TL;DR
- Workboxを使うと、オフライン対応が簡単にできるようになる。
- Next.jsでやるのはしんどい。
- 動画や音声を事前にキャッシュする場合には特別な対応が必要。
完全オフライン対応とは?
この記事では、「アプリを一度インストールしておけば、その後はインターネット接続がない状況でもアプリのすべての機能を使える状態にすること」を完全オフライン対応と定義します。
はじめに
完全オフライン対応をしたかった理由
PoCでユーザーテストを行うにあたり、スマホ端末ごと貸し出す必要がありました。アプリは事前にインストールが可能ですが、テスト環境ではネットワークに接続できないため、完全オフライン対応が不可欠でした。
「ネイティブアプリでも良いのでは?」という意見も考えられますが、今回はPoCの迅速な改善を重視していたため、PWAを採用することにしました。
どんなアプリが完全オフライン対応に向いている?
今回作ったアプリはまさにこれに該当するのですが、日記アプリや健康管理アプリのような自己完結型のアプリが向いています。
これらのアプリはユーザー自身の入力が主なデータソースであり、外部データの更新やリアルタイムのサーバー通信を必要としません。データは必要に応じて、例えば端末を回収したタイミングでサーバーに同期するようにもできます。
フレームワークの選定
このプロジェクトでは、完全なオフライン対応のため、インストール時にリソースの事前キャッシュをすることが必要です。
途中までNext.jsで作っていたのですが、SSRやらでページの事前キャッシュがしんどいのでやめました。
代わりに、React + Vite (SPA)を使います。
Service Workerを使ってオフライン対応する
Service Workerとはなにか?
メインスレッドとは独立して動く
Service Workerは、Webアプリの裏で動く特別なスクリプトです。通常のJavaScriptは、ユーザーが見て操作する部分(メインスレッド)で動きますが、Service Workerはそこから独立して動きます。これにより、ページの表示を邪魔せずにバックグラウンドで処理を行えます。
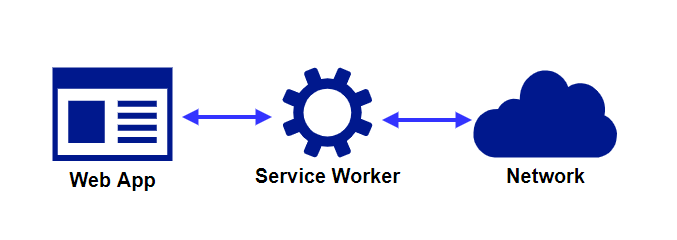
プロキシサーバーのように振る舞う
Service Workerの一番の役割は、Webアプリとインターネットの間で情報のやり取りを行うことです。これにより、ブラウザとサーバー間の通信を管理し、プロキシサーバーのように振る舞います。
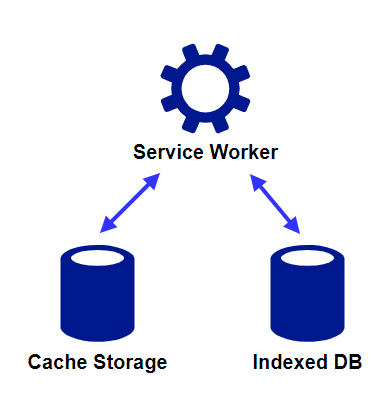
データストレージへのアクセス
Service WorkerはCache StorageやIndexedDBにアクセスすることができます。
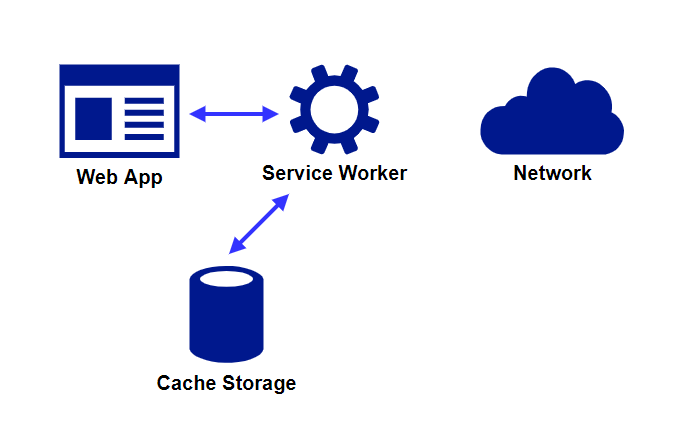
Service Workerはどのようにしてオフライン対応を実現するのか?
Service Workerは「プロキシサーバーのように振る舞う」という性質と「データストレージへのアクセス」という機能を利用してオフライン対応を実現します。
具体的には、ユーザーがサイトにアクセスした際に、インターネットからではなく、事前キャッシュされたデータをCache Storageから返すことで、オフラインでもサイトを利用できるようにします。
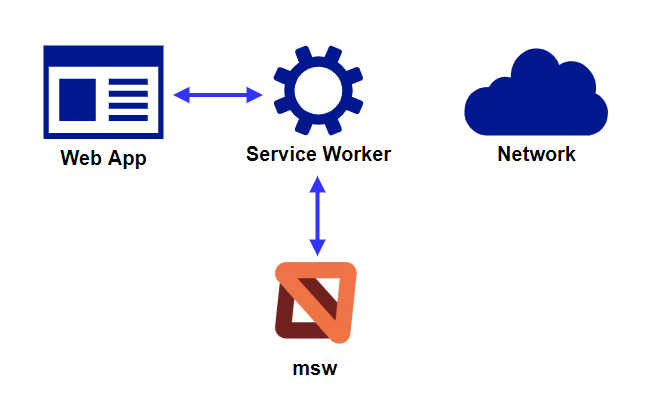
余談 : プロキシサーバとしての性質を利用したmsw
Service Workerのプロキシサーバとしての性質を応用する例として、「Mock Service Worker(msw)」があります。
このライブラリは、アプリケーションからのネットワークリクエストを捕捉し、事前に定義したレスポンスを返すことで、サーバーの応答をmockすることができます。
これにより、実際のバックエンドが存在しなくても、フロントエンドの開発やテストをすることができます。
Workboxを使ってService Workerを書く
Workboxとは何か?
Workboxは、Googleが開発したライブラリで、Service Workerの設定や管理を簡単に行うことができるツールです。
Service Workerは中身はただのjsなので直接書くこともできますが、Workboxの機能を利用すれば簡単に効率的なキャッシュ戦略などを組み込むことができます。
Workboxの導入
Workboxをプロジェクトに導入する方法はいくつかあります。主な方法は以下の3つです。
- Workbox CLI : npmスクリプトを使っている場合に適しています。
- Workbox Build : Node.jsのビルドツールを使っている場合に適しています。
- Workbox Webpack Plugin : Webpackを使っている場合に適しています。
今回は、Viteを使うので、Workbox Buildを使用した導入方法について説明します。
※ViteにはWorkbox Buildをwrapした vite-plugin-pwa というのもありますが、設定などが隠蔽されがちで、今回はシンプルに使いたかったので選択していません。
1. 依存関係のインストール
まず、 workbox-build をプロジェクトに追加します。
yarn add workbox-build --dev
2. Workbox Build 設定スクリプトの作成
プロジェクトのルートに workbox-build.js ファイルを作成し、以下のように workbox-build を設定します。
ViteはESモジュールをサポートしているため、import文を使用することができます。
import { generateSW } from "workbox-build";
// Push通知などが必要ない場合には、generateSWを利用するのが楽
generateSW({
// ここに設定を書いていく
swDest: "dist/sw.js", // 作成されたService Workerのファイルの出力先
globDirectory: "dist", // 事前キャッシュ対象ディレクトリ (後の項目で解説)
// その他の設定...
}).then(({ count, size, warnings }) => {
if (warnings.length > 0) {
console.warn(
"Warnings encountered while generating a service worker:",
warnings.join("\n")
);
}
console.log(
`Generated a service worker, which will precache ${count} files, totaling ${size} bytes.`
);
});
3. スクリプトの追加
package.jsonに以下のスクリプトを追加して、ビルドプロセスにService Workerの生成を組み込みます。
"scripts": {
"build": "vite build && node workbox-build.js"
}
事前キャッシュ
事前キャッシュとは、アプリケーションが初めて読み込まれる際に、必要なリソースをあらかじめキャッシュに保存する方法です。
完全オフライン対応を行うため、Viteが出力する dist ディレクトリ内のファイルをすべて事前にキャッシュします。
Workboxを使った事前キャッシュの設定
globDirectory に対象のディレクトリを設定し、 globPatterns にキャッシュしたいファイルタイプを指定します。
また、 maximumFileSizeToCacheInBytes オプションを使って、キャッシュするファイルの最大サイズを設定できます。
maximumFileSizeToCacheInBytes はデフォルトだと小さめの数字になっているので必要に応じて設定してください。
generateSW({
globDirectory: 'dist', // 事前キャッシュ対象ディレクトリ
globPatterns: ['**/*.{html,js,css,png,webp,mp4,mp3}'], // 対象ファイルパターン
maximumFileSizeToCacheInBytes: 100 * 1024 * 1024, // キャッシュするファイルの最大サイズ(100MB)
// その他の設定...
})
事前キャッシュでは、リソースのハッシュ値を利用したリビジョン番号を付与した状態でキャッシュされるため、リソースが更新されたときのみキャッシュを更新するなども自動で行ってくれます。
ルーティングに対応する
SPAでは通常、ルーティングはクライアントサイドで管理されます。
この場合、Service Workerは index.html のみをキャッシュします。
ルーティングとキャッシングに関連する問題
ユーザーがオフライン時に直接 /hoge/fuga などの特定のルートにアクセスすると、Service Workerは /hoge/fuga/index.html をキャッシュから探しますが、このファイルは存在しないためエラーが発生します。
Navigate Fallbackを利用して解決する
この問題を解決するために、Workboxを使用してすべてのナビゲーションリクエストに対して index.html をフォールバックとして提供する設定を行います。
これにより、どのルートにアクセスしても、 index.html がロードされ、その後JavaScriptがページを適切にレンダリングします。
generateSW({
navigateFallback : '/index.html'
// APIのパスをフォールバックさせたくない場合
navigateFallbackDenylist: [/^\/api\//],
// その他の設定...
})
Service Workerのライフサイクルを制御する
Service Workerのライフサイクルは特有のもので、主に次のステージから構成されます。
- 登録 : Service Workerのスクリプトがブラウザに登録されます。
- インストール : 事前キャッシュなどの初期セットアップが行われます。
- アクティベート : インストール完了後、Service Workerはアクティブな状態になります。
ライフサイクルに関連する問題
Service Workerを導入する際、次のような問題が発生することがあります。
-
インストール後にService Workerが待機する問題 : 新しいService Workerがインストールされた後、通常、古いService Workerがまだアクティブであり、新しいバージョンは待機状態になります。これにより、新しい機能が直ちに利用できない状況が発生します。
-
アクティベート後にすぐに適用されない問題 : 新しいService Workerがアクティベートされても、既に開いているページには自動的に適用されません。ユーザーはページをリロードする必要があります。
SkipWaiting, ClientsClaimを利用して解決する
この問題を解決するために、以下の二つのオプションが有効です:
- skipWaiting : このオプションを使用すると、新しいService Workerはインストール後すぐにアクティブ状態になります。
- clientsClaim : アクティベーション時にこのオプションが有効になっていると、新しいService Workerはすぐにページを制御開始します。
generateSW({
skipWaiting: true,
clientsClaim: true,
// その他の設定...
});
オンラインに戻ったときにリクエストを再試行する
background-sync を使うことで、オフライン時に失敗したリクエストをキューに保存し、ネットワークが復旧した際に自動的にリクエストを再試行できます。これにより、ユーザーがオンラインに戻った際に、途中で失敗した操作を再度実行し、データの整合性を保つことが可能になります。
Network Failedで失敗したもののみ再実行し、400や500で失敗したものは再試行しません。
具体的には、リクエストのデータをIndexedDB内に保存しています。
generateSW({
// 動的キャッシングの設定
runtimeCaching: [
{
urlPattern: /\/api\/.*\/*.json/,
handler: 'NetworkOnly',
options: {
backgroundSync: {
name: "api",
options: {
maxRetentionTime: 365 * 24 * 60, // 24時間
},
},
}
},
// その他の設定...
],
// その他の設定...
});
ここまでの設定でスクリプトは作成完了です。次にスクリプトの登録を行います。
Service Workerのスクリプトを登録する
Workbox Windowを使ってService Workerのスクリプトの登録を行う
Workbox Windowを使用して、フロントエンドから簡単にService Workerを登録し、その状態を効果的に管理できます。
また、今回のアプリではService Workerがアクティブになるまでアプリケーションをローディング状態にすることにします。
常に register をするのは無駄に見えますが、Service Workerのスクリプトの中身が変更されていない場合にはブラウザはService Workerを登録しないため、問題ありません。
import { useEffect, useState } from 'react';
import { Workbox } from 'workbox-window';
const RegisterServiceWorker = () => {
const [workActive, setWorkActive] = useState(false);
useEffect(() => {
const registerSW = async () => {
if ('serviceWorker' in navigator && !workActive) {
const wb = new Workbox('/sw.js');
const registration = await wb.register();
if (registration.active) {
setWorkActive(true);
}
wb.addEventListener('activated', () => setWorkActive(true));
}
};
registerSW();
}, [workActive]);
return <IndexPage loading={!workActive} />;
};
export default RegisterServiceWorker;
ここまでの設定でスクリプトは作成され、そのスクリプトの登録も行えたので完全オフライン対応は完了したはずだったのですが...
デプロイすると動画が再生されない問題が発生
意気揚々とデプロイして色々と弄っていると何故かSafariでのみ動画が再生されない...!
色々と調べていたら対処法が公式に載っていました!
キャッシュに保存された音声と動画の配信
参考 : Google DevelopersのWorkboxドキュメント
Rangeリクエストヘッダーの問題
クライアントがサーバーから動画を取得する際にHTTP Rangeリクエストを使用すると、通常、ネットワーク経由で部分的な内容を取得した場合にはステータスコード206(Partial Content)が返されます。
しかし、キャッシュからの取得時はRangeリクエストに対応していないため、全ファイルを取得してステータスコード200(OK)が返されます。
この挙動は、特にSafariのように200のステータスコードを受け取るとファイルのさらなる読み込みを停止するブラウザでは問題となり、キャッシュからの動画取得時に再生が行われないことがあります。
Rangeリクエストに対応する
-
<video>や<audio>のタグのcrossoriginにanonymousを設定する。
これは、同一オリジンであっても設定する必要があります。
<video src="movie.mp4" crossorigin="anonymous"></video>
<audio src="song.mp3" crossorigin="anonymous"></audio>
-
workbox-range-requestプラグインを使って、Rangeリクエストを処理する
generateSW({
// 動的キャッシングの設定
runtimeCaching: [
{
// urlPatternに一致するリクエストが来た場合(この場合は動画か音声)に処理する
urlPattern: ({ request }) => {
const { destination } = request;
return destination === "video" || destination === "audio";
},
handler: "CacheFirst",
options: {
cacheName: "media-cache",
// workbox-range-requestプラグインを使って処理する
rangeRequests: true,
cacheableResponse: {
statuses: [200],
},
},
},
// その他の設定...
],
// その他の設定...
});
Googleのページでは事前キャッシュでも動くと書いてありましたが、私が試したところでは事前キャッシュでは動かず、 cache.add を使うことになりました。
Service Workerがアクティブになった後で必要なメディアファイルを手動でキャッシュに追加する処理を加えます。
// 上で設定した動的キャッシングのキャッシュ名と同じキャッシュ名にする
caches.open("media-cache").then((cache) => {
cache.add("/movie.mp4");
cache.add("/song.mp3");
});
おわりに
ここまで全部やれば、アプリケーションは完全オフラインで動作するはずです。
実際に確認する場合、Viteでbuildした後にpreviewコマンドを使って動作を確認し、ブラウザの開発者ツールを使ってオフラインモードでテストすると良いでしょう。
実際のアプリケーション開発では、データの保持場所やサーバーとの同期など、さらに詳細な設計が必要になると思います。
今回はあんまり触れませんでしたが、動的キャッシングの話とかもなかなか面白いです。

Discussion