TL;DR
サイボウズでデータ基盤をゼロから立ち上げたときの経緯をまとめました。
はじめに
データエンジニア/アナリストチームの宮原です。
サイボウズでは社内のデータ基盤に Google BigQuery を採用しており、
私たちデータエンジニアが構築・運用しています。
データ基盤の改善に取り組む上で、他社様のデータ基盤の紹介記事を
日々参考にしています(下記は一例です)。
- MonotaROのデータ基盤10年史(前編) - MonotaRO Tech Blog
- Rettyのデータ基盤の歴史と統合 - Retty Tech Blog
- Data Engineering Study - YouTube
私自身、他社様の事例から学ぶことが多く、
自社の事例を公開することで還元したい想いがありました。
本記事ではサイボウズでのデータ基盤のはじめかたをご紹介します。
データ基盤の構築を検討している方の参考になれば幸いです。
前置き
- 私はデータ基盤構築プロジェクトに技術担当として参加しました。
なので、あくまで技術担当としての解釈を元に記事を作成しています。
他のメンバー、例えばプロジェクトリーダーとは解釈が異なる可能性があります。 - プロジェクトを始めたのは4年前で、記憶が曖昧な部分があります。
当時の資料や議事録を参考になるべく正確に記載しましたが、ご留意ください。
背景
弊社は kintone というクラウドサービスを販売しています。
弊社内でも kintone を活用しています(おそらく一番のヘビーユーザーです)。
kintone にはグラフ機能や CSV 書き出し機能 があり、
社内のほとんどのチームが kintone で集計するか、
CSV に書き出して Excel で集計している状況でした。
プロジェクトの発端
上述の状況の中、サイボウズの事業戦略を検討する組織内で、
「各組織は、各組織が持つデータのみを元に戦略を立てていて、意思決定に改善の余地がある」
という問題意識がありました(下記のイメージです)。
| チーム | 活用例 |
|---|---|
| 営業 | (営業チームが集めた)案件対応履歴を元に、顧客対応の優先度を決定 |
| マーケティング | (マーケチームが主催した)セミナー参加者情報を元に、送付メールを変更 |
| サポート | (サポートチームが対応した)問合対応履歴を元に、活動の優先度を決定 |
データを一箇所に集め、活用できるデータ基盤があれば、
より質の高い意思決定に繋がると考えました(下記のイメージです)。
| チーム | 活用例 |
|---|---|
| 営業 | (マーケチームが主催した)セミナー参加者情報を元に、顧客対応の優先度を決定 |
| マーケティング | (営業チームが集めた)案件対応履歴を元に、送付メールを変更 |
| サポート | (マーケチームが主催した)セミナー参加者情報を元に、活動の優先度を決定 |
プロジェクト体制
上記の問題意識から、事業戦略を検討するメンバーを中心に、
データ基盤を作る社内プロジェクトが立ち上がりました。
当時私はシステムエンジニアとして勤務していましたが、
kintone の事業責任者と他のプロジェクトでご一緒した縁から、
本プロジェクトにも参加することになりました。
他にも興味関心が高いメンバーを巻き込み、以下のような体制になりました。
| 役割 | メンバー |
|---|---|
| プロジェクトリーダー | 事業戦略チームから1名 |
| データ活用メンバー | 営業1名、経営企画1名 |
| 技術 | (私含め)SE2名 |
プロジェクトの進め方
必要なタスクを整理し、以下に取り組みました。
| 期間 | 内容 |
|---|---|
| 2019/06 - 2019/08 | 他チームへのヒアリング |
| 2019/06 - 2019/08 | 紐付キーの検討 |
| 2019/09 - 2020/04 | システム構成検討・実装 |
他チームへのヒアリング
データ基盤を作っても活用されないと意味がないので、
データ活用に関するヒアリングから始めました。
すると、同様の問題意識を持ったメンバーが社内にいることがわかりました。
特に、マーケティングチーム主催のセミナーの参加者情報を
営業チームが案件活動に利用する動きがありました。
なので、まずはスモールスタートとして、
営業チームが必要なデータを連携した基盤を作ることにしました。
営業チームのユースケースを満たすには、以下のデータが必要でした。
| データ元 | データ名 |
|---|---|
| kintone | 商談履歴、セミナー参加者情報 |
| メールワイズ | テクニカルサポート履歴 |
| 社内システム | 製品の試用・購入履歴 |
| MA ツール | 一斉配信メールの送信履歴 |
| アクセスログ | 製品の利用状況 |
データ元のシステムにより、出力方法(例:API)がそれぞれ異なります。
また、同じカラム名であってもデータ元によって微妙に意味が異なる場合がありました。
そのため、出力方法やデータの特徴を把握するため、
各データを持つチームへのヒアリングも実施しました。
紐付キーの検討
データの実態が見えるにつれ、各データをどうやって紐付けるかが問題になりました。
例えば、顧客情報を個人ごとに追いたい場合もあれば、企業ごとに調べたいケースもあります。
個人はメールアドレスである程度識別できそうですが、
企業は何を持って各企業を識別するかが課題でした。
- 会社名
- メールアドレスのドメイン(例:
user@example.comのexample.com) - 法人番号
上記を比較し、弊社では法人番号をキーとして採用しました。
会社名で法人番号を検索する kintone のプラグインを内製したり、
手動で法人番号を付与したりと、なるべく元データ側で法人番号を持つようにしました。
システム構成
要件が固まったため、構成を検討しました。
検討する上で、以下のような共通認識がありました。
※正直記憶が曖昧な部分もありますが、大きくは外れていないと思います。
- データを外に出さない。社内にあるサーバーを利用する。
- プロトタイプなので、なるべくお金をかけない。
- なるべく早く作り、フィードバックを受けながら改善していく。
上記の前提のもと、以下の構成でデータ基盤を構築しました。
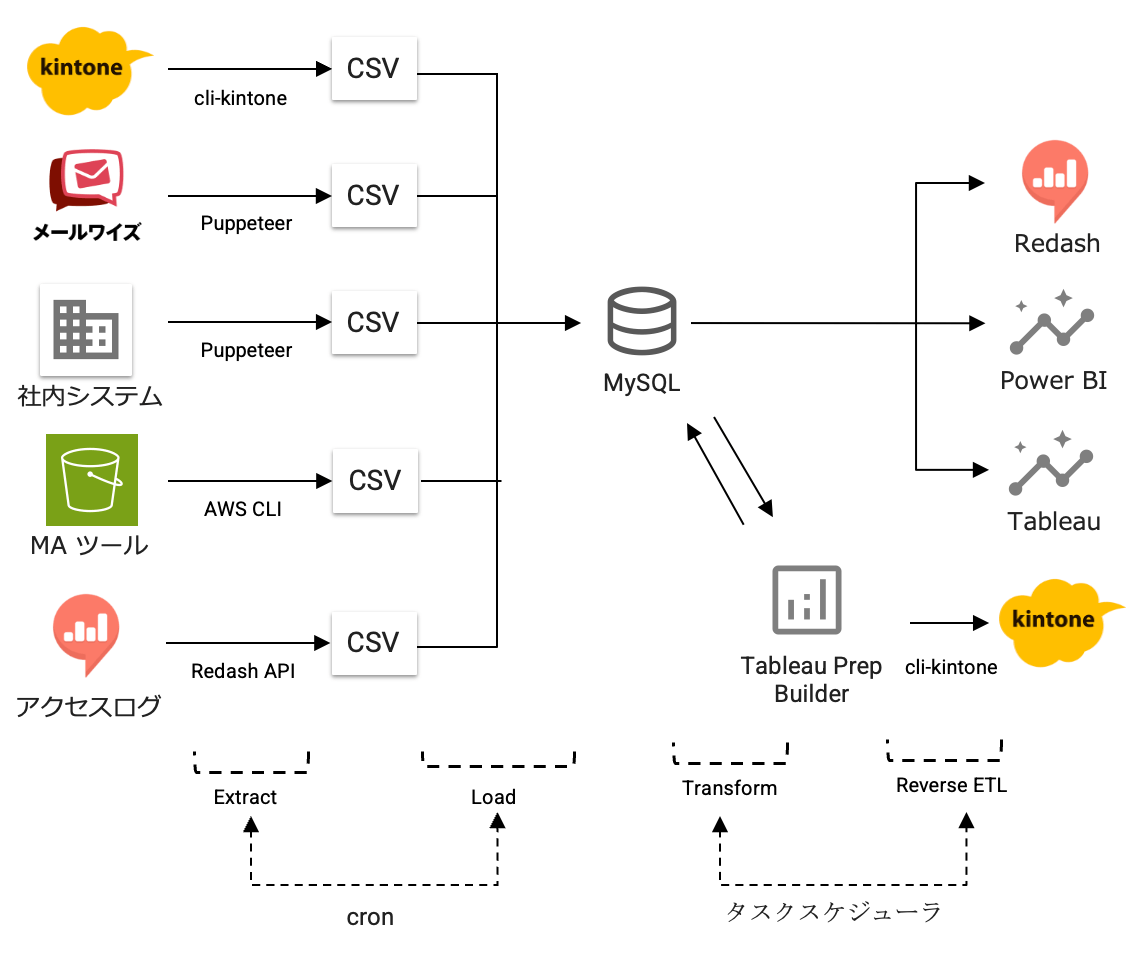
※上記は2020年時点の構成です。2024年時点の構成を別記事で公開しています。
Extract
- kintone からの出力には cli-kintone を利用しました。
- メールワイズ、社内システムからの出力には Puppeteer を採用しました。
API での出力機能がなく、Web ブラウザ上の操作であれば出力できたためです。 - MA ツールには Amazon S3 に出力するオプションがあったため AWS CLI を利用しました。
- 製品のアクセスログは Redash で利用可能になっていたため Redash API を利用しました。
Load
- DB には MySQL を採用しました。
理由としては、私がシステムエンジニアとして MySQL を利用する機会が多く、
仕様にある程度詳しかったことが大きいです。 - MySQL のデータ読み込みには mysqlimport コマンドを利用しました。
Transform
-
Tableau Prep Builder を採用しました。主な理由は以下です。
- 当時私を含めメンバーの SQL スキルが低かった。
- プロジェクトメンバーに Tableau Prep Builder に詳しいメンバーがいた。
- Tableau Prep Builder のライセンスを契約しているメンバーがいた。
Reverse ETL
- 加工したデータを kintone に戻す必要があったため、cli-kintone を利用しました。
ワークフローエンジン
- Extract、Load には cron を採用しました。
- Transform、Reverse ETL にはタスクスケジューラを採用しました。
Tableau Prep Builder は Linux には対応しておらず
Windows Server 上で起動する必要があったため、
cron ではなくタスクスケジューラを利用しました。
振り返り
企画検討から約1年後、上記構成で運用を開始しました。
以下の観点で、プロジェクトについて振り返ります。
- プロジェクトの体制
- 会社の風土
- 技術面
プロジェクトの体制
様々な役割のメンバーが参加していることで、タスクを分担でき、
効率良くプロジェクトを進めることができました。
詳しく触れていませんが、他にも様々なタスクがありました。以下に例を挙げます。
- 既存のデータの整理
- データの管理、活用に関する社内ルールの確認
- 各データの責任者への説明と承認
- システムの構築場所について情報システム部と検討
- 全社プロジェクトとして進める上での、社内での起案
これらのタスクを一人で実行するのは大変です。
様々な役割を持つメンバーがプロジェクトにいたことで、
タスクを分担でき、それぞれの得意分野に集中できました。
また、事業戦略に責任を持つメンバーがプロジェクトリーダーになることで
構築後に誰もデータ基盤を使わない状況になりにくかった点もプラスに働きました。
会社の風土
サイボウズには情報を共有する文化があります。
データ基盤を構築するにあたって、特定のチームがデータを出し渋るようなことはなく、
社内の雰囲気が協力的だったこともプロジェクトを進めやすかった要因でした。
ただし、前述した通り kintone の標準機能で、ある程度データを活用できてしまうため、
「そもそもデータ基盤って必要?kintone で十分では?」という質問への説明コストは
他の企業でデータ基盤を構築するよりも大きかったかもしれません。
技術面
プロトタイプ的な位置付けで構築するという前提があったこと、
また私自身も兼務でプロジェクトに参加していて工数が限られていたことから
実装しやすい技術を採用したのはある意味正解でした。
一方で、他社事例やベストプラクティスを調査した上で検討すれば、
構成は変わっていたかもしれません。
今データ基盤を立ち上げるなら事前調査を慎重にした上で構成を検討します。
また、Reverse ETL の部分については、
実装コストの割にビジネス側での活用が進みませんでした。
難しい部分ではありますが、最初から全てを自動化するのではなく
しばらくの間は手動で kintone に戻すなど、工数とのバランスを見て対応できたかもしれません。
最後に
ヒアリングで得た感触の通り、その後順調に利用者が増え、
パフォーマンスに問題が出たことから2022年に BigQuery に移行しました。
※他にも、ELT の部分がコンテナベースになっていたり、Airflow や dbt を導入したりと、
2023年現在では異なる構成になっています。今後、別記事に書きます。
データ基盤をゼロから立ち上げた一例として、ご参考になれば幸いです。
追記
2024年時点のシステム構成を別記事で公開しました。

Discussion