Goのnet/httpのServer側デザインの良さについて語る(Accept編)
あらすじ
前回はlistenでepollにlisteFDを登録するところまで見てきました。
今回はepollに登録したlistenFDがどう利用されるのか見ていきましょう。
操作は最初のnet.Listen()から戻ったところから開始します。
Server.ListenAndServe -> Server.Serve
func (srv *Server) ListenAndServe() error {
if srv.shuttingDown() {
return ErrServerClosed
}
addr := srv.Addr
if addr == "" {
addr = ":http"
}
ln, err := net.Listen("tcp", addr) <-★
if err != nil {
return err
}
return srv.Serve(ln)
}
func (srv *Server) Serve(l net.Listener) error {
...
ctx := context.WithValue(baseCtx, ServerContextKey, srv)
for {
rw, err := l.Accept() -★
...
c := srv.newConn(rw)
c.setState(c.rwc, StateNew, runHooks) // before Serve can return
go c.serve(connCtx)
}
}
Serveの中に入ると無限ループの中でAccept -> 新しいGoRoutineを生み出しリクエストを処理ということをやっています。
Acceptを見ていきましょう。
TCPListener.Accept -> TCPListener.accept -> netFD.accept -> FD.Accept -> accept
tcpsock.go
func (l *TCPListener) Accept() (Conn, error) {
if !l.ok() {
return nil, syscall.EINVAL
}
c, err := l.accept()
if err != nil {
return nil, &OpError{Op: "accept", Net: l.fd.net, Source: nil, Addr: l.fd.laddr, Err: err}
}
return c, nil
}
func (ln *TCPListener) accept() (*TCPConn, error) {
fd, err := ln.fd.accept()
if err != nil {
return nil, err
}
tc := newTCPConn(fd)
if ln.lc.KeepAlive >= 0 {
setKeepAlive(fd, true)
ka := ln.lc.KeepAlive
if ln.lc.KeepAlive == 0 {
ka = defaultTCPKeepAlive
}
setKeepAlivePeriod(fd, ka)
}
return tc, nil
}
fd_unix.go
func (fd *netFD) accept() (netfd *netFD, err error) {
d, rsa, errcall, err := fd.pfd.Accept()
if err != nil {
if errcall != "" {
err = wrapSyscallError(errcall, err)
}
return nil, err
}
if netfd, err = newFD(d, fd.family, fd.sotype, fd.net); err != nil {
poll.CloseFunc(d)
return nil, err
}
if err = netfd.init(); err != nil {
netfd.Close()
return nil, err
}
lsa, _ := syscall.Getsockname(netfd.pfd.Sysfd)
netfd.setAddr(netfd.addrFunc()(lsa), netfd.addrFunc()(rsa))
return netfd, nil
}
func (fd *FD) Accept() (int, syscall.Sockaddr, string, error) {
if err := fd.readLock(); err != nil {
return -1, nil, "", err
}
defer fd.readUnlock()
if err := fd.pd.prepareRead(fd.isFile); err != nil {
return -1, nil, "", err
}
//無限ループ
for {
s, rsa, errcall, err := accept(fd.Sysfd) <-★1
if err == nil {
return s, rsa, "", err
}
switch err {
case syscall.EINTR:
continue
case syscall.EAGAIN:
if fd.pd.pollable() {
if err = fd.pd.waitRead(fd.isFile); err == nil { <-★2
continue
}
}
case syscall.ECONNABORTED:
// This means that a socket on the listen
// queue was closed before we Accept()ed it;
// it's a silly error, so try again.
continue
}
return -1, nil, errcall, err
}
}
func accept(s int) (int, syscall.Sockaddr, string, error) {
ns, sa, err := Accept4Func(s, syscall.SOCK_NONBLOCK|syscall.SOCK_CLOEXEC)
...
}
netFDとかFDとかの流れは前回のListen編で見たのと同じですね。
FD.Acceptの★1 accept(fd.Sysfd)から呼ばれるacceptでは、引数にSOCK_NONBLOCKが渡されています。
acceptは通常ブロックしますが、フラグにNONBLOCKINGを渡せばブロックしません。
ただ結局ブロックしなくても無限ループでacceptできるかどうかというのを確認しなければならないので、システムコール自体ではなくacceptができるかの確認のためにブロックしてしまいます。(FD.Acceptの無限ループのところですね。)
なぜ結局ブロックするのにNONBLOCKを引数に渡しているのでしょうか。
おそらく同じくFD.Acceptの★2 fd.pd.waitRead(fd.isFile)経由でAcceptの待ち中に、
Goroutineを一旦コンテキストスイッチすることで別のGoroutineを使い効率化を図っているのが理由かと思います。
Acceptのブロックについての参考
pollDesc.waitRead -> pollDesc.wait -> poll_runtime_pollWait -> netpollblock -> gopark
listenFDが準備完了ではなくacceptが失敗するとpollDesc.waitReadに行きます。
ここからは現在動いているこのGoroutineをPから外してSleepさせる動きをしていきます。
Pから外す?と思った方はすぐに次章で説明しますのでここでは一旦スルーしてください。
fd_poll_runtime.go
func (pd *pollDesc) waitRead(isFile bool) error {
return pd.wait('r', isFile)
}
func (pd *pollDesc) wait(mode int, isFile bool) error {
if pd.runtimeCtx == 0 {
return errors.New("waiting for unsupported file type")
}
res := runtime_pollWait(pd.runtimeCtx, mode)
return convertErr(res, isFile)
}
netpoll.go
func poll_runtime_pollWait(pd *pollDesc, mode int) int {
errcode := netpollcheckerr(pd, int32(mode))
if errcode != pollNoError {
return errcode
}
// As for now only Solaris, illumos, and AIX use level-triggered IO.
if GOOS == "solaris" || GOOS == "illumos" || GOOS == "aix" {
netpollarm(pd, mode)
}
for !netpollblock(pd, int32(mode), false) {
errcode = netpollcheckerr(pd, int32(mode))
if errcode != pollNoError {
return errcode
}
// Can happen if timeout has fired and unblocked us,
// but before we had a chance to run, timeout has been reset.
// Pretend it has not happened and retry.
}
return pollNoError
}
func netpollblock(pd *pollDesc, mode int32, waitio bool) bool {
gpp := &pd.rg
if mode == 'w' {
gpp = &pd.wg
}
// set the gpp semaphore to pdWait
for {
old := *gpp
if old == pdReady {
*gpp = 0
return true
}
if old != 0 {
throw("runtime: double wait")
}
if atomic.Casuintptr(gpp, 0, pdWait) {
break
}
}
// need to recheck error states after setting gpp to pdWait
// this is necessary because runtime_pollUnblock/runtime_pollSetDeadline/deadlineimpl
// do the opposite: store to closing/rd/wd, membarrier, load of rg/wg
if waitio || netpollcheckerr(pd, mode) == 0 {
gopark(netpollblockcommit, unsafe.Pointer(gpp), waitReasonIOWait, traceEvGoBlockNet, 5)
}
// be careful to not lose concurrent pdReady notification
old := atomic.Xchguintptr(gpp, 0)
if old > pdWait {
throw("runtime: corrupted polldesc")
}
return old == pdReady
}
さて、詳しい内容を見る前に少し事前準備がいるので一度ここでストップしましょう。
ここまではGoroutineがスリープするところまでざっくりと見てきました。
acceptにおけるGoroutineのスリープと復帰の詳細...の事前準備
一旦GoにおけるGoroutineのコンテキストスイッチとスケジューリングについて軽く説明します。
押さえておきたいところはG,M,Pという要素があり、
GはGoroutine
MはOSスレッド
Pはプロセッサーで
この三つが協調しています。
ここでは下記の図にある通り、キューにはローカルキューとグローバルキューがあり、
GoroutineはPのキュー(ローカルキュー)、もしくはグローバルキューに入っていないとスケジューリングされないことを覚えておきましょう。
基本的流れを下記に書きます。
- goparkで現在のGoroutineを手放し、そのままschedule()を実行しスケジューリング
- scheduleでグローバルキューかローカルキュー、もしくはnetpollでepoll経由で使えるGを探して新しいGを使う
Step1 GoparkでGが外れる
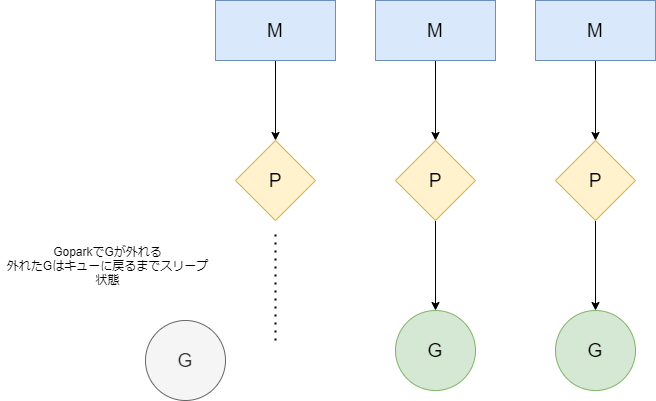
Step2 スケジューリングで新しいGを取ってくる


GMPやスケジューリングについてもっと詳しく見たい方向けの参考(のちのちソースコードレベルでの解説を自分で書いてみたいと思います。)
Schedule G,M,Pについて
実際の動作を見る前にepollとpollDescも絡んでくるのでその二つのListenとAccept中の動作も下記で見てみましょう。

epollについてはlisten編のepollの使い方を参照ください
スケジューリングとepollを合わせた動きが下図です。下図の動きをもとに次節以降解説していきます。
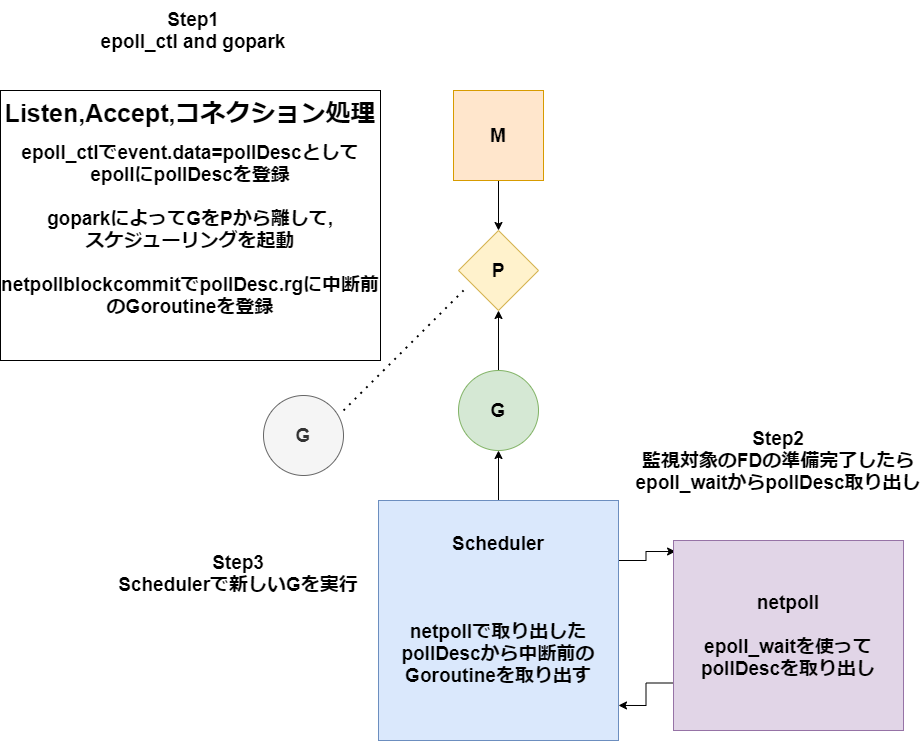
acceptにおけるGoroutineのスリープと復帰の詳細(本編)
さてここからはStep1,Step2に合わせて本編のAceeptの動作を見ていきます。
Step1 GoparkでGが外れる
listenFdが準備完了しておらずerrでEAGAINが返ってきたとして話を進めます。
pollDesc.waitRead -> pollDesc.wait -> poll_runtime_pollWait() ->netpollblockへ
func (fd *FD) Accept() (int, syscall.Sockaddr, string, error) {
//無限ループ
for {
s, rsa, errcall, err := accept(fd.Sysfd) <-★
if err == nil {
return s, rsa, "", err
}
switch err {
case syscall.EAGAIN:
if fd.pd.pollable() {
if err = fd.pd.waitRead(fd.isFile); err == nil { <-★
continue
}
}
}
return -1, nil, errcall, err
}
}
ここでfd.pdはlistenの時のpoll_runtime_pollOpenで作成していたものです。
rg,wgともに0となっています。このrg,wgの挙動が重要になってきます。
waitReadから来たのでmodeは"r"となっていてrgを使用します。
func netpollblock(pd *pollDesc, mode int32, waitio bool) bool {
gpp := &pd.rg
if mode == 'w' {
gpp = &pd.wg
}
// set the gpp semaphore to pdWait
for {
old := *gpp
if old == pdReady {
*gpp = 0
return true
}
if old != 0 {
throw("runtime: double wait")
}
if atomic.Casuintptr(gpp, 0, pdWait) { //①
break
}
}
// need to recheck error states after setting gpp to pdWait
// this is necessary because runtime_pollUnblock/runtime_pollSetDeadline/deadlineimpl
// do the opposite: store to closing/rd/wd, membarrier, load of rg/wg
if waitio || netpollcheckerr(pd, mode) == 0 {
gopark(netpollblockcommit, unsafe.Pointer(gpp), waitReasonIOWait, traceEvGoBlockNet, 5)
}
<-----------スケジューリングで復帰した後はここに戻ってくる
// be careful to not lose concurrent pdReady notification
old := atomic.Xchguintptr(gpp, 0)
if old > pdWait {
throw("runtime: corrupted polldesc")
}
return old == pdReady
}
atomicCasuintptrは第一引数のポインタを参照した値と第二引数を比較して == であるなら第三引数を第一引数に代入します。
今回の例でいえば下記みたいな感じです。
if *gpp = 0{
*gpp = pdWait
}
goparkへ
goparkではgoparkの第一引数に与えられた関数を実行し、schedule()を呼び出しスケジューリングをします。
func gopark(unlockf func(*g, unsafe.Pointer) bool, lock unsafe.Pointer, reason waitReason, traceEv byte, traceskip int) {
if reason != waitReasonSleep {
checkTimeouts() // timeouts may expire while two goroutines keep the scheduler busy
}
mp := acquirem()
gp := mp.curg
status := readgstatus(gp)
if status != _Grunning && status != _Gscanrunning {
throw("gopark: bad g status")
}
mp.waitlock = lock
mp.waitunlockf = unlockf
gp.waitreason = reason
mp.waittraceev = traceEv
mp.waittraceskip = traceskip
releasem(mp)
// can't do anything that might move the G between Ms here.
mcall(park_m)
}
// park continuation on g0.
func park_m(gp *g) {
_g_ := getg()
if trace.enabled {
traceGoPark(_g_.m.waittraceev, _g_.m.waittraceskip)
}
casgstatus(gp, _Grunning, _Gwaiting)
dropg()
if fn := _g_.m.waitunlockf; fn != nil {
ok := fn(gp, _g_.m.waitlock) //ここのfnはgoparkの第一引数
_g_.m.waitunlockf = nil
_g_.m.waitlock = nil
if !ok {
if trace.enabled {
traceGoUnpark(gp, 2)
}
casgstatus(gp, _Gwaiting, _Grunnable)
execute(gp, true) // Schedule it back, never returns.
}
}
schedule() //ここでスケジューリング
}
goparkでnetpollblockcommitを実行してスケジューリング、スケジューリングで復帰した後はgoparkの直後となります。
netpollblockcommit
*gpp = pollDesc.rgなのでpollDesc.rgに現在のGをセット
func netpollblockcommit(gp *g, gpp unsafe.Pointer) bool {
return casuintptr((*uintptr)(gpp), pdWait, uintptr(unsafe.Pointer(gp)))
}
さてここまででスリープは終わりです。
次は実際にスケジューリングで起きるところを見てみましょう。
Step2 スケジューリングで新しいGを取ってくる
Gが次にスケジューリングされるためにはグローバルorGのローカルキューに入らなくてはいけませんでした。
epoll絡みではキューに入っているものを使う方法と、キューに入っていないものを使う方法の二つがあります。
- sysmonのnetpollでグローバルorローカルキューに追加、schedulerでキューからとってくる
- schedulerで直接netpollでとってくる、その場合GListの先頭だけ直接使い、後はグローバル、ローカルキューに入れる
なので結局はschedulerを使うわけですね。
なのでschedulerのところを見ていきます。
もっとscheduler,sysmonについて知りたい方へ
sheduler参考
sysmon参考
netpoll
netpollでepollWaitを利用してev.data=pdを取り出す,さらにpd.rgにはoldGが紐づいています。
func netpoll(delay int64) gList {
...
var events [128]epollevent
retry:
n := epollwait(epfd, &events[0], int32(len(events)), waitms)
...
var toRun gList
for i := int32(0); i < n; i++ {
ev := &events[i]
if ev.events == 0 {
continue
}
if *(**uintptr)(unsafe.Pointer(&ev.data)) == &netpollBreakRd {
if ev.events != _EPOLLIN {
println("runtime: netpoll: break fd ready for", ev.events)
throw("runtime: netpoll: break fd ready for something unexpected")
}
if delay != 0 {
// netpollBreak could be picked up by a
// nonblocking poll. Only read the byte
// if blocking.
var tmp [16]byte
read(int32(netpollBreakRd), noescape(unsafe.Pointer(&tmp[0])), int32(len(tmp)))
atomic.Store(&netpollWakeSig, 0)
}
continue
}
★ここからlistenFDの時
var mode int32
if ev.events&(_EPOLLIN|_EPOLLRDHUP|_EPOLLHUP|_EPOLLERR) != 0 {
mode += 'r'
}
if ev.events&(_EPOLLOUT|_EPOLLHUP|_EPOLLERR) != 0 {
mode += 'w'
}
if mode != 0 {
pd := *(**pollDesc)(unsafe.Pointer(&ev.data)) <-★
pd.everr = false
if ev.events == _EPOLLERR {
pd.everr = true
}
netpollready(&toRun, pd, mode)
}
}
return toRun
}
func netpollready(toRun *gList, pd *pollDesc, mode int32) {
var rg, wg *g
if mode == 'r' || mode == 'r'+'w' {
rg = netpollunblock(pd, 'r', true)
}
if mode == 'w' || mode == 'r'+'w' {
wg = netpollunblock(pd, 'w', true)
}
if rg != nil {
toRun.push(rg)
}
if wg != nil {
toRun.push(wg)
}
}
func netpollunblock(pd *pollDesc, mode int32, ioready bool) *g {
gpp := &pd.rg
if mode == 'w' {
gpp = &pd.wg
}
for {
old := *gpp
if old == pdReady {
return nil
}
if old == 0 && !ioready {
// Only set READY for ioready. runtime_pollWait
// will check for timeout/cancel before waiting.
return nil
}
var new uintptr
if ioready {
new = pdReady
}
if atomic.Casuintptr(gpp, old, new) {
if old == pdReady || old == pdWait {
old = 0
}
return (*g)(unsafe.Pointer(old))
}
}
}
atomic.Castuintptrはpd.rg、またはpd.wgにpdReadyを入れてgoparkでGがセットされる前に戻します。
ここで取り出したpd.rgにはoldGがセットされていて、return (*g)(unsafe.Pointer(old))であるようにGを取得できます。
それで取り出したGはtoRunに入り、toRunにacceptで中断していたGが入ります。
ここではnetpollはschedule() -> findrunnable()から呼び出したとして見てみます。
詳しくはみませんがゲットしたGを使ってexecuteすることでそのGの前回中断したところから実行しなおします。
schedule
func schedule() {
...
//グローバルキューから探す
if gp == nil {
// Check the global runnable queue once in a while to ensure fairness.
// Otherwise two goroutines can completely occupy the local runqueue
// by constantly respawning each other.
if _g_.m.p.ptr().schedtick%61 == 0 && sched.runqsize > 0 {
lock(&sched.lock)
gp = globrunqget(_g_.m.p.ptr(), 1)
unlock(&sched.lock)
}
}
//ローカルキューから探す
if gp == nil {
gp, inheritTime = runqget(_g_.m.p.ptr())
// We can see gp != nil here even if the M is spinning,
// if checkTimers added a local goroutine via goready.
}
if gp == nil {
gp, inheritTime = findrunnable() // blocks until work is available
}
...
execute(gp, inheritTime)
}
func findrunnable() (gp *g, inheritTime bool) {
...
if netpollinited() && atomic.Load(&netpollWaiters) > 0 && atomic.Load64(&sched.lastpoll) != 0 {
if list := netpoll(0); !list.empty() { // non-blocking <-ここからnetpollが呼ばれる
gp := list.pop()
injectglist(&list)
casgstatus(gp, _Gwaiting, _Grunnable)
if trace.enabled {
traceGoUnpark(gp, 0)
}
return gp, false
}
}
...
}
スケジューリング終了後、fd.Acceptへ戻る
ここまで来てやっとnetpollblockのgoparkで中断したところに戻り、fd.Accept()の無限ループに戻ります。
戻った後はepollでlistenのfdが準備完了ということがわかっているのでacceptが正しく返ります。
func (fd *FD) Accept() (int, syscall.Sockaddr, string, error) {
...
//無限ループ
for {
s, rsa, errcall, err := accept(fd.Sysfd) <-★ これが成功する!
if err == nil {
return s, rsa, "", err
}
switch err {
case syscall.EINTR:
continue
case syscall.EAGAIN:
if fd.pd.pollable() {
if err = fd.pd.waitRead(fd.isFile); err == nil {
continue
}
}
case syscall.ECONNABORTED:
// This means that a socket on the listen
// queue was closed before we Accept()ed it;
// it's a silly error, so try again.
continue
}
return -1, nil, errcall, err
}
}
そのあとはserver.Serveの無限ループに返り、
Serveの本体の無限ループでまたAcceptでlistenのfdの準備完了待ちと、
新しいGを作りコネクション処理に分岐します。
func (srv *Server) ListenAndServe() error {
if srv.shuttingDown() {
return ErrServerClosed
}
addr := srv.Addr
if addr == "" {
addr = ":http"
}
ln, err := net.Listen("tcp", addr) <-★
if err != nil {
return err
}
return srv.Serve(ln)
}
func (srv *Server) Serve(l net.Listener) error {
...
ctx := context.WithValue(baseCtx, ServerContextKey, srv)
for {
rw, err := l.Accept()
...
c := srv.newConn(rw)
c.setState(c.rwc, StateNew, runHooks) // before Serve can return
go c.serve(connCtx)
}
}
acceptまとめ
結局epollやらschedulerをつかってacceptを非同期にして何をしたかったのでしょうか。
acceptが同期でlistenFDの準備完了を待ってその間Goroutineが動かないままとするのではなく、
acceptを非同期にしてGoroutineのコンテキストスイッチをしその間他のGroutineをうごかし、
listenFDが準備完了したらepoll_waitでGoroutineを復帰させるというのがaccept非同期化の目標でした。(間違ってたらそっと教えてあげてください。)
この非同期化は次回のコネクション処理、コネクションの書き込み、読み込みでも使いますのでGoroutineのコンテキストスイッチを押さえたうえで次回、本命のコネクション処理について見ていきましょう。
次回
まだ(10/10までにあげられたらいいな)
Discussion