MLflow使い始めたのでメモ
Kaggleなどをやる時に、実験結果を管理する必要があって、MLflowを使うと便利とのことで使ってみて、使い方などメモしました。
使ってみた感想としては、特別なことをしてくれるわけではないので必ずしも必須ではないですが、使った特徴、モデル、CVスコアなどを一覧にできて、それに学習済みのモデルや可視化した画像などを紐づけておけるのでとても便利だと思いました。
自分は、使ってみようと思いました。
使い方
Quickstart — MLflow 1.6.0 documentationをみて、やってみるのが早いです。
pip install mlflow
でインストール
import os
from mlflow import log_metric, log_param, log_artifact
if __name__ == "__main__":
# Log a parameter (key-value pair)
log_param("param1", 5)
# Log a metric; metrics can be updated throughout the run
log_metric("foo", 1)
log_metric("foo", 2)
log_metric("foo", 3)
# Log an artifact (output file)
with open("output.txt", "w") as f:
f.write("Hello world!")
log_artifact("output.txt")
このコードは、param1を保存して、metricfooを3つ保存して、output.txtを紐づけるというコード。
同じのでも良いので、何回か動かして、次のコードを動かすとイメージが湧きました。
mlflow ui
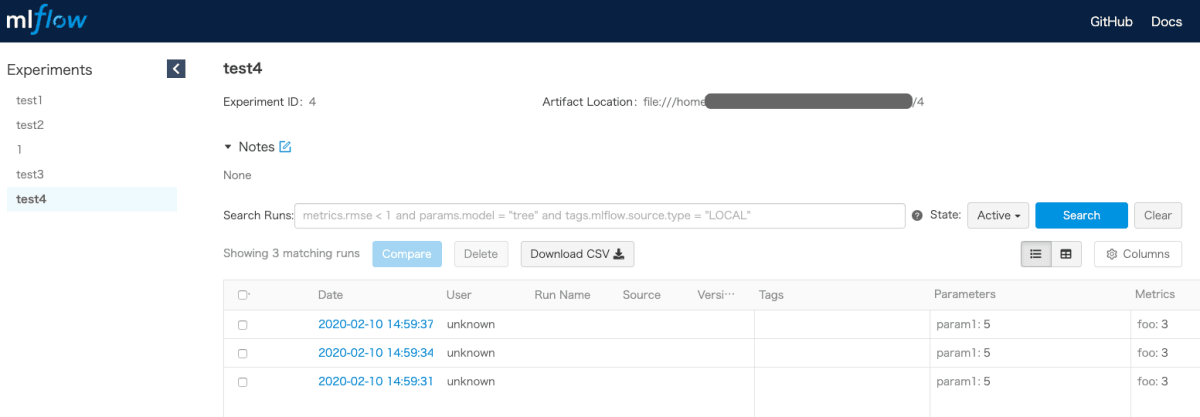
このように、結果をみることができます。
実際に、使う時も、log_param, log_metric, log_artifactで、記録したいパラメータ、評価指標、記録したいものを保存しておけば良いので楽です。
用語
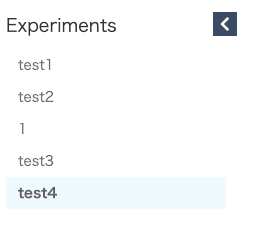
実験は、Experimentsという単位でカテゴライズされます。
この画像であれば、test1, test2, 1, test3, test4という単位。
同じコンペでも、違うジャンルの実験を行うのでありがたい。

実験はrun_idという単位で管理されます。
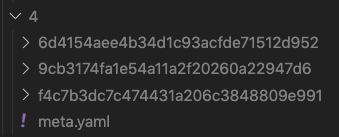
run_idは自動で付番されて、上の画像ように、run_idのフォルダができる。
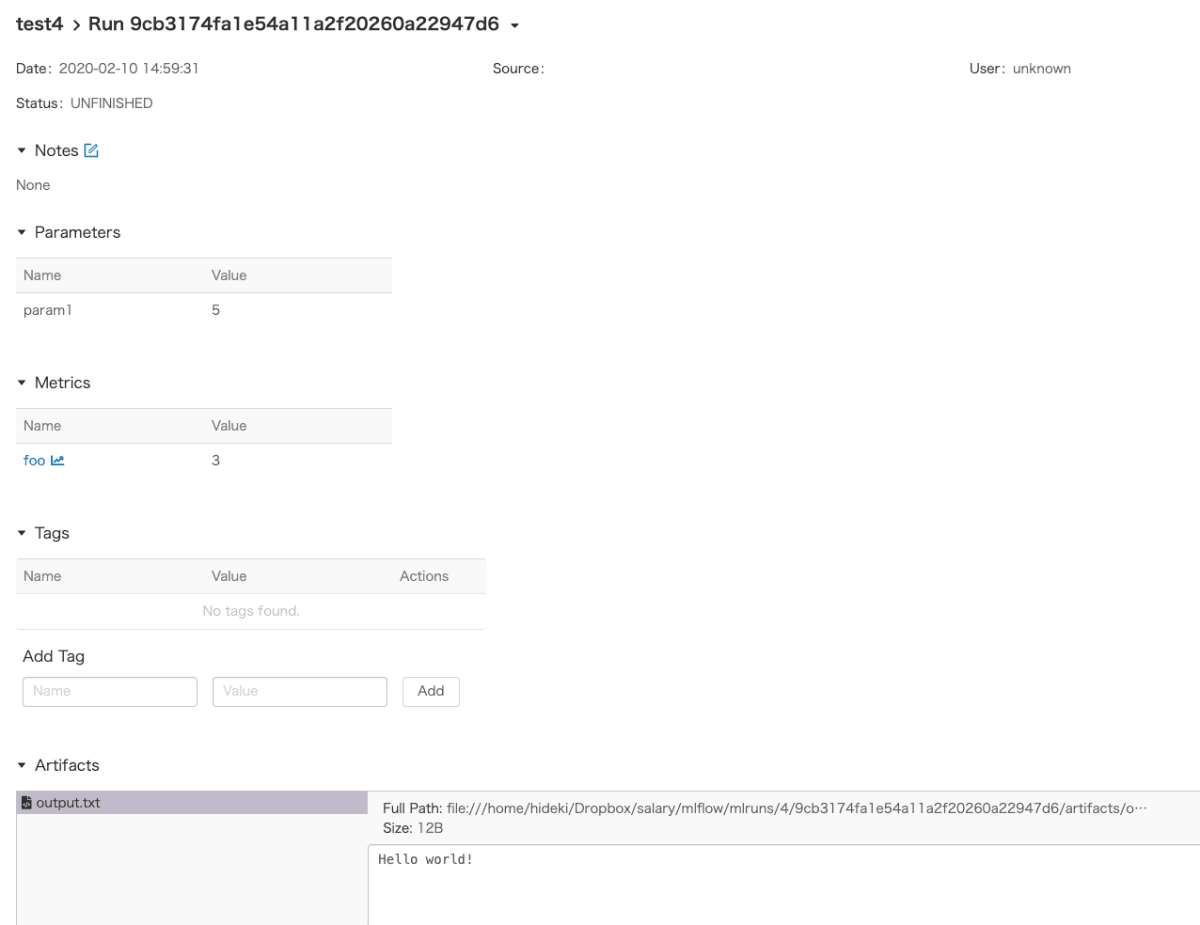
viewerからもこのように、run_idごとのページで確認が可能。
後から情報の追加
run_idを使って後から、情報の追加も可能
例えば次のようにする
mlflow.start_run(run_id="9cb3174fa1e54a11a2f20260a22947d6")
figure = plt.figure()
x = np.array([1, 2, 3])
y = np.array([3, 2, 1])
plt.plot(x, y)
plt.savefig('plot.png')
log_artifact('plot.png')
これは、run_id="9cb3174fa1e54a11a2f20260a22947d6"に、plot.pngを後から足すという処理。
紐づけておけば、veiwerからpngファイルを見ることができるのでとても便利!!
lower level API
ここまでは、“fluent” API という、抽象化されたAPIを使っての処理だったけれど、低レベルAPIも使用することができる。
ドキュメントも用意されているけれど、ドキュメントみながら、githubのソースをみるのが理解が早かった。
日本語の記事だと、ハイパラ管理のすすめ -ハイパーパラメータをHydra+MLflowで管理しよう- - やむやむもやむなしで、使用例が書かれているので参考になる。
初めのチュートリアルのコードは、このように書くことができる。
client = MlflowClient()
experiment_name = "test4"
try:
experiment_id = client.create_experiment(experiment_name)
except:
experiment_id = client.get_experiment_by_name(experiment_name).experiment_id
run_id = client.create_run(experiment_id).info.run_id
client.log_metric(run_id, "foo", 1)
client.log_metric(run_id, "foo", 2)
client.log_metric(run_id, "foo", 3)
with open("output.txt", "w") as f:
f.write("Hello world!")
client.log_artifact(run_id, local_path="output.txt")
plot.pngを追加するコードは次のように書ける
client = MlflowClient()
run_id = "9cb3174fa1e54a11a2f20260a22947d6"
figure = plt.figure()
x = np.array([1, 2, 3])
y = np.array([3, 2, 1])
plt.plot(x, y)
plt.savefig('plot.png')
client.log_artifact(run_id, local_path="plot.png")
パイプラインへの追加
特徴やCVスコアなど、loggerで吐き出している場合は、その箇所を修正して、MLflowに渡すようにしれやれば良さそう。
とりあえず始める方へ
ここまで色々書きましたが、とりあえず、既存の自分のコードに、次のコードを足して始めました。
低レベルAPI使わなくても、今のところ問題ないので、このページのメソッドのみで、自分がやりたいことができることがわかりました。
import mlflow
from mlflow.utils.mlflow_tags import MLFLOW_RUN_NAME
experiment_name = `実験のカテゴリを指定` # 要修正
mlflow.set_experiment(experiment_name)
run_id = `None or 先に行ったrun_idを指定` # 要修正
if not run_id:
mlflow.start_run(run_id=None)
run_id = mlflow.active_run().info.run_id # run_idはこれで取得できる
elif run_id: # 後から、同じrun_idに追記する時
mlflow.start_run(run_id=run_id)
# Run Nameの指定と、パラメータ・特徴の記録
mlflow.set_tag(MLFLOW_RUN_NAME, TASK_NAME) # Run Nameを指定
mlflow.log_param('model_params', PARAMS_LGB) # LigtGBMのパラメータを記録
mlflow.log_param('Feature', FEATURE) # 使った特徴を記録
###
#中略 LightGBMで学習する
##
# cvscoreの保存
dic = dict()
for i, score in enumerate(scores):
dic[f'fold{i+1}'] = score
mlflow.log_metrics(dic) # 各foldのsocreを記録
mlflow.log_metric('cv_score', np.mean(scores)) # 各foldのscoreの平均を記録
# ビジュアライズしたpngファイルを記録
mlflow.log_artifact('importance.png') # feature importanceを記録
参考
- [https://qiita.com/fam_taro/items/155912068ff475a53e44 MLflow 1.0.0 リリース!機械学習ライフサイクルを始めよう! - Qiita]
- MLflowの全体像がわかりやすい
-
mlflow — MLflow 1.6.0 documentation
- 基本的にここを見ておけば問題なし
- 上のドキュメントで、何をやっているのかわからくなったら、次のソースを見ると良い
-
nyaggle
- mlflowがパイプラインい組み込まれており、参考になる
-
ハイパラ管理のすすめ -ハイパーパラメータをHydra+MLflowで管理しよう- - やむやむもやむなし
- 使用例が書かれており参考になる
-
MLflowのデータストアを覗いてみる - 株式会社ホクソエムのブログ
- とても詳しくしっかり書かれている。
- https://mlflow.org/docs/latest/cli.html#mlflow-ui
- MLflow 1.0.0 リリース!機械学習ライフサイクルを始めよう! - Qiita
ssh使用時
sshの時は、portを指定する必要がある。
mlflow ui -h <自分のマシンのアドレス>
としてやって、自分のマシンのアドレス:5000にアクセスすれば良い
GCP使用時
GCPの時は、ファイアウォールの設定が必要になる。
次の記事が詳しいので、参考にすると良い https://stackoverflow.com/questions/60597319/running-mlflow-on-gcp-vm
ファイアウォールの設定については、次の記事 https://rf00.hatenablog.com/entry/2018/01/01/160820
以上の記事の通り設定し、<外部IP>:5000 にアクセスする。最初は設定大変だけれど、1回覚えて仕舞えば次からは簡単。
【追記】
複数環境で使うことを考える
KaggleでMLflowを使うことを考えると、複数環境での結果を統合したいというニーズを持つ場合があります。
KaggleのNotebook、自宅のマシーン、GCPなど。その場合にどうすれば良いかという方法を考えてみました。(他に良い方法があれば、教えてください)
mlflow.set_tracking_uri()を使う
mlflow.set_tracking_uri()を使うことで、サーバを動かしておける環境であれば、集約できるようです。自分は試したことはないので使い勝手はわかりません。
git(github)で同期する
mlrunsのファイルを丸ごとpushして、同期するやり方です。実験毎にできる多くのファイルをpushすることになるため、面倒な気がしますが、それを面倒と思わなければ1番楽かもしれないと思います。
githubのプライベートのレポジトリを作っておいて、そこにpushしていけば良いかと思います。
gcs(Google Cloud Storage)などで一括で管理する
kaggleのnotebookで実験を行った場合、githubにpushできないので、その際にこうやったら良いんじゃないかという例です。
notebookから送る例は、次のnotebookの通り。https://www.kaggle.com/currypurin/japanese-mlflow-gcs-wip
EXPERIMENT_ID は自動で付番されるため、gcs側のEXPERIMENT_ID を指定しています。
自宅PCや、colaboratoryからは、gsuitilを使って一括でgcsに送れるので簡単。githubなどと併用することもできます。
Discussion