ニコ生の開発環境が不足しがちなのでKubernetes/IstioとChrome機能拡張を使ってスケールするようにしてみた話
はじめに
この記事はドワンゴ Advent Calendar 2023の19日目の記事です。
昨日は@RyumaRyamaさんの「EC2とDiscordコマンドを活用したマイクラ鯖構築」でした。
ごあいさつ
ドワンゴでニコニコ生放送の開発を担当している @cornet_higashi です。クリスマスまで一週間を切りましたね。
今回はニコニコ生放送の開発において動作確認・検証に用いられている開発環境について、利用規模が大きくなっても破綻せずに運用できるような機構を構築したお話を書かせて頂きました。
なお、基本的にwebフロントエンド側の観点で書いており、主題と大きく関係のない内容・詳細な実装については省略していますのでご了承ください。
少々長くなりますが、どうか最後までお付き合い頂ければ幸いです。
背景
今回紹介する話は、我々が開発・保守を行なっているニコニコ生放送に関する内容です。
ご存じ、画面上に所狭しとコメントが流れるライブでストリーミングなサービスですね。サービス自体についての詳細な説明は下記のページを見て頂くとして、ここでは割愛します。
直面した課題や解決手段について説明する前に、まず前提知識としてニコニコ生放送での開発体制やアーキテクチャについて説明します。
この辺りは大体知ってる/興味が無いので早く本題に入りたい、という方はこちらからどうぞ。
ニコニコ生放送の開発体制
ニコニコ生放送の開発チームではサービスやシステムの品質を維持・改善するため、機能の追加や改善、コードのリファクタやマイグレーションなどを日々行っています。各々の開発案件も数ヶ月を要する大規模なものから、数日程度でリリースまで完了するものまで様々です。
主に開発に携わっているのは下記の3つの職種のメンバーになります。営業や番組制作など、広義の意味でニコニコ生放送に関わっているステークホルダーは他にも存在しますが、ここでは触れません。
-
企画職
- 案件のディレクション
- 要求定義
-
デザイナ職
- UI/UX設計
- デザインカンプ作成
-
エンジニア職
- コード設計・実装
- サーバ運用・保守
新規機能追加などの開発案件では、企画側で要求を定義し、デザイナ側でUI/UXを設計し、エンジニア側でコードを設計・実装するといった分担で開発を進めていきます。これらの境界は絶対というわけではなく、案件に応じて臨機応変に変わったりもします。
また、開発職についてはフロントエンド担当とバックエンド担当、更にフロントエンドの中でも開発対象のアプリケーション毎にチームが分かれていたりします。このあたりの詳細は後述します。
ニコニコ生放送のアーキテクチャ
次にニコニコ生放送というシステムの構成・運用についてざっと説明します。全ての領域や細かい話を色々と書き出すと収集が付かなくなるため、今回の話に関係の深い下記の事項に焦点を絞って書きます。
フロントエンドとバックエンド
大まかな構成としては、ユーザに表示するためのページを提供するフロントエンド側と、各種情報をAPIとして提供するバックエンド側に分かれています。
フロントエンド側にはBFF(Backend For Frontend)サーバが用意されており、ユーザ(クライアント)からのリクエスト内容に応じてバックエンド側から情報を取得し、これを整形・加工してユーザ側にレスポンスを返します。

フロントエンドの実行環境はNode.jsが採用されており、Express.js製のBFFサーバが稼働しています。ユーザからのリクエストはLB(Load Balancer)やRP(Reverse Proxy)を経由して、最初にここでハンドリングされます。
今回の話の主題との関係は薄いですが、フロントエンド側のBFF以外の領域であるwebクライアント側(webブラウザ上で動作するシステム部分)のアーキテクチャについては下記の資料に詳しい話が書かれています。技術スタックとしてはTypescript+React、MobXで状態管理といった構成です。
バックエンド側はマイクロサービスアーキテクチャを採用し、ScalaやGoで書かれた数十ものサービスが稼働しています。各々のサービスは、各種プロトコルでBFFサーバが利用するための情報を提供しています。
Kubernetesによるクラスタ管理
ニコニコ生放送のシステム上には、上で説明したBFFサーバなどを含めて数十を超えるサービスが稼働しています。これらのサービスが互いにやり取りを行い、ニコニコ生放送というシステムが成立しています。
従来はDocker Swarmを用いたクラスタリングによる運用を行っていましたが、拡張性や移行性などの都合から、現状はKubernetes(k8s) に移行して運用される形になりました。
上述したフロントエンドとバックエンドの各サービスは同一のKubernetesクラスタ上に共存し、namespaceを分けて運用されています。ニコニコ生放送のKubernetes移行については ニコニコ生放送 WebフロントエンドのKubernetes移行ハンドブック 2022 に詳しく記載されています。
上記資料のTypeScriptでManifestを生成するGeneratorのアーキテクチャにも記載がありますが、フロントエンド側で管理しているManifest(Kubernetesの各種リソースを定義するためのファイル)はそれ自体を直接変更・修正するのではなく、Typescriptのコードとconfig情報のjsonから専用のGeneratorを用いて生成するようになっているという特徴があります。
{
"env-a": {
"appVersion": "123.0.0",
"replicas": 2
},
"env-b": {
"appVersion": "124.0.0",
"replicas": 4
}
}
このようなconfigが各アプリケーション毎に用意されており、デプロイ対象のアプリケーションのバージョンやpodのreplicas数を指定することができるようになっています。必要なパラメータや設定を書き換えてManifest管理リポジトリに含まれるスクリプトを実行することで、各種Manifestが生成されます。

この機構を採用していることで、開発者は直接Manifestを触らなくても済むなど、多数のメリットを享受できる状態になっています。詳しくは上述の移行ハンドブックをご覧ください。
また、CD(Continuous Delivery)ツールとしてArgoCDが導入されており、Manifestを管理しているリポジトリにpushするだけでArgoCDがそれを監視し、自動でデプロイが行われるようになっています。
ページ(アプリケーション)単位での運用
ニコニコ生放送にはトップページや生放送番組視聴ページ、生放送番組作成ページなど複数のページが存在します。これらはページ毎に特性が異なることや、開発・保守を行っていく上での効率性などの都合から別々のアプリケーションとして運用しています。
フロントエンド側では、これらアプリケーション毎にリポジトリを分けて管理しています(いくつかのアプリケーションを集約したmonorepoとして管理しているリポジトリもあります)。各アプリケーションには担当チームが割り振られており、分担して開発やデプロイなどの作業を効率的に進められるようになっています。

また、アプリケーション毎にServiceやDeploymentなどのKubernetesリソースが用意されています。アプリケーションのDockerImageと静的リソースなどの成果物をCI上でビルド・生成し、それらに紐付いたkubernetesのManifestをgithub上にpushするといった流れでデプロイが行われます。
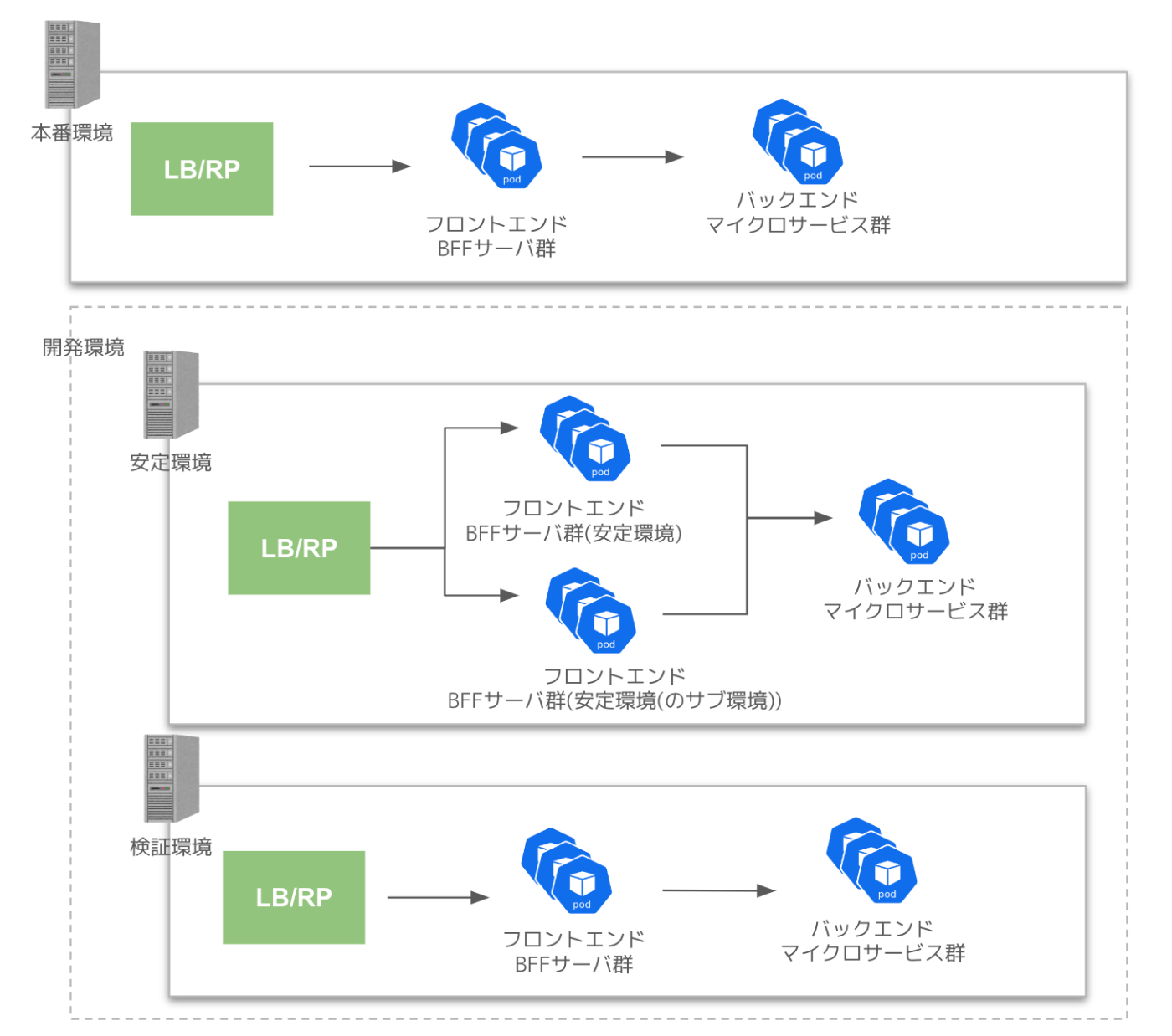
本番環境と開発環境
一般ユーザからのリクエストを受け付ける本番環境とは別に、社内からのみアクセス可能な開発環境と呼ばれる環境が存在します。開発環境はリリース前の動作確認や、各種検証などを行う際に用いられるものです。下記のような複数の種類が用意されています。
| 環境名 | 用途 | デプロイ対象 | 接続先のバックエンド |
|---|---|---|---|
| 安定環境 | リリース前の動作確認や他チームの結合確認 | 本番環境と同等のコード | 安定環境 |
| 安定環境(のサブ環境) | 案件の動作検証 | デプロイしたいブランチや特定バージョンのコード | 安定環境 |
| 検証環境 | 案件の動作検証 | デプロイしたいブランチや特定バージョンのコード | 検証環境 |
上記の環境を利用する際は、他の利用者や案件とバッティングしないように専用のカレンダーを管理表として用意し、用途・期間を入力する形で運用していました。

なお、検証環境が接続しているバックエンド側は構成上の都合から一部の機能が使えない状態になっており、そのような機能を含めて検証したい場合は安定環境(のサブ環境)が使われる状態になっていました。
開発における一連の流れ
新機能の開発を例に取ると、一般的な開発の流れとしては以下のようになります。
- 要求定義
- 要件定義
- 各種設計
- 開発・検証
- リリース
なお、画一的に上記の流れで進めると言うよりは、案件の特性に応じて適切な進め方を選択した上で案件を進行します。
例えば要件やスケジュールが明確である場合はウォーターフォール式に進めることもありますし、早い段階でプロトタイプを組んだ上で、議論を繰り返しながら成果物の品質を上げつつ完成させていくといったケースも存在します。
いずれにしても、実装がある程度完成した時点で開発環境にデプロイし、検証やQAテストを行う点は共通しています。検証を行う中で改善の余地があるとされた箇所については、検討・改善・実装した上で再度検証を行います。検証が完了し、リリースして問題なしとなった時点で対象の実装をアプリケーションのメインブランチにマージし、リリースを行います。
リリース後の保守・運用を別とすると、ここまでが基本的な開発フローです。
課題
だいぶ前置きが長くなりましたが、ここからが本題です。
ニコニコ生放送は関係するステークホルダーを含めると、数十名のメンバーで開発・運用が行なわれています。生放送開発チーム内で提案された案件の他、他のチームからの依頼を受けて開発を行うことも少なくありません。システムの保守のためのマイグレーション作業、改善作業なども必要です。これらが常時、複数のアプリケーションで発生します。
このような状況で開発のサイクルを回していく必要があるわけですが、当然複数の案件でリリース時期や検証時期などが被ってくるケースが発生します。比較的手が入りやすいアプリケーションだと、同時に4〜5件の案件が同時に回っているといった状況も珍しくありません。
各案件の検証を行うための環境について、以下のような課題が存在します。
これらについて順に説明していきましょう。
自由に環境を増やせるような構成になっていない
従来の構成では、環境毎にLBやRP、Kubernetesクラスタといったリソースのセットを用意する必要がありました。FQDNも環境毎に異なるものが割り当てられています。これを新しく増やそうと思うと、機材や環境毎の設定などのリソースが必要となるため気軽には行えません。一通りのアプリケーション・サービスも用意する必要があります。
また、仮に環境を増やそうとするとインフラ担当者の作業が必要になります。一部の作業はアプリケーション開発側で行うことも出来なくはないですが、どうしてもある程度の学習コストは必要になってきます。
環境の管理に手間がかかる
環境を増やすのが難しい以上、しばらくは検証環境や安定環境(サブ環境)を複数の案件で変わるがわる利用していました。これらで足りない場合は、安定環境を一時的に切り替えるなどして検証に用いていました。
ただ、いちいち管理表を手動で書き換えるのは手間がかかり、実際にデプロイされているバージョンと管理表の内容が一致していないようなタイミングが発生するのも防げません。
また、どうしても環境が足りず、時期が被ってしまうような場合は案件毎にスケジュールをずらして検証するといった調整も必要となります。その結果、リードタイムの悪化などのリスクが生じる結果となっていました。
利用する側のコミュニケーション・認知負荷が高い
環境を利用する側のコミュニケーションや認知面での負荷の問題もあります。
例えば任意の案件の検証を行いたいメンバーが、当該の修正がデプロイされている環境を知るためには上記の管理表を確認したり、あるいは実装担当者に都度確認しなければなりません。しかし前述の通り管理表の正確性に欠けたり、必要以上に関係者間のコミュニケーションコストが発生するという問題が生じていました。
また、この複数の環境という概念について、開発者以外には馴染みがあまり無いという点も運用の難しさを増幅させる要因でした。それぞれの環境がどういうもので何を指しているのか、新しいメンバーが入る度に説明が必要だったり、FQDNと環境の紐付けを忘れてしまうという状況も度々発生していました。
環境自体やそれを利用する運用が案件や人員の増加に対して、スケールしない状態になっていたというわけです。
やったこと
上で挙げた課題に対し、下記のアプローチで解決を図りました。
- 自由に環境を増やせるような構成になっていない
- 環境の管理に手間がかかる
- 利用する側のコミュニケーション・認知負荷が高い
k8s Manifestの自動生成とVirtualServiceのHTTP header based routingを用いて環境をスケーリングするようにする
冒頭でも説明した通り、ニコ生はKubernetesクラスタ上で動作しています。また、Typescriptで記述したパラメータとconfig情報のjsonを基にManifestをワンコマンドで生成できる仕組みが整っています。
今回はこれを拡張し、サブ環境(これ以降は自由にスケール可能な環境のことをこう呼びます)を配列の形で指定できるようなパラメータとして用意しました。
"env-a": {
"appVersion": "123.0.0",
"replicas": 2,
"subEnvSettings": [
{
"id": "migration-node",
"description": "node.jsのマイグレーション",
"version": "0.0.0-mn.0"
},
+ {
+ "id": "add-special-function",
+ "description": "画期的な機能追加",
+ "version": "0.0.0-asf.0"
+ },
]
}
仕組みとしては、上記のconfig設定のsubEnvSettingsを追加あるいは更新し、Manifestの生成コマンドを実行することで各サブ環境のリソースに対応するManifestが生成されるようになっています。
例として、ルーティング設定のManifestは以下のような形で更新されます。
kind: VirtualService
metadata:
name: page-x
namespace: front
spec:
gateways:
- niconama
hosts:
- "*"
http:
- name: http-page-x-migration-node
match:
- uri:
regex: /page-x/\d+
headers:
x-sub-env-id:
exact: migration-node
- uri:
regex: /page-x/\d+
queryParams:
subEnvId:
exact: migration-node
route:
- destination:
host: page-x-migration-node.front.svc.cluster.local
port:
number: 5678
+ - name: http-page-x-add-special-function
+ match:
+ - uri:
+ regex: /page-x/\d+
+ headers:
+ x-sub-env-id:
+ exact: add-special-function
+ - uri:
+ regex: /page-x/\d+
+ queryParams:
+ subEnvId:
+ exact: add-special-function
+ route:
+ - destination:
+ host: page-x-add-special-function.front.svc.cluster.local
+ port:
+ number: 5678
上記のManifestはVirtualServiceに関するものですが、DeploymentやServiceなどのリソースもセットで作成されます。
VirtualServiceはKubernetesのサービスメッシュを実現するソフトウェアであるIstioのリソースの一つで、トラフィックのルーティングを柔軟に行うことを可能にします。例えば任意のHTTP HeaderやURIのクエリパラメータに応じて、異なるupstreamにルーティングさせるといったことが可能です。
上の例では、match条件としてURIが/page-x/****の前提で、x-sub-env-id:add-special-functionのHTTP Header、あるいはsubEnvId=add-special-functionのクエリパラメータが付与されたリクエストの場合のみpage-x-add-special-function.front.svc.cluster.local:5678にルーティングされる設定が追加されています。これらはconfigに指定された各々のサブ環境毎のIDがmatch条件及びdestinationに自動で反映されるようになっています。
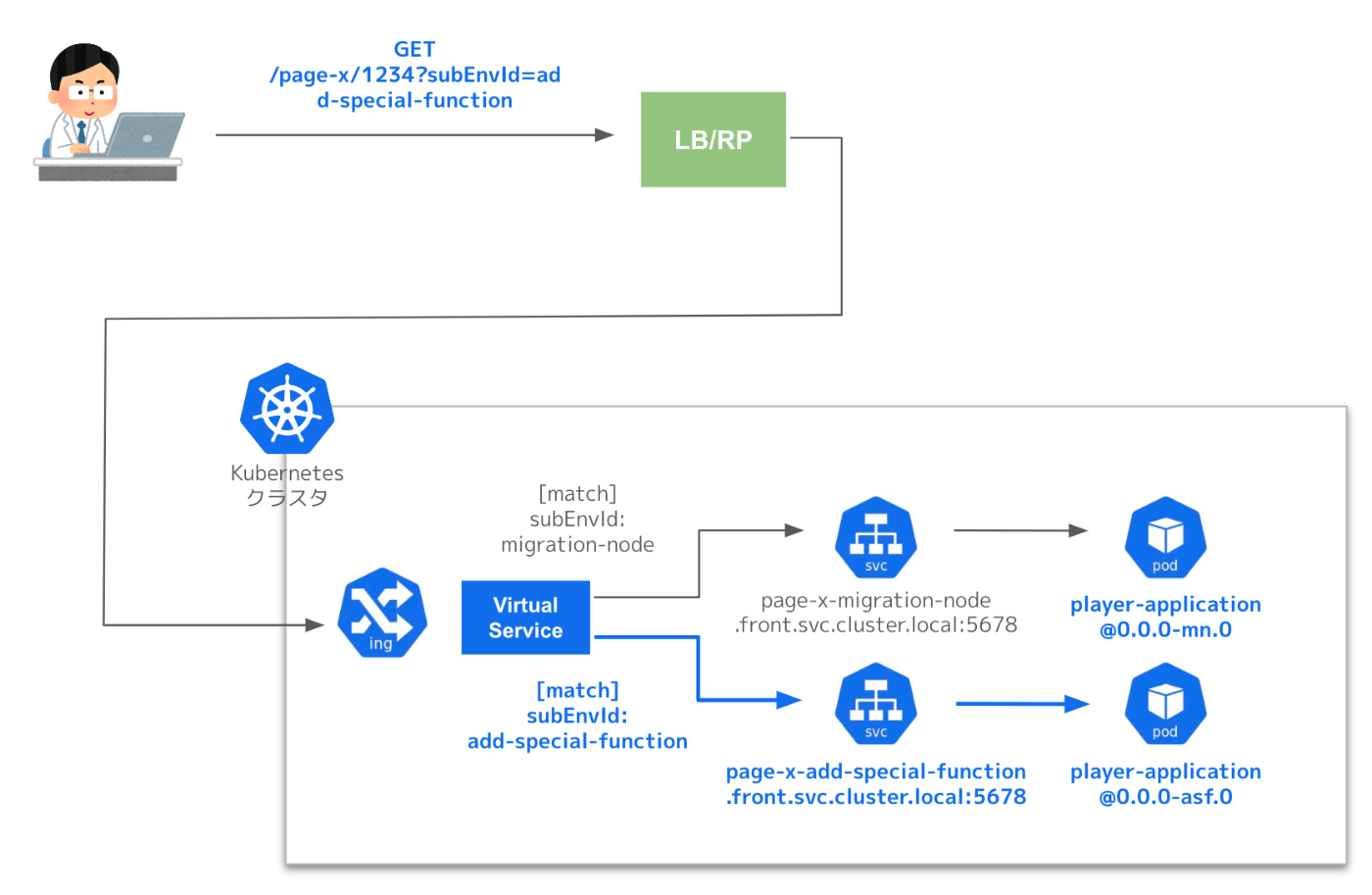
生成されたリソース群のManifestをgithub上のリポジトリにpushすると、ArgoCDによってKubernetesクラスタへのデプロイが自動で行われ、追加した環境が利用可能になります。環境の分岐部分のルーティングはVirtualServiceで完結するため、LBやRPの改修は不要です。
また、この仕組みは開発環境のみで利用可能となっているため、機構の導入要因でのセキュリティ的なリスクを生じさせないようにしています。
環境をconfigでmaster管理して生成をbotとSlackWorkflow経由で容易に行えるようにする
前述したconfigのsubEnvSettingsには実際にデプロイされるサブ環境についての情報が一通り含まれています。そのため、実際にデプロイされる環境のmaster情報として利用でき、カレンダーによる管理は不要となりました。従来必要だった利用スケジュールの情報も、今回の機構の前提では環境自体がバッティングすることがないため登録する必要はありません。
環境の追加が簡単に行えるようになったところで、可能であればconfigの書き換えやManifestの生成、デプロイについても楽をしたいところです。今回は、botとslackのワークフロー機能を利用して更新作業を簡略化しました。
ニコニコ生放送の開発においては業務効率化のためにNode.js製のbot(Bolt)で各種連携を行っており、ここにconfigの更新及びGithubへのpushを行うハンドラを追加しました。
生放送開発管理のサーバ上にboltのインスタンスが立っており、SlackのSocket Mode APIを通してSlackとのやり取りを行います。更新の際は、Slackのワークフローを経由してbot上でデプロイフローを実行します。これを図に表すと、以下の図のような構成になります。

Slackの特定のチャンネルに登録されているワークフローを実行すると、下記のようなダイアログが表示されます。
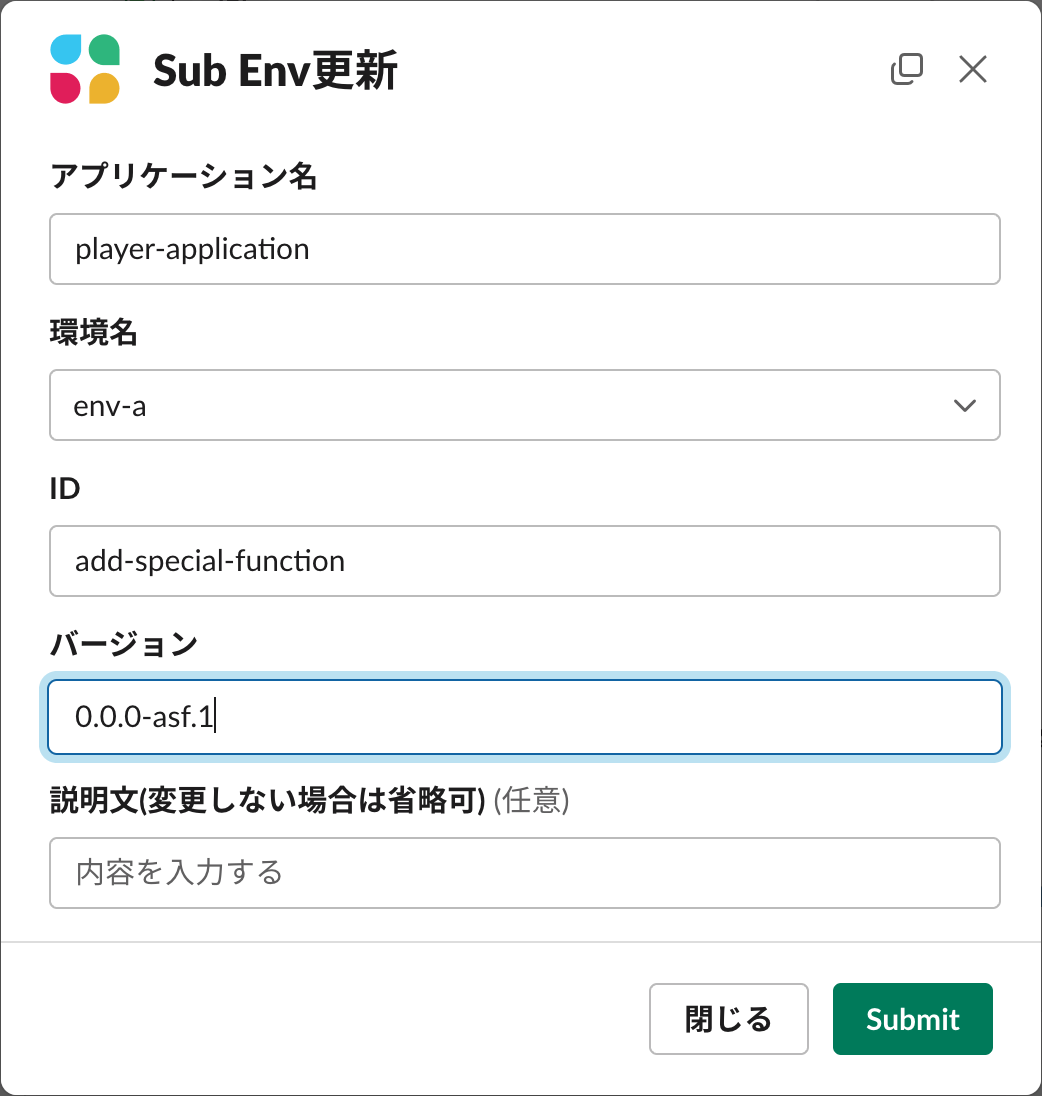
入力フォームに必要な事項を記入して実行すると、一連の作業が自動で実行され、最終的にサブ環境がデプロイされます。ワークフローは環境の作成・更新・削除に対応しているため、ここからの導線で一通りの作業が行えるようになっています。
Chrome機能拡張で利用したい環境を容易に認識・切り替えが行えるようにする
ここまでの機構で、Slack上から手軽に環境の生成・更新が行え、特定のHTTP Headerあるいはクエリパラメータを付与してアクセスすると案件毎の環境を利用できる状態になっています。
ただ、いちいちアクセスの度に案件に該当するパラメータを調べて、都度リクエストに付与しなければならないとなると面倒です。
ブラウザからのアクセスにおけるheaderの書き換え自体は既存のアドオンなどでも実現できますが、どのようなヘッダにどのような値を設定すべきかは環境を追加する毎に毎回設定しなければなりません。
そこで、色々考えてたら面倒になったのでもういいや作ってしまおう今回のユースケースに合致するようなChrome機能拡張を内製し、社内限定で公開することにしました。
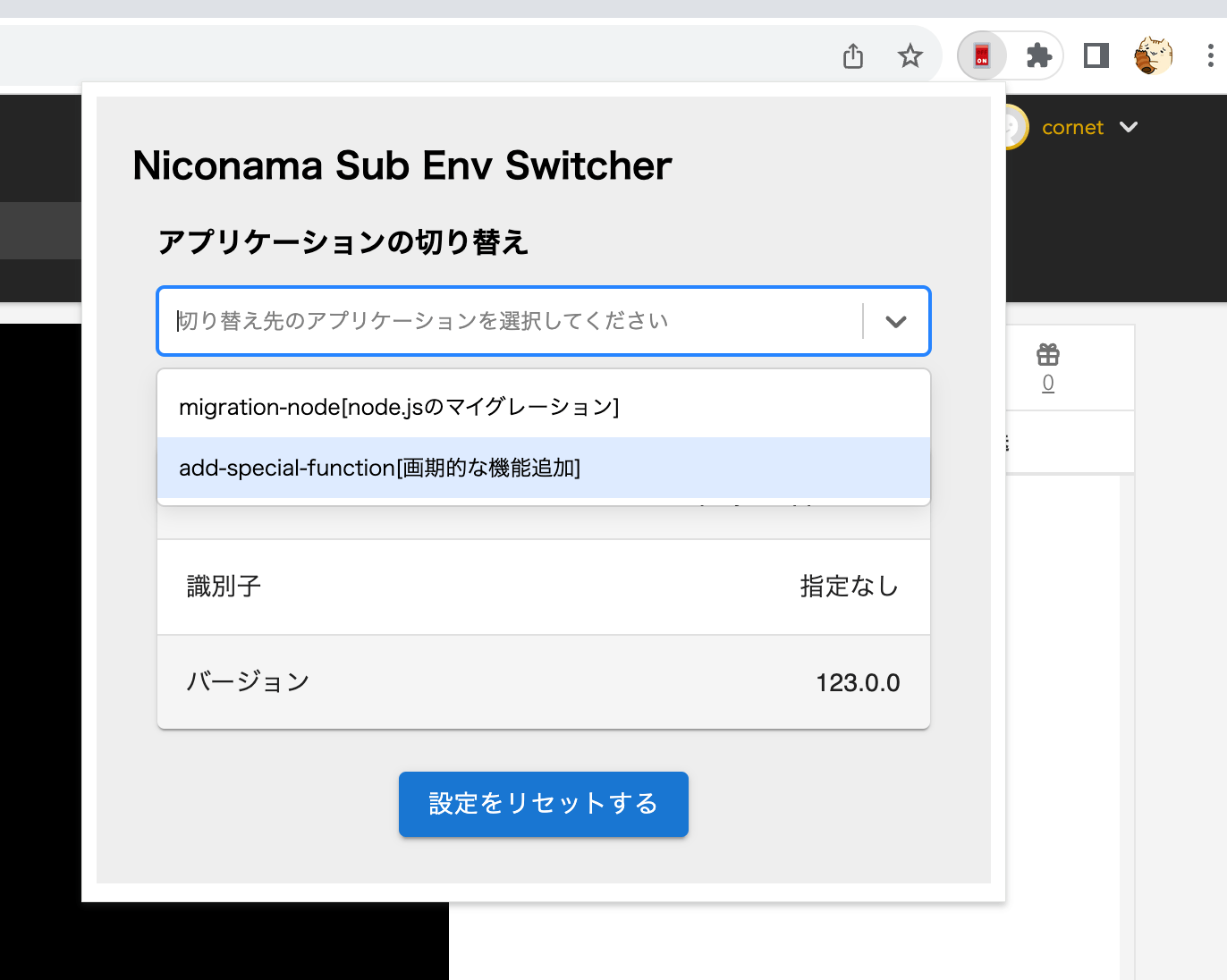
各アプリケーションのページにアクセスし、Chromeの機能拡張の設定画面を開くと、画像のようにセレクトボックスにサブ環境の一覧が表示されます。これを切り替えるとページがリロードされると共に、アクセス中のアプリケーションが選択した環境に切り替わるようになっています。
ここで表示されているリストについて見覚えがあるかと思いますが、上の章で解説したconfigの内容を取得して反映しています。表示されるリストはKubernetes側で管理しているものと常に一致する形になっているため、ここでも状態のズレが発生するということはありません。
内部的な仕組みとしては、Chrome APIのdeclarativeNetRequestを利用しています。特定のリクエストのブロックなどの用途が有名かと思いますが、予め決められたルールに従ってリクエストを書き換えることが可能です。
chrome.declarativeNetRequest.updateDynamicRules({
addRules: [{
id,
priority: 1,
action: {
type: chrome.declarativeNetRequest.RuleActionType.MODIFY_HEADERS,
requestHeaders: [
{
operation: chrome.declarativeNetRequest.HeaderOperation.SET,
header: "x-sub-env-id",
value: "add-special-function",
},
],
},
condition: {
"https://niconama-url/page-x/*",
resourceTypes: allResourceTypes,
},
}
]}
);
上記の設定では、https://niconama-url/page-x/*へのアクセスがあるとx-sub-env-id: add-special-functionのヘッダを付与するようになっています。これをリクエスト先のKubernetesクラスタのVirtualServiceで検知すると、対象のサブ環境に対応するupstreamにルーティングされます。

設定は各アプリケーション毎にStorageAPIを用いて保存されるため、一度切り替えれば毎回設定をし直す必要はありません。
また、動作確認のユースケースとして、「あるページにiframeで埋め込まれる前提のページ」の結合確認をしたいケースもあるかと思います。Chrome機能拡張を用いない前提で埋め込まれるページを特定の環境(ID: embedded-test-env)で切り替える場合は以下のようにiframeタグのsrcでクエリパラメータを指定する必要があります。
<iframe src="https://niconama-url/embedded-application?subEnvId=embedded-test-env">
埋め込む側のページが我々の管轄でないケース(ニコ生以外のサービス側のページに埋め込む場合など)などもよくあります。ページ単体で確認できるようなケースであれば良いのですが、埋め込む側のページとpostMessageでやり取りするような要件があったりするとそうもいきません。
今回用意したdeclarativeNetRequestによる機構はページ内で送信されるリクエスト全てが対象となるため、ページ内にiframeが埋め込まれていた場合はそこに対するリクエストも書き換えられます。そのため、埋め込む側のページのiframeのsrcにsubEnvId=embedded-test-envなどのクエリパラメータを付与せずとも、特定の環境に切り替えたページを埋め込んだのと同じ状況で動作確認を行うことができます。

運用してみた結果
上記対応を一通り構築すると、下記の図のような構成になります。

実際に運用を開始し、チーム内の複数の案件やアプリケーションで利用していますが、現状では特に大きな問題も見つかっていません。
実際にスケールしているかについて、3つの観点でまとめてみました。
必要な環境が増えても安心
上述の通り、必要な環境が増えた際はSlackのWorkflowから登録すれば手軽に追加できます。
また、仮にデプロイ内容に問題があり環境が壊れてたとしても他の環境への影響はありません。そのため、必要に応じて追加しては不要になったら削除する、といったサイクルを迅速に回すことが可能になっています。
また、個人環境(開発者毎に環境を用意する)との違いとしては、紐付くのが開発者ではなく案件単位であるという点です。
複数人が同一の環境で開発・閲覧するようなユースケース環境においても、特定の開発者に紐づいている訳ではないので関係者が自由に更新することができます。逆に1人の開発者が複数の案件に関わっている場合でも、複数環境に別々のものをデプロイすることも可能です。
強いて制約を上げるとすれば、Kubernetesクラスタのworker nodeの上限に依存するというぐらいです(1環境分のアプリケーションで消費するリソースはさほど大きく無いため、現実的な使い方をすれば問題ないはずです)。
アプリケーションが増えても安心
各アプリケーションのManifestは全て同じ仕組みで生成・管理されているため、新規追加したアプリケーションについても今回の機構を同様に利用できます。
また、システムを運用する際に全体のリソースは最低でもメインの環境の数 x アプリケーションの数だけ必要となるわけですが、アプリケーション個別で必要な分だけサブ環境を増やせるため、リソース効率の良い運用が可能です。
利用者が増えても安心
各サブ環境は独立にデプロイ可能なので、仮にデプロイする側の開発者が増えたとしても調整先が増えてしまうといったことはありません。
確認する側の利用者が増えても特に複雑な作業や情報を共有して覚えてもらう必要はありません。安定環境のURL1つだけ覚えておいて、機能拡張さえ入れておけばOKです。
環境へのデプロイ後に動作確認を依頼する場合も
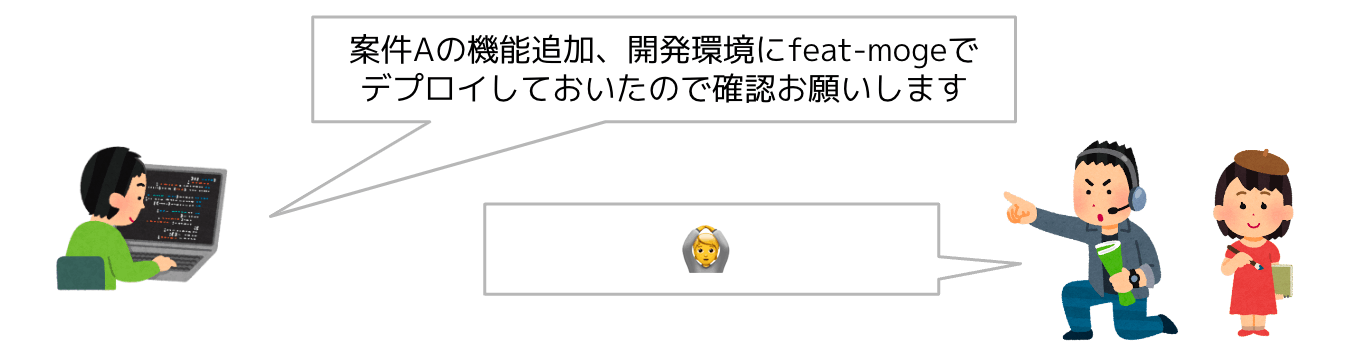
基本はこのぐらいのやり取りで済みます。リスト上に説明文も付いているため、どれを選べばいいのか分からないという問題も基本発生しません。
大変だったこと
URLのリクエストクエリベースのルーティング自体は従来から導入されていたため、後はこれをHTTP Headerに対応して可変にすること、管理を自動化することぐらいでした。
強いて言えば Chrome Manifest v3対応について、web上で欲しい情報があまり見つからず、対応自体も色々と難しいところが多かったというところでしょうか。
今後の課題
機能拡張による環境の切り替えについて、現状ではChromeにしか対応していないことが挙げられます(Edgeなどでも使えるかもしれないですが確認していません)。
また、PCのみでしか利用できないため、スマートフォンなどのデバイスでの確認は行えません。そのようなケースではクエリパラメータを付与して切り替える形になります。
また、内製している仕組みが多いため、依存しているシステムでのBreaking Changeに弱いという点も挙げられます。例えばChromeのManifestのインタフェースが変わったら動かなくなる可能性もあります(壊れたら自分達でなんとかするしかありません)。
あとはニコニコ生放送の現状の運用に特化しているという点もあります。
今回はニコニコ生放送のユースケースに特化させた仕組みとして用意したものであるため、他のシステムではそのままでは利用できません。
最後に運用面の話ですが、この仕組み自体の保守・運用が今後もちゃんと回っていくかという点も気にしておくべきポイントかと思います。作って終わりで良ければ問題ないのですが、システムが利用されている以上は今後も保守し続ける必要があります。
そのうち保守されなくなり、いざ動かないという時に誰も治せず、仕方ないので使えなくなるというのが一番残念なパターンです。
システム自体をスケールするように作っても、保守や運用自体が組織内でスケールせずに破綻するというケースは避けていきたいところです。
おわりに
開発環境が案件に対してスケールしない課題に対し、リソースやルーティングを手軽かつ自動で追加できるようにすることで対処したというお話でした。開発サイクルにおけるボトルネックの一部解消に少しは貢献できたのでは無いかと考えています。
導入にあたって色々とご協力頂いたチームメンバーにも感謝の念を述べさせて頂きたいと思います。
開発効率面の課題は割と見過ごされがちですが、実際には色々と改善可能な点が潜んでいたりします。今後も改善活動を続けていきたいと考えています。
今回の話は特に目新しい話というわけでは無いかと思いますが、少しでも皆様の参考になれば幸いです。
最後までお付き合い頂きありがとうございました。
明日は@euxn23さんの「レガシーブラウザ向けのビルドオプションを剪定する」です。
Discussion