暗号資産の価格予測: ビットコインとアルトコインの相関を利用した機械学習モデルの構築(python, scikit-learn)
目次
-
開発環境
-
はじめに
1.1 投資対象としての暗号資産
1.2 目標と収益率予測モデルの概要
1.3 価格変動予測ロジック -
データの準備
2.1 暗号資産の価格データの取得
2.2 データの前処理
2.3 データの統合 -
対数収益率の計算
3.1 特定の時間間隔での対数収益率の計算
3.2 相関係数の計算 -
収益率予測モデルの構築
4.1 scikit-learnを用いた単回帰モデル
4.2 単回帰モデルの評価
4.3 単回帰モデルの拡張 -
モデルの評価と最適化
5.1 複数のアルトコインでの評価
5.2 複数の時間間隔ごとの評価
5.3 複数通貨、複数時間間隔でのモデル構築&評価
5.4 複数通貨、複数時間間隔でのモデル評価のチャート化 -
結論と展望
6.1 収益率予測モデルの有用性
6.2 今後の展望
0. 開発環境
Google Colaboratory
1. はじめに
1.1 投資対象としての暗号資産
暗号資産市場は急速に成長し、今やプロの投資家やトレーダーのみならず、一般の投資家等にとってもメジャーな存在となりました。特に暗号資産市場の主要コインであるビットコインは、今日、その価格変動が金融市場全体にも大きな影響を及ぼしています。
2023年の今日において、暗号資産はますます注目を集め、有望な投資先の一つとなっています。そのビットコインをはじめとした各暗号資産の価格動向を分析し、価格変動を予測することができれば、非常に有用な投資情報となります。
1.2 目標と収益率予測モデルの概要
本記事では、ビットコインと他のアルトコイン[1]の価格変動をインプットデータとして、各暗号資産の価格変動を予測するモデルを構築します。具体的には、ビットコインの価格変動がアルトコインに与える影響を分析し、単回帰モデルを用いてアルトコインの価格変動の推計を行います。最終的な目標は、他のアルトコインの価格変動がビットコインにどの程度連動しているかを評価し、投資の意思決定に活用することです。
1.3 価格変動予測ロジック
今回はビットコインの価格変動をインプットとして他のアルトコインの価格変動を予測します。簡単に何故そのようなロジックを採用したかに触れておきます。
暗号資産市場に慣れ親しんでいる方は実感としてご存じの方も多いと思いますが、多くの暗号資産はビットコインの価格変動に強く影響を受けます。よって、一定時間内のビットコインの価格変動に、他のアルトコインの価格変動も連動すると考えられるため、ビットコインの価格変動をインプットとして他のアルトコインの価格変動を予測する単回帰モデルを構築することでできると考えています。
2. データの準備
2.1 暗号資産の価格データの取得
最初にビットコイン(BTC)および他の主要なアルトコインの1分ごとの価格データを準備します。ここでは、暗号資産取引所のBinanceから提供されるAPIを使用してBTCおよびアルトコインの価格を取得します。今回価格を取得するアルトコインは時価総額等を参考に以下の9種類を選定しました。
- イーサリアム(ETH)
- カルダノ(ADA)
- ソラナ(SOL)
- エックスアールピー(XRP)
- バイナンスコイン(BNB)
- ドージコイン(DOGE)
- アバランチ(AVAX)
- トロン(TRX)
- ポリゴン(MATIC)
具体的には以下のようなcsvデータを準備しました。なお、価格の単位はUSDTです。
| DATE | TIME | BTC | ETH | ADA | SOL | XRP | BNB | DOGE | AVAX | TRX | MATIC |
|---|---|---|---|---|---|---|---|---|---|---|---|
| 2023/9/13 | 23:37:01 | 26283.34 | 1608.33 | 0.2494 | 18.19 | 0.4826 | 212.5 | 0.06132 | 9.26 | 0.08112 | 0.5133 |
| 2023/9/13 | 23:38:06 | 26197.76 | 1604.24 | 0.2489 | 18.16 | 0.4819 | 212.2 | 0.06125 | 9.25 | 0.08111 | 0.5129 |
| 2023/9/13 | 23:39:01 | 26203.03 | 1605.4 | 0.2493 | 18.16 | 0.4821 | 212.3 | 0.06133 | 9.27 | 0.08113 | 0.5136 |
| 2023/9/13 | 23:40:11 | 26229.99 | 1606.71 | 0.2493 | 18.21 | 0.4824 | 212.4 | 0.06136 | 9.28 | 0.08119 | 0.5142 |
| 2023/9/13 | 23:41:05 | 26234.45 | 1607.31 | 0.2493 | 18.22 | 0.483 | 212.5 | 0.06134 | 9.28 | 0.08117 | 0.514 |
2.2 データの前処理
暗号資産の価格データの前処理を行います。上記に示した通り、価格データは取得日付(DATE
)と時刻(TIME)ごとに整理されています。上記データはGoogle Driveのcryptoフォルダにprice_list.csvとして保存してあります。

まずは、このファイルをデータフレームとして読み込み、データフレームの中身を確認します。今後の処理を進めるにあたって、秒数は00秒で統一する必要があるため、全て00秒で統一し、再度データフレームの中身を確認します。
最後にprice_list_adjust.csvとして、同じフォルダに保存します。
import pandas as pd
# price_listをdfに読み込み
df = pd.read_csv('/content/drive/My Drive/crypto/price_list.csv')
# dfの中身を確認
print('df(=price_list)の中身確認\n')
print(df.head)
# '時間'カラムを日時型(datetime)に変換
df['TIME'] = pd.to_datetime(df['TIME'], format='%H:%M:%S')
# 秒数(SS)を0に設定
df['TIME'] = df['TIME'].apply(lambda x: x.replace(second=0))
# DATE列に対して0埋めして2桁の形式に変換
df['DATE'] = pd.to_datetime(df['DATE'], format='%Y/%m/%d').dt.strftime('%Y/%m/%d')
# TIME列の日付部分を削除し、時間データのみ保持
df['TIME'] = df['TIME'].dt.strftime('%H:%M:%S')
# 結果を表示
print('秒数を0にそろえたdf(=price_list)の中身確認\n')
print(df)
# 調整後dfをprice_list_adjustとして保存
df.to_csv('/content/drive/My Drive/crypto/price_list_adjust.csv', index=False)
実行結果(一部省略)
df(=price_list)の中身確認
DATE TIME BTC ETH ADA SOL XRP BNB \
0 2023/9/13 23:37:01 26283.34 1608.33 0.2494 18.19 0.4826 212.5
1 2023/9/13 23:38:06 26197.76 1604.24 0.2489 18.16 0.4819 212.2
2 2023/9/13 23:39:01 26203.03 1605.40 0.2493 18.16 0.4821 212.3
3 2023/9/13 23:40:11 26229.99 1606.71 0.2493 18.21 0.4824 212.4
4 2023/9/13 23:41:05 26234.45 1607.31 0.2493 18.22 0.4830 212.5
... ... ... ... ... ... ... ... ...
23847 2023/9/30 23:55:12 27000.00 1682.52 0.2512 21.44 0.5162 215.6
23848 2023/9/30 23:56:05 27000.00 1682.28 0.2512 21.35 0.5163 215.5
23849 2023/9/30 23:57:14 26993.78 1681.67 0.2511 21.31 0.5160 215.5
23850 2023/9/30 23:58:08 26993.78 1681.73 0.2511 21.30 0.5159 215.4
23851 2023/9/30 23:59:01 26992.39 1681.60 0.2511 21.31 0.5159 215.4
[23852 rows x 12 columns]>
秒数を0にそろえたdf(=price_list_adjust)の中身確認
DATE TIME BTC ETH ADA SOL XRP BNB \
0 2023/09/13 23:37:00 26283.34 1608.33 0.2494 18.19 0.4826 212.5
1 2023/09/13 23:38:00 26197.76 1604.24 0.2489 18.16 0.4819 212.2
2 2023/09/13 23:39:00 26203.03 1605.40 0.2493 18.16 0.4821 212.3
3 2023/09/13 23:40:00 26229.99 1606.71 0.2493 18.21 0.4824 212.4
4 2023/09/13 23:41:00 26234.45 1607.31 0.2493 18.22 0.4830 212.5
... ... ... ... ... ... ... ... ...
23847 2023/09/30 23:55:00 27000.00 1682.52 0.2512 21.44 0.5162 215.6
23848 2023/09/30 23:56:00 27000.00 1682.28 0.2512 21.35 0.5163 215.5
23849 2023/09/30 23:57:00 26993.78 1681.67 0.2511 21.31 0.5160 215.5
23850 2023/09/30 23:58:00 26993.78 1681.73 0.2511 21.30 0.5159 215.4
23851 2023/09/30 23:59:00 26992.39 1681.60 0.2511 21.31 0.5159 215.4
[23852 rows x 12 columns]
TIME列に記録された時間の秒数がすべて00秒でそろいました。
2.3 データの統合
引き続き、この調整後の価格リストを確認していきます。実はこの価格リストには不備があることがわかっています。具体的にはサーバーの不調等で価格が取得できていない時間帯が存在します。この価格リストだけを見て、存在しないデータを確認しようとすると非常に手間がかかります。そこで、漏れがない時間帯のリストを作成し、その時間帯と価格を紐づけることで価格データが欠損している時間帯を見極めます。
以下のコードでは2023年9月14日から2023年9月30日までの時間帯リストを作成しています。
import pandas as pd
import datetime
# 開始日時と終了日時を設定
start_date = "2023-09-14 0:00:00"
end_date = "2023-09-30 23:59:00"
# 開始日時と終了日時をdatetime型に変換
start_datetime = datetime.datetime.strptime(start_date, "%Y-%m-%d %H:%M:%S")
end_datetime = datetime.datetime.strptime(end_date, "%Y-%m-%d %H:%M:%S")
# 1分ごとに増加させた日時のリストを生成
date_list = []
current_datetime = start_datetime
while current_datetime <= end_datetime:
date_list.append(current_datetime)
current_datetime += datetime.timedelta(minutes=1)
# データフレームを作成
df = pd.DataFrame({'DATE': [dt.strftime("%Y/%m/%d") for dt in date_list], 'TIME': [dt.strftime("%H:%M:%S") for dt in date_list]})
# CSVファイルとして保存
df.to_csv('/content/drive/My Drive/crypto/datetime.csv', index=False)
実行結果(datetime.csvの中身)
| DATE | TIME |
|---|---|
| 2023/9/14 | 0:00:00 |
| 2023/9/14 | 0:01:00 |
| 2023/9/14 | 0:02:00 |
| 2023/9/14 | 0:03:00 |
| 2023/9/14 | 0:04:00 |
| ・・・ | ・・・ |
| 2023/9/30 | 23:55:00 |
| 2023/9/30 | 23:56:00 |
| 2023/9/30 | 23:57:00 |
| 2023/9/30 | 23:58:00 |
| 2023/9/30 | 23:59:00 |
作成したdatetime.csvファイルに対して、先ほどのprice_list_adjust.csvファイルのデータをDATEとTIMEをキーにして左結合します。その後、欠損データのある時間帯を数えます。
import pandas as pd
# datetime.csvをdf1、price_list_adjust.csvをdf2として読み込む
df1 = pd.read_csv('/content/drive/My Drive/crypto/datetime.csv')
df2 = pd.read_csv('/content/drive/My Drive/crypto/price_list_adjust.csv')
# DATE,TIMEをキーにして左結合を実行
result_df = pd.merge(df1, df2, on=['DATE', 'TIME'], how='left')
# 結果を表示
print(result_df)
# 各行ごとにNaNが存在するかどうかを確認し、それをカウント
nan_row_count = result_df.isna().any(axis=1).sum()
print("NaNの行数:", nan_row_count)
# 結合結果をCSVファイルとして保存
result_df.to_csv('/content/drive/My Drive/crypto/merged_data.csv', index=False)
実行結果(一部省略)
[24480 rows x 12 columns]
NaNの行数: 651
統合したデータフレームは24,480行あり、そのうち651行のデータが欠損しています(欠損率2.7%)。
具体的に欠損している時間帯を確認するため、以下のコードで欠損値のある時間帯のみを抽出し、missing_data.csvとしてcsvファイルに保存して確認します。
import pandas as pd
# 結合したデータフレームを読み込む
merged_df = pd.read_csv('/content/drive/My Drive/crypto//merged_data.csv')
# 欠損値を持つ行を抽出
missing_data = merged_df[merged_df.isna().any(axis=1)]
# 欠損値のある行をCSVファイルとして保存
missing_data.to_csv('/content/drive/My Drive/crypto/missing_data.csv', index=False)
実行結果(一部省略)
| DATE | TIME | BTC | ETH | ADA | SOL | XRP | BNB | DOGE | AVAX | TRX | MATIC |
|---|---|---|---|---|---|---|---|---|---|---|---|
| 2023/9/14 | 17:43 | ||||||||||
| 2023/9/15 | 20:08 | ||||||||||
| 2023/9/15 | 22:19 | ||||||||||
| 2023/9/15 | 23:38 | ||||||||||
| 2023/9/16 | 0:49 |
missing_data.csvファイルを開いて確認すると確かに特定の時間帯で欠損データが存在することが確認できました。
このままでは、機械学習の際に支障が出るため、欠損データを線形補完します。
import pandas as pd
# 結合したデータフレームを読み込む
merged_df = pd.read_csv('/content/drive/My Drive/crypto/merged_data.csv')
# 欠損値のある行や列に対して、近くの値を使用して線形補完
fill_df = merged_df.interpolate()
# NaN行が存在するかどうかを確認
nan_row_count = fill_df.isna().any(axis=1).sum()
print("NaNの行数:", nan_row_count)
# 結合結果をCSVファイルとして保存
fill_df.to_csv('/content/drive/My Drive/crypto/fill_data.csv', index=False)
実行結果(一部省略)
NaNの行数: 0
上記の処理を行った結果、欠損データは綺麗に補完され、欠損データはなくなりました。
3. 対数収益率の計算
3.1 特定の時間間隔での対数収益率の計算
続いて、ビットコインおよび各アルトコインの特定の時間間隔での対数収益率を計算します。最終的には複数の時間間隔でモデルの精度を確認したいと思っていますが、まずは5分間での対数収益率を計算したデータフレームを準備します。
import pandas as pd
import numpy as np
# データの読み込み
data = pd.read_csv('/content/drive/My Drive/crypto/fill_data.csv')
# 10種類の暗号資産のカラム名をリストで作成
crypto_assets = ['BTC', 'ETH', 'ADA', 'SOL', 'XRP', 'BNB', 'DOGE', 'AVAX', 'TRX', 'MATIC']
# 5分前の価格を計算し、対数収益率を計算
for asset in crypto_assets:
data[f'{asset}_prev'] = data[asset].shift(5)
data[f'{asset}_return'] = (data[asset] / data[f'{asset}_prev']).apply(lambda x: 0 if pd.isna(x) or x == 0 else (np.log(x)))
# 初めの5行を削除
data = data.iloc[5:]
# 必要なカラムを選択
selected_columns = ['DATE', 'TIME'] + [f'{asset}_return' for asset in crypto_assets]
return_data = data[selected_columns]
print(return_data)
# CSVファイルに保存
return_data.to_csv('/content/drive/My Drive/crypto/returns_data.csv', index=False)
実行結果(一部省略)
DATE TIME BTC_return ETH_return ADA_return SOL_return \
5 2023/09/14 00:05:00 0.000792 0.000255 0.000000 0.002192
6 2023/09/14 00:06:00 0.001012 0.001134 0.000000 0.002191
7 2023/09/14 00:07:00 0.002103 0.002107 0.001607 0.003288
8 2023/09/14 00:08:00 0.002181 0.002318 0.000803 0.001642
9 2023/09/14 00:09:00 0.001426 0.001813 0.000803 0.001094
... ... ... ... ... ... ...
24475 2023/09/30 23:55:00 -0.000071 -0.000505 0.001195 0.007491
24476 2023/09/30 23:56:00 -0.000181 -0.000666 0.000796 -0.002806
24477 2023/09/30 23:57:00 -0.000260 -0.000767 0.000000 -0.003279
24478 2023/09/30 23:58:00 -0.000120 -0.000303 0.000000 -0.005151
24479 2023/09/30 23:59:00 -0.000282 -0.000357 -0.000398 -0.006082
各通貨の5分間での対数収益率の計算ができました。
3.2 相関係数の計算
計算した対数収益率データを用いて、ビットコインと各アルトコインの相関係数を計算します。これにより、ビットコインと他のアルトコインとの価格変動の関連性を把握します。
折角なのでチャート化ライブラリーSeabornを使って、グラフ化してみます。
import pandas as pd
import seaborn as sns
import matplotlib.pyplot as plt
from itertools import combinations
# データの読み込み
returns_data = pd.read_csv('/content/drive/My Drive/crypto/returns_data.csv')
# すべての暗号資産のリスト('DATE'と'TIME'を除く)
crypto_assets = ['BTC_return', 'ETH_return', 'ADA_return', 'SOL_return', 'XRP_return', 'BNB_return', 'DOGE_return', 'AVAX_return', 'TRX_return', 'MATIC_return']
# ヒートマップを描画
correlation_matrix = returns_data[crypto_assets].corr()
plt.figure(figsize=(10, 8))
sns.heatmap(correlation_matrix, annot=True, cmap='coolwarm', fmt=".2f", linewidths=.5)
plt.title('Correlation Heatmap')
plt.savefig('/content/drive/My Drive/crypto/correlation_heatmap.png')
plt.show()
# 散布図行列を描画
sns.set(style="ticks")
g = sns.pairplot(returns_data, vars=crypto_assets, diag_kind="kde", markers="o", plot_kws={'s': 7}) # マーカーサイズを70%に縮小
plt.savefig('/content/drive/My Drive/crypto/scatterplot_matrix.png')
plt.show()
実行結果(一部省略)
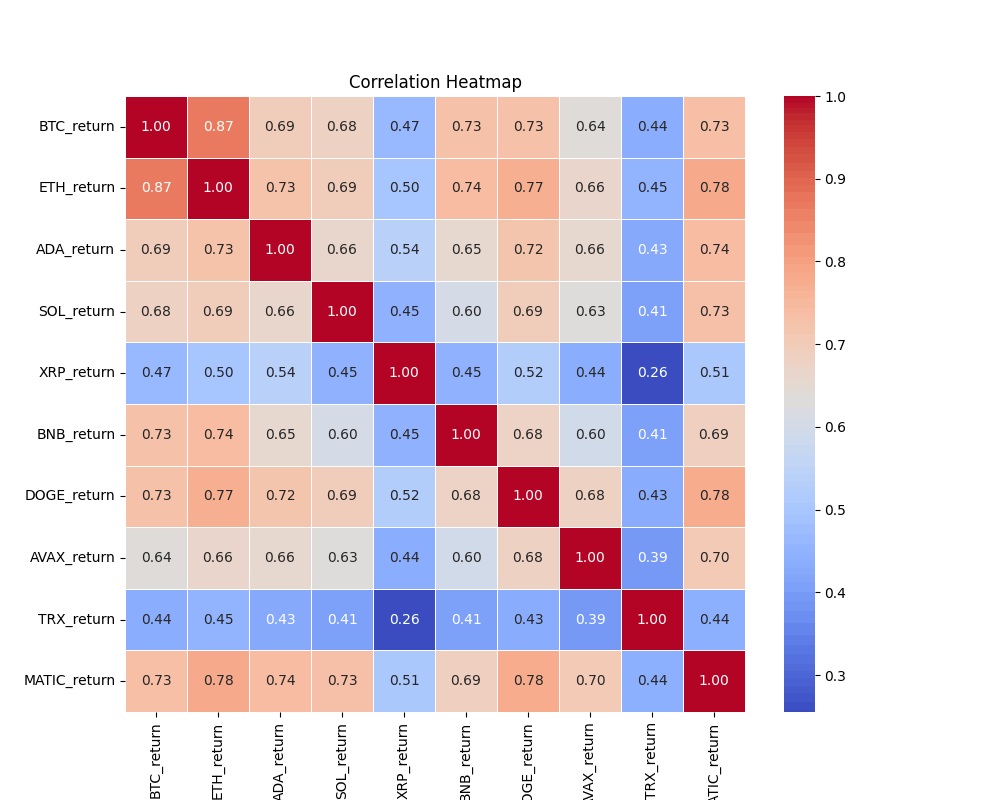
暗号資産の5分収益率の相関係数(correlation_heatmap)
暗号資産の5分収益率の散布図(scatterplot_matrix)

暗号資産の価格変動の相関を見ると、BTCと連動が高いのはETHであることがわかります(相関係数R = 0.87)。また、XRPはBTCとの相関が低いことが確認できます(相関係数R = 0.47)。これらの結果については、実感とも整合しますので、上手く相関係数の計算ができているかと思います。
4. 収益率予測モデルの構築
4.1 scikit-learnを用いた単回帰モデル
相関係数分析の結果、BTCとの5分間の対数収益率の相関が高いアルトコインはETHであることがわかりました。よって、ETHを単回帰モデルの対象として機械学習を進めます。
ここでは、scikit-learnの単回帰モデルを構築します。
単回帰モデル構築後は、RMSEと決定係数R^2によってモデルを評価します。
import pandas as pd
import numpy as np
import matplotlib.pyplot as plt
from sklearn.linear_model import LinearRegression
from sklearn.metrics import mean_squared_error, r2_score
from sklearn.model_selection import train_test_split
# データの読み込み
returns_data = pd.read_csv('/content/drive/My Drive/crypto/returns_data.csv')
# BTC_returnを説明変数、ETH_returnを目的変数として設定
X = returns_data[['BTC_return']]
y = returns_data['ETH_return']
# データの分割(学習データを80%、テストデータを20%に分割)
X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.2, random_state=0)
# 単回帰モデルの作成と学習
model = LinearRegression()
model.fit(X_train, y_train)
# モデルの予測
y_pred = model.predict(X_test)
# モデルの可視化
plt.scatter(X_test, y_test, alpha=0.5, label='Actual')
plt.plot(X_test, y_pred, color='red', linewidth=2, label='Predicted')
plt.title('Linear Regression Model')
plt.xlabel('BTC Return')
plt.ylabel('ETH Return')
plt.legend()
# チャートを画像ファイルとして保存
plt.savefig('/content/drive/My Drive/crypto/linear_regression_chart.png')
# モデルの評価
rmse = np.sqrt(mean_squared_error(y_test, y_pred))
r_squared = r2_score(y_test, y_pred)
print(f'RMSE: {rmse:.2f}')
print(f'R-squared: {r_squared:.2f}')
実行結果

RMSE: 0.00
R-squared: 0.77
4.2 単回帰モデルの評価
今回構築した単回帰モデルは決定係数が0.77という非常に高い精度が出ました。この結果は、BTCの5分間の対数収益率がわかれば、高い精度でETHの5分間の対数収益率が予測できると考えることができます。
4.3 単回帰モデルの拡張
前述の通り、BTCとETHの間において、5分間の対数収益率は高い精度で予測することが可能であることがわかりました。
次の章では、上記以外の組み合わせでもモデルを作成し、最も予測精度の高い組み合わせを探りたいと思います。
5. モデルの評価と最適化
5.1 複数のアルトコインでの評価
今回データを取得した10種類の暗号資産の価格データを用いて、モデルの構築を行います。BTCの対数収益率を説明変数とするので、実際にモデルを構築するのは残りの9通貨となります。
対象となる暗号資産(BTCは説明変数)
| BTC | ETH | ADA | SOL | XRP | BNB | DOGE | AVAX | TRX | MATIC | |
|---|---|---|---|---|---|---|---|---|---|---|
| 説明変数 | ✓ | - | - | - | - | - | - | - | - | - |
| 目的変数 | - | ✓ | ✓ | ✓ | ✓ | ✓ | ✓ | ✓ | ✓ | ✓ |
5.2 複数の時間間隔ごとの評価
これまでは5分間での対数収益率を出してきましたが、異なる時間間隔でもモデルを構築し、どの暗号資産の、どの程度の時間間隔でのモデルが最も予測精度が高くなるかを検討します。
対象とする時間間隔(min.)
| 5 | 15 | 30 | 60 | 120 | 180 | 360 | 720 | 1440 |
|---|
5.3 複数通貨、複数時間間隔でのモデル構築&評価
それでは複数通貨、複数時間間隔で対数収益率を算出し、そのそれぞれにおいてモデルを構築し、その精度を評価します。
import pandas as pd
import numpy as np
from sklearn.linear_model import LinearRegression
from sklearn.metrics import mean_squared_error, r2_score
from sklearn.model_selection import train_test_split
# オリジナルの価格データを読み込む
price_data = pd.read_csv('/content/drive/My Drive/crypto/fill_data.csv')
# 指定した時間間隔での対数収益率を計算する関数
def calculate_returns(data, interval_minutes):
returns = {}
for column in data.columns[2:]: # BTC以降の価格カラムを対象にする
returns[column] = np.log(data[column]).diff(interval_minutes)
return pd.DataFrame(returns)
# 異なる時間間隔でのモデル評価を行う
time_intervals = [5, 15, 30, 60, 120, 180, 360, 720, 1440] # 分単位
results = []
# 10通貨すべてに対してループ
for column in price_data.columns[2:]:
print(f"Evaluating for cryptocurrency: {column}")
for interval in time_intervals:
# 指定した時間間隔での対数収益率を計算
returns_data = calculate_returns(price_data.copy(), interval)
# 説明変数と目的変数の選択
X = returns_data[['BTC']]
y = returns_data[column] # 対応する仮想通貨の対数収益率
# 欠損値を含む行を削除
combined_data = pd.concat([X, y], axis=1)
combined_data.dropna(inplace=True)
# データの分割(学習データを80%、テストデータを20%に分割)
X_train, X_test, y_train, y_test = train_test_split(
combined_data[['BTC']],
combined_data[column],
test_size=0.2,
random_state=0
)
# 単回帰モデルの作成と学習
model = LinearRegression()
model.fit(X_train, y_train)
# モデルの評価
y_pred = model.predict(X_test)
rmse = np.sqrt(mean_squared_error(y_test, y_pred))
r_squared = r2_score(y_test, y_pred)
# 結果を保存
results.append({'Cryptocurrency': column, 'Interval (min)': interval, 'RMSE': rmse, 'R-squared': r_squared})
# 結果をデータフレームに変換
results_df = pd.DataFrame(results)
# 結果をCSVファイルに保存
results_df.to_csv('/content/drive/My Drive/crypto/model_evaluation_results.csv', index=False)
実行結果(一部省略;model_evaluation_results.csv)
Cryptocurrency Interval (min) RMSE R-squared
0 BTC 5 7.422228e-20 1.000000
1 BTC 15 3.146677e-19 1.000000
2 BTC 30 4.492239e-19 1.000000
3 BTC 60 1.255602e-18 1.000000
4 BTC 120 3.052413e-18 1.000000
.. ... ... ... ...
85 MATIC 120 3.470126e-03 0.557060
86 MATIC 180 4.056677e-03 0.574477
87 MATIC 360 5.517737e-03 0.568509
88 MATIC 720 7.378098e-03 0.617605
89 MATIC 1440 1.099235e-02 0.549804
全ての暗号資産、時間間隔での評価が終わりました。それぞれ精度に差があります。折角なので最後に全ての検証結果をチャート化します。
5.4 複数通貨、複数時間間隔でのモデル評価のチャート化
以下のコードで評価結果であるmodel_evaluation_results.csvをチャート化しています。各暗号資産ごとに最も精度の高かった時間間隔にその評価結果の値を付記しています。
なお、可視性を高めるため、横軸は対数スケールとなっています。
import pandas as pd
import matplotlib.pyplot as plt
import numpy as np
# データを読み込む
data = pd.read_csv('/content/drive/My Drive/crypto/model_evaluation_results.csv')
# BTCを除外
data = data[data['Cryptocurrency'] != 'BTC']
# インターバルごとにデータを分割
intervals = data['Interval (min)'].unique()
# グラフの初期化
plt.figure(figsize=(12, 6))
# 各通貨ごとに R-squared をプロット
for currency in data['Cryptocurrency'].unique():
currency_data = data[data['Cryptocurrency'] == currency]
max_r_squared = currency_data['R-squared'].max()
max_interval = currency_data[currency_data['R-squared'] == max_r_squared]['Interval (min)'].values[0]
plt.plot(currency_data['Interval (min)'], currency_data['R-squared'], marker='o', label=f'{currency} R-squared', linestyle='-')
plt.annotate(f'{currency} Max: {max_r_squared:.4f}', xy=(max_interval, max_r_squared), xytext=(max_interval, max_r_squared + 0.03))
# インターバルごとに縦線を引く
for interval in intervals:
plt.axvline(interval, color='gray', linestyle='--', linewidth=0.5)
# グラフの設定
plt.xscale('log') # X軸を対数軸に変更
plt.xlabel('Interval (min)')
plt.ylabel('R-squared Value')
plt.title('Cryptocurrency Model Evaluation (R-squared)')
plt.xticks(intervals, labels=[5, 15, 30, 60, 120, 180, 360, 720, 1440])
plt.ylim(0, 1.0) # Y軸の範囲を指定
plt.grid(True, linestyle='--', alpha=0.7)
plt.legend(loc='lower left') # Legendの位置を左下に指定
plt.tight_layout()
# グラフを保存
plt.savefig('/content/drive/My Drive/crypto/model_evaluation_results_graph.png', dpi=300)
# グラフを表示
plt.show()
実行結果(一部省略)
相関係数Rによる評価結果一覧(= model_evaluation_results.csv)
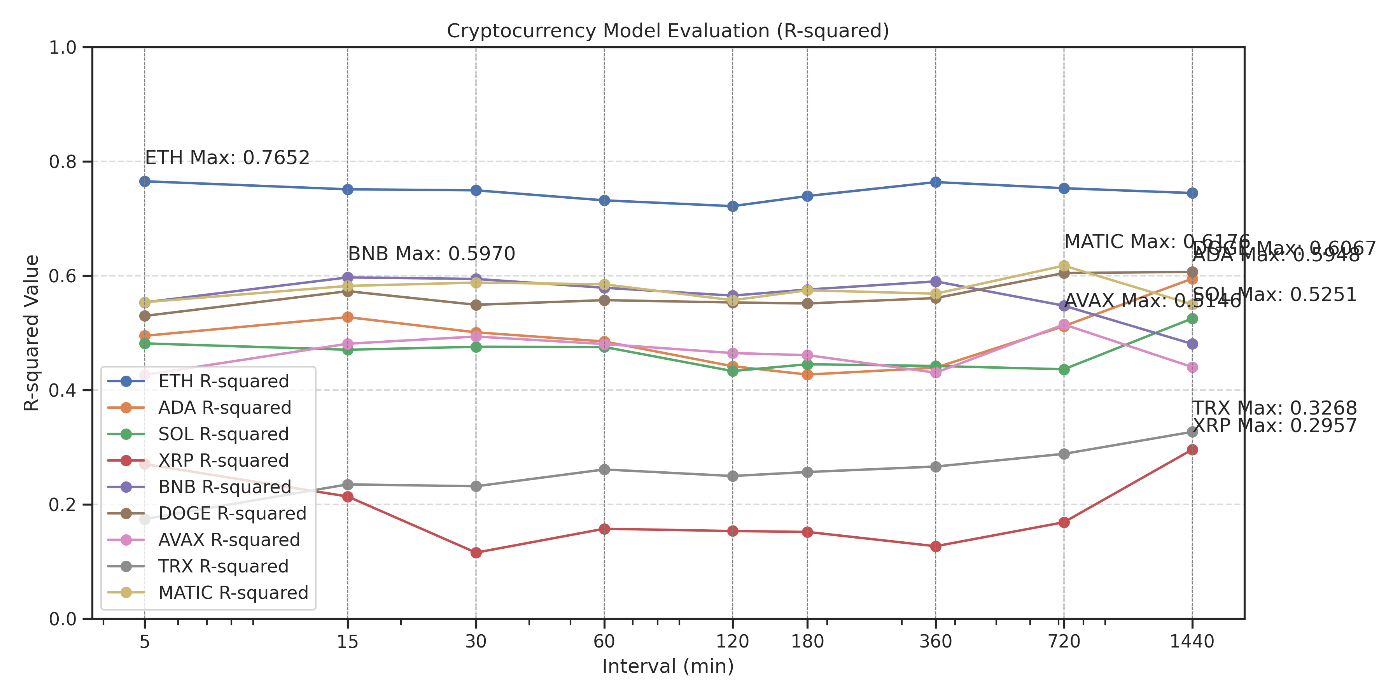
相関係数分析でも明らかになっていましたが、ETHが最も高い精度での価格予測が可能であり、時間間隔としてはサンプル的に実施した5分が最も高い精度が出ることがわかります。
その他の通貨についても時間間隔の差こそあれど、BTCとの対数収益率との相関は各暗号資産それぞれの特性によってモデルの予測精度が決まってくるようです。ただ、ETHと違ってBTCとの価格変動からの予測データでは720分~1440分あたりが精度が高くなっています。
6. 結論と展望
6.1 収益率予測モデルの有用性
今回構築した価格予測モデルが実際の投資判断にどの程度有用であるかについて考察します。
期間にして1か月にも満たないデータを用いて構築した収益性予測モデルですが、現時点での評価としては高い精度で予測ができていると考えられます。
さらに精度を上げるには学習データをさらに積み上げることが有用だと考えられます。
なお、今回対象とした9通貨以外に検討対象を広げるアプローチも考えられますが、時価総額が比較的小さいアルトコインは、今回対象としたコイン以上にボラティリティが高く、価格および収益性の安定性が低いため、候補を広げてもあまりいいモデルは構築できないと考えられます。
6.2 今後の展望
最後に、私の考える本モデルを用いた投資戦略について記述します。
今回はBTCの価格変化、すなわち収益性を捉え、他のアルトコインの収益性予測を行っています。仮に、BTCの収益性から予測されるアルトコインの収益性と実際の収益性に乖離がある場合、まだ十分にアルトコインの価格が変化していないことが予想されます。よって、比較的短い時間軸で当該乖離を解消する方向にアルトコインの価格が変化する可能性が高いと予測されるため、その機会を捉えれば短期的に収益を上げることができると考えています。
今回はモデルの構築および評価まででしたが、将来的には当該乖離が生じた際、SNS等でアラートを上げるBOT等を開発したいと考えています。
本記事が機械学習や暗号資産投資、そしてpythonに興味がある方にとって有用な記事となれば幸いです。
-
アルトコイン イーサリアムやXRP等のビットコイン以外の暗号資産の総称 ↩︎
Discussion