Microsoft のオープンソース Vision モデル Florence2 を試す
Florence2 とは
Florence-2: Advancing a Unified Representation for a Variety of Vision Tasks
Florence2 は Microsoft が提供する Vision モデルで、様々な Vision タスクに対応したオープンソースのモデルです。
大きな特徴は以下のとおりです。
- ゼロショットで様々なタスクに対応
- 物体検出
- キャプション生成
- セグメンテーション
- 画像内検索
- OCR
- プロンプトベースで利用可能
- 軽量ながら高性能
より詳細なスペックやベンチマークについては以下のページを参照してください。
また各機能の例については以下のノートブックがとてもわかりやすいです。
実行環境
以下のコンテナに transformers をインストールすれば実行できます。
-
nvcr.io/nvidia/pytorch:24.02-py3
- OS: Ubuntu 22.04
- python: 3.10.12
- PyTorch: 2.3.0a0
- Cuda: 12.3
- GPU: Quadro RTX 5000
試してみた
以下のコロナウイルスの画像を使って、各タスクを試してみます。
コロナウイルスの画像を使うのは、これを試した当時コロナに感染してたからです。
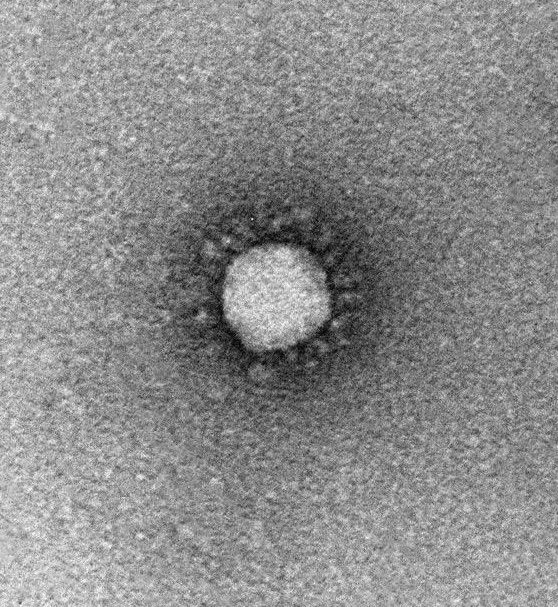
引用元: 東京都健康安全研究センター » 新型コロナウイルスの電子顕微鏡写真 (オミクロン株の写真を追加) (tokyo.lg.jp)
実行コードは以下の通りで、run_example メソッドにわたす引数でタスクを切り替えます。
from PIL import Image
from transformers import AutoProcessor, AutoModelForCausalLM
import torch
device = "cuda" if torch.cuda.is_available() else "cpu"
model = AutoModelForCausalLM.from_pretrained(
"microsoft/Florence-2-large", trust_remote_code=True
).to(device)
processor = AutoProcessor.from_pretrained(
"microsoft/Florence-2-large", trust_remote_code=True
)
image = Image.open(open("./covid-19.jpg", "rb"))
def run_example(task_prompt, text_input=None):
if text_input is None:
prompt = task_prompt
else:
prompt = task_prompt + text_input
inputs = processor(text=prompt, images=image, return_tensors="pt").to(device)
generated_ids = model.generate(
input_ids=inputs["input_ids"],
pixel_values=inputs["pixel_values"],
max_new_tokens=1024,
num_beams=3,
)
generated_text = processor.batch_decode(generated_ids, skip_special_tokens=False)[0]
parsed_answer = processor.post_process_generation(
generated_text, task=task_prompt, image_size=(image.width, image.height)
)
return parsed_answer
物体検出
results = run_example("<OD>")
以下の関数で画像上に結果を表示します。
import matplotlib.pyplot as plt
import matplotlib.patches as patches
def plot_bbox(image, data):
# Create a figure and axes
fig, ax = plt.subplots()
# Display the image
ax.imshow(image)
# Plot each bounding box
for bbox, label in zip(data['bboxes'], data['labels']):
# Unpack the bounding box coordinates
x1, y1, x2, y2 = bbox
# Create a Rectangle patch
rect = patches.Rectangle((x1, y1), x2-x1, y2-y1, linewidth=1, edgecolor='r', facecolor='none')
# Add the rectangle to the Axes
ax.add_patch(rect)
# Annotate the label
plt.text(x1, y1, label, color='white', fontsize=8, bbox=dict(facecolor='red', alpha=0.5))
# Remove the axis ticks and labels
ax.axis('off')
# Show the plot
plt.show()
plot_bbox(image, results["<OD>"])

invertebrate という見慣れないラベルが付与されていますが、日本語で言うと無脊椎動物のことです。
ウイルスが無脊椎動物なのかは専門外なのでよくわかりませんが、少なくとも期待した結果ではありませんでした。
次に Phrase Grounding というタスクを試してみます。
このタスクは、画像とその Context を与えることで Context に基づいて画像内の物体を特定するタスクです。
今回は "ウイルスの白黒顕微鏡像" という Context を与えてみます。
task_prompt = '<CAPTION_TO_PHRASE_GROUNDING>'
results = run_example(task_prompt, text_input="A black and white microscopic view of a virus.")
plot_bbox(image, results['<CAPTION_TO_PHRASE_GROUNDING>'])

適切な Context を与えることで、ウイルスを検知することができました。
ファインチューニングみたいなことをせずに出力を制御できるのは、非常に便利だと感じます。
キャプション生成
run_example("<CAPTION>")
# {'<CAPTION>': 'a black and white image of a small hole in the ground'}
画像を端的に説明するには十分ですが、この説明だと具体的に何を示す画像なのかがわかりません。
より詳しい説明を生成させてみましょう。
run_example("<MORE_DETAILED_CAPTION>")
# {'<MORE_DETAILED_CAPTION>': 'The image is a black and white microscopic view of a small, circular object. The object appears to be made up of small, irregularly shaped particles that are densely packed together. The particles are arranged in a way that they form a ring-like shape, with the center of the object being the largest and the outermost. The surface of the surface is covered in small, textured particles, giving it a textured appearance. The image is taken from a top-down perspective, looking down on the object.'}
The image is a black and white microscopic view of a small, circular object. The object appears to be made up of small, irregularly shaped particles that are densely packed together. The particles are arranged in a way that they form a ring-like shape, with the center of the object being the largest and the outermost. The surface of the surface is covered in small, textured particles, giving it a textured appearance. The image is taken from a top-down perspective, looking down on the object.
出力結果を日本語に翻訳してみます。
画像は小さな円形の物体の白黒顕微鏡写真である。この物体は、小さな不規則な形の粒子が密集してできているように見える。粒子はリング状になるように並んでおり、物体の中心が最も大きく、最も外側にある。表面は小さな粒子で覆われているため、テクスチャーがあるように見える。画像は上から見下ろした視点で撮影されている。
画像の特徴はよく捉えられており、これが顕微鏡で撮影した何らかの物体であることも理解しているようです。
ただ、これがコロナウイルスであることまでは説明できていないようでした。
Caption 結果を LLM に渡してみる
この説明がどれだけ適切かを確認するために、生成されたキャプションを LLM に渡してみます。
今回は Claude 3.5 sonnet を利用してみます。
入力:
以下の説明は、とある物体の電子顕微鏡像の説明です。この説明に当てはまる物体を教えて下さい
The image is a black and white microscopic view of a small, circular object. The object appears to be made up of small, irregularly shaped particles that are densely packed together. The particles are arranged in a way that they form a ring-like shape, with the center of the object being the largest and the outermost. The surface of the surface is covered in small, textured particles, giving it a textured appearance. The image is taken from a top-down perspective, looking down on the object.
出力:
この説明に当てはまる物体は、高い可能性で「ウイルス粒子」、特に「コロナウイルス」だと考えられます。
その理由は以下の通りです:
- 円形の形状:多くのウイルス、特にコロナウイルスは球形または円形の形状を持ちます。
- 不規則な形の小さな粒子:これはウイルスの表面にある突起(スパイクタンパク質)を表している可能性が高いです。
- 密に詰まった構造:ウイルスの内部は遺伝物質やタンパク質で密に満たされています。
- リング状の配置:コロナウイルスの特徴的な「王冠」のような外観を示唆しています。
- 中心が最も大きい:これはウイルスの核(遺伝物質を含む部分)を表している可能性があります。
- テクスチャのある表面:ウイルスの表面にある突起(スパイクタンパク質)によるものと考えられます。
- 上からの視点:電子顕微鏡でウイルスを観察する際の典型的な視点です。
コロナウイルスは2020年以降、COVID-19パンデミックの原因として世界的に注目されており、その電子顕微鏡像は広く公開されています。この説明はそのような画像と非常によく一致します。
ただし、他のウイルスや微小な球状粒子でも似たような特徴を持つ可能性があるため、100%の確実性でコロナウイルスだと断言することはできません。画像自体を見ることができれば、より正確な判断が可能になるでしょう。
なんと説明だけでコロナウイルスと判断できるという結果が得られました、あまり期待してなかったのでこの結果は驚きです。
Claude が優れている側面もありますが、Florence 2 は適切に画像を読み取って Caption を生成できていると言えるでしょう。
ちなみに画像だけを与えると以下のような結果になり、コロナウイルスの特定までは至りませんでした。
この画像は電子顕微鏡で撮影されたウイルス粒子のようです。中央に球状の構造体が見え、その周りに暗い外殻や表面のタンパク質と思われる構造が確認できます。
ウイルスの種類を特定することは難しいですが、多くのウイルスがこのような球形の構造を持っています。例えば、コロナウイルス、インフルエンザウイルス、ノロウイルスなどが似たような形態を示します。
ただし、これは一般的な観察に基づく推測であり、正確な同定にはさらなる専門的な分析が必要です。この画像だけでは特定のウイルスを断定することはできません。
ウイルス学や微生物学の研究において、このような電子顕微鏡画像は病原体の構造を理解し、その特性を研究する上で非常に重要な役割を果たしています。
画像内検索
まずは単純な例で試してみます。
prompt = "<OPEN_VOCABULARY_DETECTION>"
results = run_example(prompt, "circle")
以下の処理で物体検出の表示用に結果を整形します。
def convert_to_od_format(data):
"""
Converts a dictionary with 'bboxes' and 'bboxes_labels' into a dictionary with separate 'bboxes' and 'labels' keys.
Parameters:
- data: The input dictionary with 'bboxes', 'bboxes_labels', 'polygons', and 'polygons_labels' keys.
Returns:
- A dictionary with 'bboxes' and 'labels' keys formatted for object detection results.
"""
# Extract bounding boxes and labels
bboxes = data.get('bboxes', [])
labels = data.get('bboxes_labels', [])
# Construct the output format
od_results = {
'bboxes': bboxes,
'labels': labels
}
return od_results
od_results = convert_to_od_format(results["<OPEN_VOCABULARY_DETECTION>"])
plot_bbox(image, od_results)
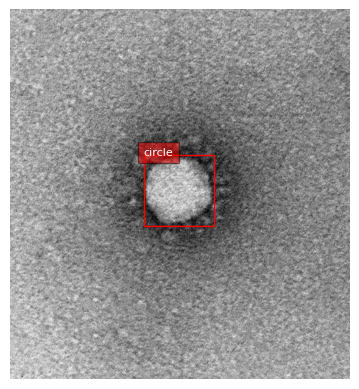
circle というキーワードを与えたところ、画像内に円形の物体を検出できました。
一般的な知識であれば検出できる事がわかったので、次にコロナウイルスを検出してみます。
results = run_example(prompt, "Covid-19 virus")
od_results = convert_to_od_format(results["<OPEN_VOCABULARY_DETECTION>"])
plot_bbox(image, od_results)
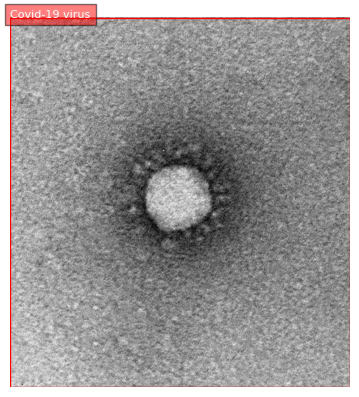
Covid-19 virus というキーワードを与えたところ、コロナウイルス単独では検出できず、画像全体がウイルスの画像であると判定されました。
間違ってはいないのですが、もう少し具体的に検出できると良かったです。
専門的すぎる固有名詞は難しいのかと思ったので、もうちょっと一般的なキーワードで試してみます。
results = run_example(prompt, "A virus")
od_results = convert_to_od_format(results["<OPEN_VOCABULARY_DETECTION>"])
plot_bbox(image, od_results)

A virus というキーワードを与えたところ、ウイルスを検出できました。
ただ検出結果が複数あり、コロナウイルス同様画像全体も検出されているので、もう少し精度が欲しいところです。
今回の例だと Phrase Grounding の方が精度が高い結果が得られているので、タスクに合わせて使い分けが必要だと感じました。
まとめ
Florence2 は多様な Vision タスクに対応したモデルで、プロンプトベースで利用できるのが大きな特徴です。
今回はコロナウイルスの顕微鏡像という特殊な画像を使って試しましたが、そのうえで比較的良い結果が得られました。
一般的な画像であればより高い精度が期待できると感じます。
また実際に使ってみて特に魅力を感じたのは実行速度の速さです。
どのタスクもほぼ1秒程度で結果が得られるので、実運用も十分可能だと感じました。
Florence 2 含めオープンソース AI はますます進化しているので、これからも注目していきたいです。
Discussion