MySQLのGeometryデータを扱う
最近は業務で、現在地周辺の施設候補を検索する機能のリクエストが出て、それを解決するために色々と調査してみました。
ロケーションテーブル
仮に下記のようなテーブルがあったとします。
CREATE TABLE IF NOT EXISTS `location`(
`id` INT NOT NULL PRIMARY KEY AUTO_INCREMENT,
`geo_hash` VARCHAR(12),
`position` POINT NOT NULL SRID 4326,
`latitude` DOUBLE(8,6) NOT NULL,
`longitude` DOUBLE(9,6) NOT NULL,
SPATIAL INDEX(`position`)
);
delimiter //
CREATE TRIGGER add_geometry_on_insert BEFORE INSERT ON location
FOR EACH ROW
BEGIN
SET @lng = NEW.longitude;
SET @lat = NEW.latitude;
SET @point = CONCAT('POINT(',@lat,' ',@lng,')');
SET NEW.position = ST_GeomFromText(@point,4326);
END;//
CREATE TRIGGER add_geometry_on_update BEFORE UPDATE ON location
FOR EACH ROW
BEGIN
SET @lng = NEW.longitude;
SET @lat = NEW.latitude;
SET @point = CONCAT('POINT(',@lat,' ',@lng,')');
SET NEW.position = ST_GeomFromText(@point,4326);
END;//
CREATE TRIGGER add_geohash_on_insert BEFORE INSERT ON location
FOR EACH ROW FOLLOWS add_geometry_on_insert
SET NEW.geo_hash = ST_GeoHash(NEW.position,12);//
CREATE TRIGGER add_geohash_on_update BEFORE UPDATE ON location
FOR EACH ROW FOLLOWS add_geometry_on_update
SET NEW.geo_hash = ST_GeoHash(NEW.position,12);//
delimiter ;
基本的に、フロントエンドとバックエンドでは経度と緯度をメインに扱うため、この二つのデータさえあれば動くように、geo_hashとpositionフィールドに対して、トリガーを追加しています。経度と緯度だけでいいじゃんとか思われる方もいるかもしれませんが、この二つのフィールドが必要かどうかは今回議論範囲外です。
GeoHash
latitudeとlongitudeを使ってハッシュ関数で生成された数字とアルファベットの文字列。文字列の長さは精度と正の相関があります。
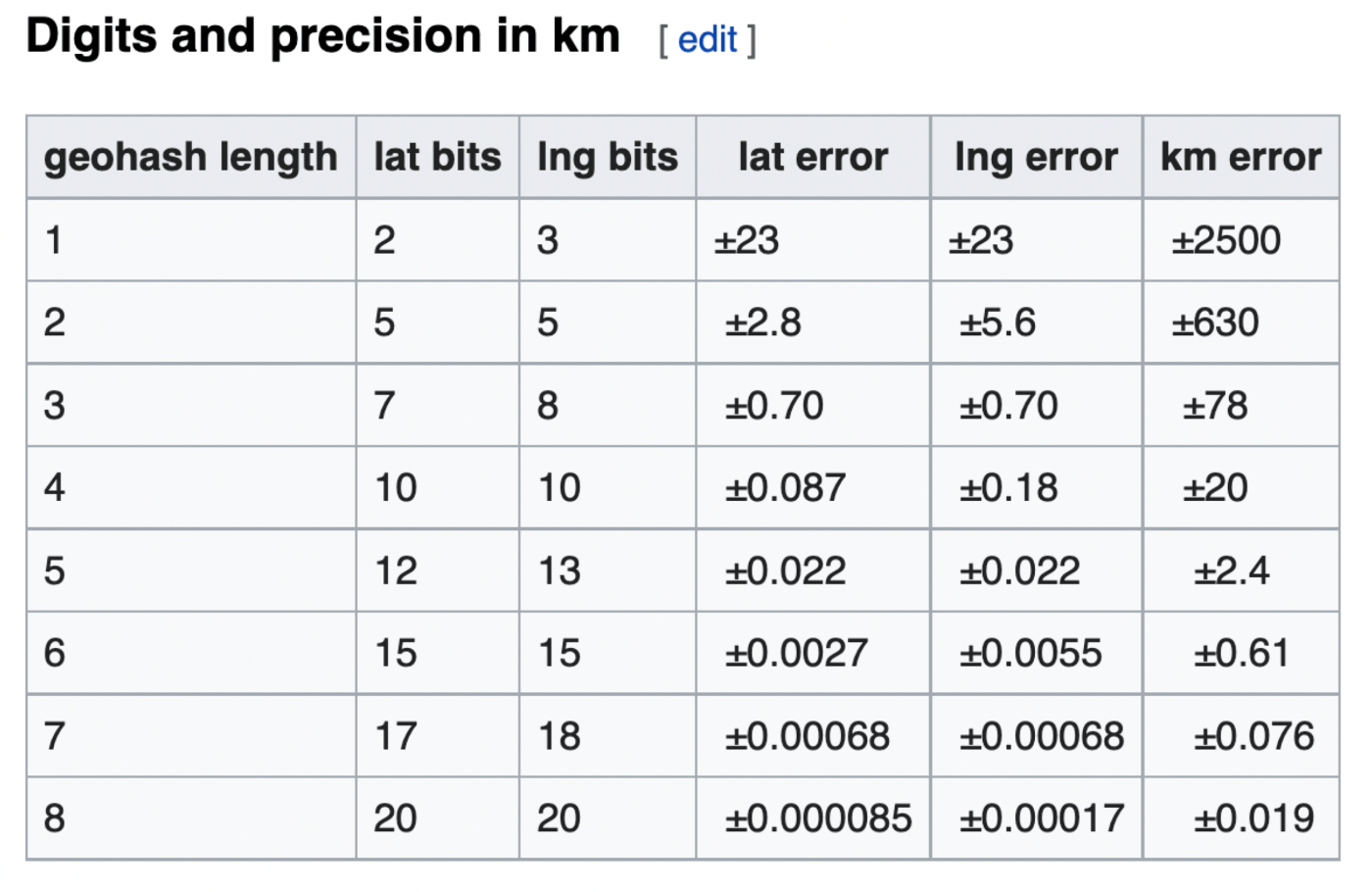
上記の表( 参照先 )で表示されたように、生成された文字列の長さが8桁であれば、精度は+-0.019キロメートル=19mとなります。また、こちらの回答によると、9桁以上になると精度がさらに増えます:
| 桁数 | 精度(km) |
|---|---|
| 9 | ± 0.0024 |
| 10 | ± 0.00060 |
| 11 | ± 0.000074 |
この通り、10桁までいくと、精度が1メートル以内になるので、保存時は10桁で十分なはずですが、今回は一旦12桁で保存してみます。
MySQLには、GeoHashのデータから経度緯度を抽出する関数があります。今回は直接経度緯度を保存しているので関心外となりますが、詳細 はこちら に参照。
精度は桁数と関係あるため、左から同じ文字が多ければ多いほど、二つの場所が近いとのことになります。次の表のように、MySQLのST_GeoHash関数を使用し、東京駅周辺と台東区のサンプルロケーションデータの経度緯度で計算した結果、上位数桁の文字列が同じとなっています。
| "id" | "geo_hash" | "latitude" | "longitude" |
|---|---|---|---|
| "1" | "xn76u7d7ccrq" | "35.659526" | "139.760255" |
| "2" | "xn76ukf8h3rx" | "35.665749" | "139.760706" |
| "3" | "xn76um23ymxe" | "35.668818" | "139.757702" |
| "4" | "xn76umc7e6zr" | "35.671851" | "139.758946" |
| "5" | "xn76upm6jq1e" | "35.67985" | "139.753531" |
| "6" | "xn76uru5z734" | "35.682882" | "139.762886" |
| "7" | "xn76urnr2y34" | "35.679379" | "139.765697" |
| "8" | "xn76vp3r7g9h" | "35.680738" | "139.791918" |
| "9" | "xn77hec3d8f4" | "35.704455" | "139.769893" |
| "10" | "xn77hudy12t6" | "35.709346" | "139.78289" |
GEOMETRYデータタイプ
MySQLにはいくつかのGeometryデータタイプが用意されています。
- GEOMETRY
- POINT:点、マップの場合は緯度経度が入っている
- LINESTRING:線、例えばマップ上の経路を表す
- POLYGON:文字通り多角形、マップ上の一つのエリアを表現できる
その中、GEOMETRYの方はベースとなっているので、他の3種類のデータタイプを入れることが可能です。他には上記の4種類と対応するコレクション・集合タイプがありますが、今回は関心外のため省略。
- MULTIPOINT
- MULTILINESTRING
- MULTIPOLYGON
- GEOMETRYCOLLECTION
今回は経度緯度も含めているので、暗黙の前提として、経度緯度のPOINTタイプに定義しています。
ここで注意点は二つ:
-
POINTはNOT NULL。ここはインデックスと関係しており、SPATIALインデックスはNULLを許容しないからです。 -
SRIDは4326を設定している。このSRIDというのは、Spatial Reference System Identifierの略となりますが、デフォルトでは0となっており、2Dの平面のケースの座標系(デカルト座標系)を表しています。4326とは、地球上の点を表す球体上の座標系を表しています。今回はマップ上の点を保存するので、ここは4326と指定する必要があります。
経度と緯度
latitudeとlongitudeはそれぞれDOUBLEタイプで、小数点以下6桁で定義しています。GOOGLE MAPのデータでは小数点6桁までとなっており、この時点で既に1メートル以内の精度となっていますので、更なる精度を求める必要がないでしょう(参照先)。
| decimal | places | distance |
|---|---|---|
| 0 | 1.0 | 111 km |
| 1 | 0.1 | 11.1 km |
| 2 | 0.01 | 1.11 km |
| 3 | 0.001 | 111 m |
| 4 | 0.0001 | 11.1 m |
| 5 | 0.00001 | 1.11 m |
| 6 | 0.000001 | 0.111 m |
| 7 | 0.0000001 | 1.11 cm |
| 8 | 0.00000001 | 1.11 mm |
また、緯度の値は-90~90の範囲、経度の値は-180~180の範囲ですので、それぞれ合計8桁と9桁で定義しています。
SPATIAL INDEX
こちらはMySQL内蔵のインデックスタイプの一つで、GEOMETRYデータタイプ専用のインデックスとなります。他のB-Tree構造とは違い、ギオデータ向けのR-Tree構造となっています。
制限は先ほど触れていましたが、NULLは許容しないため、場所不明のデータに関しては、0,0とかに変換する工夫が必要です。例えば:
set position = POINT(coalesce(longitude, 0), coalesce(latitude, 0))
もう一つは、SRIDを最初に設定してインデックスが作られたあと、フィールドタイプを変更することができず(例えばPOINTからGEOMETRYへ変更する)、変更する場合はインデックスを削除して作り直す必要があります。
ただ、このインデックスの適応にも若干制限があり、例えば、現在地周辺2km以内の候補を探すときになると、わかりやすい直接な関数がなく、少しトリッキーな操作が必要になります。2Dの平面なら、ST_Bufferという内蔵関数があり、半径を指定して候補を全て取得することができますが、球体面の場合は使用できません。詳しい解決法はまた次の節で議論します。
現在地から周辺2kmの候補を取得
実際の業務で必要なのは、現在地から一定の範囲内の候補を取得することです。ここではいくつかのやり方がありますが、それぞれの問題点を含めて検討してみたいと思います。
アプローチ1: ST_Distance_Sphere関数
MySQL内蔵の球体表面にある2つの点の距離を計算する関数です( Haversine formula )。
最もわかりやすい方法かもしれません:
SET @user_location = ST_GeomFromText( 'POINT(35.659526 139.760255)', 4326);
SELECT
*,
ST_Distance_Sphere(`position`, @user_location) AS `distance`
FROM
`location`
WHERE ST_Distance_Sphere(`position`, @user_location) <= 2000;
ただ、この方法には大きな欠点があります。WHEREクローズでは、直接positionではなく、計算されたdistanceで固定値2kmと比較しているため、インデックスが効かない問題があります。もしデータ量が多くなると、フルスキャンになるので非常に遅くなります。そのため、この方法はプロダクションにはあまり使えません。
アプローチ2: POLYGONを計算して範囲を指定
2D平面で使えるST_Bufferからの発想ですが、こちらの多角形を指定すると、ST_Within(position, polygon)で範囲内のデータを取得できます。
SET @user_location = ST_GeomFromText( 'POINT(35.659526 139.760255)', 4326);
SET @polygon = ST_GeomFromText( 'POLYGON((139.760255 35.659526, 139.760255 35.659526, 139.760255 35.659526, 139.760255 35.659526, 139.760255 35.659526))', 4326);
SELECT
*,
ST_Distance_Sphere(`position`, @user_location) AS `distance`
FROM
`location`
WHERE ST_Within(`position`, @polygon);
ただ、これにも欠点があります。多角形のため、半径=円形範囲とは合致しません。もちろん、多角形の点を増やすことによって円形に近づけることが可能ですが、計算が大変です。
この欠点に関しては、WHERE句の追加によって解決は可能です:
SELECT
*,
ST_Distance_Sphere(`position`, @user_location) AS `distance`
FROM
`location`
WHERE ST_Within(`position`, @polygon)
AND ST_Distance_Sphere(`position`, @user_location) <= 2000;
つまり、先にST_Withinでインデックスを利用して検索範囲を大幅に縮小します。その後もう一度精確な条件で絞り込みます。
この場合、最初の多角形は、内接円の形で円形範囲を包括する正方形で良いのではないかと思います。正方形だけであれば、左下と右上の2つの点の経度緯度だけが分かれば、多角形の計算よりだいぶ楽になります。

function deg2rad(deg) {
return deg * (Math.PI / 180);
}
function rad2deg(rad) {
return rad * (180 / Math.PI);
}
function getRectPoints(latitude, longitude, distance)
{
let latLimits = [deg2rad(-90), deg2rad(90)];
let lonLimits = [deg2rad(-180), deg2rad(180)];
let radLat = deg2rad(latitude);
let radLon = deg2rad(longitude);
if (radLat < latLimits[0]
|| radLat > latLimits[1]
|| radLon < lonLimits[0]
|| radLon > lonLimits[1]) {
throw new Error("Invalid Argument");
}
let angular = distance / 6371; // 地球半径km
let minLat = radLat - angular;
let maxLat = radLat + angular;
let minLon, maxLon;
if (minLat > latLimits[0] && maxLat < latLimits[1]) {
let deltaLon = Math.asin(Math.sin(angular) / Math.cos(radLat));
minLon = radLon - deltaLon;
if (minLon < lonLimits[0]) {
minLon += 2 * Math.PI;
}
maxLon = radLon + deltaLon;
if (maxLon > lonLimits[1]) {
maxLon -= 2 * Math.PI;
}
} else {
minLat = Math.max(minLat, latLimits[0]);
maxLat = Math.min(maxLat, latLimits[1]);
minLon = lonLimits[0];
maxLon = lonLimits[1];
}
return {
minLat: rad2deg(minLat),
minLon: rad2deg(minLon),
maxLat: rad2deg(maxLat),
maxLon: rad2deg(maxLon),
};
}
ST_MakeEnvelop関数で正方形の範囲を作ることができるので、多角形の作成が簡単に:
SET @polygon = ST_MakeEnvelope(POINT(@minLat, @minLon), POINT(@maxLat, @maxLon));
ただ、このST_MakeEnvelope関数は、平面(デカルト)座標系で計算しているため、精確的に言えば、4つの点をしていた方が良いでしょう:
-- 実際はCANCATで変数と文字列を結合するためが必要だがここは省略
SET @polygon = ST_PolyFromText( '((@minLat @minLon, @minLat, @maxLon, @maxLat @minLon, @maxLat @maxLon))', 4326);
アプローチ3: 精度を下げて別途フィールドを追加
この方法はアプローチ2と一部同じですが、肝心なインデックスの利用が違います。
考えとして、latitudeとlongitudeは1メートル以内の精度を持ちますが、もし少し精度を下げると、一つの範囲内のデータを包括するデータとして表現できます。これは、解析度のように、27インチのFHDのディスプレイと4Kのディスプレーを比較すると、DPIが段違いするが、あえて27インチの方を使い、ぼんやりとしたエリアをまず探し、次に4Kに切り替えて、そのエリア内のピクセルの座標を取得する、との考えです。
要するに、Googleマップを使うときに、一旦ズームレベルの高い範囲で候補を洗い出し、それでさらにズームインして精確な場所を探すのと同じ感じです。
CREATE TABLE IF NOT EXISTS `location`(
`id` INT NOT NULL PRIMARY KEY AUTO_INCREMENT,
`geo_hash` VARCHAR(10),
`position` POINT NOT NULL SRID 4326,
`latitude` DOUBLE(8,6) NOT NULL,
`longitude` DOUBLE(9,6) NOT NULL,
`lat_1000_floor` MEDIUMINT GENERATED ALWAYS AS (FLOOR(latitude * 1000)) STORED,
INDEX(`lat_1000_floor`, `longitude`)
);
ここで新しい生成されたフィールドを追加して、lat_1000_floorとlongitudeをインデックスに追加します。ただ、注意点として、AS (expression)の後ろには、STOREDを指定する必要があり、デフォルトではVIRTUALとなるためインデックスが作れません(STOREDタイプが実際にハードディスクに保存されます)。
これに何ができるかというと、多角形の4つの経度緯度を計算するときに、latitudeの範囲を絞り込み、WHERE INを使うことができます。
const rect = {
"minLat" : 35659, // Math.floor(rect.minLat * 1000)
"maxLat" : 35709, // Math.floor(rect.maxLat * 1000)
"minLon" : 139.753531,
"maxLon" : 139.791918,
}
const lats = range(35659, 36709) // [35659, 35660, ..., 35709]
// 実装例
const range = (start, end, step=1) {
let output = [];
if (typeof end === 'undefined') {
end = start;
start = 0;
}
for (let i = start; i < end; i += step) {
output.push(i);
}
return output;
}
MySQLでは、IN演算子を使うときに、集合データをソートしてからバイナリー検索で素早く候補を特定し、その上インデックスが効くため、BETWEENよりだいぶ効率が良くなります。これでSQLに絞り込むと:
SELECT
*,
ST_Distance_Sphere(`position`, @user_location) AS `distance`
FROM
`location`
WHERE latitude IN (35659, 35660, ..., 35709)
AND longitude BETWEEN 139.753531 AND 139.791918
AND ST_Distance_Sphere(`position`, @user_location) <= 2000;
こちらの検証によると、上記の方法では、アプローチ2よりも早いらしいです。
ただ欠点はないわけではありません。実質もう一つのカラムを追加しているので、この精度をどのくらい下げるか(例えば今回は1000をかける)は最初から決めておく必要があり、後から変更することがややこしいことになります。業務に必要な中間精度がはっきりと分かればこれでも良いかもしれませんが、個人的にアプローチ2の方が無難かと思います。
まとめ
最終的にアプローチ2を採用しようと思いました。
- フロントエンドから、現在地の経度緯度とズームレベルを受け取る
- ズームレベルから大体の半径を計算する(こちらに参照)
- 現在地と距離を指定して、囲む四角形を求める
- 四角形の座標を使い、
SPATIALインデックスの効くST_Withinを使って、範囲内のレコードを検索する - さらに
ST_Distance_Sphereを使って、より精確な結果を絞り出す
という流れになるかと思います。
またこれで実装してみて、何かあれば追って補足します。
ではでは。
補足
- GeoHashの使い道によりますが、もし精確性に要求がなければ、中間レベルのlat_1000_floorを作るよりも、GeoHashの桁数を下げて、それにインデックスを貼ると同じ効果にできるかなと。もしくは、geo_hashの方は精度を保つために10桁、geo_hash_prefixを追加して、桁数を5桁(誤差2.4km)に設定してインデックスを貼ると。
Discussion
めちゃめちゃ参考になる記事でした!
もし球体上の円を内包する正方形の計算スクリプトの出典とかあれば教えていただきたいですmm
コメントありがとうございます。ご参考になれて嬉しいです。
出典のことですが、こちらの記事で合っていますか(「まとめ」の節の上の段落にリンク付きの記事です)。
記事内はオリジナルのコードベースリンクがあります。
いずれもソースがPHPだったのでこちらでjsコードに書き換えているだけです!
おお!ありがとうございます!(見落としてました汗 :pray: :pray:
圧倒的感謝!