はじめに
エンジニアにならないと聞き覚えのない言葉「文字コード」
"UTF-8"とか"Shift_JIS"とか色々あるけど、
なんでいろんな文字コードがあるのか、なんで文字化けが生まれてくるのか、を説明できる自信がない。。。。
ということで、調べてみました!
文字コードの説明
文字コードって?
文字コードとは文字に割り当てた番号のことです。
文字をファイルに保存する時やインターネットでやり取りする時に、この番号で行います。
例えば、1=a、2=b、、、、26=zと決めておくと、
counterworksを3,15,21,14,20,5,18,23,15,18,11,19と表現することができます。
「いや、数字にすると文字数増えてるじゃん」って思われるかもしれませんが、数字しか扱えないコンピュータと文字を基本にしている人間とのコミュニケーションには、このような取り決めが必要になるのです。
ちなみに文字コードでは、10進数ではなく16進数が使われるのが基本です。
現在よく聞く文字コードは、"ASCII","Shift_JIS","UTF-8","UTF-16"あたりですかね。。。
少なくとも私が仕事中に聞くのはこの4つが多いです。
ASCII
ASCⅡは1963年に制定され、アルファベット・数字・記号などを1文字当たり7ビットで表します。
American Standard Code for Information Interchange(情報交換用米国標準コード)の略称でアスキーと読みます。
以下が変換表になります。
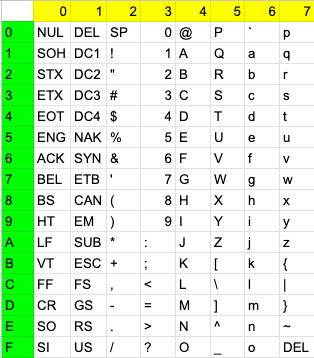
00~1Fになんかよくわからないものがありますよね。それが以下のようになっています。
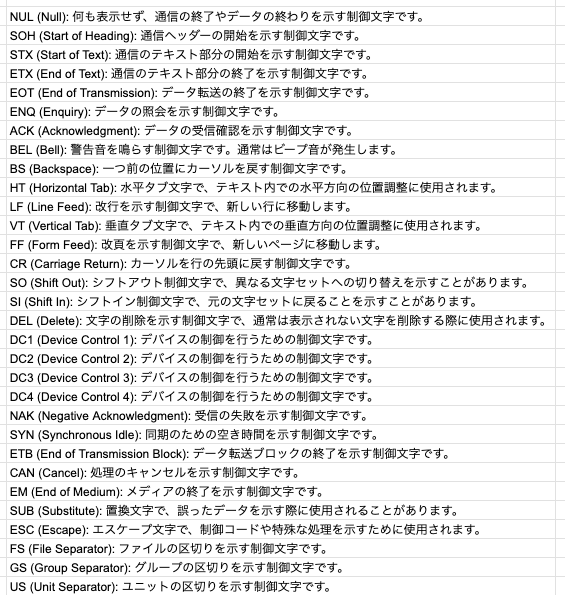
文字だけでは伝えられない改行などの動作を表しているようですね。
Shift_JIS
Shift_JISは、日本語の文字コードで、昭和57年(1982)にマイクロソフト、アスキー、三菱電機などが共同で開発したようです。SJISとも言われるようですね。
1バイト領域で表せる文字列と2バイト領域で表せる文字列が存在します。2バイトは主に漢字を表示するために使われるようです。
表せる文字数は約6万字程です。
さすがに全てを書き出すのは不可能なので、省略します。
エクセルはCSVファイルを開く際に 「Shift_JIS」 の文字コードを識別するされます。
エクセルでのCSVファイル読み込みで文字化けが多いのは、UFT-8でエンコードしたものをShift_JISで読み込んだので、対応していない文字が化けてしまうのです。
自分が業務の中で驚いたのは、ただのスペースなのに文字化けが起こったことです。
よくよく調べてみると、Shift_JISでは文字化けしてしまうスペースでした。
↓の
左側がShift_JISでは文字化けするスペースの文字コード
右側が私がフツーに打ったスペースの文字コード

(発明元のマイクロソフトもShift_JISからUNICODEベースの文字コードを使うように呼びかけています。この先日本語表記もShift_JISからUTF-8に主流がシフトして行くかもしれませんね。)
UTF-8
UTF-8は、世界的にポピュラーな文字コードで、Unicode用の符号化方式の1つです。ASCIIをUnicodeでそのまま使用することを目的として制定されました。
ASCII文字(0x00から0x7Fまでの範囲)は1バイトで表現され、半角かたかなは1文字3バイト,全角日本語は3~8バイトと可変長で表現されます。
Unicodeとは
下記で紹介しますが、日本語用の文字コード以外にも世界には様々な文字コードがあります。
その国々で独自の文字コードを使っていては、他国と仕事をするときに文字化けが頻発してしまいます。
そこで国際的な標準規格が制定されました。その一つがUnicodeです。
メジャーな言語のほとんどを網羅しており、貨幣記号などに使われる記号や絵文字も登録されています。
これにより言語が異なる国にデータを送っても、文字化けを恐れる心配が減りました。
UTF-16
UTF-8と同じで、Unicodeをそのまま使用するすることを目的として制定されました。
UFT-8は可変長で文字が表現される一方で、UTF-16では16bitで表現することが基本になっています。
UTF-16では、ほとんどの基本多言語面の文字は2バイト(16ビット)で表現されます。ただし、一部の文字は2バイト以上(サロゲートペア)で表現される場合もあります。
サロゲートペアとは
サロゲートペアを簡単に言うと、1つの文字に対し、2つの文字コードを使って表される文字を指します。
Unicodeでは、2byteで全ての文字を取り込む予定でした。しかし、それだけでは足りない文字もあるため、もっと多くの文字を表現するための新しい「場所」が必要になりました。
この新しい「場所」を表現するために、2つの2バイトの組み合わせ、つまり4バイトを使用することになりました。これにより、たくさんの新しい文字(約100万字)をコード化できるようになりました。
この4バイトの文字の表現方法を「サロゲートペア」と呼びます。
そのほかにも
Shift_JISが日本語を表記するための文字コードなら、諸外国専用の文字コードがあってもおかしくありません。
GB18030
中国語を主な対象とした文字コードです。
Big5
繁体字中国語を主な対象とした文字コードです。
KOI8-R, KOI8-U
ロシア語やウクライナ語のための文字コードです。
文字化けが起こる原因
先ほど説明した通り日本語をエンコードするにも"Shift_JIS”を使うか"UTF-8"を使うかで、エンコード後の数列が変わります。
例えば、「カウンターワークス」をShift_JISでエンコードすると、
83 4a 83 45 83 93 83 5e 81 5b 83 8f 81 5b 83 58
のようになります。
一方、UTF−8でエンコードすると、
e3 82 ab e3 82 a6 e3 83 b3 e3 82 bf e3 83 bc e3 83 af e3 83 bc e3 82 af e3 82 b9
全く違いますね!そりゃ文字化けもします。
実際にShift_JISでエンコードしたものをUTF-8でデコードすると
JE^[[NX
となりました。
逆にUTF-8でエンコードしたものをShift_JISでデコードすると、
繧ォ繧ヲ繝ウ繧ソ繝シ繝ッ繝シ繧ッ繧ケ
よく見る文字列が出てきました。
対処法はもうわかりますよね?
デコードで使う文字コードを適切なものに変更するだけです!
ちなみに
URLでよくみる%E3%82%AB%E3%82%A6%E3%83%B3%E3%82%BF%E3%83%BC%E3%83%AF%E3%83%BC%E3%82%AF%E3%82%B9は、URLエンコーディング(パーセントエンコーディング)と呼ばれる記法です。この形式は、URLやクエリパラメータで非ASCII文字や特殊文字を安全に伝送するために使用されるエンコーディング方式です。
UTF-8やShift_JISでエンコーディングした後に、URLエンコーディングされた文字列であると考えて問題ないと思います。
まとめ
今回は文字コードについてまとめてみました。
業務中にShift_JISが云々、UTF-8は云々という言葉が出てきた際にはなんとなく理解できそうですね。
追加
UTF−8でエンコードしたファイルでもBOMをつけることで、エクセルでも文字化けせずにデコードできるらしいです。
BOMとは
BOM(Byte Order Mark)は、テキストファイルの先頭に置かれる特殊なバイト列で、エンディアン(バイトの順序)を示すために使用されます。BOMがついていることで、このファイルがUTF-8で書かれていることが明記され、エクセルなどのソフトウェアが文字化けせずにファイルをデコードできるそうです。
しかし、「BOM」付けると動作や表示に不具合が出る可能性があるので、必要のない時にBOMをつける必要はなさそうです。
参考
よく見るやつ わかりやすく複数回にわたって文字コードについて紹介してくれています 一括でエンコード/デコードできるサイトです サロゲートペア入門です

ポップアップストアや催事イベント向けの商業スペースを簡単に予約できる「SHOPCOUNTER」と商業施設向けリーシングDXシステム「SHOPCOUNTER Enterprise」を運営しています。エンジニア採用強化中ですので、興味ある方はお気軽にご連絡ください! counterworks.co.jp/
Discussion