はじめに
株式会社コズム開発部、データアナリストの大塚です。
近年DX(デジタルトランスフォーメーション)が様々な業界から注目され、国からも推進されるなか、AIやデータ活用がその手段として重要視されています。
データアナリストは簡潔にいうと、そのデータ分析を行い、業務への活用を推進していく職種です。
今回は「専門知識が無くてもデータ分析はできるのか?」をテーマに、以下の方々を対象として情報を発信します。
- これからデータの仕事についていざ取り組もうとしている人
- ビジネス関係なく、データ分析に興味を持ち始めた人
少しでもお役に立てれば幸いです。
結論から申し上げますと、専門知識が無くてもデータ分析は行えます!
それではよろしくお願いいたします🙇🏻♂️
そもそも分析とは

広義:事象を細かく分けて新たな情報を見つけること
狭義:統計などを用いて事象を客観的に評価し、仮説検証や予測を行うこと
狭義の分析は言い換えると「データサイエンス」という、テクノロジーの発展によりビジネスで活用されるようになった学問や技術の事です。
本ブログで取り扱っていくのは、狭義の分析となります!
データの分析って難しそう…
私の回答は、「思っているほど難しくありません!」です 😄
それは以下の方法でデータ分析が出来るからです。
-
Excel(身近でとっつきやすい)
-
ChatGPT(よりお手軽)
専門知識やスキルがなくてもノーコードで分析できます。重要なのは分析結果がどう役立つかを想定する力です。
特にビジネスであれば自社やお客様ありきとなりますので、今後具体的に学んでいく事をお勧めいたします。以下がお勧めの書籍です。
分析するメリットとは?
大きいメリットがあります。例えばビジネスでは、以下のようなことが可能です。
-
意思決定の質の向上
データに基づく客観的な判断ができます。直感や経験に頼らないから質が向上すると言われがちですが、実際にはデータ分析と直感や経験は共存します。例えば、経験から特定の顧客が受注確度が高いと仮説を立て、それが統計的に有効であれば、その顧客にアクションを取るといった判断ができます。
-
視野を広げる (チャンスを見つける確率が上がる)
データ分析により、今まで意識していなかった重要な事柄に気づくことがあります。
例えば野球では、以前は打率が重視されていましたが、今では出塁率や長打率、OPS(出塁率+長打率)が重要視されています。
MLBのアスレチックスというチームは、このOPSを含む『セイバーメトリクス』を採用し、2001年と2002年にシーズン100勝を達成して注目を浴びました。
👍 この事が映画となった「マネーボール」も面白いのでおすすめです!
どうやれば分析力が身につく?
-
オープンデータを活用する
現在は、インターネットからオープンデータを簡単に取得できます。例えば、厚生労働省のホームページでは、コロナウイルスの感染者数や重傷者数のデータが公開されています。
-
統計を学ぶ
専門知識がなくても分析はできますが、統計を学ぶことは分析の練習になります。統計は分析の基礎であり、その知識は直接分析に役立ちます。
参考:統計学の時間
-
資格取得
分析を行うのに資格は必須ではないですが、「Python 3 エンジニア認定データ分析試験」が有名です。分析に加え、役立つ数学やプログラムも学べる為、効率の良い勉強になると思います。
分析の手法
今回はオープンデータ(重傷者数の推移)を使って、コロナの重傷者に関するフィクションの分析の練習を実際に行います。簡略版ですが、考え方やプロセスの参考になれば幸いです。
(練習のため、専門用語の解説やビジネス的な観点などはいくつか省略します🙇🏻♂️)
1. 目的、問題、仮説を設定する
【分析の目的】(今回は割愛)
【問題の定義】
コロナ流行時にG県のコロナでの重症者が多いという報道があったが、客観的に正しいのか
【仮説】
実はG県の人口当たりの重傷者数でみてみれば、多いとは言えないのではないか
2. 分析方法、データの種類、分析結果の活用方法を設定する
【分析方法】
2標本t検定
1群目:G県のコロナ重傷者数 / G県の人口
2郡目:D県のコロナ重傷者数 / D県の人口
【必要なデータ】
県ごとのコロナが原因の重傷者
【分析結果の活用方法】(今回は割愛)
3. 環境設定
今回はExcelを使って分析をしていきますので、その環境設定をしていきます。
3-1. データが入っているExcelを開き、「ファイル」タブ→「その他」→「オプション」→「アドイン」を選択
3-2. 管理ボックスで、「Excel アドイン」を選択し、「設定」をクリック

3-3. 「分析ツール」にチェックを入れ、「OK」をクリック

3-4. Excel画面に戻り、「データ」タブの右に「データ分析」が追加されているのを確認(環境設定完了)

3-5. データの前処理
そのままのデータの状態では分析を出来ない場合がありますので、データをいじる必要があります。それを前処理といいます。
-
要らないデータを削除
今回必要なのは、「G県」と「D県」なので、それ以外の都道府県のデータを削除。
期間も2021年1月~12月の間のデータに限定し、それ以外の期間のデータを削除。
【削除前】

【削除後】
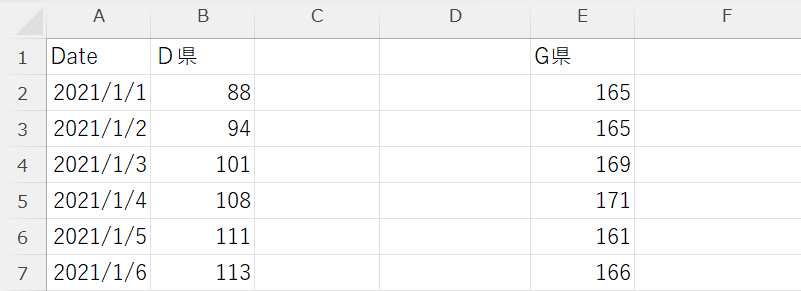
-
D県とG県の人口をそれぞれC列、F列に追加
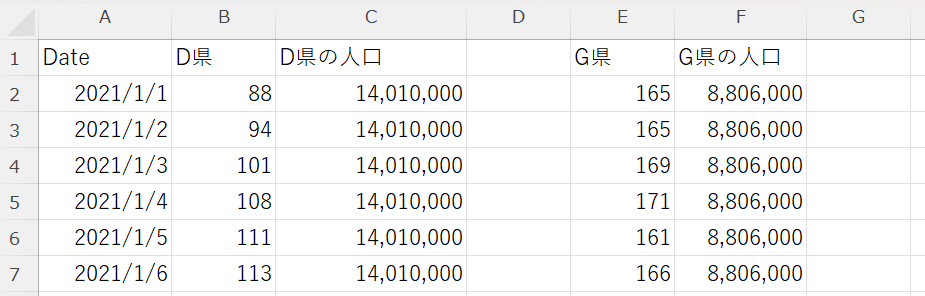
-
D県、G県それぞれの重傷者数を人口で割った値をD列、G列に入力する
D列:B列のセル ÷ C列のセル
G列:E列のセル ÷ F列のセル

4. 等分散性の検定
D列とG列の値を比較分析する前に、分散(各セルの値が平均からどれくらい離れているか)が等しいかどうかの検定を行います。つまりD列とG列の分散が同じ母集団から現れたかどうかを確認します。
4-1. Excelの「データ」タブの「データ分析」をクリック

4-2. 「分析ツール」から「F検定:2標本を使った分散の検定」を選択し、「OK」をクリック
4-3. 「変数1の入力範囲」にG列の値、「変数2の入力範囲」にD列の値を入力し、「OK」をクリック
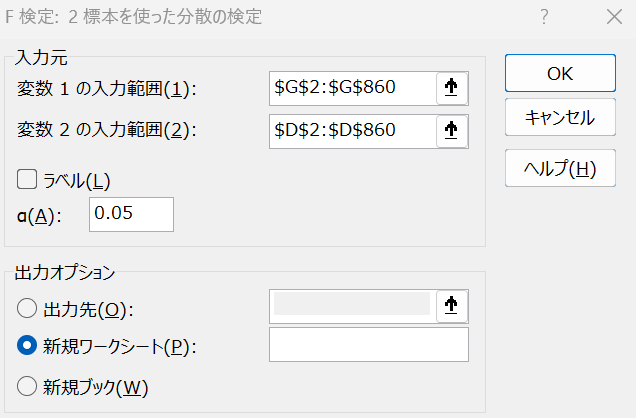
上記の0.05というのは有意水準と呼ばれる数字です。
検定後に出る「P値」が有意水準を下回れば、「G列とD列は等分散である」という仮定が棄却(否定)されます。
4-4. 分析結果の確認

「P(F<=f) 片側」が1.9224E-149と有意水準(0.05)よりも非常に小さいため、「G列とD列の値は等分散である」という仮定は棄却され、分散が等しいとは言えないと結論付けられました。
4-5. 2標本t検定
- Excelの「データ」タブの「データ分析」→「分析ツール」→「t検定:分散が等しくないと仮定した2標本による検定」を選択し、「OK」をクリック
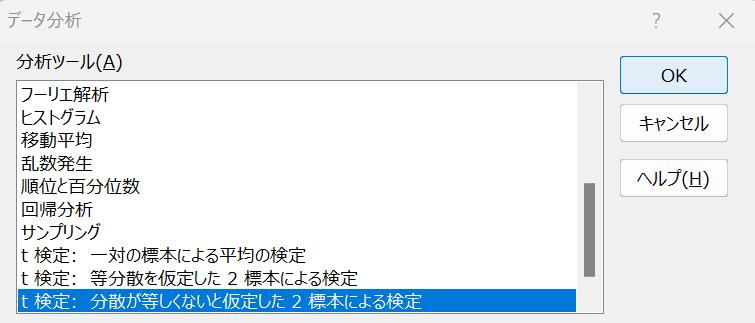
いくつかのt検定がありますが、等分散性の検定で「G列とD列の分散は等しくない」と結論付けたため、分散が等しくないと仮定したt検定を選択します。
- 「変数1の入力範囲」にG列の値、「変数2の入力範囲」にD列の値を入力し、「OK」をクリック

上記の0.05も有意水準です。
検定後P値が有意水準を下回れば、「G列とD列の値に差はない」という仮定が棄却されます。
- 分析結果の確認

「P(T<=t)片側」が6.54841E-54と有意水準(0.05)よりも非常に小さいため、「G列とD列の値に差はない」という仮定は棄却されました。つまり、「G県のコロナの重傷者数はD県と比較して多い」との結論が出ましたが、全ての分析結果の解釈には注意が必要です。
分析結果の解釈の注意点
「データ分析は、与えられたデータ同士の関係の強さしか測れない」という重要なポイントを紹介します。
上記の結果から「G県の重傷者数はD県より多い」と解釈するかもしれません。今回は「重傷者数」と「人口」で分析しましたが、それだけでは全てを判断できません。
重傷者数は「病床数」や「高齢者割合」などの要因にも影響されます。G県がD県より病床数が少ない、または高齢者が多い場合、そもそも比較は適切ではない可能性があります。
このように、データの解釈には注意が必要です。
おわりに
私が特にお伝えしたかったポイントは、以下の通りです。
- 専門知識が無くても、分析は可能。どんどんアウトプットしよう
- ビジネスで使う場合は分析がどのように役に立つのか事前に想像し、設定しておく
- 分析は与えられたデータ同士の関係の強さしか測れないので、分析の解釈は慎重に
長文となってしまいましたが、ここまで読んでいただき、誠にありがとうございました。
データ活用を志す方々の参考になれば幸いです。

株式会社コズムは「日本を代表する企業になる」というビジョンを掲げ、製造業をはじめ様々な業界にDX製品・ソリューションを提供し、お客様の課題解決を推進しています。スタートアップとして柔軟性を活かし、迅速な意思決定、先端技術への探求、情熱をもって、社会をクリエイティブな方向へ導くことで、大きなインパクトを与えていきます。
Discussion