Yolo と SAM による自動アノテーションを使って我が家の愛猫識別モデルを作る

物体検出モデルを作るときに最も大変な作業はなんといってもアノテーションです。
ここでアノテーションとは、画像中の物体の位置やクラスを示すための情報を付与する作業を指します。
従来アノテーションを行うためには、LabelMe などのアプリを使って画像を開いて物体の位置を示す矩形を描き、その矩形に対応するクラスを選択するという作業を繰り返す必要がありました。
しかし最近では、Yolo と Segment Anything Model (以下 SAM) というモデルを組み合わせることで、このアノテーション作業を自動化することが可能になりました。
この記事では、Yolo と SAM を使って自動アノテーションを行う方法について解説します。
また、この自動アノテーションの手法を使って我が家の猫を識別するモデルを作ったので合わせて紹介します。
Yolo と SAM とは
Yolo は、物体検出モデルの一つで、画像中の物体の位置とクラスを同時に推定することができるモデルです。
詳細な説明は他の記事に譲りますが、以下の画像のようなことができます。
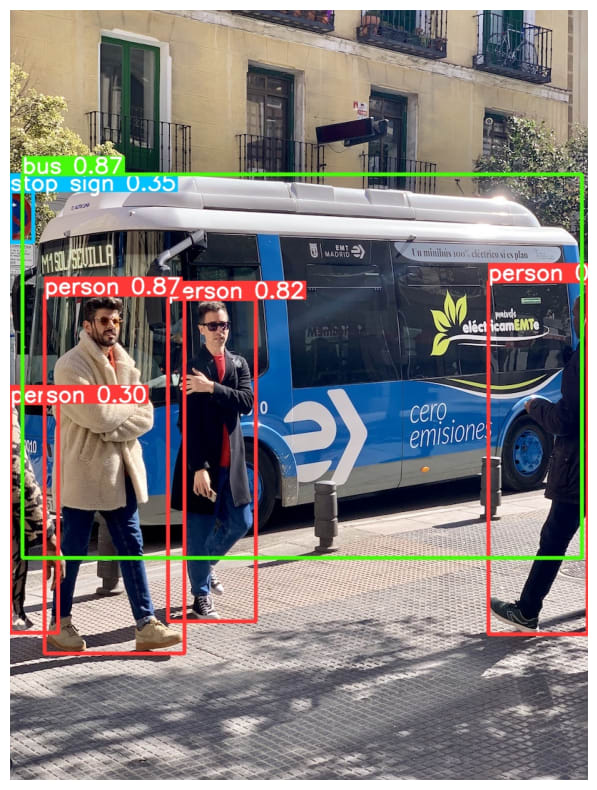
一方 SAM は Meta 社が開発したセグメンテーションモデルの一つで、画像中の領域を検出できるモデルです。
SAM のすごいところは、大規模なデータセットで事前学習を行ったことで、未知の画像データに対しても高い精度でセグメンテーションを行うことができる点です。
こちらは実際にデモサイトを見てもらうのが一番わかりやすいと思います。
自動アノテーションの仕組み
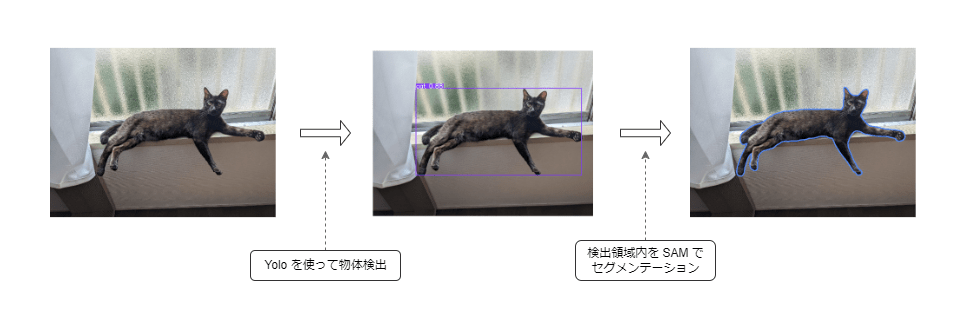
自動アノテーションの概略
自動アノテーションは下記のようなステップで行われます。
- 画像を入力として Yolo による物体検出を行う
- 検出された物体の位置を切り取って SAM によるセグメンテーションを行う
- Yolo の検出結果と SAM のセグメンテーション結果を組み合わせて、物体の位置とクラスを出力する
上記からわかるように、自動アノテーションできるのは Yolo で学習済みのクラスに対してのみです。
そのためユースケースとしては、事前に学習済みのモデルをファインチューニングする時などに有用です。
SAM を使うメリット

アノテーションを作るだけなら Yolo だけでも可能です。
しかし SAM を使ってセグメンテーションを行うことで、物体をより正確に切り取ることができます。
これによりアノテーションの精度が向上し、モデルの学習にも良い影響を与えることが期待できます。
例えば Yolo だけでアノテーションを行った場合、背景や前に他の物体がある場合に物体を正確に切り取ることが難しいです。
しかし SAM を使うことで、物体の輪郭を正確に切り取ることができるため、これらノイズの影響を軽減することが期待できます。
自動アノテーションの手順
早速試してみましょう。
自動アノテーションには Yolo が提供する auto_annotator を利用します。
こちらに画像を保存しているディレクトリと物体検出・セグメンテーション用のモデルを指定することで、自動アノテーションを行うことができます。
モデルの方は事前にダウンロードしておくか、自前で学習したものを使ってください。
from ultralytics.data.annotator import auto_annotate
auto_annotate(data='path/to/assets_dir', det_model='yolov8n.pt', sam_model='sam_b.pt')
各パラメータの説明は以下のとおりです。
| 名称 | タイプ | 説明 | デフォルト |
|---|---|---|---|
| data | str | 注釈を付ける画像を含むフォルダへのパス。 | 必須 |
| det_model | str | 事前に訓練されたYOLO 検出モデル。デフォルトは 'yolov8x.pt' です。 | 'yolov8x.pt' |
| sam_model | str | 事前に訓練されたSAM セグメンテーションモデル。デフォルトは 'sam_b.pt' です。 | 'sam_b.pt' |
| device | str | モデルを実行するデバイス。デフォルトは空の文字列(利用可能な場合はCPUまたはGPU)。 | '' |
| output_dir | str | None | 注釈付き結果を保存するディレクトリ。 デフォルトは'data'と同じディレクトリの'labels'フォルダ。 | None |
実行すると、指定したディレクトリ内の画像に対して自動アノテーションが行われ、output_dir にアノテーション結果が保存されます。
アノテーション結果は {画像ファイル名}.txt という形で保存され、中身には検出した物体のクラスと位置が記述されています。
# クラス番号 x1 y1 x2 y2 ...
15 0.26913580298423767 0.21481481194496155 ...
テキストだけだとわかりにくいので、実際にアノテーション結果を可視化してみました。

# アノテーション可視化処理
import cv2
import numpy as np
from random import randint
from IPython.display import display, Image
img = cv2.imread('./image.jpg')
h,w = img.shape[:2]
with open('./image.txt', 'r') as f:
labels = f.read().splitlines()
for label in labels:
class_id, *poly = label.split(' ')
poly = np.asarray(poly,dtype=np.float16).reshape(-1,2) # Read poly, reshape
poly *= [w,h] # Unscale
cv2.polylines(img, [poly.astype('int')], True, (randint(0,255),randint(0,255),randint(0,255)), 50) # Draw Poly Lines
_, buf = cv2.imencode(".jpg", img)
display(Image(data=buf.tobytes()))
可視化してみることで、確かに対象物だけを切り取ってアノテーションができていることがわかりました。
我が家の猫識別モデルの作成
自動アノテーションの効果を試して見るためにモデルの学習をしてみます。
今回は、我が家の完璧で究極のアイドル猫「すみちゃん」を識別するモデルを作ってみました。
まずはデータセットを用意するために、すみちゃんとそれ以外の猫画像を700枚ほど集めました。
比率としてはすみちゃんの画像が約 350 枚、それ以外の猫画像が約 350 枚です。
本来ならこれらすべての画像に対してアノテーションを行う必要がありますが、今回は自動アノテーションを使いました。
データセットの作成
自動アノテーションを行う際には、すみちゃんの画像とそれ以外の猫画像を別々に実行する必要がありました。
これは Yolo の学習済みモデルが「猫」としか認識できないため、全部一緒にやってしまうとすみちゃんとそれ以外の猫を区別することができないからです。
from ultralytics.data.annotator import auto_annotate
auto_annotate(data="../dataset/sumi", det_model="yolov8n.pt", sam_model='sam_l.pt', output_dir="../dataset/sumi_labels")
auto_annotate(data="../dataset/cats", det_model="yolov8n.pt", sam_model='sam_l.pt', output_dir="../dataset/cat_labels")
正確な時間は計っていませんが、700枚の画像に対して自動アノテーションが約 15 分ほどで完了しました。
画像1枚あたり1秒強でアノテーションを行っており、非常に効率的です。
次にそれぞれの結果に対して学習用にラベルを振り直します。
今回はすみちゃんの結果に classId 0 を、それ以外の猫の結果を出して、classId 1 を設定しました。
def relabeling(labels_dir: Path, new_labels_dir: Path, old_id: int, new_class_id: int):
"""
自動アノテーションで作成した猫ラベルを振り直す
"""
# ラベルファイルのリストを取得
labels = list(labels_dir.glob("*"))
# ラベルファイルをコピー
for label in labels:
with open(label, "r", encoding="utf-8") as f:
lines = f.readlines()
with open(new_labels_dir / label.name, "w") as f:
for line in lines:
# old_id で始まる行を new_class_id に置き換える
if line.startswith(f"{old_id} "):
f.write(f"{new_class_id} {line.split(' ', 1)[1]}")
else:
continue
# すみちゃんとそれ以外の猫画像に対してそれぞれラベルを振り直すを行う
relabeling(Path("sumi_labels"), Path("new_labels"), 15, 0) # 15 は猫のラベル
relabeling(Path("cat_labels"), Path("new_labels"), 15, 1)
モデルの学習と推論
データセットの作成が終わったら学習です。
学習については通常通りの方法なので詳細は Yolo の公式ドキュメントを参考にしてください。
from ultralytics import YOLO
model = YOLO("yolov8n.pt")
model.train(data="./data.yaml", epochs=300, batch=20) # 作成したデータセット内のyamlファイルまでのパスを指定
学習したモデルですみちゃんを識別してみた結果がこちらです。

学習モデルによるすみちゃん識別結果
結果は期待通りにすみちゃんを識別することができました。
上の2枚はネットで拾ってきた猫画像で、下二枚がすみちゃんです。
すみちゃんと同じ黒猫でも正しく別の猫と識別できてます。
またすみちゃんの二枚はあえて似てない画像を選んだつもりでしたが、こちらも正しく識別できていました。
他の猫はどちらも低い精度で検出されてます。
簡単に考察するなら、すみちゃん1種類に対して、それ以外の猫は種類が膨大だからだと考えられます。
今回はすみちゃんとそれ以外の猫の画像数が同じだったので、すみちゃんの特徴をより強く学習しているのだとおもわれます。
もし正確に識別するなら、すみちゃんのデータの数倍データを集めて学習する必要があるでしょう。
まとめ
簡単にですが Yolo と SAM を使って自動でアノテーションを作り、新しいモデルを学習する方法を紹介しました。
紹介した手法では、事前に学習済みのモデルを使う必要がありますが、ファインチューニングなどで使う場合には非常に有用な手法だと思います。
またこちらの手法以外でも SAM を活用すればアノテーションの精度をぐっと高めることが期待できます。
画像認識の精度を向上させたい方は、ぜひ試してみてください。
それでは。
Discussion