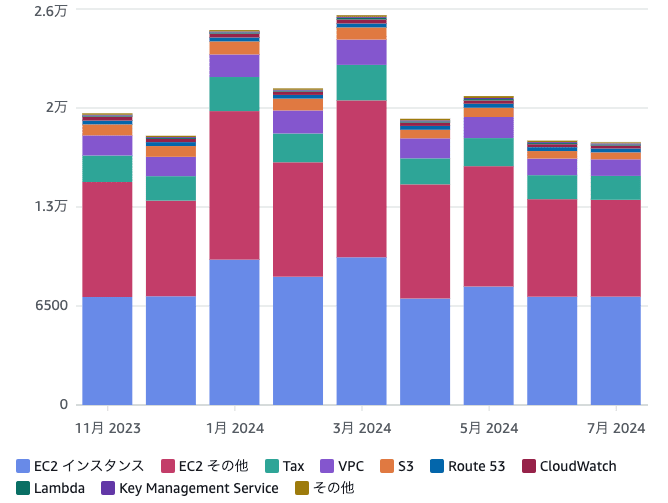
その割には特に料金が高かった1月-3月と比較すると4月以降はNAT Gatewayの料金も含めて全体的に落ち着いているのですが、理由はまだ詳しく調査できていません。自分たちがEC2の費用対策をした2-3月の同時期にプロダクト開発側でも無駄なE2Eテストを削減するなどの効率化を進めていたようなので、その影響があるのかもしれません。
今後の展望:NAT Gatewayの料金削減
EC2費用に関しては今回それなりの削減を達成できたので、今後はNAT Gatewayの料金削減のために以下の対策を予定しています。
VPCフローログの分析
NAT Gatewayの料金削減に向けて、まずはVPCフローログの分析基盤を整備しようと考えています。VPCフローログでNAT Gatewayからどのサイトへの外向きの通信が多いのかを調べることで、削減するための具体的な対策を立てることが可能になります。これにはAthena + QuickSightもしくはGrafanaなどによる可視化を検討しています。
Dockerミラーレジストリの導入
実はVPCフローログの先行調査で、NAT Gatewayを通る通信の上位はセルフホストランナーからDocker Hubへの docker pull であることが判明しました。外向きの通信を減らすために自分たちのVPC内にDocker Hubのミラーレジストリを構築し、pull through cacheを導入することを検討しています[5]。
ミラーレジストリとpull through cacheの設定方法について既にローカルでは検証済みであり、これをAWS上に構築することを予定しています。
IPv6とEgress-Only Internet Gatewayの活用
最後に、これはまだ未検証ですがIPv6とEgress-Only Internet Gatewayの活用を検討しています。IPv6であればPrivate Subnet内から直接インターネットに外向きの通信が可能となるEgress-Only Internet Gatewayが利用できるので、NAT Gatewayを経由する通信を削減できそうです。
2024/6に行われたAWS Summit Japan 2024でもこれに関するセッションがありましたので、こちらを参考にして検証を進めていきたいと考えています。
IPv6 on AWS ~Public IPv4 アドレス削減に向けてできることできないこと~(AWS-20)
まとめ
最近1年間のCybozuでのGitHub Actionsのセルフホストランナーの費用対策について紹介しました。この記事では主にEC2の費用削減に焦点を当て、ランナープールの最適化とスポットプールの最適化によってEC2の費用を30%削減を達成できました。
NAT Gatewayの料金削減についてはまだ改善の余地があるため、今後はこちらに焦点を当ててさらにコスパ良くセルフホストランナーを提供できるようにしていきたいと考えています。
-
運用開始初期の発表スライド https://www.docswell.com/s/miyajan/ZG8QJZ-odc-autoscaling-github-actions-self-hosted-runner ↩︎
-
最近だと最も有名なのは https://github.com/actions/actions-runner-controller (通称ARC)でしょう。 ↩︎
-
過去に生産性向上チームのmiyajanさんが
pool_configとidle_configを併用することは想定されているのか質問したdiscussionには特に返信がないのですが、自分たちで挙動確認した結果この2つを併用することでプール台数を確実に1台に固定可能であると分かりました。 ↩︎ -
ネットワーク帯域が強化される
nはジョブによっては恩恵を受けられるかもしれませんが、高速SSDが追加されているdに関しては専用のセットアップが必要となるためです。 ↩︎ -
同様の問題の対策として良く知られているのはECRのpull through cache機能ですが、様々なチーム向けにセルフホストランナーを提供している自分たちのケースでは適さないと判断しました。これについてはまたいずれ別の記事で説明したいと思います。 ↩︎

Discussion